清华团队发布27M参数AI,推理能力超越大模型,颠覆AI“蛮力”范式。
原文标题:马斯克挖不动的清华学霸,一年造出 “反内卷 AI”!0.027B参数硬刚思维链模型,推理完爆o3-mini-high
原文作者:AI前线
冷月清谈:
怜星夜思:
2、HRM的成功,是不是意味着“大模型”的时代要过去,或者说“越大越好”的观念不一定对?未来AI发展趋势会是更偏向“小而精”的专业模型,还是继续在通用大模型上卷参数?大家怎么看待这种“反内卷AI”的趋势?
3、这团队核心是刚毕业的清华学生,加上一批顶尖科学家,在没有巨额融资的情况下做出这么牛的东西。这给我们国内的AI创业和研究有哪些启示?是不是说,优秀的人才和好的思路比烧钱更重要?
原文内容

近期,总部位于新加坡的 Sapient Intelligence 推出了一款新的人工智能模型,名为 HRM。其参数规模仅为 2700 万,但能够解决那些让当今先进大型语言模型都束手无策的复杂推理难题。
据其研究人员称,像 ChatGPT 这类模型存在一个问题——它们在架构上属于“浅层”设计。这些模型依赖“思维链(CoT)”提示法(本质上是通过一步步自言自语来拆解问题)作为辅助手段,但这种方式存在隐患:只要一步出错,整个推理过程就会偏离正轨。而这次发布的小型模型 HRM 采用了截然不同的思路,其做法是借鉴了人类大脑的工作方式。
发布后,该模型迅速引起了网友的讨论。不少网友震惊于该模型的参数规模及带来的效果,称“这太疯狂了”。一位网友指出,“一个名为 HRM 的小型 AI 模型刚刚击败了 Claude 3.5 和 Gemini,它甚至不使用 token。”
一位资深投资人对该模型的成果论文给予极高的评价:“人工智能领域最重要的论文之一”。还有一位网友称,“如果这个成果得以确立,它不仅仅是一篇人工智能论文——它标志着一个哲学性的转变。效率和结构或许终于能够战胜蛮力。”
值得一提的是,Sapient Intelligence 背后是一个大学生团队。2024 年 8 月,刚从清华大学毕业的王冠和连续创业者郑晓明共同创立了这家公司。
创业之前,王冠尝试做了一个仅 7B 大小的的开源模型 OpenChat,发布后在 Github 上获得 5.2k stars,在无融资和推广的情况下成为全世界下载量最高的开源模型之一,在 Hugging face 上月均下载量一直在 20 万以上。
之后,这个开源小模型还获得了马斯克的关注与青睐。据了解,XAI 曾向王冠伸出橄榄枝,想让他利用 OpenChat 的经验从事模型开发工作,但被其拒绝了。
王冠与郑晓明的相识,也与 OpenChat 有很大关联。彼时,Austin 正在寻找可以在 AGI 领域有突破、致力于改变世界的年轻人,借由 OpenChat 的热度,他在 Github 上发现了王冠。
据悉,在创立初期,Sapient Intelligence 汇聚了众多来自世界各地的一线科学家,包括 XAI、Deepmind、Google、Anthropic、Meta 和 Microsoft 等世界级 AI 机构的资深科学家。这些来自世界各地的人才曾领导或参与过众多知名模型和产品的开发,包括 AlphaGo、Gemini、Microsoft Copilot 等。
准确率碾压先进思维链模型,
推理能力超越 o3-mini-high
当前,大型语言模型在面对复杂问题时很大程度上依赖思维链提示法,将问题拆解为基于文本的中间步骤,本质上是强迫模型在朝着解决方案推进的过程中 “大声思考”。尽管思维链提升了大型语言模型的推理能力,但它存在根本性局限。
Sapient Intelligence 的研究人员在论文中指出:“用于推理的思维链只是一种辅助手段,并非理想的解决方案。它依赖于脆弱的、人为定义的分解方式,其中任何一个步骤出错或步骤顺序混乱,都可能导致整个推理过程彻底偏离轨道。”
这种对生成显性语言的依赖,将模型的推理限制在了 token 层面,这往往需要海量的训练数据,并且会产生冗长而缓慢的响应。这种方法还忽略了那种在内部发生、无需通过语言明确表达的“隐性推理”。正如研究人员所指出的:“我们需要一种更高效的方法来减少这些数据需求。”
据 Sapient Intelligence 介绍,其推出的 HRM 在复杂推理任务上能与大型语言模型不相上下,在某些情况下甚至远超后者,同时其规模显著更小,数据效率也更高。
研究人员对该模型的测试结果显示,在“极限数独”和“高难度迷宫”基准测试中,最先进的思维链模型彻底失败,准确率为 0%;相比之下,HRM 在每个任务仅用 1000 个样本训练后,就达到了接近完美的准确率。
在用于测试抽象推理与泛化能力的 ARC-AGI 基准测试中,这个参数规模仅为 2700 万的 HRM 取得了 40.3% 的得分。这一成绩超过了主流的基于思维链的模型,如规模大得多的 o3-mini-high(34.5%)和 Claude 3.7 Sonnet(21.2%)。(根据之前微软论文,几款主流模型参数量分别为:Claude 3.5 Sonnet: 175B;GPT-4: 1.76T;GPT-4o: 200B;o1-preview: 300B;o1-mini: 200B。)HRM 在没有大型预训练语料库、仅用极少数据的情况下就实现了这样的性能,充分彰显了其架构的强大与高效。
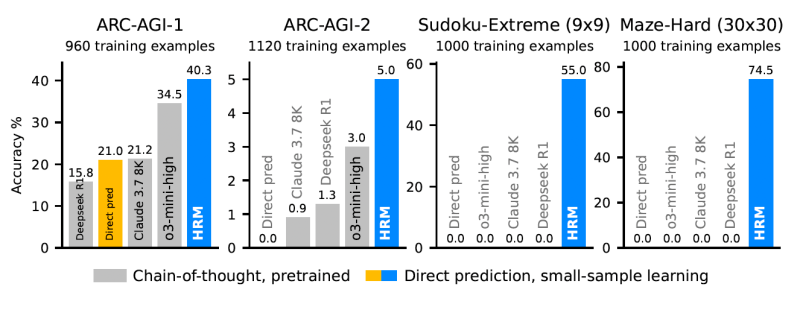
除此之外,HRM 在另一类问题上体现出现实世界中的意义。Sapient Intelligence 的创始人兼 CEO 王冠表示,开发者应继续使用大型语言模型处理语言相关或创意任务,但对于“复杂或确定性任务”,类似 HRM 的架构能以更少的幻觉输出实现更优性能。他特别指出了“需要复杂决策或长期规划的序列性问题”,尤其是在具身 AI 和机器人等对延迟敏感的领域以及科学探索等数据稀缺的领域。
在这些场景中,HRM 不仅能解决问题,还能学得更高效的解决方法。“在我们的大师级数独实验中,随着训练推进,HRM 需要的步骤逐渐减少——就像新手成长为专家的过程。”王冠解释道。
受大脑启发,
提出“隐性推理”路径
据介绍,HRM 的灵感来源于人类大脑如何利用不同系统进行慢速、审慎的规划和快速、直觉性的计算。并且,该模型仅需当今大型语言模型所需数据和内存的一小部分,就能取得令人瞩目的结果。这种高效性可能对现实世界中的企业级人工智能应用产生重要影响 —— 在这些场景中,数据往往稀缺,计算资源也十分有限。
在论文中,Sapient Intelligence 详细介绍了他们所探索的各种思路及做出的相关研究工作。
首先,为突破思维链的局限,研究人员探索了“隐性推理”——模型不再生成“思考 tokens”,而是通过其内部对问题的抽象表征进行推理。这与人类的思考方式更为契合:“大脑能在隐性空间中以极高的效率维持冗长且连贯的推理链,无需不断将其转化为语言。”
然而,在人工智能中实现这种深度的内部推理并非易事。在深度学习模型中简单堆叠更多层,往往会导致“梯度消失”问题——学习信号在各层间逐渐减弱,使训练效果大打折扣。另一种选择是通过循环计算的递归架构,但这类架构又可能面临“过早收敛”问题——模型在未充分探索问题的情况下就仓促得出结论。
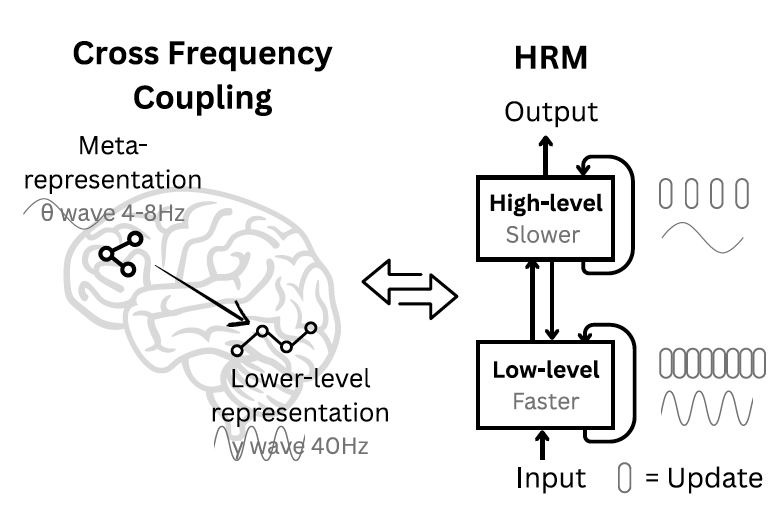
为了找到更优方案,Sapient Intelligence 团队转从神经科学中去寻求灵感。“人类大脑为实现当代人工模型所缺乏的有效计算深度提供了极具吸引力的蓝图。它通过不同时间尺度运作的皮质区域,对计算进行分层组织,从而实现深度、多阶段的推理。”研究人员写道。
受此启发,他们为 HRM 设计了两个耦合的递归模块:一个是用于慢速、抽象规划的高层(H)模块,另一个是用于快速、细节计算的低层(L)模块。这种结构实现了团队所说的“分层收敛”过程。直观来看,快速运作的 L 模块处理部分问题,执行多步计算直至得出稳定的局部解;此时,慢速运作的 H 模块接收这一结果,更新整体策略,并向 L 模块下达新的、更精确的子问题。这一过程有效重置了 L 模块,避免其陷入僵局(过早收敛),同时让整个系统能以精简的模型架构执行长序列推理步骤,且不会出现梯度消失问题。
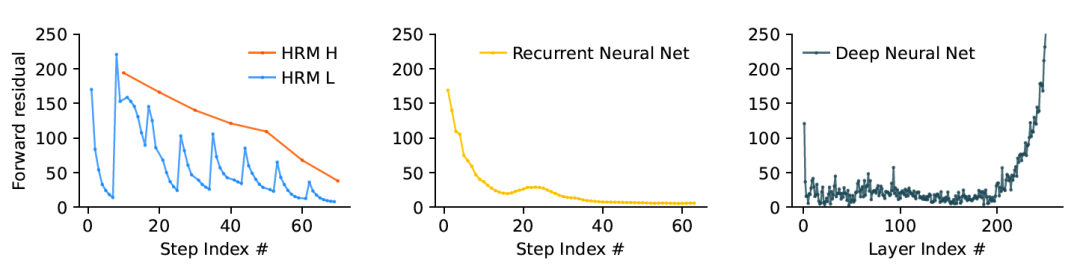
论文中提到,“这一过程使 HRM 能够执行一系列独特、稳定且嵌套的计算——H 模块主导整体解题策略,L 模块则负责执行每一步所需的密集搜索或细化工作。”这种嵌套循环设计让模型能在隐性空间中深度推理,无需冗长的思维链提示或海量数据。
一个自然会产生的疑问是:这种“隐性推理”是否以牺牲可解释性为代价?对此,王冠并不认同。他解释说,模型的内部过程可以被解码和可视化,就像思维链能让人窥见模型的“思考”过程一样。他还指出,思维链本身可能具有误导性。“思维链并不能真正反映模型的内部推理。”
王冠在接受采访时表示,他引用的研究显示,模型有时会在推理步骤错误的情况下得出正确答案,反之亦然,“它本质上仍然是一个黑箱。”
经济性突出,
任务效率百倍提升
对于企业而言,架构的高效性直接转化为经济效益。据王冠估计,不同于思维链那种逐 token 的串行生成方式,HRM 的并行处理能力可实现“任务完成时间 100 倍的提速”。这意味着更低的推理延迟,以及在边缘设备上运行强大推理的能力。
为了直观说明其高效性,他提到训练达到专业水平数独能力的模型仅需约 2 个 GPU 小时,而针对复杂的 ARC-AGI 基准测试,也只需 50 到 200 个 GPU 小时——这只是大型基础模型所需资源的一小部分。这为解决特定业务问题开辟了道路,从物流优化到复杂系统诊断,这些场景往往数据和预算都有限。
“与大型、昂贵且延迟高的基于 API 的模型相比,像 HRM 这样的专用推理引擎为特定复杂推理任务提供了更具前景的替代方案。”王冠说道。
据悉,Sapient Intelligence 已着手将 HRM 从专用问题求解器发展为更通用的推理模块。“我们正积极开发基于 HRM 的类脑模型。”同时,王冠强调了他们在医疗健康、气候预测和机器人技术领域取得的初步可喜成果。据其透露,这些下一代模型将与当今的文本型系统有显著差异,尤其是会加入自我修正能力。
参考链接:
https://arxiv.org/pdf/2506.21734
https://venturebeat.com/ai/new-ai-architecture-delivers-100x-faster-reasoning-than-llms-with-just-1000-training-examples/
https://36kr.com/p/2957829366400520
声明:本文为 AI 前线整理,不代表平台观点,未经许可禁止转载。

