人大高瓴-华为诺亚团队系统构建大模型智能体记忆机制研究体系,涵盖理论综述、评测数据与榜单、以及统一工具包,全方位助力LLM智能体发展。
原文标题:人大高瓴-华为诺亚:大语言模型智能体记忆机制的系列研究
原文作者:机器之心
冷月清谈:
首先,在记忆机制的综述(TOIS'25)中,研究团队深入探讨了智能体记忆的定义(狭义与广义)、为何需要记忆(从认知心理学、自我进化及应用场景三个维度阐述),并系统梳理了现有记忆的实现方式(按来源、形式、操作分类)及评测方法(直接与间接)。文章还列举了记忆如何增强智能体在角色扮演、个人助理、开放世界游戏、代码生成、推荐系统和领域专家系统等领域的应用,并展望了未来的研究方向。
接着,团队在记忆机制的评测方面进行了深入工作。2024年9月,发布了用户事实性记忆评测框架 MemSim,并基于此构建了智能助手场景下的评测数据集 MemDaily。该框架利用贝叶斯关系网络构造用户画像,生成多样化的问答类型和用户消息,用于评估记忆的有效性和效率。此外,MemDaily 已支撑华为鸿蒙系统级AI助手小艺的能力评测。在此基础上,2025年2月,团队进一步推出了更全面的评测榜单 MemBench(ACL'25 Findings)。MemBench 从观测和参与两个场景,以及事实和反思两种记忆类型出发,对智能体记忆的准确率、召回率、容量和效率进行了多维度评估,尤其引入了对记忆容量限制的探讨。
最后,为推动领域发展和方便开发者实现,团队于2024年12月推出了智能体记忆机制的统一模块化工具包 MemEngine(TheWebConf'25 Resource)。MemEngine 提供了分层框架,内置了9种前沿记忆方法,支持便捷的扩展开发和用户友好的本地及远程部署,并兼容主流智能体平台。这套系统性的工作为理解、评估和构建具备强大记忆能力的大语言模型智能体奠定了坚实基础。该系列研究为大模型智能体记忆领域提供了从理论梳理到工具实践的完整解决方案。
怜星夜思:
2、文章提及了记忆的评测,比如准确率、容量等。但智能体的“记忆”毕竟跟人类的记忆不同,人类的记忆有时是模糊的、甚至是错误的,并且会遗忘。那么,在评测智能体记忆时,我们是否应该考虑这些“类人”的复杂性?简单追求百分百的准确和无限容量,是不是有点脱离实际了?
3、文章强调记忆对于智能体个性化的重要性。联想到现在市面上有很多AI伴侣或者个人助理,它们是怎么通过记忆来塑造独特的“人格”或者服务风格的?仅仅是记住用户的喜好就够了吗?这背后还有哪些技术难点或者伦理考量吗?
原文内容

本系列工作第一作者张泽宇,中国人民大学博士生,研究方向为大语言模型智能体的记忆机制和个性化;谭浩然,中国人民大学硕士生,研究方向为大语言模型智能体。陈旭,中国人民大学预聘副教授,研究方向包括大语言模型,信息检索等。
近期,基于大语言模型的智能体(LLM-based agent)在学术界和工业界中引起了广泛关注。对于智能体而言,记忆(Memory)是其中的重要能力,承担了记录过往信息和外部知识的功能,对于提高智能体的个性化等能力至关重要。中国人民大学高瓴人工智能学院与华为诺亚方舟实验室聚焦大语言模型智能体的记忆能力,在该领域的研究早期,形成了一套完整的包括综述论文、数据集和工具包的研究体系,致力于推动该领域的发展。
智能体记忆机制的早期综述
(TOIS'25)

-
论文标题: A Survey on the Memory Mechanism of Large Language Model based Agents
-
论文链接: https://dl.acm.org/doi/10.1145/3748302
在 2024 年 4 月,团队完成了早期的关于智能体记忆机制的综述。该综述从不同角度对智能体的记忆进行了全面讨论。该综述讨论了「什么是智能体的记忆」和「为什么智能体需要记忆」,总结回顾了「如何实现智能体的记忆」和「如何评测智能体的记忆能力」,归纳整理了「记忆增强的智能体应用」,并提出当前工作存在的局限性和未来方向。通过该综述,团队希望能够为研究者带来启发和讨论,推动大语言模型智能体领域的发展。
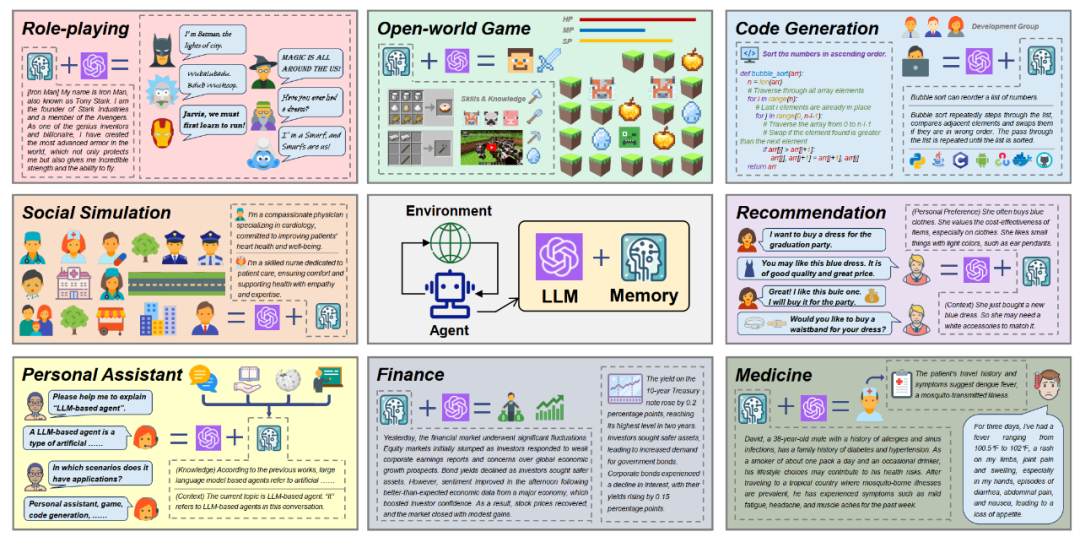
什么是智能体的记忆?
对于智能体的记忆,从记忆内容的来源出发,团队提出了狭义和广义两种记忆概念:
-
狭义记忆: 记忆是智能体在进行本次任务时与环境交互的历史信息。
-
广义记忆: 记忆除了包括智能体在本次任务进行时与环境的交互信息,还包括此前完成该类任务的经验,以及外部知识。
为什么智能体需要记忆?
为了更好地阐述记忆对智能体的重要性,团队从认知心理学、智能体的自我进化和智能体的应用三个角度进行讨论。
-
认知心理学角度: 为了更好地让智能体完成任务,智能体的设计往往需要借鉴人类的思维特点。而记忆对于人类而言,在知识学习、概念提取、价值观孵化、社会规范形成和文化萌芽等方面具有重要作用。
-
智能体的自我进化: 在智能体与环境的交互过程中,记忆承担了经验积累、环境探索和知识提取的作用,使智能体能够在于环境的动态交互过程中不断自我进化。
-
智能体的应用: 在智能体的实际应用中,记忆对于语境连贯、角色定位和领域知识积累等方面具有关键作用。
团队从记忆的来源、记忆的实现形式和记忆的操作三个角度,分别对现有的智能体记忆实现方法进行分类和讨论。
如何实现智能体的记忆?
从记忆的来源角度出发,团队将现有工作分为三类来源,这种分类与上文中「广义记忆」的三部分记忆内容来源相对应。
-
Inside-trial Information: 智能体在进行本次任务时与环境交互的历史信息。
-
Cross-trial Information: 智能体在此前完成该类任务的历史经验信息。
-
External Knowledge: 智能体在当前交互环境之外所获得的信息。
从记忆的实现形式角度出发,团队将现有工作分为文本形式(Textual Form)和参数形式(Parametric Form)两种实现形式,不同的形式有各自的实现方法。
-
文本形式记忆: 本质上是用显式(Explicit)的方法表示记忆。在文本形式的记忆中,可以通过完全信息记忆、最近信息记忆、检索信息记忆和外部工具信息记忆四类方法来实现智能体的记忆机制。
-
参数形式记忆: 本质上是用隐式(Implicit)的方法。在参数形式的记忆中,可以通过模型微调和记忆编辑两类方法来实现智能体的记忆机制。
从记忆的操作角度出发,团队将现有工作按照记忆写入、管理和读取三个重要操作进行总结。
-
记忆写入: 智能体将重要的信息写入记忆存储,作为未来的推理和决策依据。在记忆写入时,既可以写入原始信息,也可以对其进行总结提取,或同时记录辅助信息。
-
记忆管理: 智能体将写入的记忆进行管理与加工,例如记忆合并、记忆反思和记忆遗忘。
-
记忆读取: 智能体在决策时可以使用此前存储的相关记忆信息,来为决策提供更多信息与知识。
如何评测智能体的记忆?
团队将智能体记忆机制的评测分为直接评测和间接评测两类。
-
直接评测: 直接对单独的记忆模块进行评测,包括主观评测和客观评测。
-
间接评测: 在智能体的实际应用中进行端到端的评测,通过不同记忆机制对相同智能体任务产生的性能影响,间接反映出各个记忆机制的能力。
记忆增强的智能体有哪些应用?
记忆推动了智能体在各领域中的应用,而在各个应用场景中,记忆所承担的功能也各不相同。
-
角色扮演与社会模拟: 在角色扮演和社会模拟中,记忆赋予了智能体不同的人格和自我感知,使他们能够按照人设执行动作,从而区分于其他的智能体角色。基于不同的人格,它们可以进一步交互形成模拟社会。
-
个人助理: 在个人助理中,记忆赋予了智能体记忆用户习惯和个性化需求的能力,使智能体能够提供个性化的帮助。此外,记忆可以基于上下文,帮助智能体更好地理解当前用户的需求。
-
开放世界游戏: 在开放游戏世界中,记忆赋予了智能体总结回顾过往经验的能力,从而用于智能体的后续探索。另外,来自外部信息的记忆可以为智能体提供更丰富的知识,提升其探索能力。
-
代码生成: 在代码生成和软件开发中,记忆赋予了智能体更丰富的开发知识。此外,借助过往记忆,智能体可以生成风格更加一致的代码,同时有利于基于上下文进行需求澄清。
-
推荐系统: 在推荐系统中,记忆赋予了智能体捕捉和维护用户个性化信息的能力,使它能够更深入地理解用户的个性化需求,从而提供更符合用户需求的推荐结果。
-
领域专家系统: 在领域专家系统中,记忆赋予了智能体丰富的领域知识。此外,记忆有利于提升知识的时效性,克服知识过时的问题。
局限性与未来方向
最后,团队进一步讨论了当前智能体记忆机制工作的局限性和未来方向,包括参数化记忆机制、多智能体记忆机制、记忆机制与终身学习和类人智能体的记忆机制。
智能体记忆机制的早期评测-MemSim

-
论文标题: MemSim: A Bayesian Simulator for Evaluating Memory of LLM-based Personal Assistants
-
论文链接: https://arxiv.org/abs/2409.20163
-
代码仓库: https://github.com/nuster1128/MemSim
在 2024 年 9 月,团队进一步地对智能体记忆机制的评测方法进行了探究。团队聚焦智能助手场景,提出了对用户事实性记忆的评测数据构造框架 MemSim,并构建了评测数据 MemDaily。基于 MemDaily,团队对常用的智能体记忆方法进行了评测和分析。
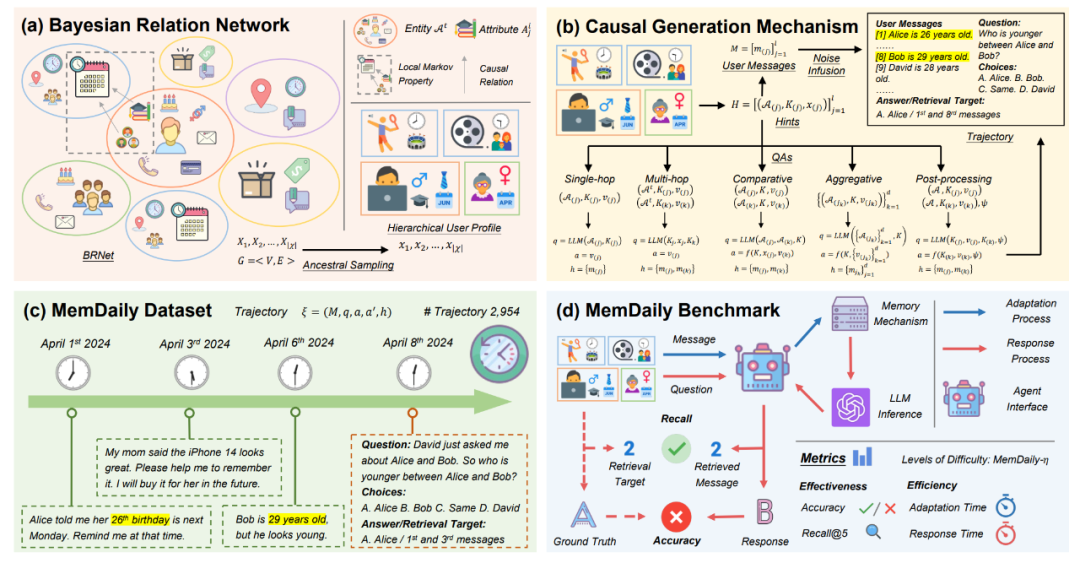
用户事实性记忆评测数据构造
相比于世界知识,用户事实性记忆主要来源于不同个体,由智能体与用户个体交互而获得,因此也是评测智能助手记忆的关键。团队提出了 MemSim 框架,用以构建用户事实性记忆的评测数据。团队首先提出了贝叶斯关系网络,构造了表征用户画像概率分布的元用户画像,包含属性层次和实体层次,并由此采样出不同的用户画像。
然后,团队基于不同实体与属性之间的关系,构造了多种形式的问答,包括单跳、多跳、比较、聚合和后处理等问答类型,以贴近真实场景下的用户问答。对于用户消息,团队基于采样属性中的答案和噪声构造事实信息元组,并借助大模型的文本组织能力,生成得到流畅且包含特定信息的用户消息。基于 MemSim 框架,团队在日常生活场景下生成了数据集 MemDaily。
MemDaily 数据评估
团队对 MemDaily 数据进行了评估,其中包括用户画像构建的质量,用户消息构造的质量和问答的质量。对于用户画像,关注其合理性和多样性;对于用户消息,侧重于它的流畅性、合理性、自然性、信息性和多样性;对于问答的质量,着重评估它对于文本答案、选择答案和检索目标的正确性。
记忆机制评测
基于 MemDaily,团队对目前常用的几种记忆机制进行了对比评测,并进一步融入了不同程度的噪声,以扩展记忆文本的总量,从而提供不同难度的评测数据集。团队对记忆的有效性和效率进行了评测。其中,记忆有效性的指标主要包括问答的准确率和检索目标的召回率,记忆效率的指标主要包括调整时间和推理时间。实验表明,不同模型的性能与问答类型和记忆文本的总量有关,因此,不同模型适用于不同类型的任务。值得提及的是,MemDaily 数据也支撑了华为鸿蒙系统级 AI 助手小艺的记忆相关特性的能力评测。
智能体记忆机制的评测榜单-MemBench
(ACL'25 Findings)

-
论文标题: MemBench: Towards More Comprehensive Evaluation on the Memory of LLM-based Agents
-
论文链接: https://arxiv.org/abs/2506.21605
-
代码仓库: https://github.com/import-myself/Membench
2025 年 2 月,在 MemSim 的基础上,团队进一步构建了智能体记忆机制的评测榜单。团队同样聚焦于智能助手场景,提出从观测和参与两个角度,对智能体的反思和事实两种记忆类型进行评测,涵盖了记忆的有效性、效率和容量评估。
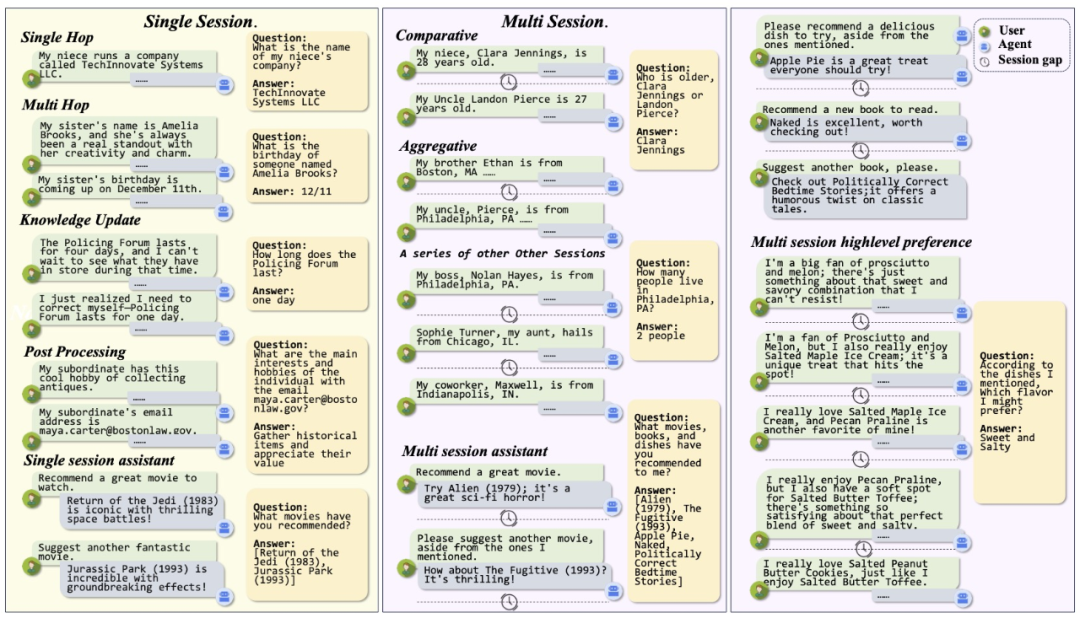
多场景记忆视角
在参与场景中,智能体与用户进行互动,而在观测场景中,智能体仅作为观察者,记录用户输入的消息。在参与场景中,智能体执行其他模块如推理动作模块,从而和用户发生交互,并改变记忆模块记忆的内容;在观测场景中,智能体不会执行除了记忆之外的任何模块,只接受用户单方面的信息输入。
多层次记忆数据
团队在 MemDaily 构建的事实记忆基础上扩展了问答的类型,增加了例如知识更新等问答类型。同时,团队新增了偏好和情感两种记忆内容,分别评估智能体反思记忆能力。相较于用户向智能体直接表达出的事实记忆,反思记忆需要根据用户表达的低层次内容,从对话中提取并总结高层次的偏好,包括一些事实属性。
多维度记忆评测
基于构建的数据集,论文从记忆的准确率、召回率、容量和效率对现有常见的多种记忆机制进行了评测。其中,团队认为智能体的记忆机制可能存在容量限制,当记忆内容的量达到一定程度时,准确性会急剧下降,这一临界值代表了记忆的容量。
智能体记忆机制的工具包-MemEngine
(TheWebConf'25 Resource, Oral/Top 10)

-
论文标题: MemEngine: A Unified and Modular Library for Developing Advanced Memory of LLM-based Agents
-
论文链接: https://dl.acm.org/doi/10.1145/3701716.3715299
-
代码仓库: https://github.com/nuster1128/MemEngine
2024 年 12 月,团队实现了智能体记忆机制的早期工具包 MemEngine。近年来,虽然一些近期的工作提出了不同的智能体记忆机制,但它们缺少统一框架下的实现方案。
为此,团队提出了统一的智能体记忆机制框架,并设计了模块化的工具库 MemEngine,用于便捷地实现和使用不同的智能体记忆机制。MemEngine 实现了近期研究中的记忆机制方法,设计了便捷开发与可扩展的模块,并提供了丰富且用户友好的使用方式。
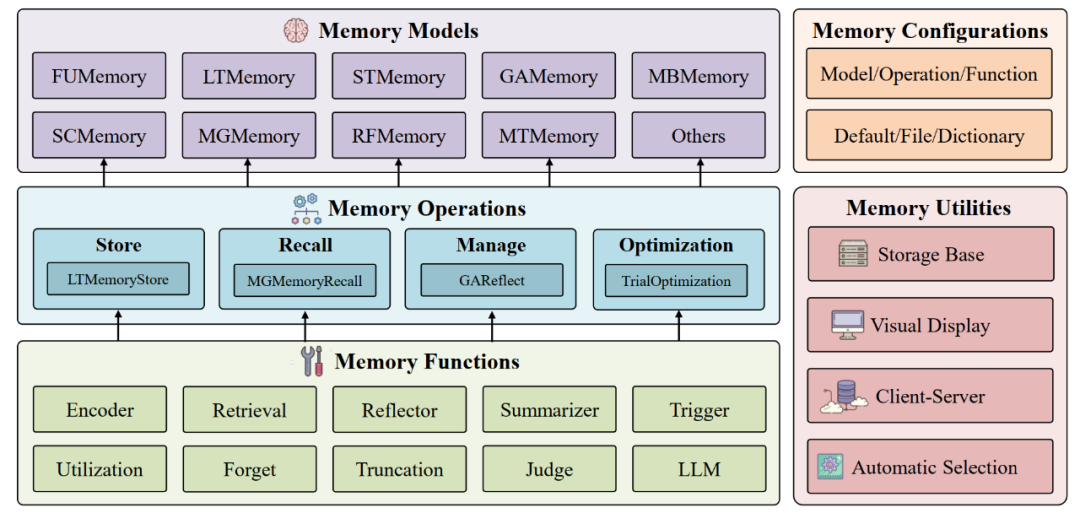
统一模块化的记忆框架
团队提出了一个统一模块化的记忆框架,该框架包含三个层次:最底层为基础的功能方法,如检索、总结等;中间层为记忆操作,包含记忆的存储、召回等;最高层为具体的记忆方法,如 MemoryBank、MemGPT 等。在框架中,高层的模块可以组合复用低层模块,从而提高实现效率。此外,MemEngine 还提供了配置模块和工具模块,辅助研究者和开发者进行探究和部署。
丰富的内置记忆方法
基于上述统一模块化的记忆框架,团队实现了 9 种近期研究工作中常用的记忆方法,如 MemoryBank,MemGPT 等。基于 MemEngine 的统一框架,这些方法之间可以无缝切换,从而更便捷地适配于具体应用。
便捷扩展的记忆开发
基于模块化架构,研究者可通过三级扩展机制快速实现记忆方法的创新:在最底层扩展基础功能,如可新增多模态编码器;在中间层扩展记忆操作,如可实现不同的反思操作;在最高层基于现有模块构建新型记忆模型。MemEngine 提供了完整开发文档与代码示例,支持从基础功能定制到模型级创新的全流程开发。开发者可继承基础类实现个性化功能,或通过配置模块快速验证不同参数组合,显著降低新记忆方法的实现门槛。
用户友好的记忆部署
MemEngine 提供本地与远程双部署模式:本地支持 pip 安装与源码集成,远程可通过 API 调用记忆服务。提供默认、可配置、自动三种使用模式:默认模式开箱即用;配置模式支持动态调整提示词等参数;自动模式可根据任务类型自动搜索记忆模型与参数组合。框架兼容 AutoGPT 等主流智能体平台,满足从学术研究到工业落地的多样化需求。
北京时间 8 月 7 日 18:00-19:00,我们邀请到了本系列工作第一作者张泽宇为大家分享《大语言模型智能体的记忆机制》,欢迎关注预约。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com