SWE-Swiss:小尺寸模型达到代码修复SOTA,配方和模型已开源。
原文标题:北大、字节跳动联手发布SWE-Swiss:一把修复代码Bug的「瑞士军刀」,完整配方直指开源SOTA
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章提到自动化解决真实软件问题是个大挑战。SWE-Swiss现在能修bug,但像软件架构设计、复杂需求分析这些更“高级”的活儿,你觉得AI啥时候能挑起来大梁,甚至有没有可能?
3、SWE-Swiss把模型和数据都开源了,这对我们普通开发者或者小团队来说,除了研究意义,还有啥实际用处没?比如能直接拿来干点啥,或者能省多少钱省多少事儿?
原文内容

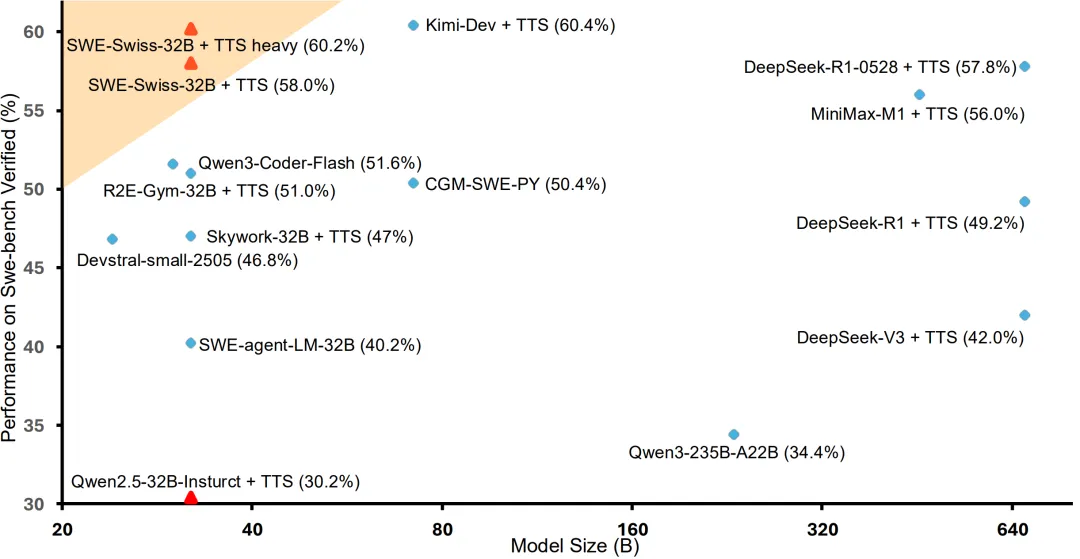
图 1: SWE-bench Verified 上的性能与模型尺寸对比。该研究的 32B 模型 SWE-Swiss,取得了 60.2% 的顶级分数,与更大的模型如 Kimi-Dev, DeepSeek-R1-0528 处于同一梯队。这证明了该研究的训练配方能让一个小得多的模型达到同样的 SOTA 性能级别,凸显了其卓越的效率。
近日,一项由北京大学、字节跳动 Seed 团队及香港大学联合进行的研究,提出了一种名为「SWE-Swiss」的完整「配方」,旨在高效训练用于解决软件工程问题的 AI 模型。研究团队推出的 32B 参数模型 SWE-Swiss-32B,在权威基准 SWE-bench Verified 上取得了 60.2% 的准确率,在同尺寸级别中达到了新的 SOTA。该工作证明,通过精巧的方法论设计,中等规模的模型完全有能力实现顶级性能,为 AI 在软件工程领域的应用提供了新的思路。为促进社区发展,该研究的模型、数据集将全部开源。

-
GitHub 地址: https://github.com/zhenyuhe00/SWE-Swiss
-
Hugging Face 模型和数据: https://huggingface.co/SWE-Swiss
引言:软件工程 AI 的挑战与机遇
自动化解决真实世界的软件问题,是大型语言模型(LLM)面临的一项艰巨挑战。相较于纯粹的代码生成,这项任务要求模型具备理解复杂上下文、定位问题、生成修复并进行验证的综合能力。现有框架(如 Agentless)已证明,将此复杂任务分解为结构化工作流是一条可行的路径。然而,如何高效地训练一个模型以精通所有环节,是当前研究的核心问题。
本项工作提出的 SWE-Swiss 配方,正是为了解决这一问题。其核心原则是,通过对软件工程中的核心能力进行显式建模和训练,来构建一个功能强大且高效的问题解决模型。
方法概览:结构化的「SWE-Swiss 配方」

图 2: 由三个核心能力驱动的 LLM 补丁生成流程图示。模型首先利用问题描述和代码库结构进行代码定位和测试生成,随后修复模块利用定位和检索到的文件生成补丁,最后所有生成的测试和已有测试被用来过滤和验证最终的补丁。
SWE-Swiss 配方将问题解决流程解构为三项核心技能:
-
代码定位 (Localization): 准确识别需要修改的文件。
-
代码修复 (Repair): 生成能解决问题的正确代码补丁。
-
单元测试生成 (Unit Test Generation): 创建单元测试以验证修复的有效性。
为确保训练数据的质量,研究团队采用验证性拒绝采样的来构建数据集。该过程首先生成大量候选数据,随后通过严格的、基于测试的自动化验证流程进行筛选,只保留被成功验证的样本用于模型微调
两阶段训练方法
SWE-Swiss 的训练分为两个主要阶段:
-
第一阶段:通过多任务 SFT 构建基础能力
此阶段将上述三种技能共 10,254 个高质量样本混合,对 Qwen2.5-32B 模型进行监督微调。这使得模型能够对整个问题解决流程建立全面的基础理解。完成此阶段后,模型在未进行测试时扩展的情况下,取得 36.0% 的基准性能。
-
第二阶段:通过两阶段 RL 精通核心技能
在 SFT 模型的基础上,此阶段专注于通过强化学习提升最关键的「修复」能力。受 POLARIS 的启发,团队设计了
两阶段 RL 课程:首先,模型在完整数据集上训练 200 步以建立广泛能力;随后,通过基于性能的剪枝,移除模型已掌握(准确率 > 90%)的简单样本,让模型在接下来的 90 步训练中专注于更具挑战性的难题。
这一阶段效果显著,在单补丁生成模式下,模型性能从 36.0% 跃升至 45.0%。
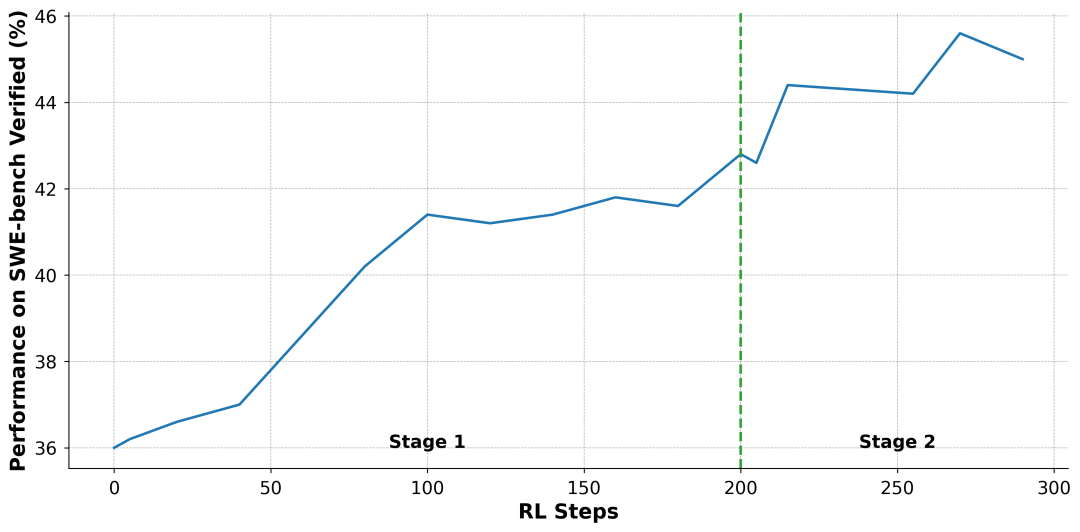
图 3: 两阶段强化学习过程中的性能提升曲线。第一阶段(0-200 步)显示了在完整数据集上训练的稳定提升。第二阶段(200 步之后)则是在过滤后更具挑战性的数据集上继续训练,带来了进一步的性能增益。
测试时扩展
在评估阶段,类似 Agentless 和 Agentless Mini,SWE-Swiss 采用多补丁生成与过滤的策略。在自我一致性 (self-consistency) 的基础上,团队提出了一种「增强自我一致性 (Enhanced Self-consistency)」的最终选择方法。
传统的自洽性方法依赖于代码的「完全一致」匹配,这在语法细节多样的代码场景下存在漏洞。增强自我一致性则通过引入相似度度量,不仅奖励与最多数完全相同的候选者,也奖励那些处在「相似解决方案」密集区域的候选者。该方法的最终评分为:
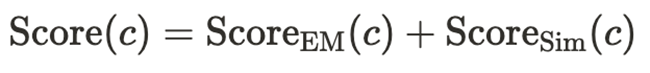
其中,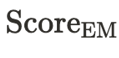 为精确匹配的频率计数,而 为与 top-k 个最相似邻居的平均相似度得分。
为精确匹配的频率计数,而 为与 top-k 个最相似邻居的平均相似度得分。
图 4: SWE-Swiss-32B 的测试时扩展性能,增强自我一致性在 120 个补丁时达到了 60.2% 的准确率。
结论与开源
本项研究工作的核心贡献在于提出并验证了一套完整的、高效的 SWE-Swiss「配方」。实验证明,该配方能够使一个 32B 的中等规模模型和更大的模型相媲美。从 SFT 后的 36.0%,到 RL 后的 45.0%,再到结合测试时扩展和增强自洽性的最终 60.2%,这一系列的性能提升清晰地展示了配方中每一个环节的价值,为业界提供了一条通过优化大模型软件工程能力的有效路径。
该团队将开源 SWE-Swiss-32B 模型、全部训练数据,以期为社区的后续研究提供支持。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com