北京大学与银河通用发布DyWA模型,赋能机器人全面泛化的非抓握操作,通过世界-动作建模与动力学自适应,实现了零样本迁移。
原文标题:机器人不只会抓和放!北京大学X银河通用「世界-动作模型」赋能全面泛化的非抓握技能
原文作者:机器之心
冷月清谈:
为克服这些难题,北京大学与银河通用共同提出了自适应性“世界-动作模型”(Dynamics-adaptive World Action Model, DyWA)。该模型的核心方法包括:首先,创新性地采用“世界-动作模型”,联合建模机器人执行的动作及其将导致的未来状态。这赋予了机器人“想象力”,使其能在训练过程中隐式地学习并理解物理世界的动力学过程,从而显著提升策略的学习效率与泛化能力。其次,DyWA引入了“动力学自适应机制”。通过分析历史观测与动作序列,模型能够推理出环境中隐含的物理属性,如桌面摩擦系数或物体质量分布,并动态调整操作策略以实现自适应的物理交互。
此外,为确保实际部署的可行性,DyWA仅依赖单个深度相机获取点云作为输入,并结合大规模域随机化仿真训练,实现了从仿真环境到真实机器人的“零样本迁移”。实验结果表明,DyWA在仿真和真机环境中均显著优于现有基线方法,展现出强大的全面泛化能力,不仅能泛化至未训练的物体几何形状和质量分布,还能自适应各种摩擦表面,并具备强大的闭环自适应能力。该模型还可与现有抓取策略及视觉语言大模型协同工作,进一步提升复杂场景下机器人完成任务的成功率。
怜星夜思:
2、文章里说DyWA能让机器人“想象”动作效果,还能“读懂”环境里的摩擦力、物体质量这些“隐含因素”。这听起来很玄乎,大家觉得这种“想象力”和“自适应”机制在实际中具体是怎么实现的?有没有一些例子能帮助理解?
3、DyWA能零样本从仿真迁移到真实世界,这听起来太酷了!是不是意味着以后我们买个机器人,就能直接把它扔到各种新环境里,不用再专门训练就能干活了?但它有没有什么局限性或者适用范围呢?比如对于那些特别精细、或者从未见过的任务,它还能搞定吗?
原文内容

本文的作者团队来自北京大学和银河通用机器人公司。第一作者为北京大学计算机学院前沿计算研究中心博士生吕江燃,主要研究方向为具身智能,聚焦于世界模型和机器人的灵巧操作,论文发表于 ICCV,TPAMI,RSS,CoRL,RAL 等机器人顶会顶刊。本文的通讯作者为北京大学计算机学院教授王亦洲和北京大学助理教授、银河通用创始人及CTO 王鹤。
尽管当前的机器人视觉语言操作模型(VLA)展现出一定的泛化能力,但其操作模式仍以准静态的抓取与放置(pick-and-place)为主。相比之下,人类在操作物体时常常采用推动、翻转等更加灵活的方式。若机器人仅掌握抓取,将难以应对现实环境中的复杂任务。例如,抓起一张薄薄的银行卡,通常需要先将其推到桌边;而抓取一个宽大的盒子,则往往需要先将其翻转立起(如图 1 所示):

这些技能都属于一个重要的领域:非抓握操作(Non-prehensile Manipulation)。非抓握操作泛指不通过夹取、抓握等方式进行物体操控的行为,广泛应用于处理薄片、大型物体、复杂几何或密集场景下的操作任务。然而现实环境的物理属性比较复杂,操作对象的几何形状,质量,桌面的摩擦力等都会成为制约非抓握操作的因素。为了实现对上述环境因素全面泛化的非抓握操作技能,北京大学与银河通用提出了自适应性【世界 - 动作】模型 Dynamics-adaptive World Action Model (DyWA)(/diː.və/),协同学习系统的动力学和机器人的精细操作策略。该项研究已被 ICCV 2025 接收。

-
论文链接:https://arxiv.org/abs/2503.16806
-
论文标题:DyWA: Dynamics-adaptive World Action Model for Generalizable Non-prehensile Manipulation
-
项目主页:https://pku-epic.github.io/DyWA/
-
代码仓库: https://github.com/jiangranlv/DyWA
非抓握操作的两大难点
复杂的接触建模
与抓取相比,非抓握操作涉及连续接触、多变的摩擦力等复杂物理交互。 机器人推一个物体时,摩擦力的微小变化可能导致运动轨迹完全不同:换一块桌布,物体就变得 “推不动” 或 “滑太快”;同一个杯子,空的和装满水时,移动行为完全不同;对于质量分布不均的物体,会出现 “旋转 - 滑动” 的非线性行为。
传统的物理建模或优化方法(如 Trajectory Optimization)虽然可以部分求解这些问题,但依赖精确的物体质量、摩擦系数、几何模型,这些属性难以在真实世界获得。目前的学习方法如 CORN、HACMan 等,主要侧重于仅根据几何信息推理动作,例如 “向左推物体会往左移动”,但它们缺乏对环境中潜在动力学属性(如摩擦、质量、弹性等)的建模与适应能力,导致在面对真实物理扰动时表现急剧下降。
现实感知受限:信息缺失 + 噪声干扰
要实现高质量的非抓取操作,机器人必须知道物体在哪里、姿态如何、表面几何如何接触。这对感知系统提出了极高的要求。
但在现实中,常见传感器面临单视角点云严重遮挡,多视角设置昂贵且繁琐,不适合部署在真实环境或移动平台上;而已有方法常常假设多视角输入、额外的位姿追踪模块,但在现实中难以部署。
DyWA 的核心方法
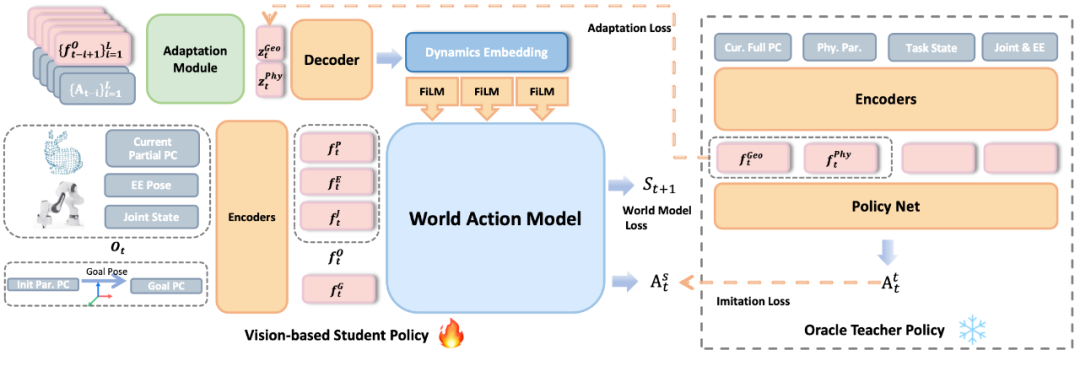
1. 世界 - 动作模型:联合建模动作与未来状态,让策略具备 “想象力”
DyWA 采用标准的 teacher-student 框架,将利用全知信息训练的强化学习教师策略在线蒸馏给一个仅接收点云输入的学生模型。与传统方法仅学习动作输出不同,DyWA 同时预测动作将带来的未来状态,相当于让机器人 “想象” 动作执行后的效果。在训练过程中,模型因此能够隐式建模物理世界的动力学过程,从而显著提升学习效率与泛化能力。该模型被称为 “World Action Model”。实验结果表明,这种联合建模方式可带来更优的策略优化效果和更强的鲁棒性。
2. 动力学自适应机制:从历史中 “读懂” 摩擦、质量等隐含因素
在真实环境中,机器人往往无法直接获知桌面的摩擦系数或物体的质量分布。DyWA 引入了一种类似 RMA(Rapid Motor Adaptation)思想的动态适应模块,通过分析历史观测和动作序列,推理出环境中隐含的物理属性,例如表面是否光滑、物体是否沉重或质量分布是否均匀。同时,历史信息还包含更完整的几何线索,弥补了单帧观测中的缺失。
该动力学表示通过 FiLM 机制调控世界模型的中间特征,使策略在执行过程中能够动态调整 “用力” 或 “稳住” 的程度,实现自适应的物理交互。
3. 单视角输入 + 大规模域随机化仿真训练 + 零样本迁移
考虑到现实部署的可行性,DyWA 设计上仅依赖单个深度相机获取的点云作为输入,不依赖多摄像头系统,也无需外部位姿追踪模块。经过对物理参数(摩擦系数,物体质心分布等)规模域随机化训练后,模型能够实现从仿真到真实机器人的零样本迁移,达成端到端的泛化操控能力。
DyWA 的全面泛化能力
在仿真中,本文搭建了一个全面的 benchmark 用以评估目前 learning-based 方法的表现。可以看到,在已知物体状态(三视角点云),未知物体状态(三视角点云)和未知物体状态(单视角点云)三种设置下,DyWA 都显著优于基线方法,实现了 80 + 成功率的精准操作。
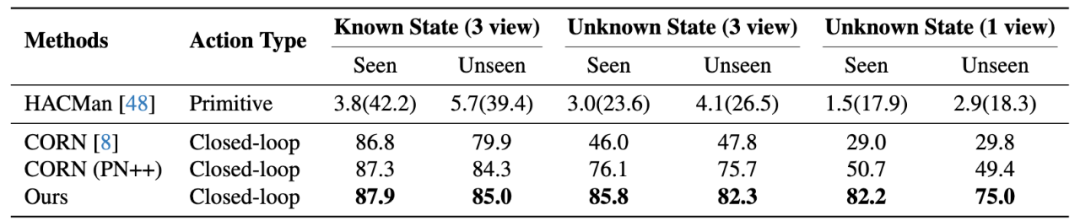
仿真实验结果

真机实验结果
DyWA 可以零样本迁移到真实世界并展现全面泛化性:
1. 不仅对物体几何形状泛化,更对物体质量分布泛化: DyWA 能将桌面上任意形状的未在训练中见到的物体推到目标 6D 位姿,成功率接近 70。无论是底重头轻的咖啡壶,或是摇晃着的半满水瓶,DyWA 都能实现稳健操作

6 倍速播放

原速播放
2. 适应各种摩擦面:无论是高摩擦的瑜伽垫,还是低摩擦易打滑的塑料板,DyWA 都能自适应控制力度,维持操作的鲁棒性。

6 倍速播放
3. 强大的闭环自适应能力:面对光滑的瓶子,DyWA 能在失败几次后适应并成功翻转瓶子

6 倍速播放
另外,DyWA 可与抓取策略及视觉语言大模型(VLM)协同工作。如图 1 所示的例子,在用户通过自然语言指定目标位置后,DyWA 首先将物体推至便于抓取的姿态,再由抓取策略完成任务,从而显著提升复杂场景下的整体成功率。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com