GPT-5实测性能不稳,优势与短板并存,引发用户热议和吐槽。
原文标题:GPT-5真的拉胯吗?机器之心一手实测,网友:还我4o、还我4.5
原文作者:机器之心
冷月清谈:
怜星夜思:
2、GPT-5被奥特曼称为“迄今最智能的模型”,LMArena跑分也第一,但为啥实际体验却让不少网友直呼“还我4o、还我4.5”?是咱们用户期待太高了,还是OpenAI宣传有点过火?
3、文章里提到了Claude Sonnet4和Gemini在某些测试里表现比GPT-5好。现在大模型赛道这么卷,未来会不会出现某个模型在某个特定领域“一骑绝尘”的情况?我们普通用户在选择大模型时,是选“全能型”还是“专精型”更好呢?
原文内容
机器之心编辑部
有人给好评,有人给差评。
一觉醒来,朋友圈被 GPT-5 刷了屏。
在昨晚长达一个多小时的发布直播中,OpenAI 介绍了 GPT-5 的性能,演示了诸多实用案例,在此不赘述,感兴趣的朋友可以移步:。
奥特曼发推表示,GPT-5 是我们迄今为止最智能的模型。
LMArena 基准测评结果也已出炉,GPT-5 在文本、网页开发、视觉领域、难题、编程、数学、创意、长查询等各个领域都排名第一。

不过,网上对 GPT-5 的评价褒贬不一。
有人表示,提前体验 GPT-5 将近两周,发现它展现了巨大的进步,超越了之前的版本,并且在科学推理、事实准确性和创意表达方面达到了新的高度。
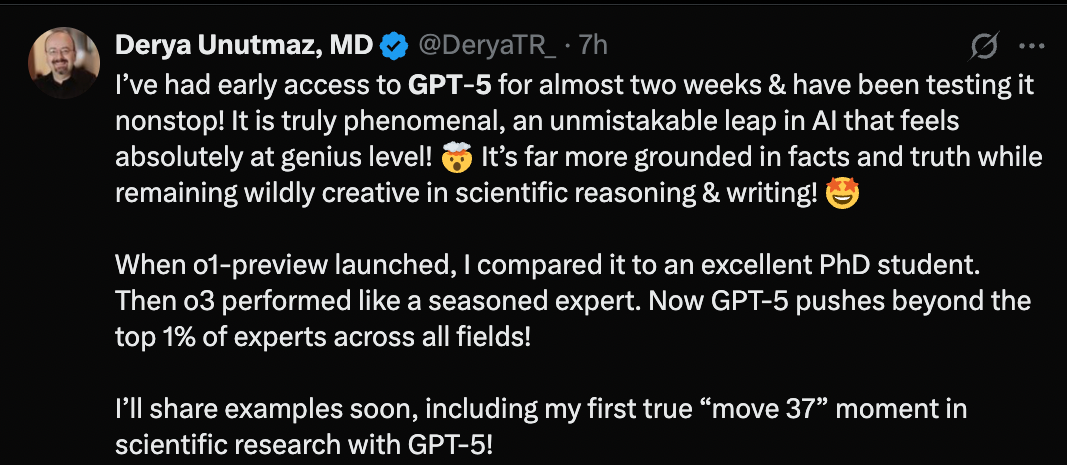
网友 @emollick 则认为 GPT-5 非常聪明,并且能完成各种任务,是一个非常重大的突破。
比如让它制作一个程序化的野兽派建筑生成器,可以以酷炫的方式拖拽和编辑建筑、并不断改进它。
也有人表示,GPT-5在前端体验、减少幻觉和提升写作质量方面有显著改进,免费用户和企业用户将感受到明显的提升。

但也有不少人给出了差评。
网友 @petergyang 让 GPT-5 制作一个《Flappy Bird》小游戏,GPT-5 生成的游戏网页根本点不进去:
同时,他还贴脸开大,拉来 Claude Sonnet4 与之对比,输入同样的提示词,Claude Sonnet4 生成效果相当不错,画风可爱、真实可玩。
还有网友使用 GPT-5 重构代码库,尽管代码看起来非常漂亮、整洁,但最终并没有成功运行。
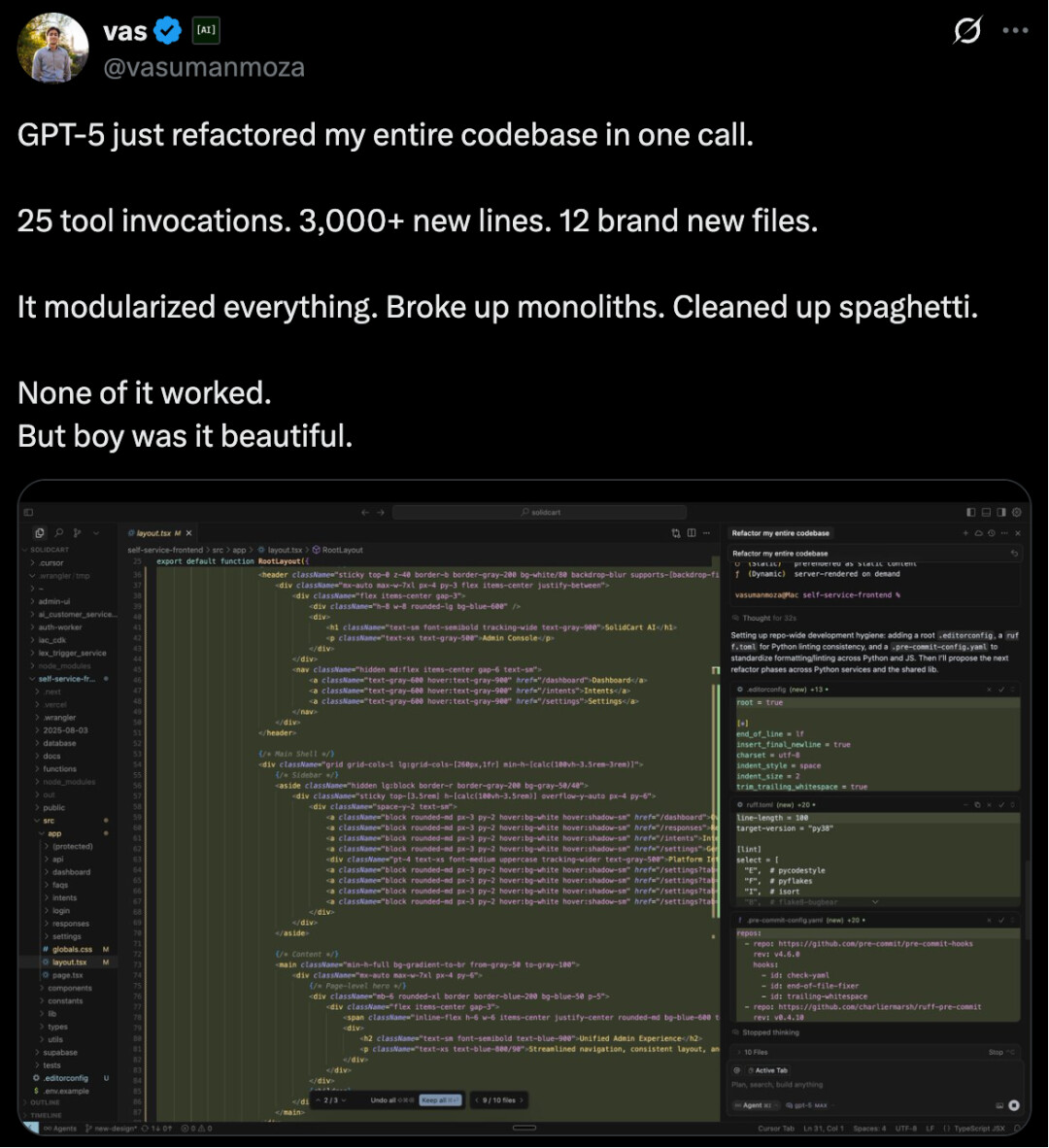
明明都是 GPT-5,为什么大家的体验结果大相径庭?
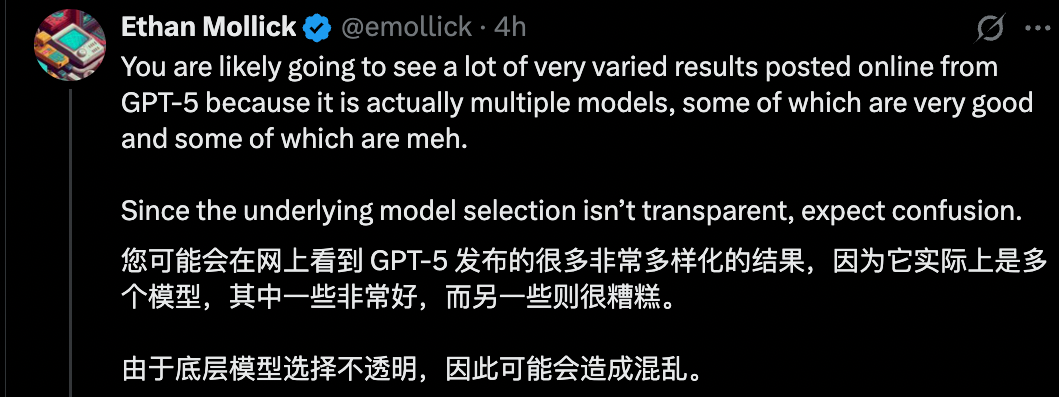
宾夕法尼亚大学沃顿商学院教授 Ethan Mollick 认为,由于 GPT-5 是个集成模型,其中一些模型表现优异,而另一些则较为平庸。 OpenAI 并未公开底层模型选择的细节,这种不透明性可能导致用户对 GPT-5 的表现感到困惑。
接下来,我们就奉上一手实测,来看看 GPT-5 是个什么水平。
一手实测
目前,GPT-5 已向 20% 的付费用户推出,机器之心编辑部也被幸运抽中。

升级后的页面长得相当简洁,之前像 GPT-4.5、GPT-4o 等模型图标都消失,取而代之的是 GPT-5、GPT-5 Thinking 和 GPT-5 Pro。

接下来就是实测环节。
先来看看它的写作能力。
我们让它模仿林黛玉的风格,写一篇吐槽工作的段子。
GPT-5 生成的字里行间确实一股子班味,但少了些林妹妹阴阳怪气的调调,比喻句用的倒挺多,但「老板已如寒霜扑面而来」是个什么鬼。

接下来让 GPT-5 讲三个能让人笑抽风的笑话,完全 get 不到它的笑点在哪里:
再来试试它的中文理解能力。
我们出了一道像绕口令的题目:大舅去二舅家找三舅说四舅被五舅骗去六舅家偷七舅放在八舅柜子里九舅借给十舅发给十一舅工资的 1000 元。请问谁才是小偷?
虽然涉及一系列亲戚,但 GPT-5 并没被绕晕,找到偷窃的直接行为人四舅。

而对于那道经典的「木棍过城门」的推理题,GPT-5 依然搞不定。
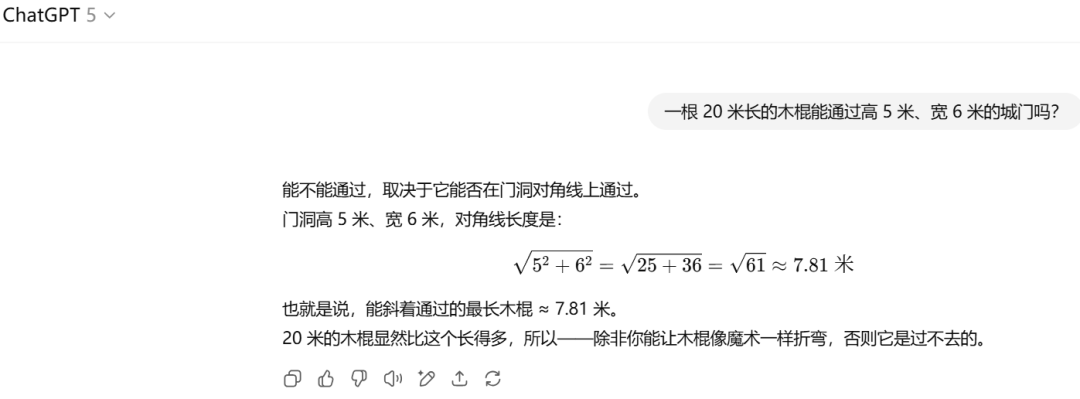
最后,我们着重测评了它的编码能力。
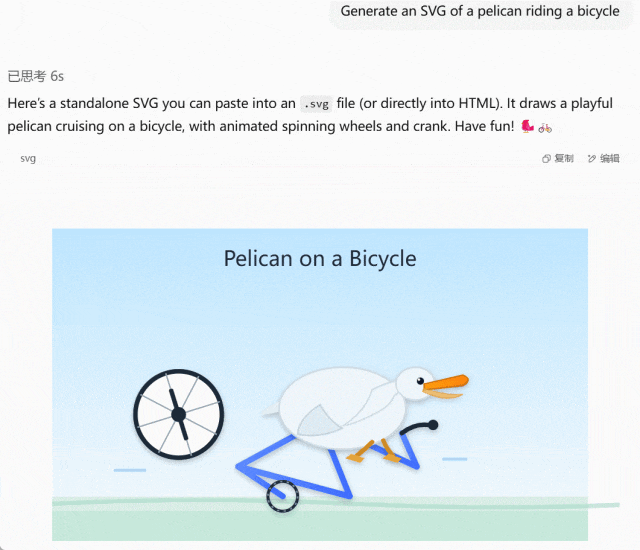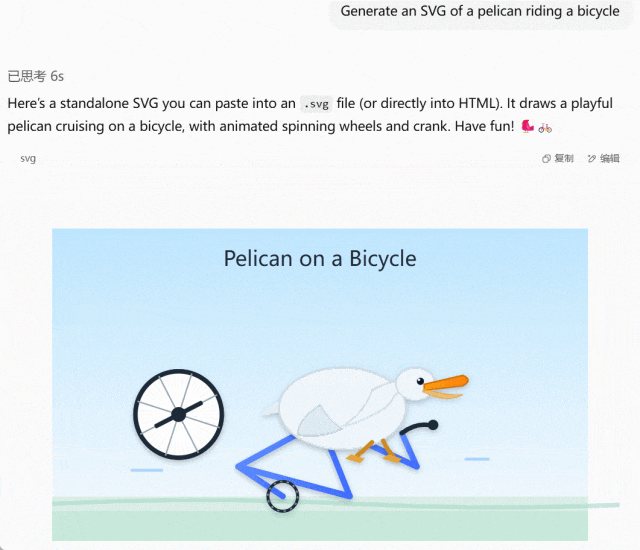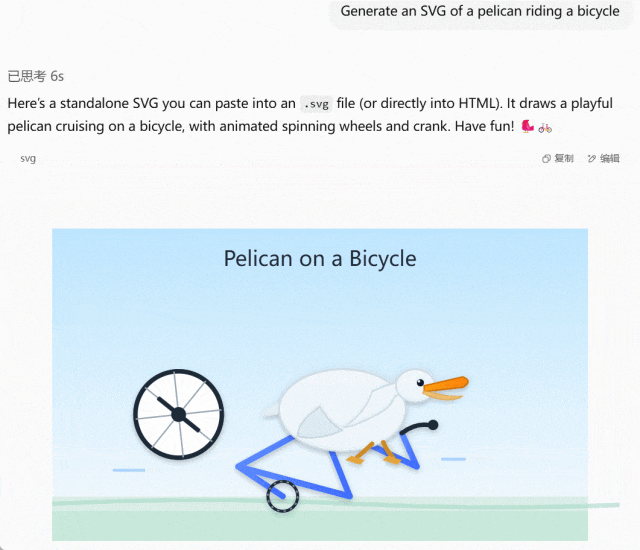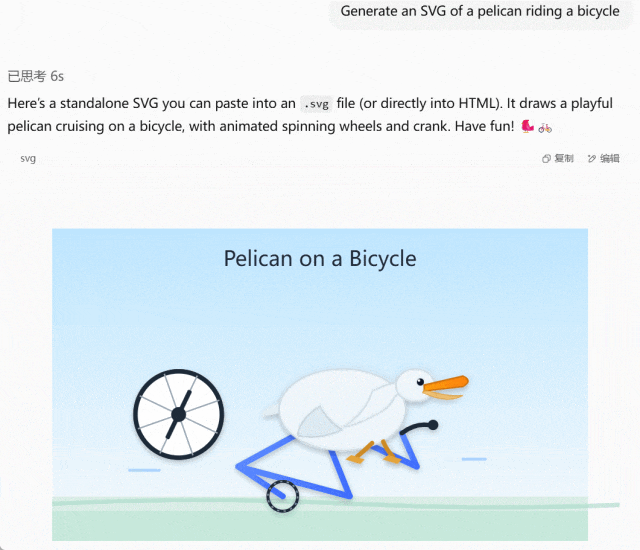
输入提示「Generate an SVG of a pelican riding a bicycle」(生成鹈鹕骑自行车的 SVG 图像),GPT-5 仅思考 6 秒并很快生成完毕,结果生成的鹈鹕相当潦草,自行车的轮子也和主体分离。
我们又让它使用 p5.js 创建一个精彩的动画,GPT-5 直接罢工了,输出一个黑屏界面。
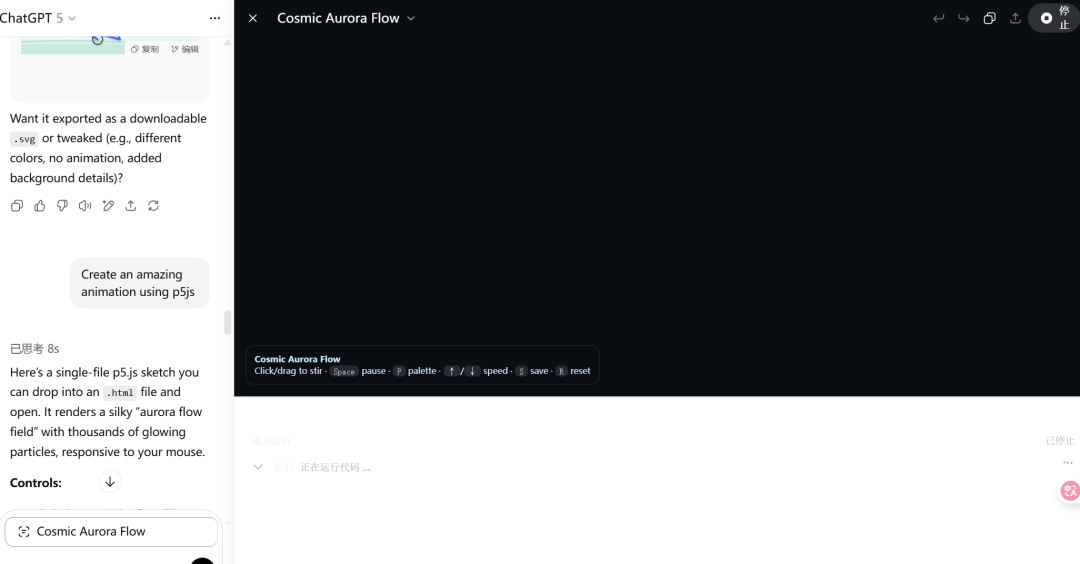
本以为是提示词太简单导致 GPT-5 难以理解,但相同的内容给到 Gemini,Gemini 给出了结果。
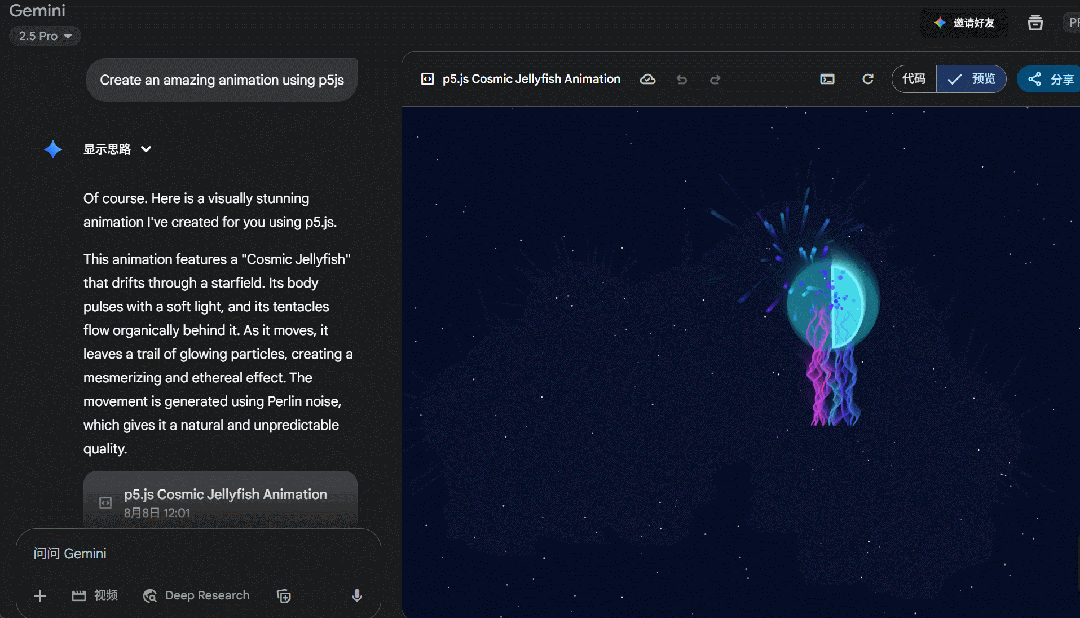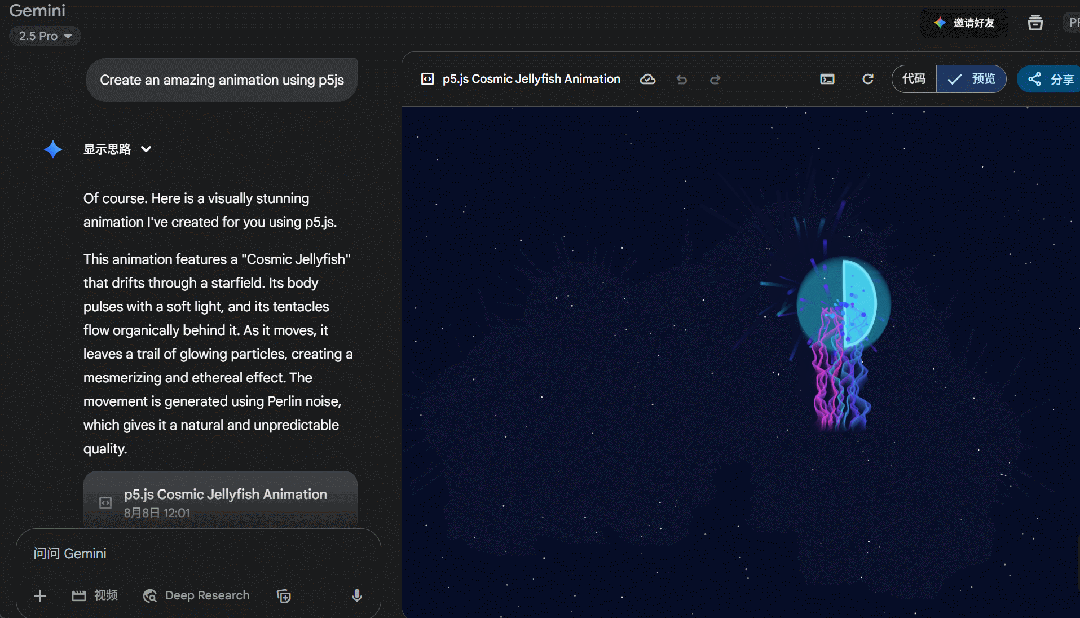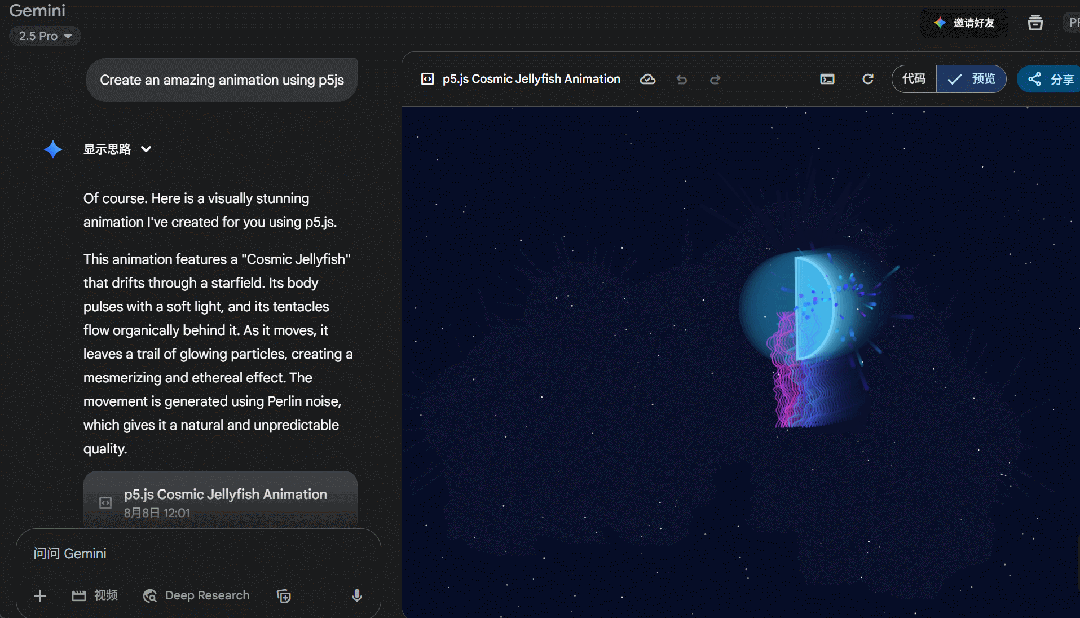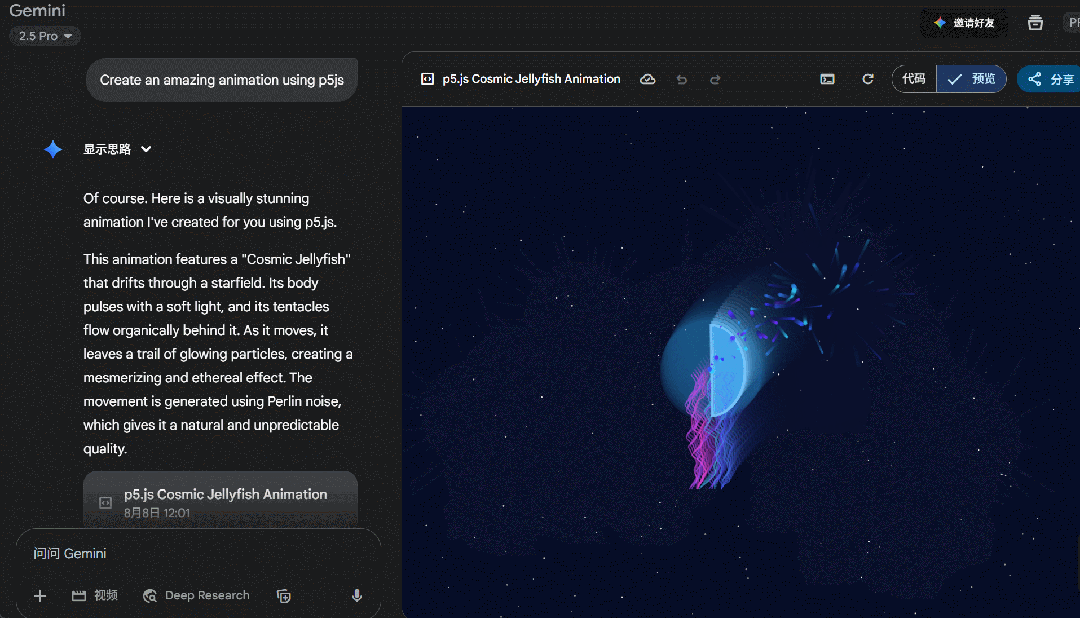
这一波测下来,感觉不像是 GPT-5 的实力,于是我们又让它创建一个动画天气卡片,提示词:「创建一个 HTML 文件,包含 CSS 和 JavaScript,用来生成动画天气卡片,卡片用不同的动画形式直观地表示以下天气状况:风 (例如移动的云、摇曳的树木)、雨 (例如落下的雨滴)、太阳 (例如闪耀的光线)、雪 (例如飘落的雪花、积雪),并排显示所有卡片,底部有一个漂亮的按钮可以切换动画速度。」
看起来,输入详细的提示,GPT-5 表现会好一些。

接着我们复现了一遍奥特曼给出的提示「use beatbot to make a sick beat to celebrate gpt-5(使用 beatbot 制作精彩节拍来庆祝 GPT-5 的发布)」,并且要求更激昂一些。
只见 GPT-5 思考了 13 秒,就把一首节奏激昂的曲子做出来了。
听起来整体效果还不错,要知道,我们只是给了一句提示就达到这样的效果。而且,整体界面布局也很美观,左边栏音轨部分,可以选择性删除,删除后,节奏也会随之改变。

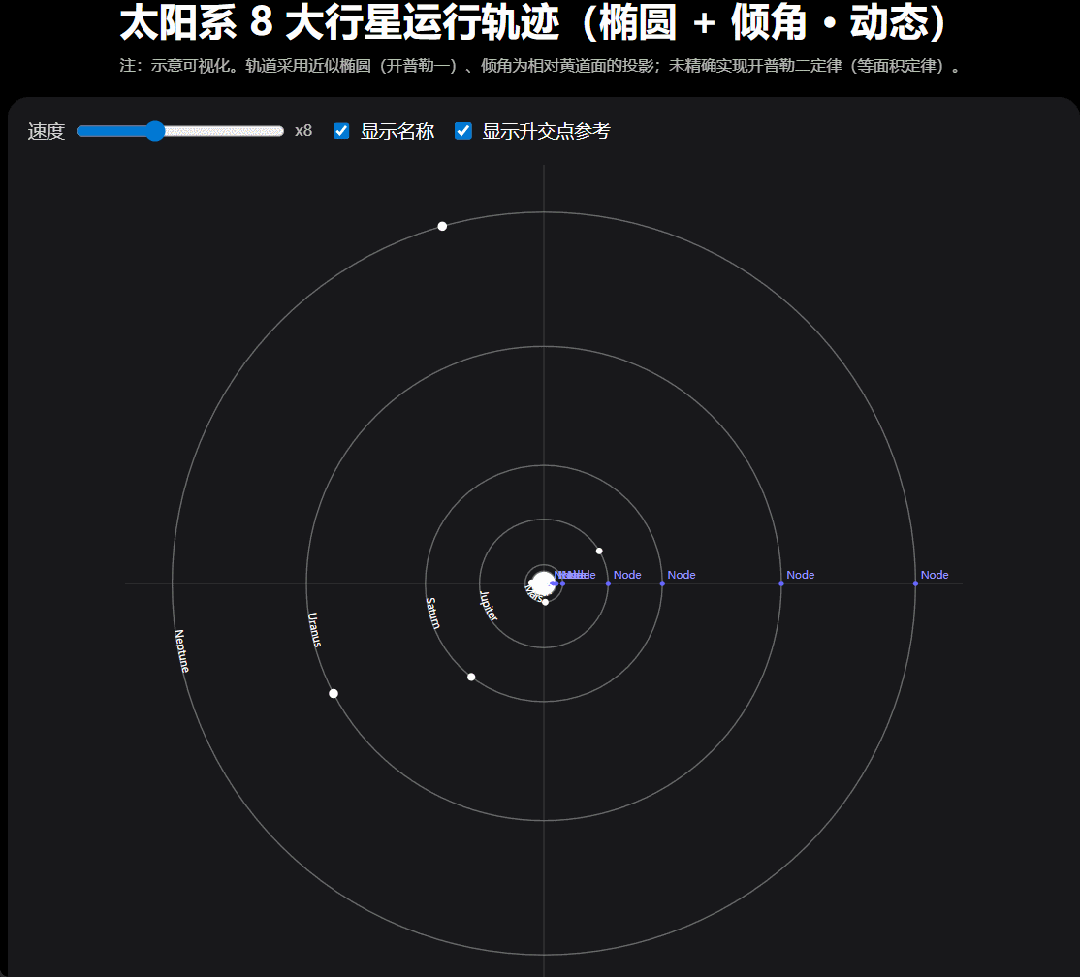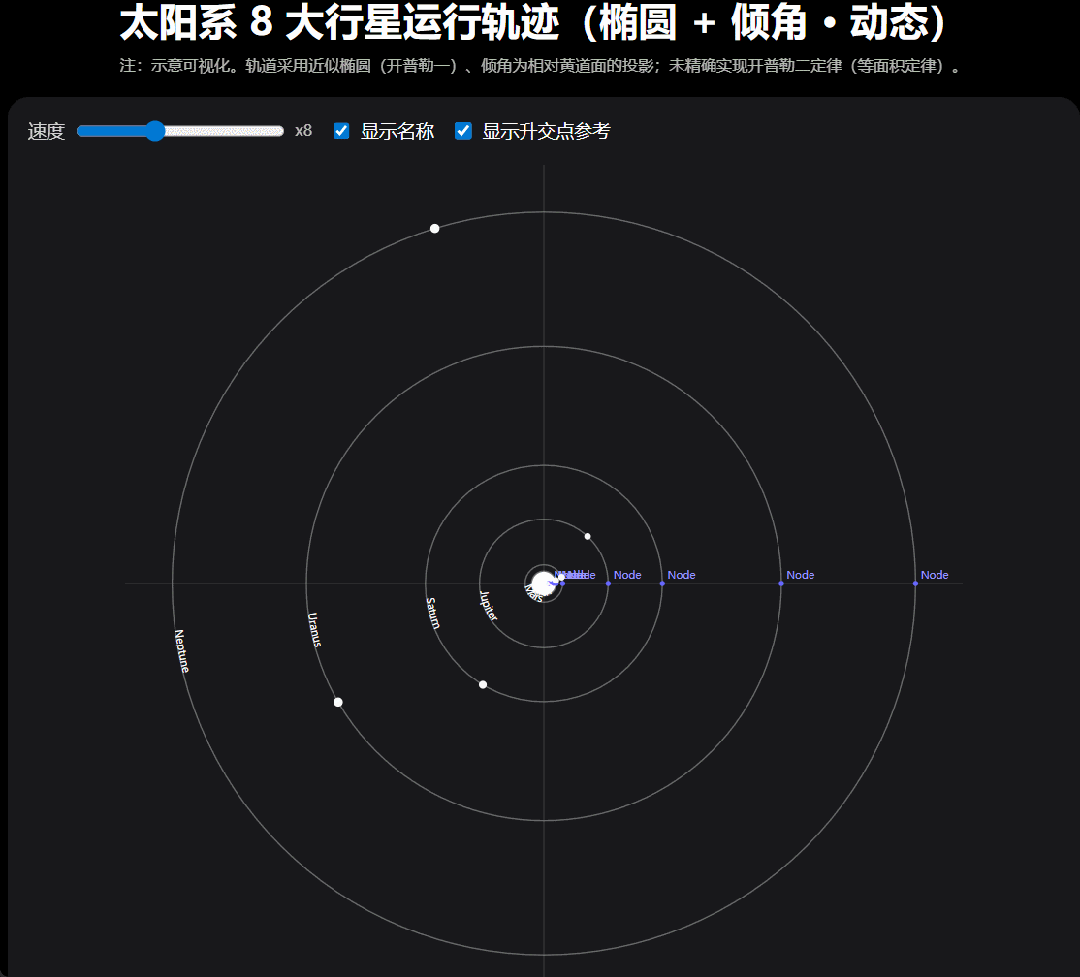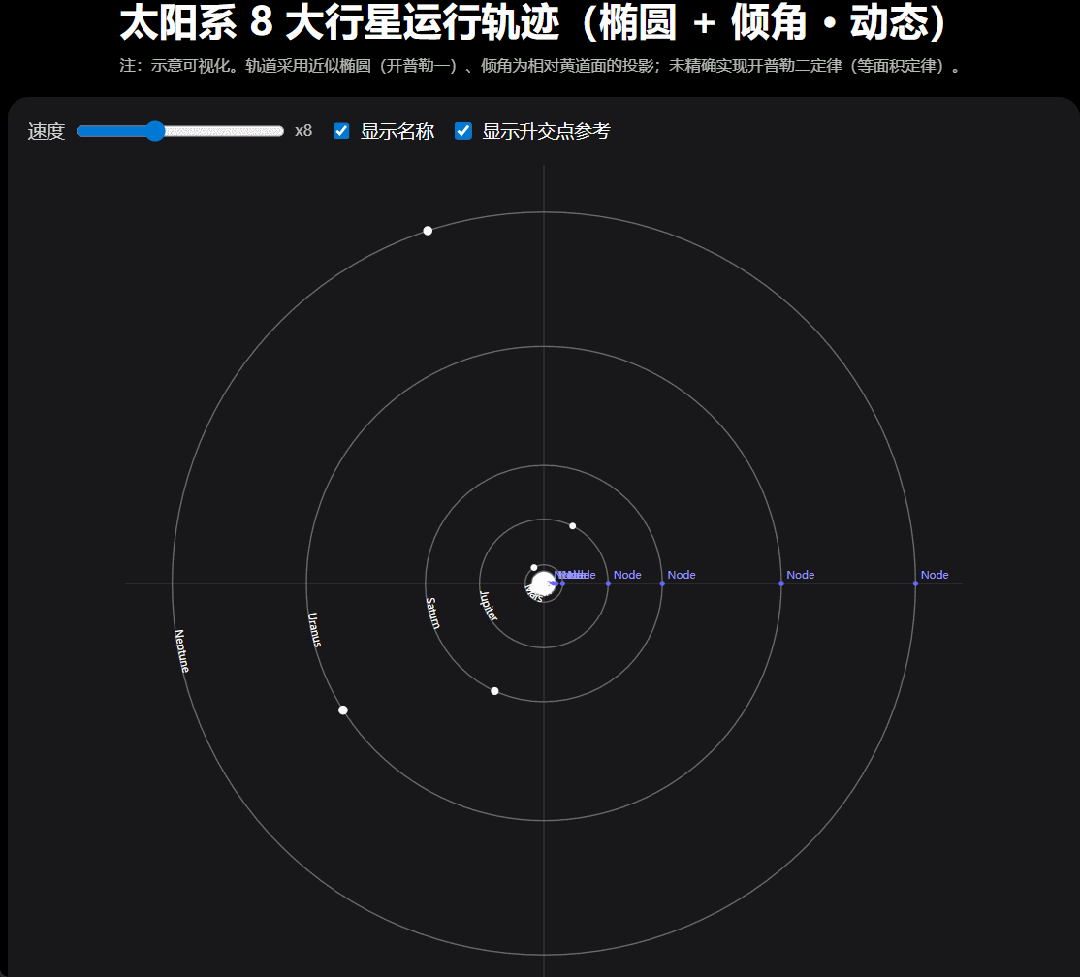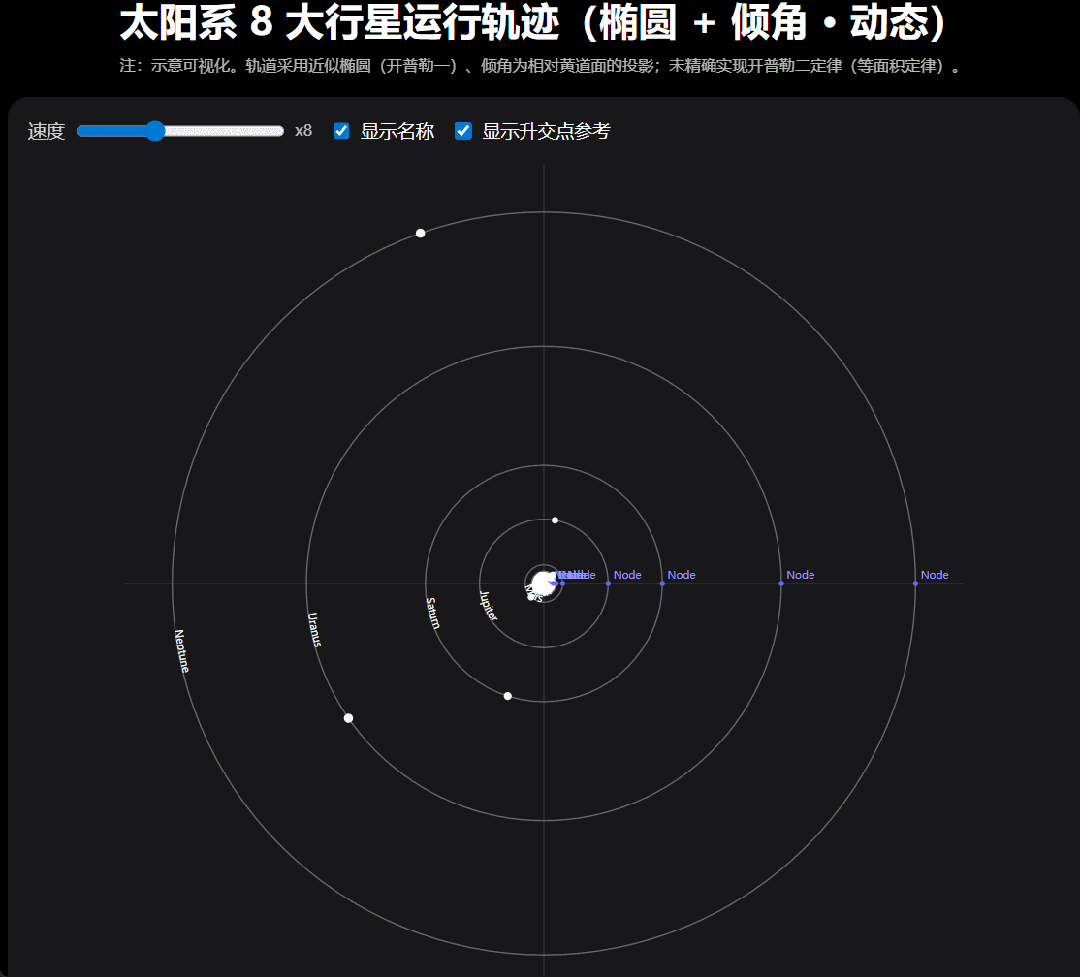
还是考验编程能力 「太阳系 8 大行星运行轨迹图,动态的。 」我们提出要求,GPT-5 嗖嗖的就把代码写好了。你可以下载代码,也可以在画布中直接运行。

运行结果是这样的,我们还可以调节行星的运行速度。

我们注意到,GPT-5 在这个项目完成之后会继续追问要不要在优化,然后,我们按照给出的优化方向「 做成更真实的椭圆轨道和轨道倾角。」结果如下:
GPT-5 开发小游戏如何呢?我们给出提示:帮我做一个俄罗斯方块的游戏 。
接到指令后,GPT-5 开始写代码,一串长长的代码:
运行结果如下:

再来一个物理测试:「一个球在旋转的六边形内弹跳。 小球应受到重力和摩擦力的影响,而且必须真实地从旋转的墙壁上弹起。」

可视化结果如下,拖动不同按钮,小球轨迹也随之改变。

接下来我们提出要求「创建一个高度逼真的物理布料模拟,模拟不同材质(棉、丝绸、皮革、橡胶等)在风力、重力和碰撞作用下的动态行为。 」不知为何,一开始 GPT-5 生成的程序不能运行,然后 GPT-5 自行检查了一遍,程序可以运行了,但是结果……

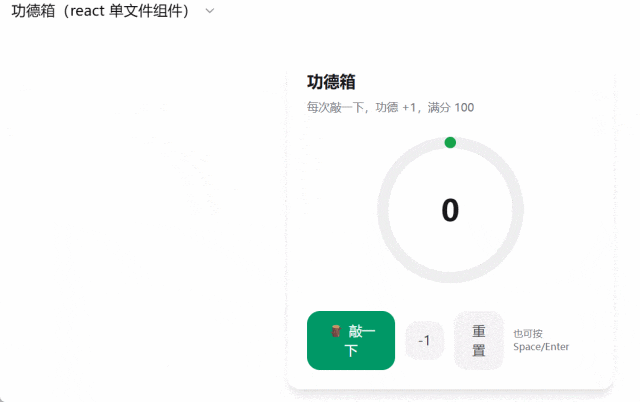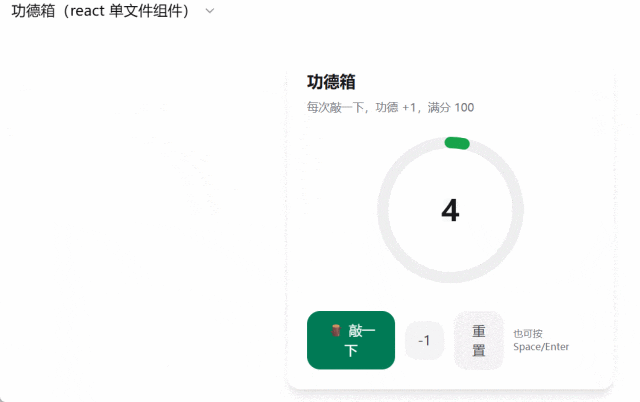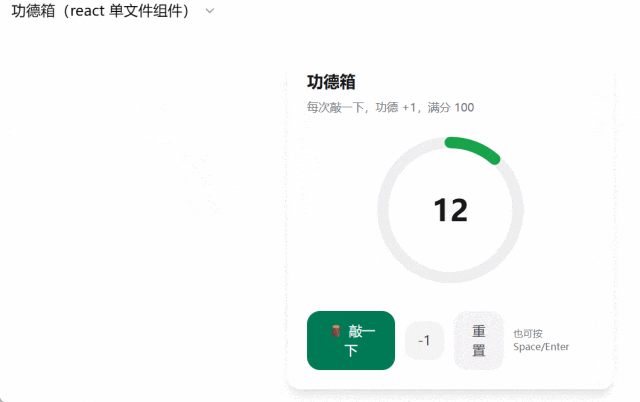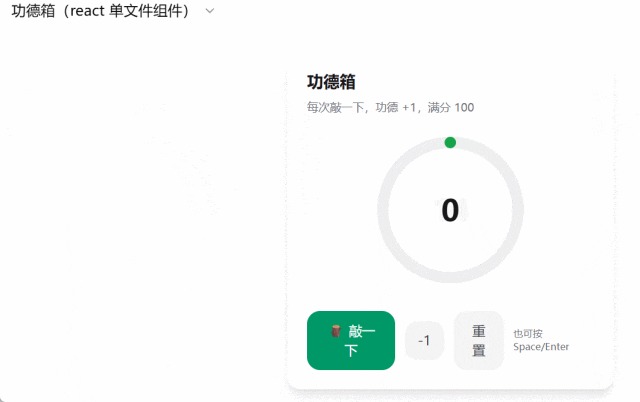
「做一个功德箱,每次敲一下,功德加一,满分 100 分 」。功能是实现了,但操作界面着实有些简单糊弄。
我们继续输入提示词:Code simulation of water in a bucket that is rocking back and forth.(编写模拟水桶中的水来回摇晃的代码),GPT-5 又罢工了。
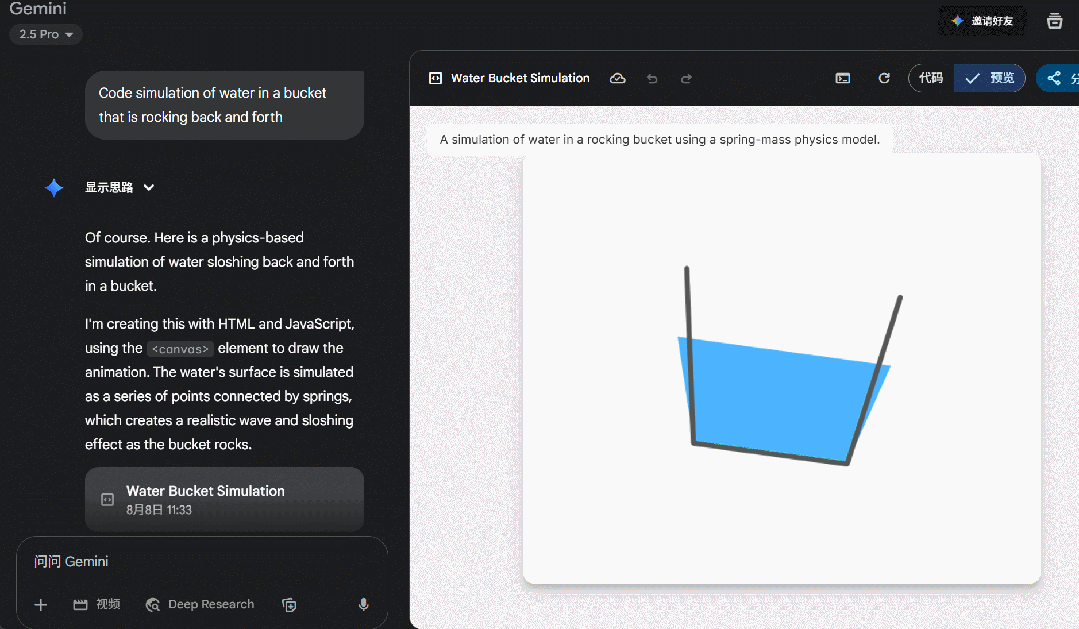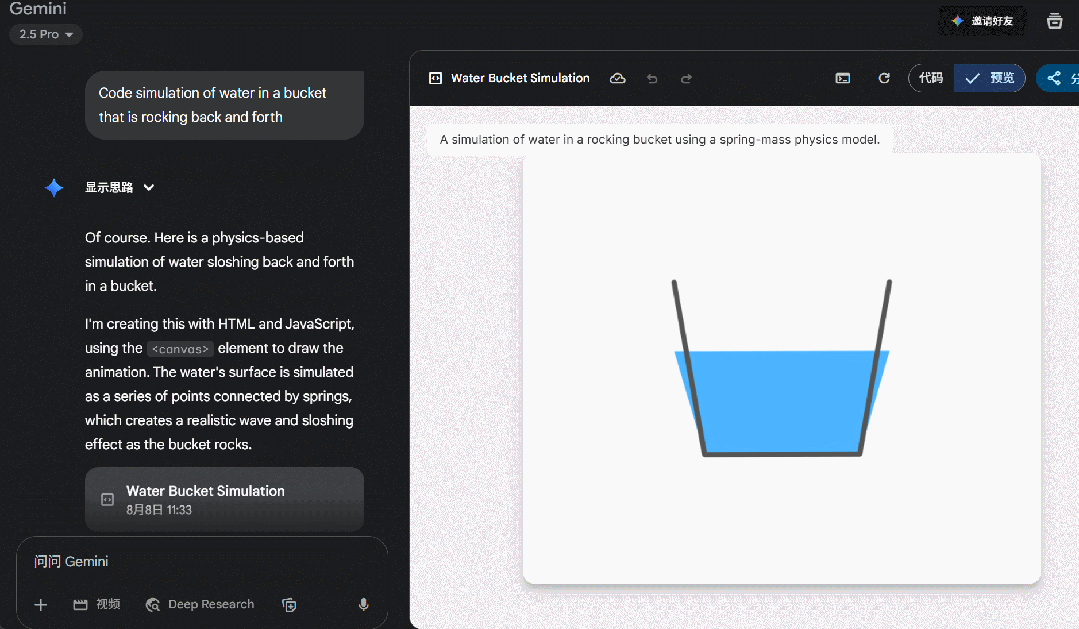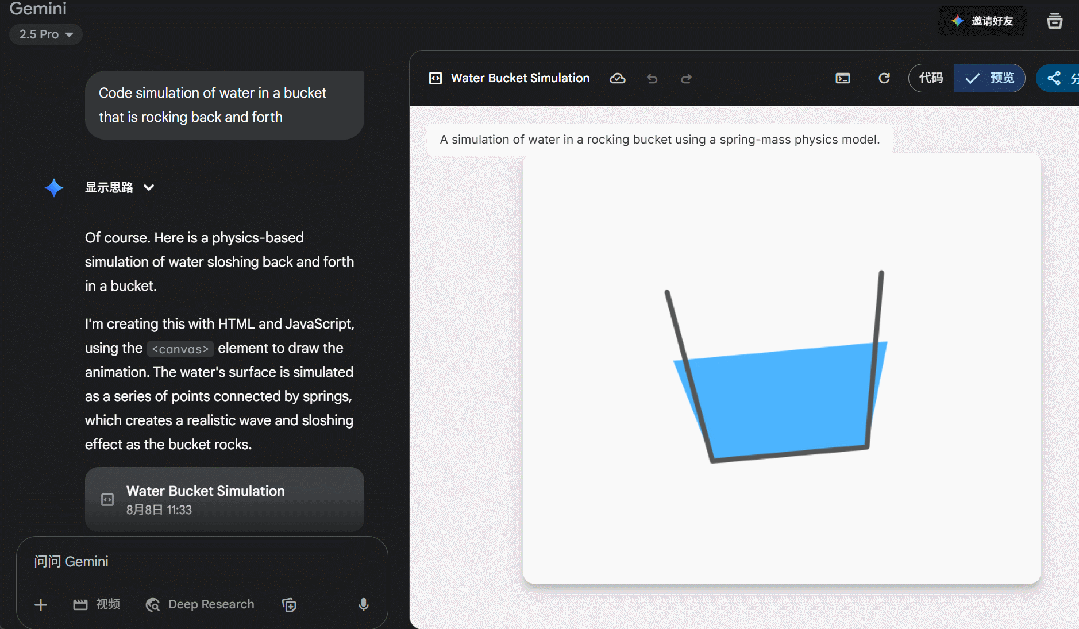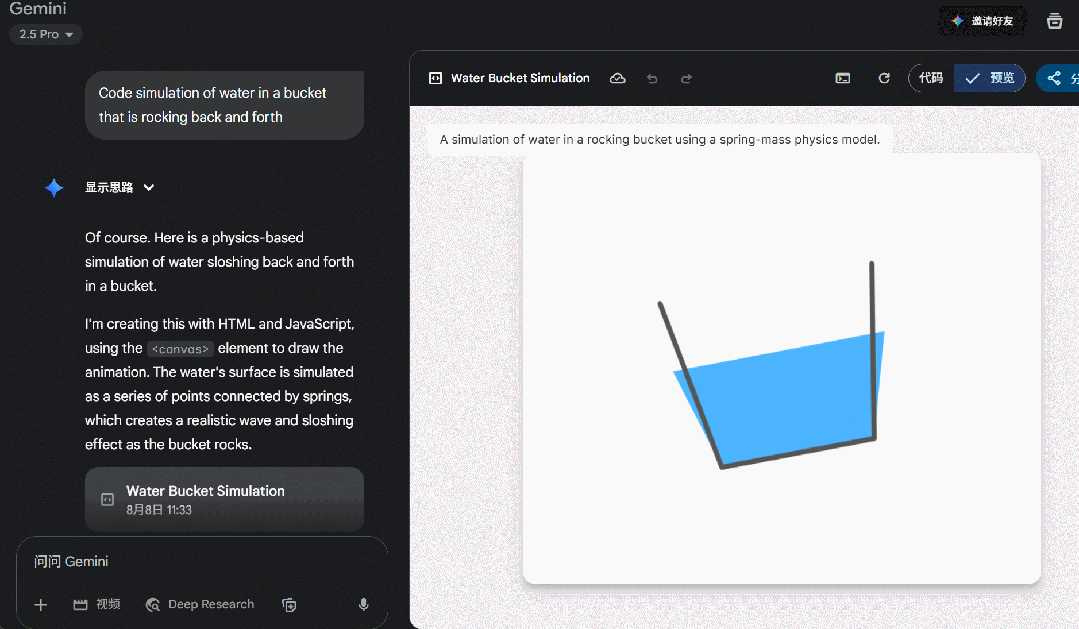
但相同的提示词发给 Gemini 2.5 Pro,虽然生成的效果也一般,但起码能呈现出一个可视化效果。
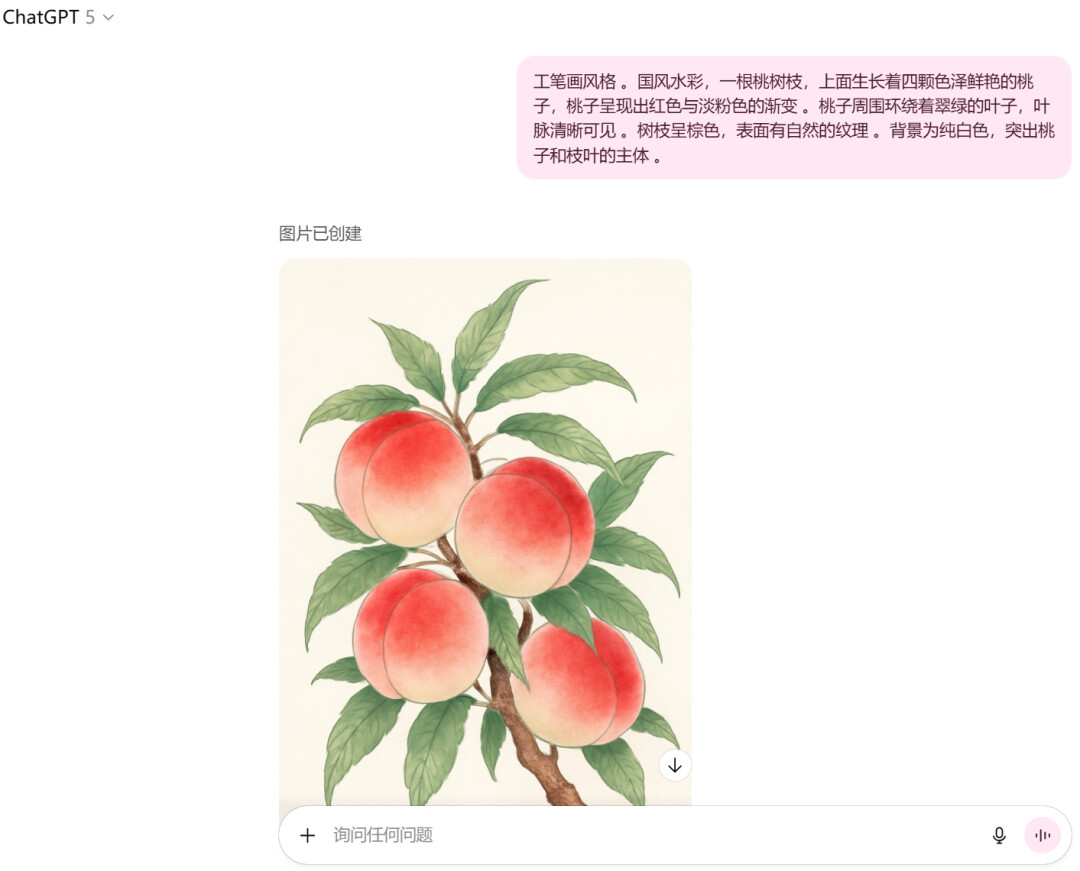
我们还试了下 GPT-5 生成图片功能,让它生成一幅桃树的工笔画,效果还是不错的。
我们测评了一圈,实话实说,GPT-5 的表现着实不稳定。
在写作能力方面,它表现出一定的文学性,但在细节和情感捕捉上稍显生硬,幽默感也不足;经典的「木棍过城门」的题目,它仍然做不对,这也表明其推理能力仍有提升空间。
在编码能力方面,GPT-5 的表现不一,虽然在一些简单任务中(如生成天气卡片的 HTML 代码)有所进展,但在更复杂的任务(如使用 p5.js 生成动画时)表现出明显的不足,尤其是生成的结果未能正确呈现出预期效果,甚至直接罢工。
这也难怪网友吐槽:还我 GPT-4.5!
参考链接:
https://x.com/vasumanmoza/status/1953531950137815374
https://x.com/apples_jimmy/status/1953517411862282330
https://x.com/emollick/status/1953502029126549597
https://x.com/petergyang/status/1953633559387984179
https://x.com/lmarena_ai/status/1953504958378356941
大家还有什么想测的,欢迎评论区留言。