腾讯混元开源四款小尺寸模型,主打卓越Agent能力与256k超长上下文,可轻松运行于消费级设备,赋能多元场景应用。
原文标题:腾讯混元开源 4 个小尺寸模型,主打 Agent 和长文
原文作者:AI前线
冷月清谈:
新开源的模型采用了融合推理技术,可在“快思考”和“慢思考”两种模式间灵活切换,以适应不同的复杂问题解决需求。在语言理解、数学和推理等多个公开测试集上,这些模型的效果达到了行业领先水平。
其核心亮点在于Agent能力和超长上下文处理能力。通过精心的数据构建和强化学习,模型在任务规划、工具调用、复杂决策及反思等Agent方面表现出色,能胜任深度搜索、Excel操作等复杂任务。同时,这些模型原生长上下文窗口高达256k,这意味着它们可以一次性处理相当于40万中文汉字或50万英文单词的超长内容,例如完整理解和分析多本《哈利波特》小说。
在部署方面,这些模型仅需单卡即可运行,并兼容主流推理框架和多种量化格式。腾讯已将这些模型广泛应用于其内部业务,如腾讯会议AI小助手、微信读书AI问书、腾讯手机管家、智能座舱助手、搜狗与微信输入法等,实践证明其可用性和实用性。此外,模型在金融、游戏翻译、专业客服和电商直播等垂直行业也展现了巨大的应用潜力。
此次开源是腾讯混元持续推进大模型开源战略的重要一步,旨在通过提供更多尺寸和模态的模型,加速产业落地,与开发者和合作伙伴一同构建开放的AI生态。
怜星夜思:
2、文章提到混元小尺寸模型的Agent能力很强,能做深度搜索、Excel操作。在你的想象中,未来Agent技术还会给我们日常生活和工作中带来哪些“更贴心”或“更颠覆”的变化?大家觉得它会取代哪些人类工作?
3、拥有256k超长上下文窗口的模型,被拿来举例是能“一口气读完3本《哈利波特》”。除了文学创作和阅读,你觉得在像法律、医疗、科学研究这些需要处理海量专业信息的领域,这种超长上下文能力还能带来哪些“革命性”的应用场景?
原文内容

8 月 4 日,腾讯混元宣布开源四款小尺寸模型,参数分别为 0.5B、1.8B、4B、7B,消费级显卡即可运行,适用于笔记本电脑、手机、智能座舱、智能家居等低功耗场景,且支持垂直领域低成本微调。
腾讯表示,这四款模型的推出,是腾讯混元大模型持续开源的一大举措,也进一步丰富了混元开源模型体系,可为开发者和企业提供更多尺寸的模型选择。目前,四个模型均在 Github 和 HuggingFace 等开源社区上线,Arm、高通、Intel、联发科技等多个消费级终端芯片平台也都宣布支持部署。

新开源的 4 个模型属于融合推理模型,具备推理速度快、性价比高的特点,用户可根据使用场景灵活选择模型思考模式——快思考模式提供简洁、高效的输出;而慢思考涉及解决复杂问题,具备更全面的推理步骤。
效果上,四个模型均实现了跟业界同尺寸模型的对标,特别是在语言理解、数学、推理等领域有出色表现,在多个公开测试集上得分达到了领先水平。
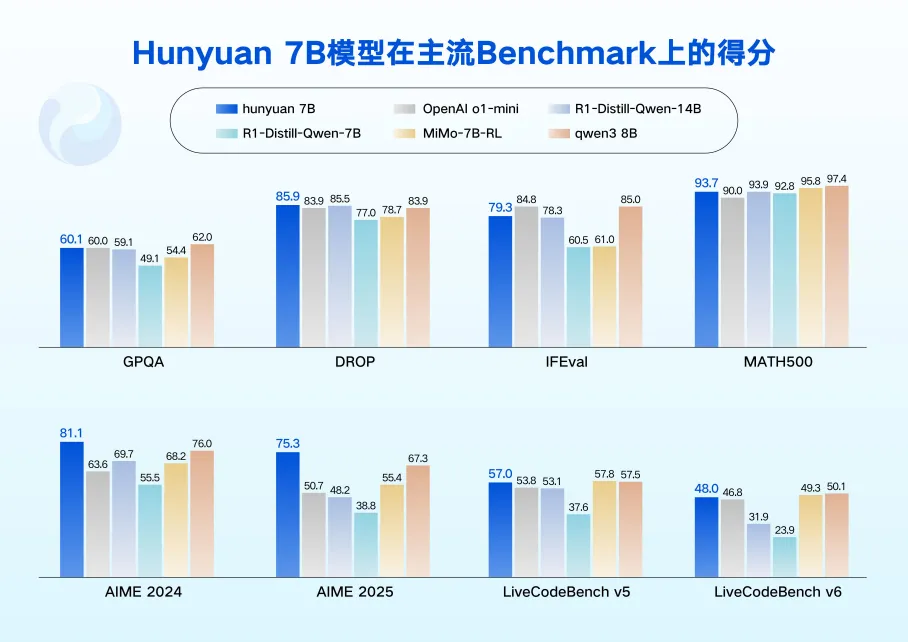

这四个模型的亮点在于 Agent 和长文能力,跟此前开源的 Hunyuan-A13B 模型一样,技术上通过精心的数据构建和强化学习奖励信号设计,提升了模型在任务规划、工具调用和复杂决策以及反思等 agent 能力上的表现,让模型实际应用中可以轻松胜任深度搜索、excel 操作、旅行攻略规划等任务。
此外,模型原生长上下文窗口达到了 256k,意味着模型可以一次性记住并处理相当于 40 万中文汉字或 50 万英文单词的超长内容,相当于一口气读完 3 本《哈利波特》小说 ,并且能记住所有人物关系、剧情细节,还能根据这些内容讨论后续故事发展。
部署上,四个模型均只需单卡即可部署,部分 PC、手机、平板等设备可直接接入。并且,模型具有较强的开放性,主流推理框架(例如,SGLang,vLLM and TensorRT-LLM)和多种量化格式均能够支持。
应用层面,四款小尺寸模型都能够满足从端侧到云端、从通用到专业的多样化需求,并且已经在腾讯多个业务中应用,可用性和实用性经过了实践的检验,是真正实用的模型。
例如,依托模型原生的超长上下文能力,腾讯会议 AI 小助手、微信读书 AI 问书 AI 助手均实现对完整会议内容、整本书籍的一次性理解和处理。
在端侧应用上,腾讯手机管家利用小尺寸模型提升垃圾短信识别准确率,实现毫秒级拦截,隐私零上传;腾讯智能座舱助手通过双模型协作架构解决车载环境痛点,充分发挥模型低功耗、高效推理的特性。
在高并发场景中,搜狗输入法基于模型的多模态联合训练机制使嘈杂环境下提升识别准确率;腾讯地图采用多模型架构,利用意图分类和推理能力提升了用户交互体验;微信输入法「问 AI」基于模型实现输入框与 AI 即问即答的无缝衔接。
在需求各异、约束严苛的垂直行业应用中,金融 AI 助手通过 Prompt 优化和少量数据微调实现 95%+ 意图识别准确率,展现出金融级的高可靠性;游戏翻译和 QQ 飞车手游 NPC 充分利用模型的理解能力在多语言理解能力、方言翻译和智能对话方面有突出表现,这些能力在专业客服、内容出海甚至电商直播等场景有巨大应用潜力。
最近,全球开源领域异常热闹,中国大模型表现抢眼。腾讯混元大语言模型也在持续推进开源,参与技术社区的共建之中,其开源模型已覆盖文本、图像、视频和 3D 生成等多个模态。
在大语言模型领域,腾讯混元此前陆续开源了激活参数量达 52B 的 Hunyuan large 和首个混合推理 MoE 模型 Hunyuan-A13B ,这些模型凭借架构上的创新以及在性能和效果上的不错表现,在开源社区受到广泛关注。
多模态方面,混元还开放了完整多模态生成能力及工具集插件,陆续开源了业界领先的文生图、视频生成和 3D 生成能力,提供接近商业模型性能的开源基座,方便社区基于业务和使用场景定制,图像、视频衍生模型数量达到 3000 个。上周,腾讯发布并开源混元 3D 世界模型 1.0,这一模型一经发布即迅速登上 Hugging Face 趋势榜第二,下载量飙到近 9k,混元 3D 世界模型技术报告还拿下了 Hugging Face 论文热榜第一。
腾讯表示,开源是腾讯混元大模型长期坚持的方向,未来腾讯混元也将不断提升模型能力,继续积极拥抱开源,推出更多尺寸、更多模特的模型,加速产业落地和应用,与开发者和合作伙伴共建大模型开源生态。
Github:
Hunyuan-0.5B:GitHub - Tencent-Hunyuan/Hunyuan-0.5B
Hunyuan-1.8B:https://github.com/Tencent-Hunyuan/Hunyuan-1.8B
Hunyuan-4B:https://github.com/Tencent-Hunyuan/Hunyuan-4B
Hunyuan-7B:GitHub - Tencent-Hunyuan/Hunyuan-7B: Tencent Hunyuan 7B (short as Hunyuan-7B) is one of the large language dense models of Tencent Hunyuan
HuggingFace:
Hunyuan-0.5B:https://huggingface.co/tencent/Hunyuan-0.5B-Instruct
Hunyuan-1.8B:https://huggingface.co/tencent/Hunyuan-1.8B-Instruct
Hunyuan-4B:https://huggingface.co/tencent/Hunyuan-4B-Instruct
Hunyuan-7B:https://huggingface.co/tencent/Hunyuan-7B-Instruct
点击底部阅读原文访问 InfoQ 官网,获取更多精彩内容!

