理想i8搭载VLA高阶辅助驾驶,以视觉-语言-行为大模型革新L3范式,实现智能交互与平顺驾驶。
原文标题:通向L3的正确范式?理想i8全球首发VLA高阶辅助驾驶,我们帮你试了试
原文作者:机器之心
冷月清谈:
VLA系统最大的改进在于利用大模型的语言智能提供决策能力,将空间智能输入转化为语言理解与动作指令,实现人车自然语言交互。用户可以直接通过语音指令更改AI决策,例如精确控制车辆前进距离。系统运行中,将环境信息总结为语言进行推理,以10Hz的速度实现决策。
VLA的特点包括:思维推理能力(基于CoT深度理解环境生成决策)、沟通能力(自然语言交互)、记忆能力(记住路径设定)和自主学习能力(通过仿真环境迭代提升)。它带来了更平顺的驾驶体验(通过Diffusion生成光滑轨迹)和更稳健的“专车司机”式驾驶风格,并引入了防御性驾驶理念。理想汽车在数据收集、云端算力投入及算法效率上进行了大量优化,尤其是通过“世界模型”进行大规模仿真测试,大幅降低了测试成本,并加速了系统迭代,宣称版本迭代速度仅受显卡数量限制。理想表示,未来VLA技术迭代将加速,目标是将MPI(接管里程)提升到1000公里,为用户提供一个“私人司机”般的驾驶体验。
怜星夜思:
2、文章提到,理想VLA大量采用了“世界模型”进行仿真测试,通过生成数据来训练模型,大幅降低了成本并加速了迭代。听起来很高效,但这种高度依赖虚拟环境训练的方式,会不会在面对真实世界中那些“意料之外”的复杂、极端或从未发生过的长尾场景时,出现理解和决策上的偏差,甚至带来安全隐患?毕竟,现实世界总比虚拟世界复杂多了。
3、理想高层提到,一年后MPI(接管里程)达到1000公里,意味着智能驾驶将“真正到来”。大家觉得,当辅助驾驶系统能够如此长时间不需人工干预时,我们的交通法规、保险制度、以及社会大众对自动驾驶的信任度能跟上技术进步的速度吗?未来,交通事故责任认定会变得更复杂吗?
原文内容
作者:泽南
VLA「司机大模型」问世。
本周二,理想全新纯电 SUV 理想 i8 正式上市,其搭载的全新一代 VLA 辅助驾驶系统立刻引起了人们的关注。
作为全球第一个展示 VLA 辅助驾驶范式的车企,理想应用基于视觉-语言-行为大模型、新一代英伟达 Thor-U 芯片和禾赛 ATL 激光雷达的 VLA 司机大模型,让新车型的辅助驾驶能力实现大幅提升。
在理想 i8 发布之前,工程师向我们分享了他们基于最新 VLA 模型的辅助驾驶技术以及研发历程。

全球范围内,辅助驾驶系统刚刚经历了从无图智驾到端到端范式的革新,不过理想在大规模实践后认为,面向 L3,系统架构还需要再次演进。
自去年端到端辅助驾驶上线后,理想落地技术的 MPI(接管里程)水平在近 12 个月以内提升明显。自去年 7 月份开始小规模内测时,端到端辅助驾驶的成绩是十几公里,到今年 2 月上线 1000 万 clips 的版本之后,MPI 做到了 100 公里,7 个月翻了 10 倍。
然而在 1000 万 Clips 的成绩过后,只增加数据量带来的提升变得有限,有价值的训练数据也越来越少。理想尝试了「超级对齐」,通过后处理、一定的规则机制来规范模型输出效果,使之符合人类需求。与此同时,理想提升了筛选数据的标准,今年 3 月到 5 月,模型性能提升在两倍左右。
理想发现,端到端的方法如果只通过数据驱动升级会存在边际效应。无论如何配比数据都会面临难以克服的挑战,如会出现违反常理的行为(缺乏对于场景的理解);开车不够聪明(决策没有深度思考);行驶时让人类感觉安全感不足(没有根据场景做出「预防性驾驶」)等问题。
事实证明,「模仿学习」的路线不具备深度的逻辑思维能力。
去年,理想工程师开始试图在需要深度决策时为 AI 模型中加入更多推理能力。但当时基于 VLM 的推理速度很慢(当时为 2-3Hz),它也不能理解在执行任务的中间接受由人类提出的新指令。
在基于 VLA(Vision Language Action)架构的辅助驾驶方案中,最大的改进在于使用、依靠大模型的语言智能提供决策能力——空间智能的输入会转化成语言智能的理解表达编码,最后形成动作指令。
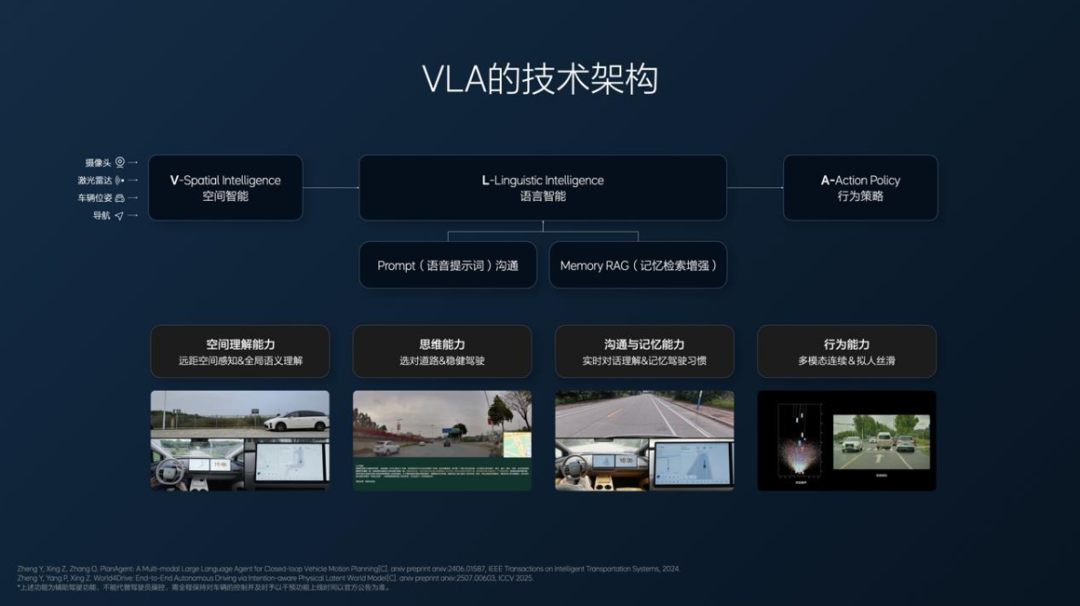
也正是因为这样的架构变化,与目前 AI 领域的深度思考大模型类似,辅助驾驶系统拥有了很强的可交互能力。VLA 在使用上最明显的变化是:假如人类在中间有指令(Prompt),可以随时更改 AI 做出的决策。VLA 天生可以听懂人类的指令,并按照人类的指令来完成任务。
比如你可以直接跟 i8 说话,「理想同学前进 5 米」,它就会开出准确的 5 米距离。

VLA 在运行时会把看到的整个环境总结成语言,然后形成类似于人的思考。可以看到,在辅助驾驶开启的过程中,系统会把传感器传来的视频信息转化为文本再进行推理,目前可以实现的速度是 10Hz。

除了对现实世界的充分理解之外,VLA 辅助驾驶还带来了更好的平顺性。过去的端到端辅助驾驶上,AI 对于车辆操作的 Action 是生成轨迹点,然后连接点进行近似平滑的方式;现在模型做出的推理是由 Diffusion 生成的光滑轨迹。从实际驾驶体验上看,现在开车动作会更加丝滑,动作调整会变少,体验会更好。
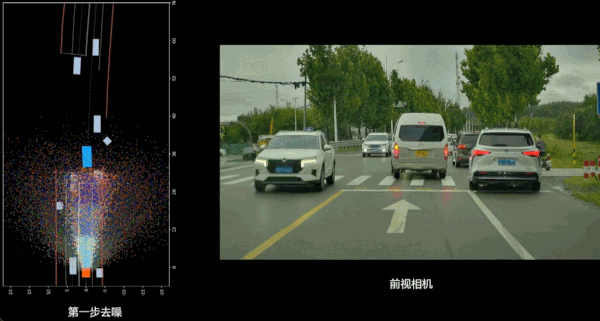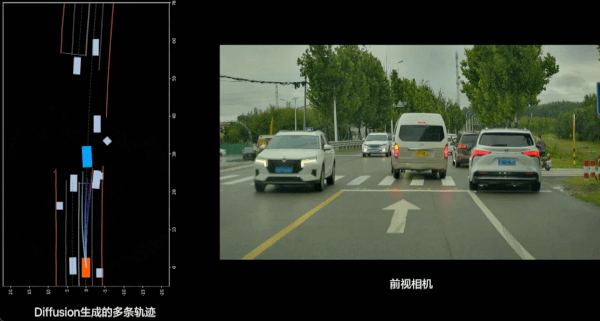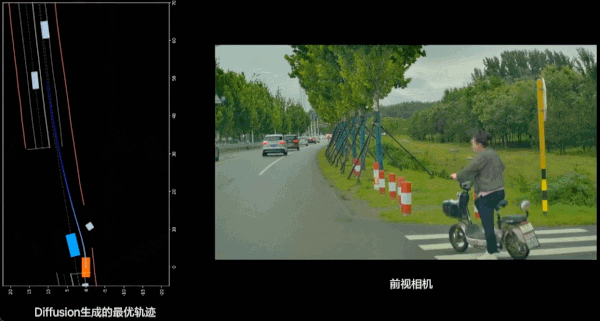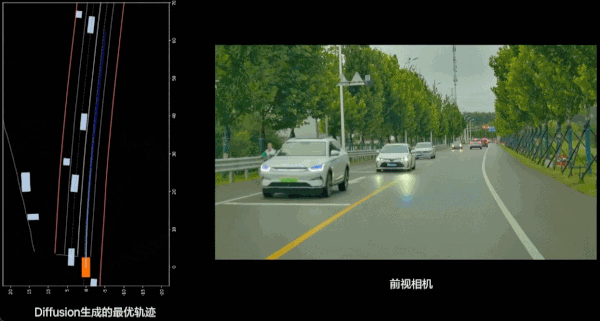
此外还有驾驶风格的改进:在上代辅助驾驶,理想更多参考的是「老司机」提供的数据,这一代则更多是在模仿「专车司机」,更加稳健的风格会受到更多人欢迎。
总结一下,VLA 范式的特点包括:
-
思维推理能力,利用 CoT(Chain of Thought,思维链)的推理,系统能够充分理解和感知环境,并由此生成驾驶决策;
-
沟通能力,可以和驾驶者使用自然语言无缝交流,开快点、开慢点、左转、右转、超车等基本操作都可以;
-
记忆能力,开到某一条路上,你可以跟大模型说「以 ×× 公里速度行驶」,下一次来到同样的道路,车辆可以记住上一次的设置;
-
自主学习的能力,VLA 通过仿真环境自我迭代和提升,其中用到了大量生成数据。
简单来说就是「能思考、能沟通、能记忆、能自我提升」。在全面架构升级后,第一版 VLA 的体验相比端到端辅助驾驶的最新版本已有不小的提升。

基于 VLA,理想希望能够面向更广泛的用户群体提供一个「私人司机」。VLA 司机大模型将为用户带来驾驶体验的一系列升级。例如,VLA 辅助驾驶已经学会了防御性驾驶,区别于「遇到丁字路口就刹车」的决策,VLA 能够通过推理分析出道路上存在的盲区,从而提前刹车预防潜在的碰撞风险。
在狭窄的道路上,车辆也可以自行多次倒车调头。

理想汽车的辅助驾驶研发历程自 2021 年开始,从最初的 BEV 方案到无图辅助驾驶再到 2024 年开始落地的端到端架构,技术架构已经历了多轮的迭代。
截止目前,理想已经积累了 43 亿公里用户智驾总里程,其用户规模总计 134 万辆,理想为智驾算法准备的云端算力总计已达 13EFLOPS。
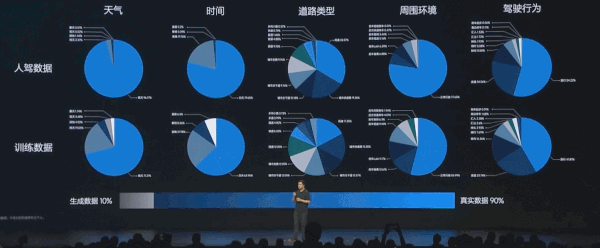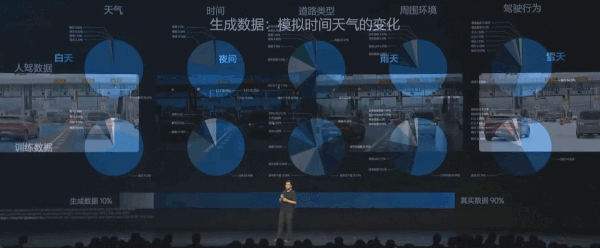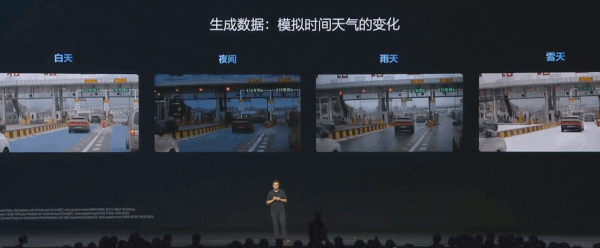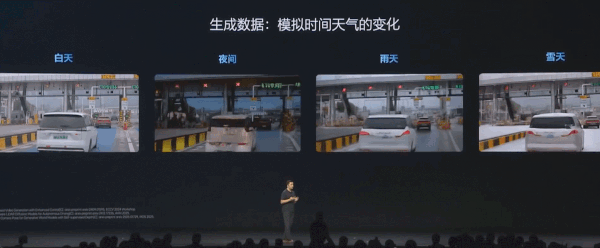
数据方面,理想自 2020 年开始收集数据进行迭代。到今年 7 月份已经累计了 12 亿公里的有效数据。理想积累了大量不同环境下的数据,并进行分类,例如不同天气、时间段、道路类型、车道路口类型、交通状况、目标车的场景、自车行为、合规行为、接管类型等维度。
「大家都可以做到 1000 万 clips,这可能等于 1000 到 2000 万公里的数据,但问题在于你是否能够构建出有价值的数据。我们针对长尾场景采用数据合成的方式,让场景分布更加均衡,才获得了一些性能提升,」理想汽车智能驾驶研发副总裁郎咸朋博士说道。「在一些难以获取数据的长尾场景上,我们更多地使用生成数据来进行训练。」
今年 2 月份起,理想调整优化了端到端模型的训练数据。通过世界模型负责场景的重建和生成,根据真实数据「举一反三」以提升 VLA 应对复杂场景的能力。
比如「高速 ETC 收费站」,同样一个地点可以生成不同天气、不同时间的场景。有些 corner case 危险场景的数据,也可以通过世界模型生成出来。
算法方面,理想的核心能力在于算法效率高,以及强化学习的应用。李想此前提到过,VLA 大模型生成需要五步。理想构建了 MindGPT 基座模型,经过后训练、RLHF(基于人类反馈的强化学习)、强化学习、构建 VLA 司机智能体几步实现了辅助驾驶系统。
在后训练过程中,VLA 模型在世界模型中进行仿真测试,世界模型生成「真题」(完全复现)和「模拟题」(新的场景)。所有条件完全可控,测试周期大幅缩短,成本降低,可以实现天级发版。理想甚至表示,「实际上版本迭代的速度只取决于显卡的数量。」
虽然显卡的价格很贵,对比极为耗费人力的实车测试,这样做不仅让成本大幅降低,辅助驾驶效果也可以持续提升。也正是因此,理想的辅助驾驶测试里程从 2023 年的实车测试 157 万公里,每公里成本 18.4 元,2024 年实车测试 122 万公里,仿真测试 514 万公里,每公里成本 4.84 元,进化到了今年截至 6 月 30 日的实车测试 2 万公里,仿真测试 4009 万公里。目前每公里成本只用 0.53 元。
在工程能力方面,理想着力进行了模型量化,并提升部署效率。在 Thor-U 上部署的 4B 模型进行了 FP8、INT8 量化,在「旧版」硬件车辆的 Orin-X 上也能部署。预计在未来,通过 FP4 精度的推理,Thor-U 搭载芯片车辆的算力可实现翻倍,为 VLA 模型释放更大的算力空间。
最后还有 One more thing:在北京的理想总部,目前已经有正在运行的 MEGA Home 接驳车,可以实现全区域(包括地下停车场)的巡游。

理想基于世界模型,为自家总部构建了一个 1×1km 的完全仿真环境。作为庞大 3D 资产的集合,其中的每个交通参与者都重建了 3D 模型,并作为智能体有自己的行动逻辑,完全模仿真实的物理世界。理想表示,车辆在其中运行,训练速度会是真实世界训练速度的很多倍。
上一代技术能力的上限,是下一代技术能力的起点,未来 VLA 技术的迭代速度还会再次加快。理想表示,一年后大家看到一个 MPI 在 1000km 的辅助驾驶系统,就会真正相信智能驾驶快要到来了。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com