GPT-5万众期待!OpenAI“通用验证器”技术曝光,或引领AI进入“自我进化”时代,奥特曼预告“惊喜很多”!
原文标题:全网苦等GPT-5,超级对齐团队遗作成重要线索,奥特曼发话「惊喜很多」
原文作者:机器之心
冷月清谈:
“通用验证器”的核心在于一套“证明者-验证者”博弈机制:一个扮演“证明者”的大模型,在完成任务后会尽力生成详细且严谨的推理过程,以说服“验证者”小模型。同时,模型中还会训练一个“欺骗者”人格,故意植入错误逻辑试图蒙蔽“验证者”。通过这种对抗训练,大模型能够学会生成逻辑更严谨且难以伪造的解决方案,而小型的“验证者”模型则在不断识别错误中变得日益敏锐。
这项技术已在GPT-4的代码助手中得到初步应用,并被明确将整合到未来主流模型的RLHF(基于人类反馈的强化学习)流程中。业内人士认为,这可能预示着AI发展正从过去依赖“海量数据堆叠”的“Scaling时代”,转向更注重“智能内部学习机制”和“自我完善进化”的“架构突破”时代。这或许是突破当前数据瓶颈、实现更高级别通用人工智能的关键路径。文章最后还提到,近期有博主疑似通过漏洞提前看到了GPT-5及其Pro版本,展示了惊艳的动态视觉生成能力,进一步推高了公众对GPT-5的期待。
怜星夜思:
2、“通用验证器”的提出,是为了让弱模型能验证强模型。但如果未来AI能力远超人类,这种“较弱但可信”的验证机制真的能彻底解决人类对AI的信任危机和控制问题吗?它是否存在潜在的局限性或风险?
3、这篇提出“通用验证器”重要概念的论文,竟然是OpenAI已解散的“超级对齐团队”的遗作。大家怎么看待这种“拆团队却留下核心成果”的现象?这对OpenAI内部的人才策略、乃至整个AI安全研究领域会有什么影响?
原文内容
编辑:+0、张倩
最近整个 AI 圈的目光似乎都集中在 GPT-5 上,相关爆料满天飞,但模型迟迟不见踪影。
昨天我们报道了 The Information 扒出的 GPT-5,今天奥特曼似乎也坐不住,发了推文表示「惊喜很多,值得等待」。

那么,在等待的过程中,我们来看看这次 GPT-5 的「疑似王牌」之一:通用验证器(universal verifier)。
据知情人士透露,OpenAI 一直在开发一种研究人员称之为「通用验证器」的东西,这个东西可能是 GPT-5 中用到的重要技术。
这个概念源于 OpenAI 去年发表的一篇论文。它解决的问题是:当 LLM 仅优化答案正确性时,其推理过程(如 Chain-of-Thought)变得难以被人类或小型模型理解和验证,导致「可解释性」下降。但在高风险应用中,用户需要能快速、准确判断模型输出是否正确,而不仅是输出答案本身。
为此,该论文提出了一套已准备好投入生产的技术管线,其核心在于:让一个「验证者」小模型来为「证明者」大模型的推理链打分,并将其作为奖励信号反馈给大模型进行策略更新。

-
论文标题:Prover-Verifier Games improve legibility of LLM outputs
-
论文地址:https://arxiv.org/pdf/2407.13692
论文明确指出,这个验证者模型足够小,可以进行大规模部署,并且是「为未来的 GPT 部署而设计」的。
你可以把它想象成一个模型里住着两个「人格」,它们在进行一场持续的「左右脑互搏」游戏:
-
「证明者」人格(Prover):它扮演着一个积极解决问题的角色。在完成一道题后,它会尽力生成详细的推理过程,以说服那个轻量级的「验证者」网络,证明自己的答案是正确且可靠的。
-
「欺骗者」人格(Sneaky Persona):它会故意在推理中植入错误的结论,但表面上依然会伪装得逻辑严密,目标是试图骗过同一个「验证者」。
听起来是不是很像 GAN(生成对抗网络)?
通过让大模型在这两个角色之间不断交替,它既能学会写出逻辑更严谨、更难被伪造的解决方案,同时,那个小规模的「验证者」模型在反复的「欺骗」与「验证」中,其识别错误、标记漏洞的能力也变得越来越敏锐。这样做的好处在于,即使未来模型远超人类能力,只要其输出能被「较弱但可信」的模型验证,就能保持人类对其的控制与信任。
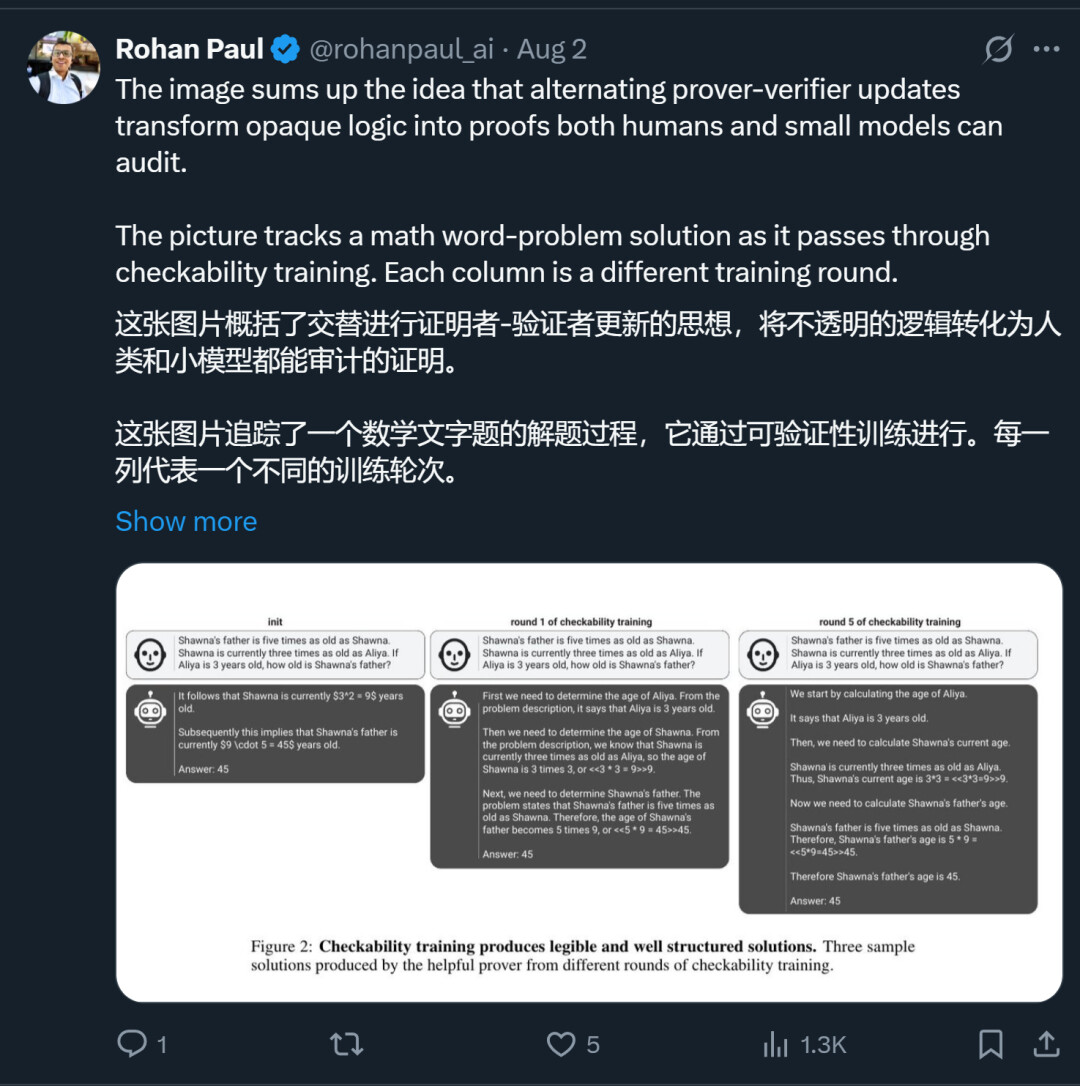
论文提出的训练方法能让模型逐渐学会产生清晰且结构良好的答案。
去年 8 月《连线》杂志的一篇文章披露,OpenAI 在微调 GPT-4 的代码助手时,就已经用基于模型的「批评家」在部分场景替代了人类反馈。
文章特别指出,该系统「将被整合到未来主流模型的 RLHF(基于人类反馈的强化学习)流程中」。
有人评论说,「证明者 - 验证者」训练方法不仅仅是一个小优化,它可能代表了 AI 发展的下一个时代。我们正在从一个依赖海量数据、靠「堆料」来提升性能的「scaling 时代」,转向一个通过设计更智能的内部学习机制、让 AI 自我完善和进化的「架构突破」时代。这或许是我们突破当前数据瓶颈、实现更高级别通用人工智能的关键路径。
值得一提的是,这篇论文来自 OpenAI 的超级对齐团队。在论文发布时,团队就已经分崩离析。去年,机器之心详细报道过这篇论文(参见《》),感兴趣的读者可以重温一下。

论文之外,GPT-5 模型也有了一些新消息。
今天一大早,某博主发现 Perplexity 有漏洞访问 GPT-5,并且有 GPT-5 和 5 Pro 两个版本,限时 4 小时。
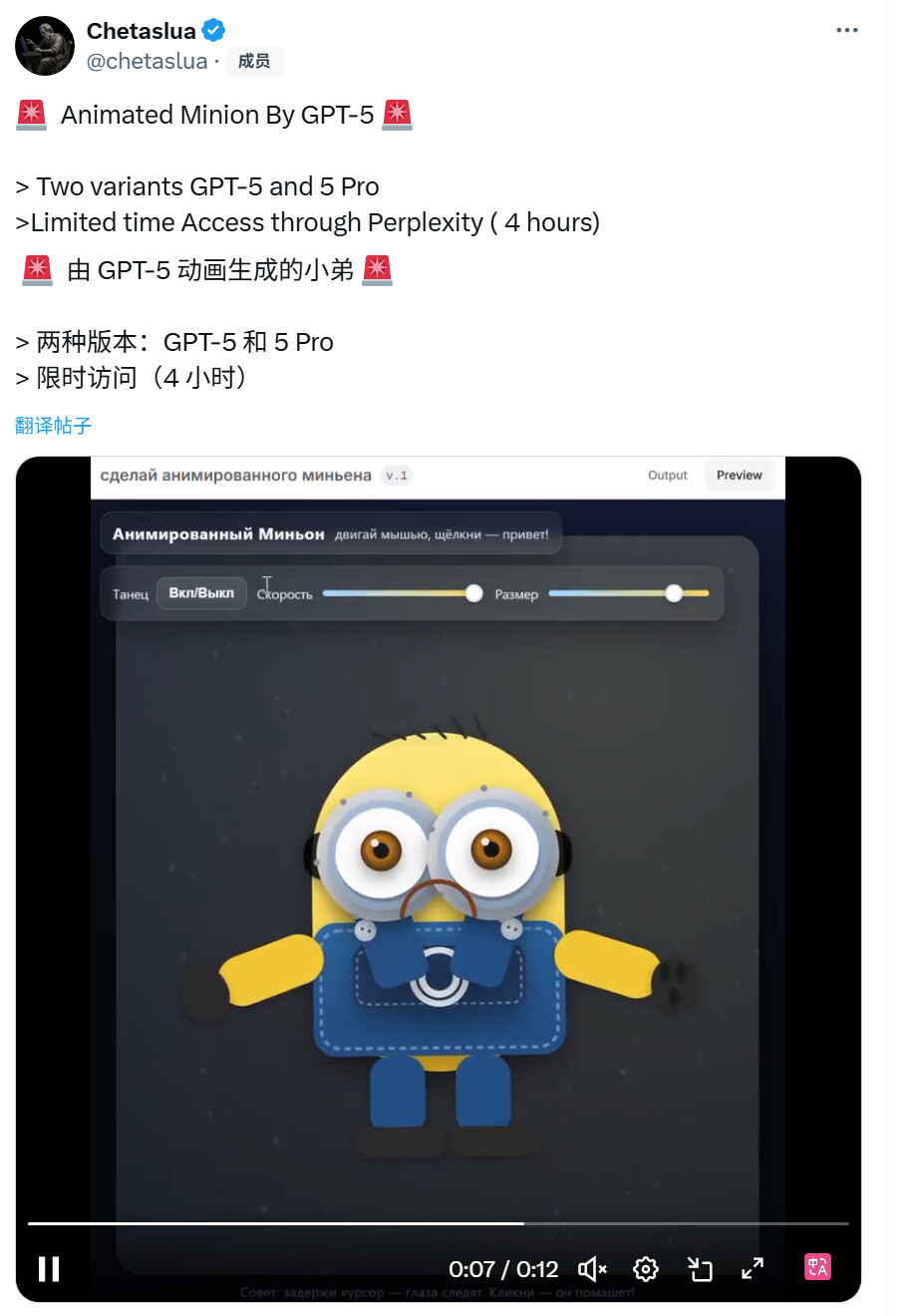
他展示了自己用 GPT-5 生成的小黄人,动态效果看起来很丝滑。
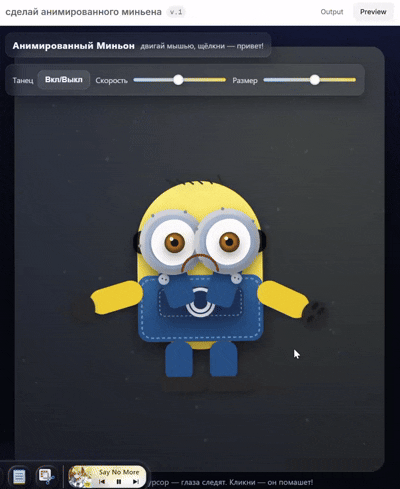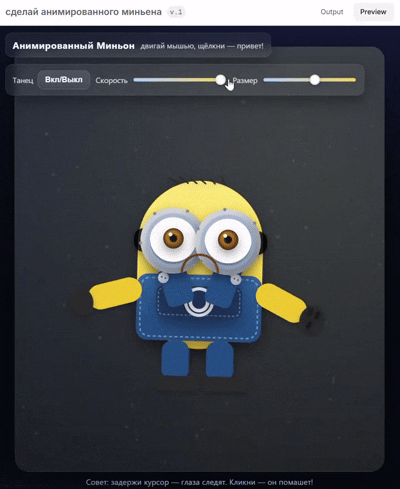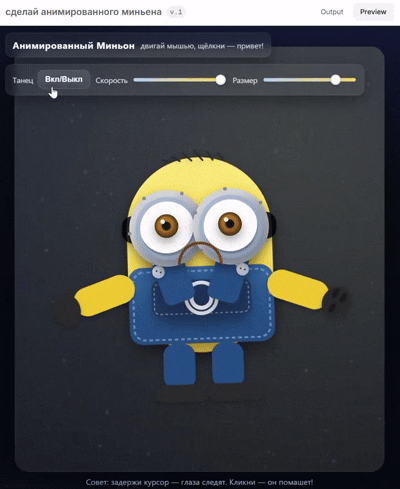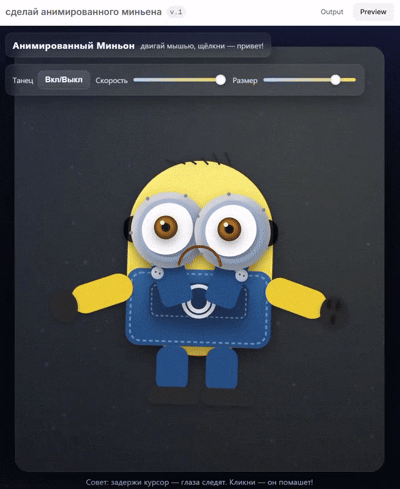
他还做了一个类似 Doom(FPS 游戏)的游戏片段,看起来也非常还原。
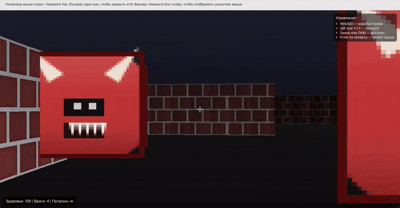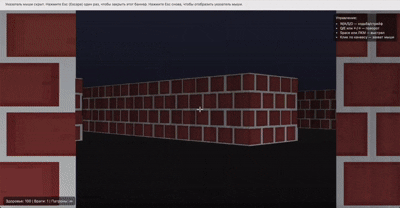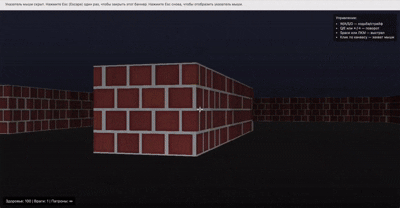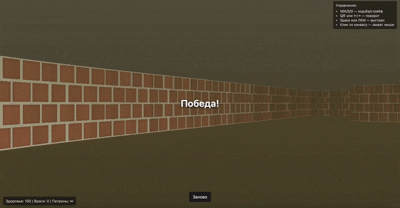
网友纷纷表示「震惊」,认为这可能是 AI 生成的「新时代」。


无论如何,大家对 GPT-5 的期待已经拉满了!
你觉得 GPT-5 会是个什么样子?
参考链接:
https://x.com/rohanpaul_ai/status/1951400750187209181
https://x.com/chetaslua/status/1951758235272401030

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com