大模型微调让AI更懂代码,通过学习代码模块,显著提升代码理解与迁移效率。
原文标题:让AI读懂代码需求:模块化大模型微调助力高效代码理解与迁移
原文作者:阿里云开发者
冷月清谈:
通过简化学习任务,选用如Qwen3-4B这样的小参数量模型进行针对性微调,结合高质量结构化数据集构建和LoRA等高效微调策略。训练数据中引入“思维链”(CoT)机制,促使模型进行分步思考,提升推理的可解释性和泛化能力。最终,该方案在测试集上取得了78%的综合准确率,并实现了低成本、端侧秒级部署,有效解决了用户需求与代码关联的稳定性问题,提升了研发效率。
怜星夜思:
2、文章里提出,把AI对代码的理解从‘代码片段’升级到‘代码模块’,这个思路挺巧妙的。但如果我们需要对某个模块里非常具体的某一行代码、某个函数做精细化修改,或者某个小功能点恰好跨越了多个模块边界,那这种‘模块级理解’会不会有局限,甚至反而增加了AI的理解难度呢?大家怎么看?
3、文章提到,他们把AI模型部署到了Mac端,也就是开发者的本地电脑上运行。这种‘端侧部署’是不是除了文章说的降低成本和灵活性外,也带来了一些潜在的安全隐患或者数据隐私问题?毕竟模型是跑在本地,而且可能还接触到一些敏感的代码信息,大家有没有想过这方面的问题?
原文内容

阿里妹导读
本文介绍了一种解决开源项目代码升级中“用户需求关联相应代码”难题的创新方法。面对传统Code RAG和Code Agent在召回率、准确率和稳定性上的不足,以及领域“黑话”和代码风格差异带来的挑战,作者团队提出并实践了一套以大模型微调(SFT)为核心的解决方案。
一、项目背景
高德终端技术团队进行开源项目仓库代码升级期间,由于主版本跨度大,代码量更新变化也很大,过往在低版本上的经验知识不足以支持升级,如果依赖个人读懂整体仓库代码耗时过长。为研发提效,使用了阿里内部代码平台工具,发现暂不能满足一些定制化的知识问答,同时使用上也存在一些限制,外部类似deepwiki工具又存在代码安全问题,因此,基于code RAG和code Agent技术开发了研发提效工具,一定程度上满足了对仓库代码的定制理解,查询和修改需求。
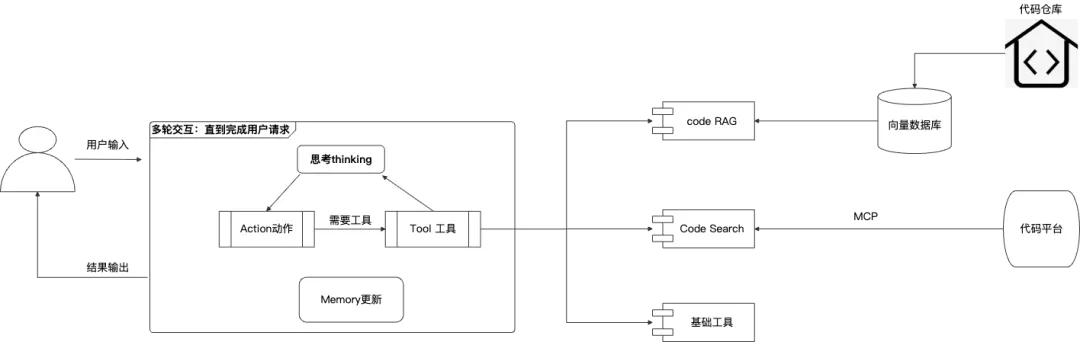
在使用过程中依然存在如下问题:
1.code RAG
把代码知识图谱,分片存入向量数据库,通过RAG进行匹配查找,会存在召回率和准确率的问题,在实际过程中,LLM基于查询结果会存在不稳定的输出;即使把这些知识,通过预置到prompt上下文中,LLM也会因为上下文过长,而导致性能下降,输出准确率变差。
2.code Agent
通过AI Agent利用代码查询工具,加上Agent的思考过程,会使查询结果进一步准确,但是,一旦一次查询的结果不够更好,基于这次查询结果的下一次迭代思考,会造成结果的不确定性,而且,也取决于代码查询工具的准确性,以致于不能够稳定输出正确的推理结果。
除了上述稳定性问题之外,在这个过程中我们发现,有以下问题也是难以解决的:一个是领域“黑话”,譬如专业术语,模块人为定的名称等,这些是研发人员在业务开发过程中,形成的约定俗成的“知识”;另外一个就是代码风格,通用的代码风格以及函数并不是当前模块所需要的,尽管功能基本相同,但是也需要采用符合仓库模块的代码风格及函数设计。综上所述,需要采用大模型微调的方式,对专业领域知识图谱进行学习,来解决这些问题,在本文中,重点解决的就是“用户需求关联相应代码的稳定性问题”。
代码需求理解
根据用户需求找到仓库内相应关联的代码,在业界LLM编程提效领域也是一个重要的课题,类似cursor通过对仓库做向量语义检索加上IDE内文件查找匹配,获取最接近的若干个代码片段,像aider更是通过建立庞大的仓库地图repo map,包含仓库内重要的代码符号和定义, 来给到LLM上下文里,但是,这些都建立在一个假设的基础上,就是给到LLM全部所需的仓库代码内容,在上下文窗口也满足的情况下,LLM就能够实现对仓库的全面准确的理解,显然不是这样的,因为代码是程序员根据产品需求的二次加工,理解了代码并不能等同理解仓库的业务架构设计,用户需求的自然语言描述同代码逻辑理解是存在gap的。
仓库的业务架构设计,体现在代码“模块”里,而不是在代码片段,而且越高层级的“模块”一般来说越稳定不变,而模块说明的信息,是密切跟产品需求的自然语言描述相关的,包含了领域知识和代码风格,形成了一张仓库的“模块缩略图”。因此,大模型微调学习的方向重点在代码模块学习,来实现代码需求理解。
-
把业界直接进行仓库代码检索学习,转化为“对仓库知识图谱代码模块”的学习,简化了学习任务,实现了低成本小参数量模型训练且能获得更准确更稳定的推理结果。
-
结合全仓库的代码知识图谱进行解析,获取高质量的训练/验证数据集,而不是直接基于代码构建数据集。
-
对模型输出的结果,推理时进行了模块列表范围控制,确保模型只生成符合模块ID格式的输出。
二、微调准备
下面是微调的一般过程,基础模型由专业的大模型公司提供,在微调(SFT)之前,要进行基础模型选型和微调框架选择,做好微调前准备工作。

基础模型选型
选择哪个基座模型,主要考虑以下因素:
1.任务复杂度
为了降低任务复杂度,我们把“用户需求关联出相应代码”任务,简化成了“用户需求匹配相关模块”的模块匹配任务。通过LLM匹配出对应的代码模块,模块内的代码是确定的,也就找到了用户需求关联的相应代码。

从模型性能角度,匹配任务需要大模型具备足够强的“语义理解”能力,能够理解用户的需求,并通过领域知识,找到相应的关联模块;但通常不需要复杂的逻辑推理。
2.易于部署
从做研发工具来讲,“用户需求关联相应代码”这个步骤属于代码生成的前置环节,期望大模型能够在端侧运行,即在mac端能够运行,不部署在服务端,这样能够降低成本,同时具备灵活性。
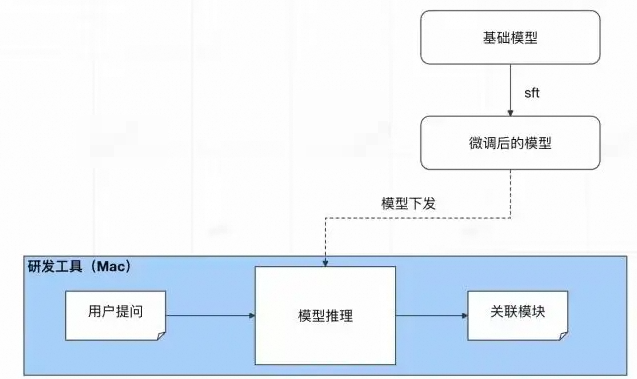
基于这方面考虑,满足端侧部署需要小参数量的基础模型。
3.训练资源
训练资源上使用单机单卡16GB显存,资源比较受限,需要在性能和资源之间要达到理想的平衡点。

综合上述几点考虑,以Qwen3-4B 作为基准模型,支持Chain-of-Thought(CoT)思维链式推理,结合领域数据进行微调,以最大化提升在特定任务上的效果,同时采用量化技术优化部署,尤其适合大多数场景下的匹配任务。
微调框架选择
集团内部有多个微调训练的平台,譬如openLM, 魔搭平台的SWIFT等,集团外部有LLaMA-Factory,利用服务端共享的GPU集群进行训练,支持多种先进的微调算法和模型,适用于参数量大的复杂模型训练任务,但是对简单模型训练任务,希望在单机有限GPU资源下完成,并且缩短训练周期,基于这个考虑,选择了unsloth高性能训练框架。

三、微调过程
数据集构建
构建领域特定的训练数据集,需要基于全仓库的代码知识图谱进行解析,高质量的训练/验证数据集,是微调 (Fine-tuning)的基础。
以下是MNN仓库的部分代码知识图谱:

从代码知识图谱中,进行实体关系抽取:
-
节点信息:模块节点
-
边关系:模块间关系
-
属性信息:功能描述等
然后根据节点生成模块内容,按关系生成层次结构,按属性生成功能描述,最终生成如下的结构化的训练数据格式。模块ID有固定结构,父模块-子模块,增强可解释性;关键词增强标注描述中的关键动词或者名词,构建关键词-模块ID的映射词典,辅助模型注意力。
最终,数据集里的数据格式如下:

数据预处理
为了提高模型的训练效率和性能,需要对上述结构化数据进行处理,确保输入给LLM的数据格式统一、上下文明确、监督信号清晰。以下是训练数据的输入的Prompt模板和标签Label:

从上述可以看出,明确了给到大模型的指令,清晰说明任务要求,并进行了上下文限定,聚焦模块匹配场景;同时,标签Label中包含思考的过程和最终的模块输出,结构化的输出格式方便解析,其中的thinking字段包含高质量的思考过程,包括:关键技术点的详细分析,功能领域的准确归类,以及模块层级的清晰划分。
在预处理过程中,也应用了如下数据增强,扩充了训练数据的多样性,防止过拟合:
-
模块描述创建多个变体;

-
增强Prompt上下文信息;
-
同义词替换,添加/删除非关键信息,句子句式重组等,同时需要保持核心语义不变。


Qwen3-4B既支持普通模式推理,也支持CoT思考方式推理,在数据预处理时,把这两部分数据按1:1比例进行处理。使用带有Chain of Thought (CoT)的训练数据, 让模型学会分步骤思考,提高推理过程的可解释性,增强泛化能力,降低直接匹配的难度。输出如下:

微调策略
1.Lora微调
LoRA(Low-Rank Adaptation)是一种参数高效的微调技术(Parameter-Efficient Fine-Tuning, PEFT),旨在通过低秩分解减少大模型微调的计算和存储成本。其核心思想是假设模型权重的变化可以用低秩矩阵近似表示,在微调过程中,冻结预训练模型的原始权重,仅训练这些低秩矩阵,从而大幅降低可训练参数量。LoRA 具有显存占用低、计算效率高、性能接近全量微调等优势,特别适合大规模语言模型的适配任务。此外,LoRA 可与其他技术(如量化)结合,进一步优化资源利用,广泛应用于多任务学习和边缘设备部署场景。
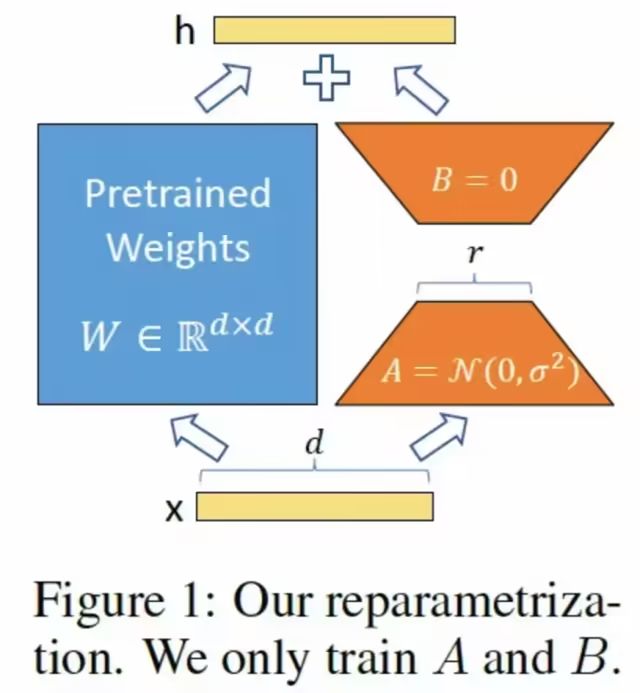
可以通过unsloth的FastLanguageModel.get_peft_model方式,进行Lora微调配置,其中的配置参数,主要考虑以下几方面:
-
任务复杂度
-
可用显存大小
-
训练数据量
-
实际文本长度需求
-
训练任务类型

2.SFT训练参数
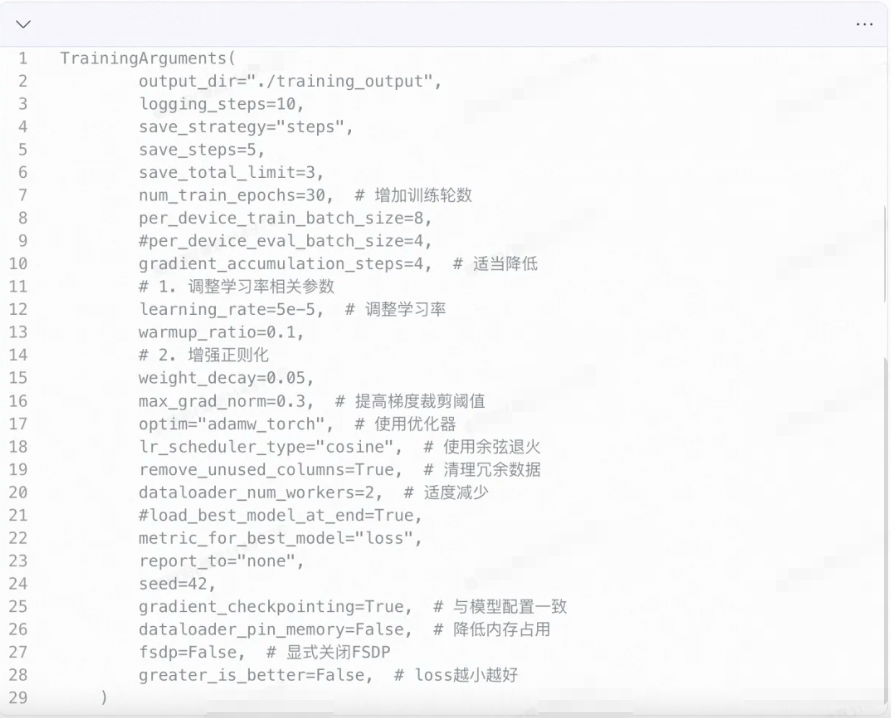
最终通过merge方式,保存最终的完整模型。

输出如下:
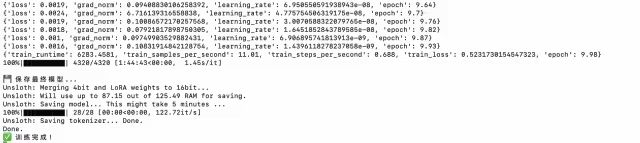
工程处理
对模型输出的结果,推理时进行了模块列表范围控制,和数据清洗,确保模型只生成符合模块ID格式的输出。
四、实验结果
在测试集上测试,综合准确率78%,达到预期效果。

五、端侧部署
在mac端通过mps进行部署sft模型,使用CPU或Metal Performance Shaders (MPS)后端并运行,主要修改包括设备检测和内存管理部分。测试推理代码如下:
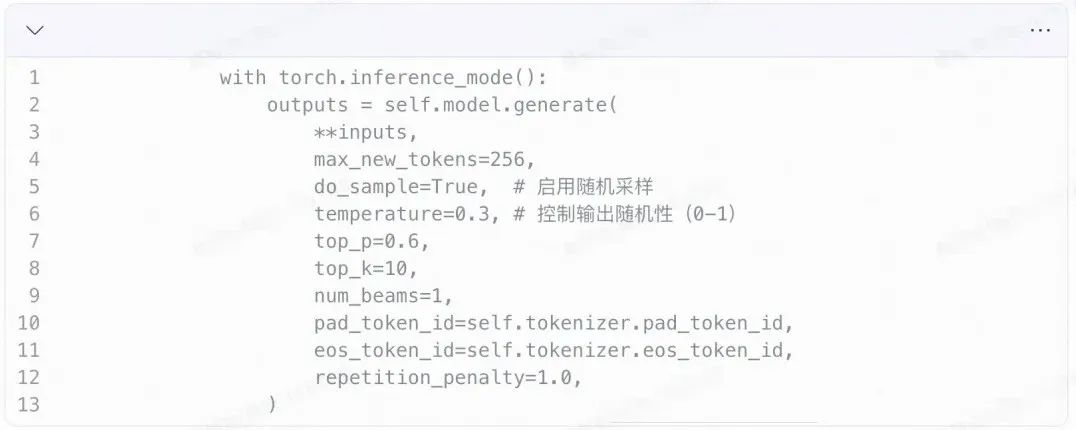
以下测试case输出,处理耗时在mac端达到秒级。

六、总结
通过微调,大模型能快速适应领域知识以及术语,生成更加准确,专业,稳定的回复;同时,低成本进行大模型微调,且能够在端侧部署和使用,也是业界一直在解决的问题,上述方案在落地过程中,也遇到了数据集单一,梯度不收敛,基座模型选型等问题,最终通过算法加工程方法进行了解决,未来结合强化学习,小参数量模型的微调在解决垂直领域问题上将会发挥越来越来越重要的作用。
高效搭建 AI 智能体与工作流应用
阿里云百炼作为一站式大模型开发和应用构建平台,提供丰富的模型选择和便捷的开发工具,并支持多模态数据处理,帮助用户快速构建生产级 AI 应用,以满足各行业的定制化需求。通过这些优势,平台最终助力企业实现高效创新,为业务持续赋能。
点击阅读原文查看详情。