首个系统综述揭秘离散化技术,为多模态大模型搭建统一桥梁。
原文标题:Discrete Tokenization:多模态大模型的关键基石,首个系统化综述发布
原文作者:机器之心
冷月清谈:
怜星夜思:
2、码本坍塌听起来是个挺严重的问题,它具体会对多模态大模型的表现带来哪些实际影响?比如,会不会导致生成的图片模糊、语音失真,或者模型难以理解某些复杂的指令?除了文章里提到的解决方案,社区里还有没有其他比较新颖、有效的缓解方法?
3、文章提到了离散化技术能让大模型处理图像、音频、视频甚至推荐系统数据,这听起来太酷了!但如果所有的信息都能被统一成 token,未来我们在信息处理上可能会遇到什么新的伦理或隐私问题吗?比如,个人多模态数据被统一分析后,会不会更容易被推测出更多隐私?
原文内容

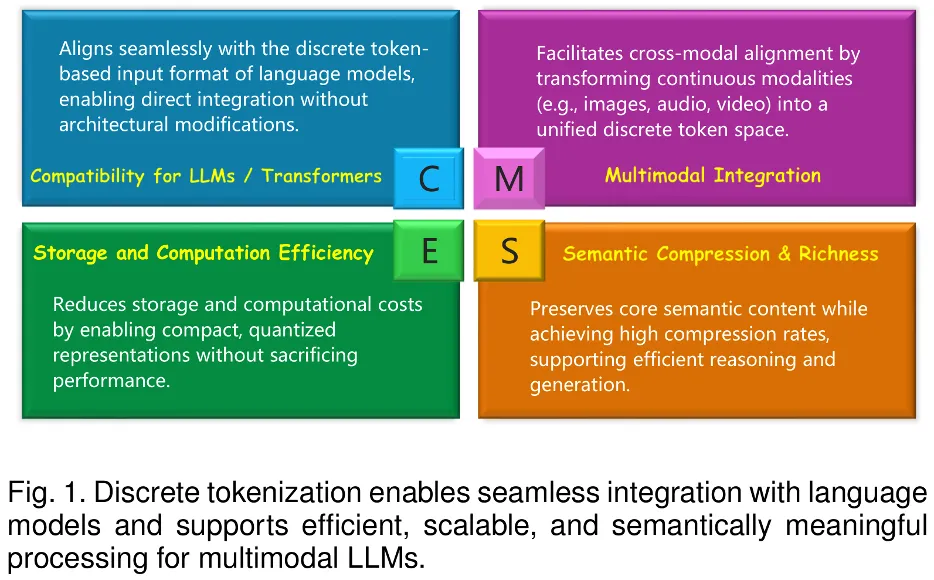
近年来,大语言模型(LLM)在语言理解、生成和泛化方面取得了突破性进展,并广泛应用于各种文本任务。随着研究的深入,人们开始关注将 LLM 的能力扩展至非文本模态,例如图像、音频、视频、图结构、推荐系统等。这为多模态统一建模带来了机遇,也提出了一个核心挑战:如何将各种模态信号转化为 LLM 可处理的离散表示。
在这一背景下,Discrete Tokenization(离散化)逐渐成为关键方案。通过向量量化(Vector Quantization, VQ)等技术,高维连续输入可以被压缩为紧凑的离散 token,不仅实现高效存储与计算,还能与 LLM 原生的 token 机制无缝衔接,从而显著提升跨模态理解、推理与生成的能力。
尽管 Discrete Tokenization 在多模态 LLM 中扮演着日益重要的角色,现有研究却缺乏系统化的总结,研究者在方法选择、应用设计与优化方向上缺少统一参考。为此,本文团队发布了首个面向多模态 LLM 的 Discrete Tokenization 系统化综述,系统地梳理技术脉络,总结多模态场景下的实践、挑战与前沿研究方向,为该领域提供全面的技术地图。

-
论文标题:Discrete Tokenization for Multimodal LLMs: A Comprehensive Survey
-
论文链接:https://arxiv.org/abs/2507.22920
-
论文仓库:https://github.com/jindongli-Ai/LLM-Discrete-Tokenization-Survey
-
发文单位:香港科技大学(广州),吉林大学,香港中文大学,南京大学,加州大学默塞德分校

此综述按照输入数据的模态与模态组合来组织内容:从早期的单模态与多模态 Tokenization 方法,到 LLM 结合下的单模态与多模态应用,逐步构建出清晰的技术全景。这种结构既反映了方法的演进路径,也方便读者快速定位自己关心的模态领域。
方法体系:八大类核心技术全景梳理
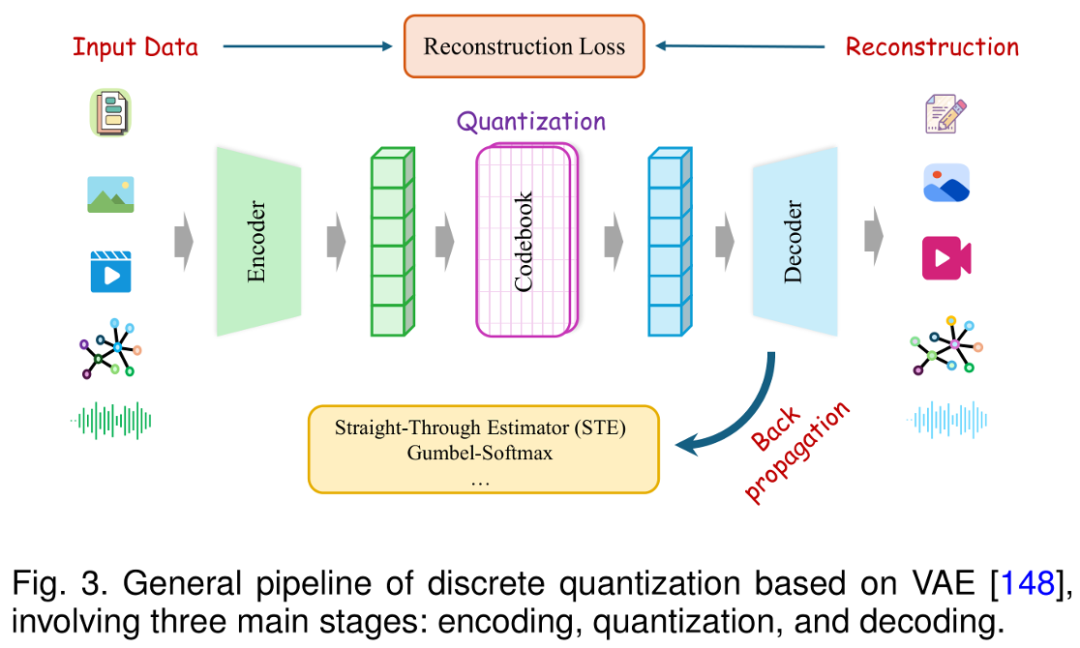
此综述首次系统性地整理了八类 Vector Quantization 方法,覆盖从经典方法到最新技术变体,并剖析了它们在码本构建、梯度传播、量化实现上的差异。
八类方法包括:
-
VQ(Vector Quantization):经典码本设计与更新机制,结构简单、便于实现;
-
RVQ(Residual Vector Quantization):多阶段残差量化,逐步细化编码精度;
-
PQ(Product Quantization):乘积量化,子空间划分与独立量化;
-
AQ(Additive Quantization):加性量化,多码本叠加建模,增强表达能力;
-
FSQ(Finite Scalar Quantization):有限标量量化,每个维度独立映射到有限标量集合,通过隐式码本组合实现离散化,无需显式存储完整码本,计算高效;
-
LFQ(Lookup-Free Quantization):去查表量化,每个维度通过符号函数直接离散化,无需显式存储完整码本;
-
BSQ(Binary Spherical Quantization):球面二值量化,单位球面上进行离散化,无需显式码本;
-
Graph Anchor-Relation Tokenization:面向图结构的锚点 - 关系离散化,降低存储与计算开销。
不同方法在编码器训练、梯度传递、量化精度等方面各具特点,适用于不同模态与任务场景。
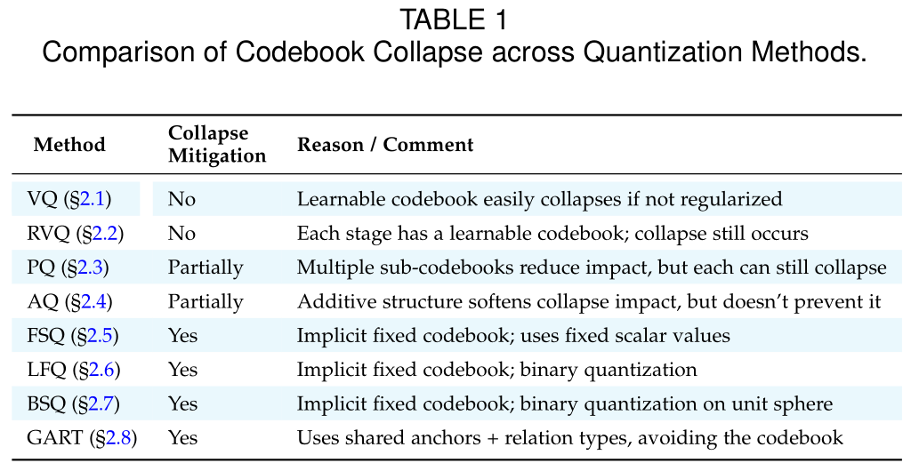
方法挑战:码本坍塌(Codebook Collapse)
在多种 VQ 方法实践中,码本坍塌是影响性能的核心问题之一。它指的是在训练过程中,码本的有效向量逐渐收敛到极少数几个,导致码本利用率下降、表示多样性不足。
常见解决思路包括:
-
码本重置(Code Reset):对长期未使用的码字进行重新初始化,使其靠近活跃码字,从而提升利用率;
-
线性再参数化(Linear Reparameterization):通过线性变换优化码字分布,并为未使用码字引入可学习参数,保持其活跃状态;
-
软量化(Soft Quantization):将输入表示为多个码字的加权组合,平衡不同码字的使用频率,防止过度集中在少数码字;
-
正则化(Regularization):引入熵正则、先验分布约束或 KL 正则等机制,提高码本利用率并避免表示空间坍缩。
缓解码本坍塌对于提升 Discrete Tokenization 在多模态 LLM 中的稳定性与泛化能力至关重要。
早期 Tokenization
在 LLM 出现之前,Discrete Tokenization 已经在多个深度学习任务中得到广泛应用,涵盖单模态场景与多模态场景。在这一阶段,它的主要作用是实现高效表示、压缩以及不同模态间的对齐。典型应用包括:
-
早期单模态任务:在图像任务中,Discrete Tokenization 常用于检索与合成,高效保留全局语义与关键细节;在音频任务中,它在编解码中作为稳定中间表示,兼顾压缩比与音质;在视频任务中,它实现帧级高效表示,支持可控生成与长时序建模;在结构化数据任务中,它将节点、边或交互序列映射为紧凑的离散表示,用于图表示学习与推荐系统。
-
早期多模态任务:在视觉 - 语言任务中,Discrete Tokenization 将视觉特征离散化,与文本 token 共享模型接口,实现描述生成与跨模态检索;在语音 - 文本任务中,它将连续语音离散化,与文本 token 对齐,支持语音识别、合成、翻译等互转;在跨模态生成任务中,它让视觉、音频、文本等模态能够统一输入到生成模型,完成多模态协同输出。
这一阶段的实践奠定了 Discrete Tokenization 在后续 LLM 时代广泛应用的技术基础,并为跨模态对齐和统一处理提供了早期经验。
LLM 驱动的单模态离散建模
LLMs 在生成、理解、泛化等任务中展现了强大的能力,使其成为建模非文本模态的理想骨干。在单模态任务中,Discrete Tokenization 被广泛应用于图像、音频、图、动作以及推荐系统等领域,通过将非文本模态编码为 LLM 可读的 token,Discrete Tokenization 实现了与语言 token 在同一空间下的融合。这些离散 token 作为桥梁,使 LLM 能够完成多类下游任务:
-
图像任务:通过离散 token 编码局部细节与全局语义,实现图像描述、生成与编辑;
-
音频任务:利用量化后的语音单元支持语音识别、语音合成等任务;
-
图结构任务:将节点与边离散化,支持节点分类、链接预测、图分类等结构化任务;
-
动作序列任务:对动作轨迹与控制信号进行离散化,便于 LLM 处理序列生成与预测;
-
推荐系统任务:将用户行为、商品属性等多类型非语言特征映射为统一 token,提升推荐与排序性能。
通过 Discrete Tokenization,不同单模态的数据特征得以映射到 LLM 的词表空间中,统一进入模型处理框架,从而充分利用 LLM 强大的序列建模和泛化能力。
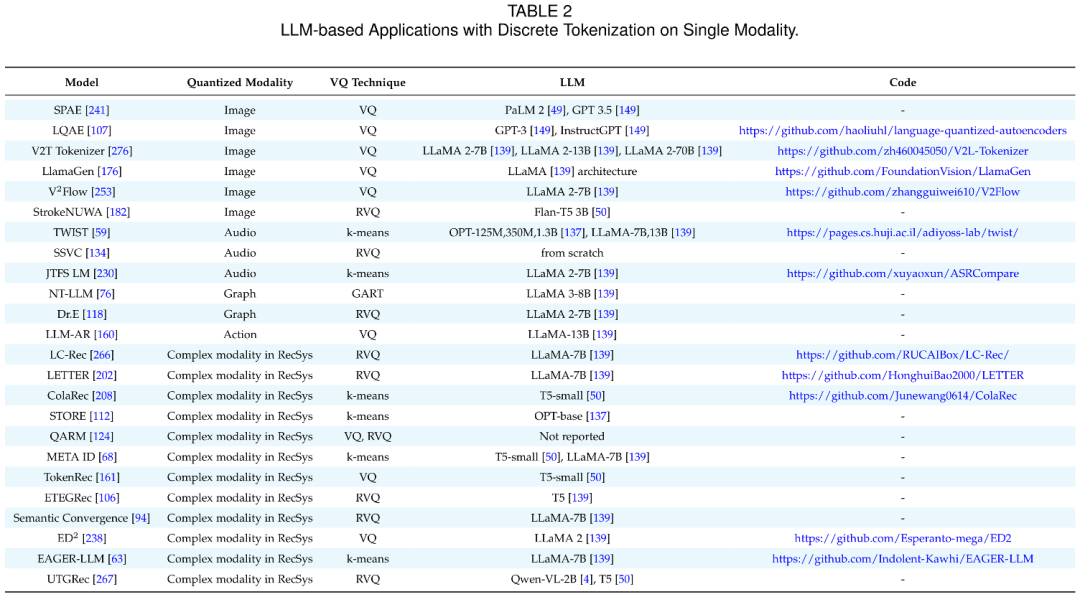
LLM 驱动的多模态离散建模
在多模态任务中,Discrete Tokenization 的作用尤为关键,它为不同模态之间建立了统一的语义桥梁,使模型能够在一致的 token 表示下处理复杂的多模态输入。
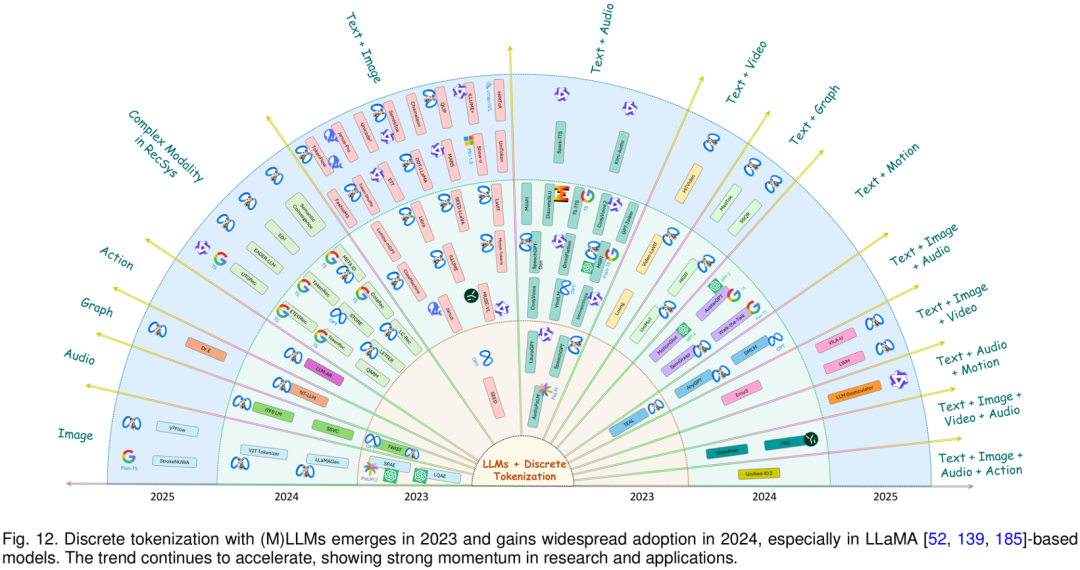
双模态融合
双模态组合起步于 2023 年,其中 Text + Image 是最活跃的方向,其次是 Text + Audio,随后扩展到 Text + Video、Text + Graph、Text + Motion。在这些任务中,各模态通过各自的 tokenizer 转换为离散 token,并映射到统一空间,从而支持图文描述、跨模态问答、语音合成、视频理解、动作生成等任务。
多模态融合
在三模态及以上的组合中,Discrete Tokenization 帮助更多模态在统一框架中协同工作,例如 Text + Image + Audio、Text + Image + Video、Text + Image + Audio + Action。这些组合在统一 token 空间中实现检索、生成、对话、理解等复杂任务。
统一 token 机制使得模型无需为每个模态单独定制架构,而能够在单一框架内自然扩展到更多模态组合,大幅提升泛化性与扩展性。
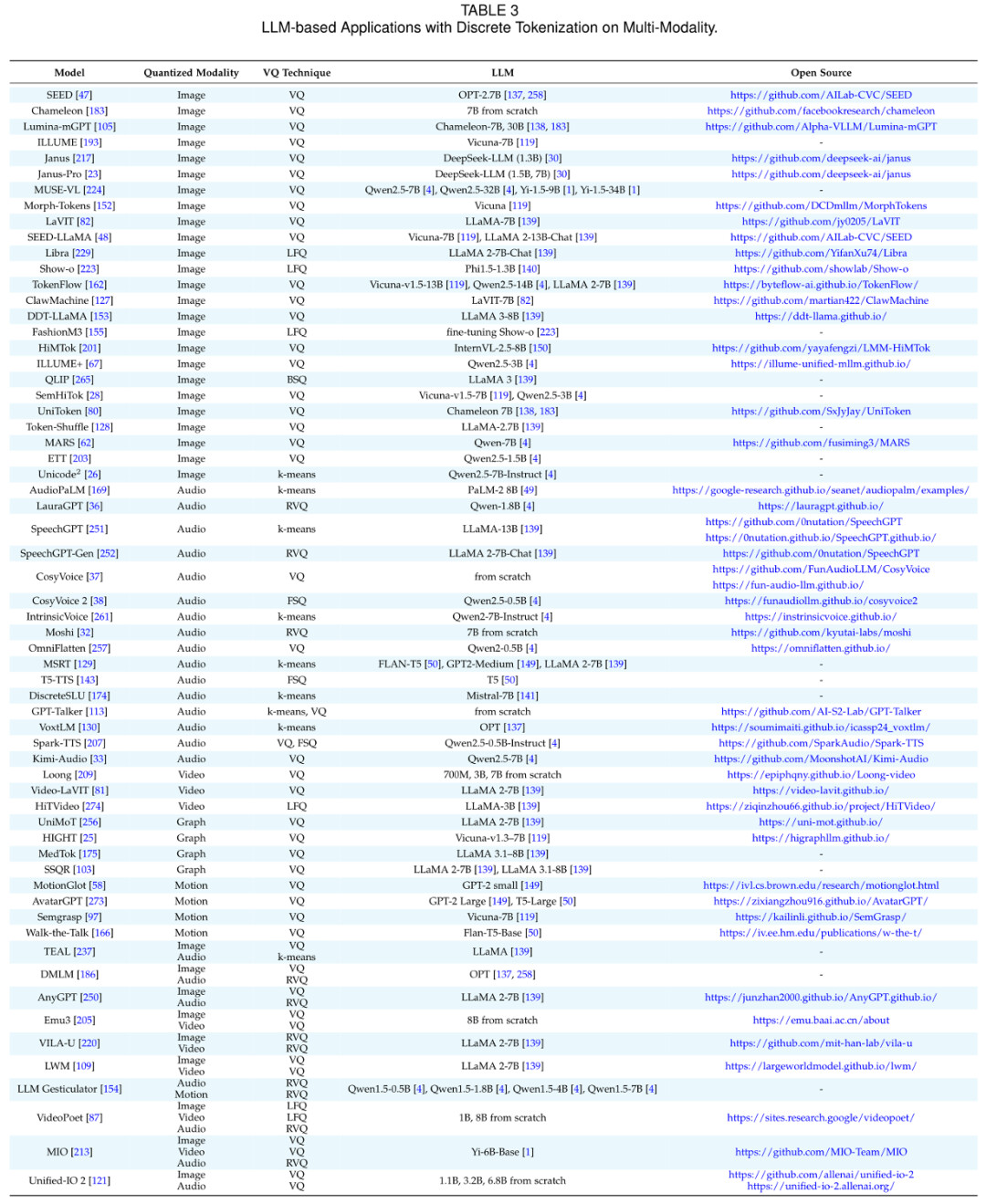
挑战与未来方向
尽管已有显著进展,Discrete Tokenization 在多模态 LLM 中仍存在多方面挑战:
-
码本利用率不足:部分码字长期闲置,降低表示多样性。
-
信息损失:量化过程中压缩语义细节,影响下游性能。
-
梯度传播困难:离散化阻碍了梯度流动,影响稳定训练。
-
粒度与语义对齐:粒度选择不当可能导致细节缺失或计算开销高。
-
离散与连续统一:缺乏两类表示的有效协同。
-
模态与任务可迁移性:跨模态与跨任务的泛化能力不足。
-
可解释性与可控性:token 语义不透明,难以调试与控制。
未来研究方向可以聚焦在:自适应量化、统一框架、生物启发式码本、跨模态泛化、可解释性提升等方面,推动离散化在多模态 LLM 中更高效、更通用地发展。
结语
作为多模态 LLM 的底层桥梁,Discrete Tokenization 的重要性会随着模型能力边界的拓展而不断提升。此综述提供了首个全景化、系统化的离散化参考,不仅梳理了八类核心技术,还围绕输入数据的模态与模态组合构建了完整的应用全景,从单模态到双模态,再到多模态融合,形成了清晰的技术脉络。
这是首个以输入模态为主线构建内容结构的系统化综述,为研究者提供了按模态快速检索方法与应用的技术地图。这种组织方式不仅凸显方法演进的脉络,还为不同研究方向提供了清晰的切入路径,有望在推动理论创新的同时,加速实际落地与跨模态系统的发展。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com