DocTron团队的Chart-R1模型,通过思维链监督和强化学习,使7B参数模型在复杂图表推理中媲美GPT-4o和Claude-3.5。
原文标题:思维链监督和强化的图表推理,7B模型媲美闭源大尺寸模型
原文作者:机器之心
冷月清谈:
首先,研究团队开发了新颖的程序化数据合成技术,利用大型语言模型生成图表绘制代码,并基于这些代码构建包含复杂问题、多步骤思维链推理过程和最终答案的数据。这种方法生成了包含258k多步推理样本的ChartRQA数据集,有效避免了传统有损解析,确保了数据的多样性和真实性。
其次,Chart-R1采用了精妙的两阶段训练策略。在Chart-COT阶段,模型通过思维链监督,学习将复杂的图表推理任务分解为细粒度、可理解的子任务。接着,在Chart-RFT阶段,模型采用数值敏感的强化学习微调方法(群组相对策略优化GRPO),奖励信号结合软匹配和编辑距离,专门针对数值和字符串答案提高准确性。值得一提的是,这两个阶段使用了不同的数据集,这一设计有效避免了强化学习过程中模型探索能力的受损。
实验结果令人瞩目,Chart-R1在多种公开基准测试和自建数据集上表现卓越,不仅超越了现有图表领域方法,甚至在多个任务上媲美GPT-4o和Claude-3.5等闭源大型模型。这充分证明了该方法在处理复杂图表推理任务上的优越性。
该研究的意义深远,它不仅证明了强化学习在需要精确数值推理的视觉多模态任务中的有效性,提出的程序化数据合成方法也为解决多模态数据稀缺提供了新思路,同时其两阶段训练策略为构建高效推理模型提供了实用框架。Chart-R1在商业智能、科学研究、金融报告分析等场景具有广泛应用前景,并为未来多模态推理研究指明了方向。
怜星夜思:
2、论文里提到Chart-R1这个7B的模型能媲美GPT-4o这种大模型,大家觉得这说明了“小而精”的领域模型未来会是主流吗?还是说通用大模型最后还是会通吃一切,只是现在技术还没到那个程度?
3、R1-Style的强化学习在数学、代码领域效果显著,现在又看到它在视觉多模态的图表理解上也很给力。未来RL还能在哪些视觉任务或者多模态任务中发挥更多作用?比如游戏AI、机器人操作、或者创意内容生成方面?
原文内容

近期,随着OpenAI-o1/o3和Deepseek-R1的成功,基于强化学习的微调方法(R1-Style)在AI领域引起广泛关注。这些方法在数学推理和代码智能方面展现出色表现,但在通用多模态数据上的应用研究仍有待深入。
DocTron团队提出的Chart-R1模型在这一背景下应运而生,针对图表这一信息密集型多模态数据类型,开发出一套思维链监督和强化的图表推理方法,通过逐步骤的思维链监督和数值敏感的强化学习微调实现复杂图表推理能力。图表分析不仅需要视觉理解,还需要进行多步骤的数值推理和关系分析,因此这项工作的重要性不言而喻。
DocTron是一个在通用视觉语言模型架构上实现结构化内容解析和理解的开源项目,而无需定制化的模块开发,覆盖通用文档、学科公式、图表代码等场景。
-
论文标题:Chart-R1: Chain-of-Thought Supervision and Reinforcement for Advanced Chart Reasoner
-
论文链接:https://arxiv.org/pdf/2507.15509
-
Github链接:https://github.com/DocTron-hub/Chart-R1
-
项目开源地址:https://huggingface.co/DocTron
创新点与技术突破
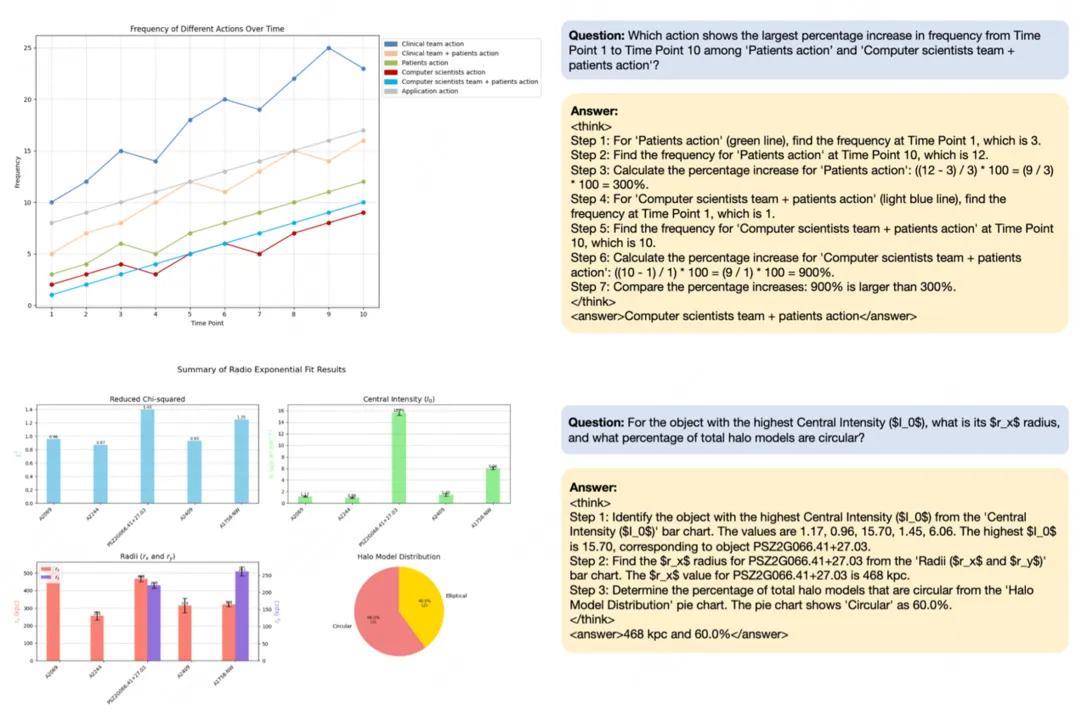
Chart-R1 的核心创新在于其两阶段训练策略和高质量数据合成方法:
1. 程序化数据合成技术:
研究团队开发了一种新颖的程序化数据合成技术,利用 LLM 生成图表绘制代码,并基于这些代码构建复杂问题、多步骤思维链推理过程和最终答案。
这种方法生成了覆盖单图表和多子图表的高质量推理数据,构建了包含 258k 多步推理样本的 ChartRQA 数据集。与现有方法相比,该技术避免了有损解析过程,确保了数据的多样性和真实性。
2. 两阶段训练策略:
-
Chart-COT 阶段:通过思维链监督,训练模型将复杂图表推理任务分解为细粒度、可理解的子任务;
-
Chart-RFT 阶段:采用数值敏感的强化学习微调,使用群组相对策略优化 (GRPO),奖励信号结合软匹配和编辑距离,专门针对数值和字符串答案提高准确性。
这种两阶段策略的独特之处在于为两个阶段使用不同的数据集,避免了在强化学习过程中模型探索能力的受损。
实验结果与性能表现
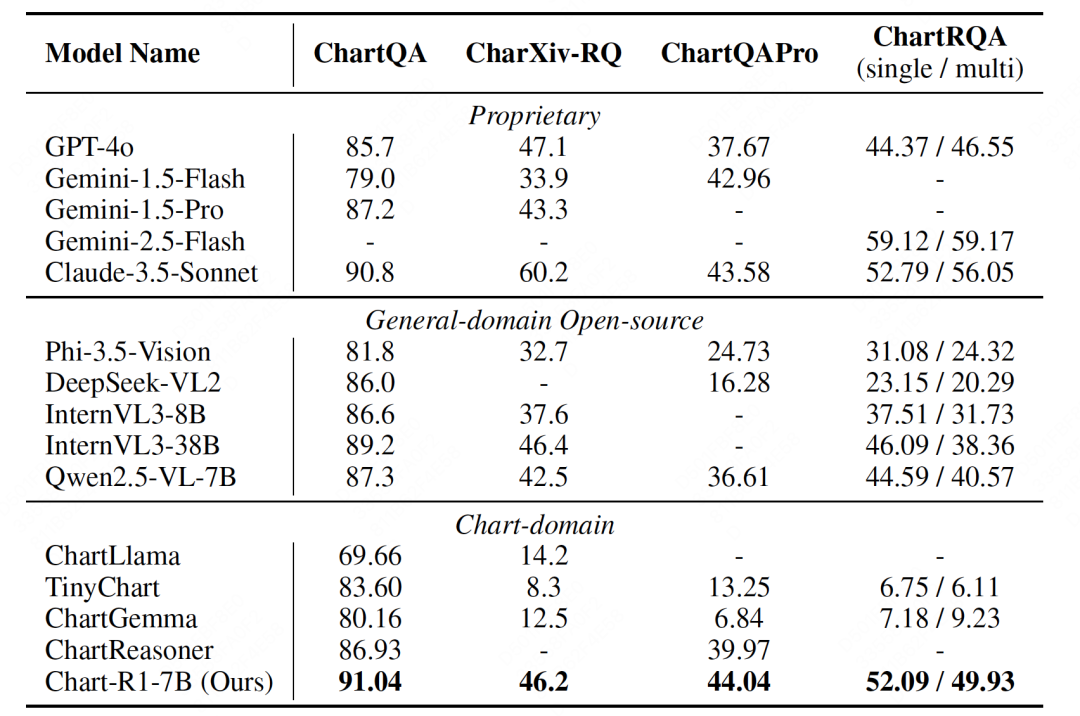
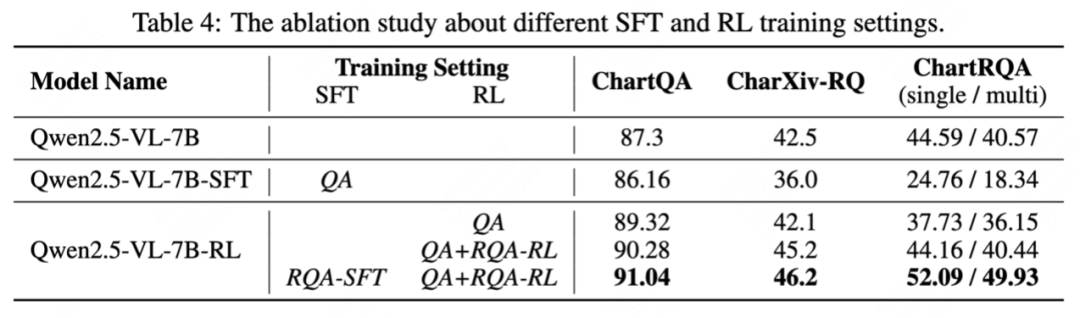
实验结果令人瞩目:Chart-R1 在各种公开基准测试和自建的 ChartRQA 数据集上表现卓越,不仅超越了现有的图表领域方法,甚至在多个任务上媲美 GPT-4o 和 Claude-3.5 等闭源大型模型。
在复杂图表推理任务上,现有视觉语言模型的性能大幅下降,而 Chart-R1 依然保持稳定的高水平表现,这充分证明了该方法在复杂推理任务上的优越性。
研究意义与应用前景
该研究不仅在技术上取得了突破,也为图表理解和推理领域提供了新的研究方向:
-
证明了强化学习在视觉多模态推理任务中的有效性,特别是针对需要精确数值推理的场景;
-
提出的程序化数据合成方法为解决多模态数据稀缺问题提供了新思路;
-
两阶段训练策略为构建高效推理模型提供了实用框架。
在实际应用方面,Chart-R1 可广泛应用于商业智能分析、科学研究数据解读、金融报告分析等需要深度图表理解的场景,大幅提升自动化分析效率。
结论
Chart-R1 的成功表明,通过精心设计的训练策略和高质量数据,即使是参数规模相对较小的模型也能在特定领域达到与大型闭源模型相媲美的性能。这一研究为构建高效、专业的领域特定 AI 模型提供了宝贵经验,也为未来多模态推理研究指明了方向。
该工作不仅是对 R1-Style 方法在多模态领域有效性的验证,更是对如何构建高效专业领域模型的重要探索,值得学术界和产业界的高度关注。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com