新版GB/T 20988-2025信息系统灾难恢复规范发布!它整合旧标,强调生命周期管理、云计算,并细化RPO/RTO要求,确保业务连续性及数据安全。
原文标题:信息系统灾难恢复规范GB/T 20998-2025解读
原文作者:牧羊人的方向
冷月清谈:
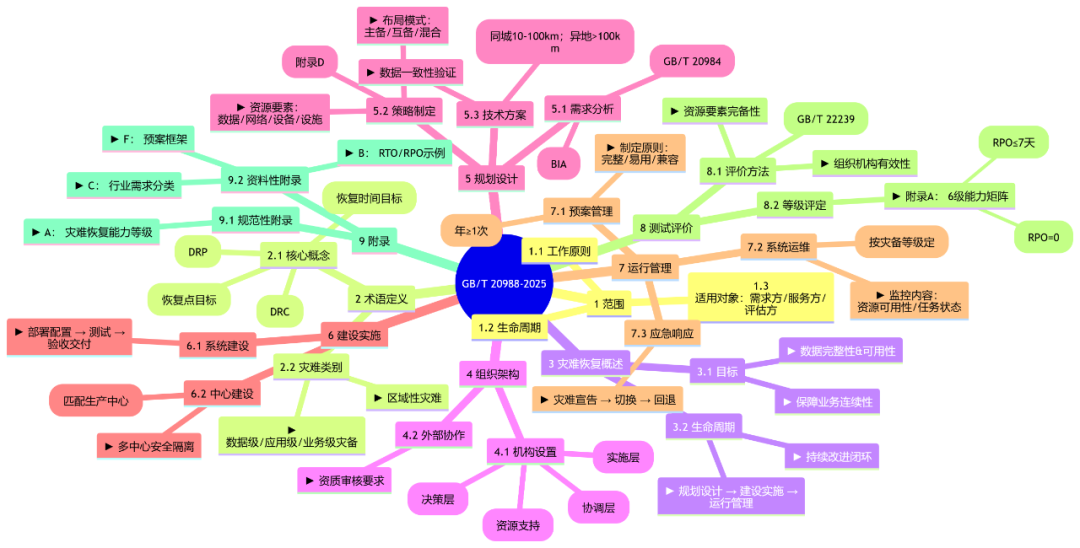
新规范在灾难恢复工作原则、生命周期管理、能力等级划分及测试评价方法上都有显著提升和细化。它明确了灾难恢复目标在于保障数据完整性和业务连续性,并为此构建了规划设计、建设实施和日常运行管理的全生命周期体系。在确定灾难恢复需求时,强调了基于风险分析和业务影响分析的重要性,以匹配不同的等保和运维服务级别。
规范将灾难恢复类别细分为数据级、应用级和业务级,各自对应不同的恢复范围、核心目标、RTO/RPO要求、技术复杂度和成本投入,为企业提供了更为清晰的参照标准。例如,业务级灾难恢复不仅涵盖数据和系统,更扩展至人员、办公环境及业务流程的连续性,适用于金融交易、医疗急救等战略级业务系统,其恢复时间(RTO)和数据丢失量(RPO)要求极其严格。
此外,规范对灾备恢复中心的选址(同城10-100KM,异地大于100KM,并规避自然灾害同发区)和基础设施等级提出了具体要求。值得注意的是,新规范还专门针对云计算技术的灾难恢复提出了适用性和兼容性需求。在测试评价方面,新增34项测试方法,覆盖建设、运维、审计全环节,确保灾备体系的有效性。最引人注目的是,新规范将信息系统灾难恢复能力细分为6个级别,明确了各级别的RPO和RTO要求,特别是在5级和6级对数据零丢失的强调,为企业提供了更精细的灾备目标。该国标作为推荐标准,将引导各行业制定或修订自身的灾备规范。
怜星夜思:
2、文章里把灾难恢复类别分成数据级、应用级和业务级三大类,而且RPO/RTO要求和成本投入都差异巨大。对于我们这些预算有限的中小型企业来说,如何在保障业务连续性和控制成本之间找到最佳平衡点?有没有一些比较实用、可以落地实施的建议?
3、新规范对RPO(恢复点目标)和RTO(恢复时间目标)有了更细化的要求,甚至提到5、6级灾备能力要实现“数据零丢失”。在实际操作中,面对复杂的系统环境和数据类型,企业如何精确测量和验证自己的RPO和RTO,并确保它们真正符合新规范的要求?有没有哪些具体的工具或方法可以推荐?
原文内容
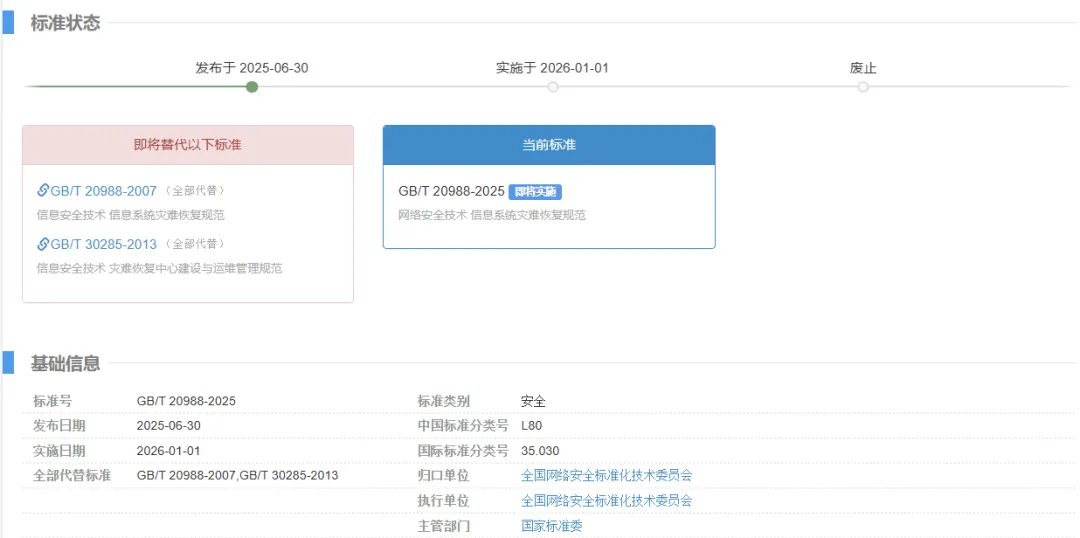
最近新发布了GB/T 20988-2025《网络安全技术 信息系统灾难恢复规范》,该规范定义了信息系统灾难恢复的生命周期,明确了灾难恢复的基本要求,并对各信息系统的RPO和RTO有了更为细化的要求。规范于2025年06月30日发布,并将于2026年01曰01日实施。
1、新旧规范差异对比
《网络安全技术 信息系统灾难恢复规范》GB/T 20988-2025确立了信息系统灾难恢复工作原则,给出了信息系统灾难恢复生命周期,规定了信息系统灾难恢复应遵循的基本要求,描述了灾难恢复能力等级划分和测试评价方法。作为替代GB/T 20988-2007《信息安全技术 信息系统灾难恢复规范》和GB/T 30285-2013《信息安全技术 灾备恢复中心建设与运维管理规范》,其中有以下不同地方,如下表所示:
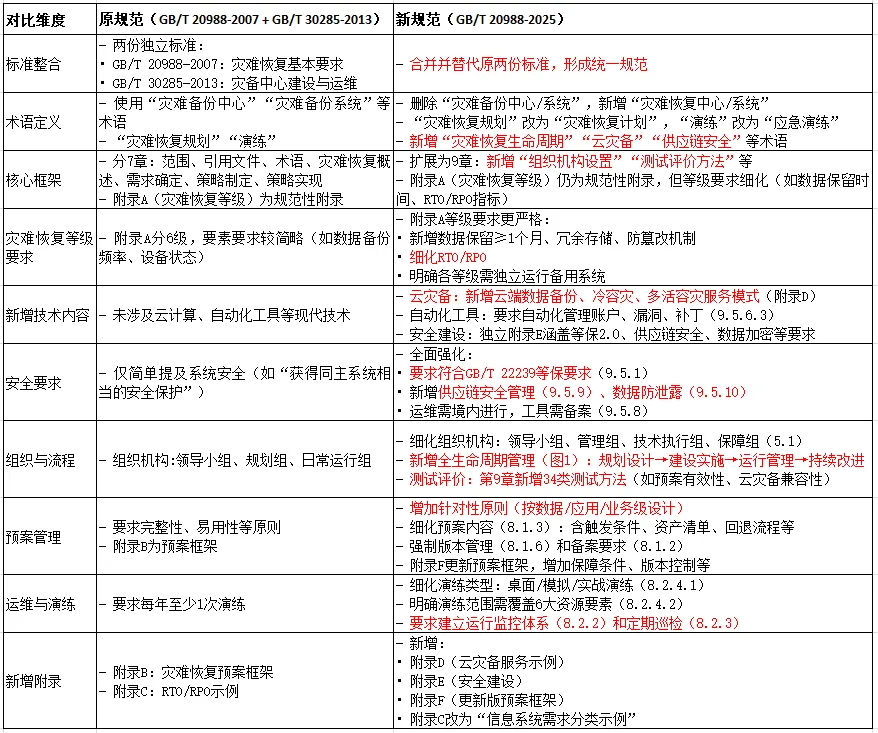
新旧版本规范主要差异点,从规范名称和范围上由原来的信息安全技术变为网络安全技术,标准也整合了GB/T 20988-2007灾难恢复基本要求和GB/T 30285-2013灾备中心建设与运维,形成了统一标准。另外结合现代技术发展,纳入云计算、网络安全、自动化等新技术领域。在管理上强调了生命周期管理,测试评价系统更为系统化,新增34项测试评价方法,覆盖建设、运维、审计全环节。对灾备恢复的等级也做了细化,强调数据零丢失,RTO/RPO要求更明确。
2、GB/T 20988-2025新规范内容解读
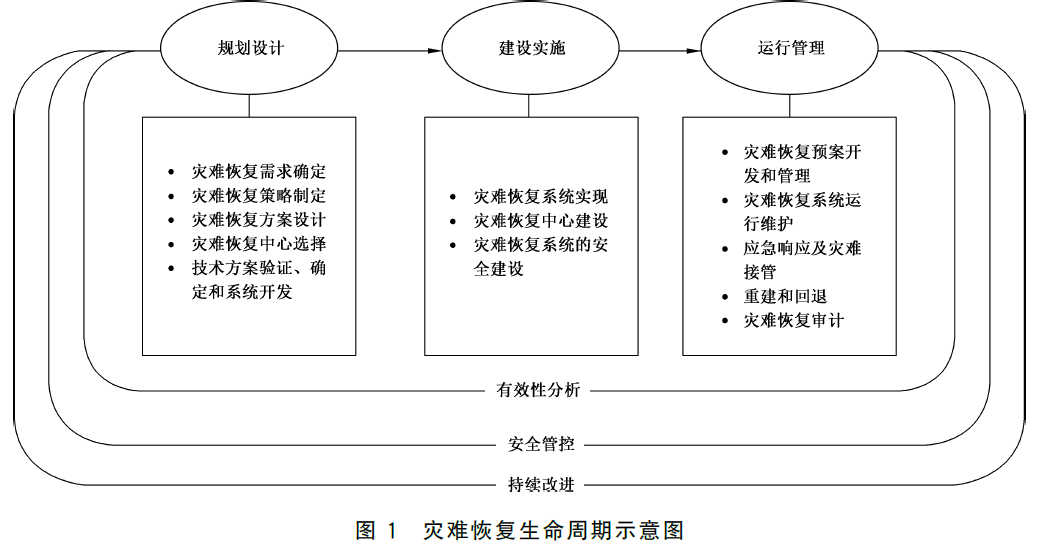
新规范中明确了灾难恢复的目标,也就是保障数据的完整性,保障业务的连续性。
灾难恢复目标是通过有效的技术与管理手段,确保组织在灾难发生时迅速恢复信息系统运行,最大限度地降低损失和影响,保障数据的完整性和可用性,保障业务的连续性。
为实现该目标定义了灾难恢复的生命周期管理,包括规划设计、建设实施和日常运行管理,包括预案管理、运行维护、监控、巡检工作,还涉及应急响应及灾难接管、重建和回退、审计等相关工作。
在确定灾难恢复的需求之前,需要进行风险分析和业务影响分析。风险分析遵循GB/T 20984-2022《信息安全技术 信息安全风险评估方法》,识别信息系统中存在的风险和存在的脆弱性。业务影响分析则需要识别各信息系统和业务之间的相关性,确定各个业务功能模块之间的强弱依赖关系,并进行定量和定性分析,对业务功能中断造成的影响进行评估。

根据风险分析和业务影响分析的结果,确定应用系统的等保级别和运维服务级别,根据不同的级别制定不同的灾难恢复需求,包含恢复的优先级、灾难恢复的RTO和RPO指标。
根据提供服务重要性、时效性要求和建设规划,灾难恢复类别分为:数据级、应用级和业务级。
-
数据级灾难恢复:确保灾难发生后数据的完整性和可恢复性,重点在于保护数据本身不受损坏或丢失。通常通过数据备份(如磁带库、异地存储)或数据复制技术(同步/异步传输)实现,适用于对业务中断容忍度较高的非核心系统,成本较低。
-
应用级灾难恢复:在数据级基础上,实现应用系统的快速接管,减少业务中断时间,保障业务连续性。通过在灾备中心构建与生产中心相同(或部分相同)的应用系统环境,支持故障切换,依赖主备集群间的高可用能力和数据复制能力。适用于关键业务系统,需在灾难发生时快速恢复系统运行。
-
业务级灾难恢复:在应用级基础上,不仅涵盖数据和系统的恢复,还确保整个业务运作的连续性,包括人员、办公环境、业务流程等。通过完整的业务运行环境以及跨中心的多活部署架构,实现业务功能全接管,并且有足够的人力和资源保障业务运行。适用于战略级业务系统(如金融交易、医疗急救、政府核心系统),需在灾难发生时立即恢复全部业务功能。
|
维度
|
数据级
|
应用级
|
业务级
|
|---|---|---|---|
|
恢复范围
|
仅数据
|
数据+系统
|
数据+系统+业务环境+人员
|
|
核心目标
|
数据完整性
|
系统可用性
|
业务连续性
|
|
RTO/RPO要求
|
宽松(数小时至数天)
|
严格(分钟级至小时级)
|
极其严格(秒级至分钟级)
|
|
技术复杂度
|
低
|
中
|
高
|
|
成本投入
|
低
|
中
|
高
|
|
适用场景
|
非关键业务系统
|
关键业务系统
|
战略级业务系统
|
灾备恢复中心包括同城和异地两种类型,选址符合以下要求:
-
同城恢复中心不在同一个电网、通信节点内,直线距离10~100KM之间
-
异地灾难恢复中心避开自然灾害同发地区,建设距离要大于100KM
-
重要的国家战略层面的灾难恢复中心的选址宜关注防灾害、防侦测和攻击等因素
另外,新规范中规定灾难恢复中心基础设施的等级宜与生产中心的等级保持一致或低一个等级。
使用云计算技术时,需要考虑云上、云下、跨区、跨云场景下的适用性和兼容性需求。同时按照成本风险平衡原则,确定数据级、应用级的灾备恢复能力,并考虑系统架构和兼容性能力、独立于生产云平台的场外云平台能力。
新规范中对灾难恢复生命周期中的各个环节和各个阶段进行测试评价,包括组织机构的设立、灾备恢复的需求、策略和方案设计、灾备恢复系统的建设以及运行管理等。
新规范中奖信息系统的灾难恢复能力等级划分为6个级别,细化了RPO和RTO要求,明确数据备份周期和数据零丢失。如表所示:
|
灾难恢复能力
|
数据备份
|
RPO
|
RTO
|
数据安全性
|
数据零丢失
|
|---|---|---|---|---|---|
|
1级
|
至少每周一次
|
天级
|
72h
|
-
|
-
|
|
2级
|
至少每周一次
|
天级
|
48h
|
-
|
-
|
|
3级
|
至少每天一次
|
小时级~天级
|
24h
|
有
|
-
|
|
4级
|
至少每天一次
|
小时级
|
小时级
|
有
|
-
|
|
5级
|
至少每天一次
|
小时级
|
分钟级~小时级
|
有
|
有
|
|
6级
|
至少每天一次
|
小时级
|
分钟级
|
有
|
有
|
可以看到,随着灾难恢复能力的增加,对数据的安全性和完整性要求越高,应用系统的恢复时间也越短,在5级和6级不仅要求小时级RPO,而且需要保证数据零丢失。
3、总结
GB/T 20988-2025《网络安全技术 信息系统灾难恢复规范》定义了灾难恢复的生命周期管理,包括规划设计、建设实施和运行管理。
GB/T 20988-2025是一个国家推荐标准,具体到各个行业会根据该规范制定不同的行业标准,比如在金融行业有JR/T 0265-2023《金融数据中心能力建设指引》和JR/T 0264—2024《金融数据中心容灾建设指引》,其中也定义了金融数据中心的场地建设、网络环境和运行管理等要求,不过其中没有指定RPO和RTO的要求。
另外在JR/T 0205-2020 《分布式数据库技术金融应用规范 灾难恢复要求》中给出了金融领域分布式数据库的容灾能力级别以及对应的RPO和RTO要求。
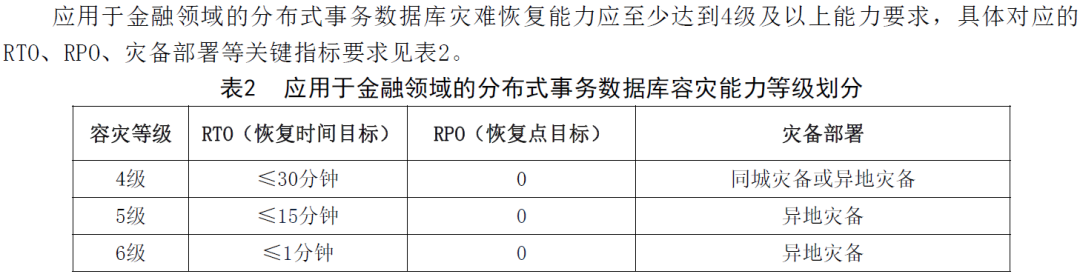
金融领域集中式数据库暂无相应的行业标准和规范,也可能按照国家标准来执行。不过在GB/T 20988-2025新规范发布以后,各个行业内的标准也可能相对应的进行修改和细化了。
参考资料:
-
https://std.samr.gov.cn/
-
GB/T 20988-2025《网络安全技术 信息系统灾难恢复规范》
-
GB/T 20988-2007《信息安全技术 信息系统灾难恢复规范》
-
GB/T 30285-2013《信息安全技术 灾备恢复中心建设与运维管理规范》
-
JR/T 0205-2020 《分布式数据库技术金融应用规范 灾难恢复要求》
-