工业数据分析挑战重重,AI赋能生产提效,洞悉异常,探索根因。
原文标题:干货 | 清华大数据智能讲堂:工业数据分析的原理与AI时代的机会
原文作者:数据派THU
冷月清谈:
怜星夜思:
2、郭博士提到了湖北疫情数据和工业数据采集标准导致的分析失真。在实际的智能制造转型中,企业应该如何建立一套健壮且适应性强的数据标准和采集体系,来应对复杂多变的产品和工况?
3、文章提到工业数据常出现“工作点”附近相关性低、检测误差大、难以满足统计假设等问题,这似乎与当前AI领域流行的大数据、大模型训练理念有些出入。在工业场景下,我们应该更侧重于小样本学习、机理模型融合,还是在数据有限的情况下,有什么办法能更好地应用AI大模型的能力?
原文内容

下文整理自前宝钢研究院首席研究员郭朝晖博士在清华大数据智能讲堂做的主题报告《工业数据分析的原理与AI时代的机会》。

大家好,首先我分享一个真实案例。某钢厂炼一炉钢要30~37分钟。容易算出,如果每次炼钢时间都能控制到30分钟左右,就可以提高10%的产量。30分钟是实践中可以实现的;如果某一炉钢冶炼时间超过30分钟,一定是由某种原因导致的。如果能找到并消除这种原因,自然就可以把冶炼时间降低到30分钟。优也得咨询团队按照这种思路去做,最终取得了两个亿的效益。这种做法在工业中叫做对标找差,是一种持续改进的方法。

再讲一个例子。上世纪70年代,上海的弄堂里就有人做光刻机,说明那时我们就懂光刻机最基本的原理。但为什么光刻机现在还是被国外“卡脖子”?其中,我国有一种现象,被称为“引进、落后,再引进、再落后”。所以,我们的落后发生在持续改进阶段。
这两个例子说明:持续改进对现代工业非常重要。数字化技术的一个重要作用,其实就是促进持续改进。
我去年参观一家企业,看见一个大屏。这是很多智能制造企业都有的。看完之后我问:今天的产量、质量、能耗是否正常?结果公司领导都说不知道。我就对他们说:不知道是否正常,也就不知道如何采取行动。不采取行动,也就无法创造价值。这样的大屏有什么用呢?
在工业过程中发现和识别异常是非常重要的。许多场景下,只有发生异常,才有必要进行智能决策和控制,才有持续改进和创新的机会。但是发生异常后,需要先找到根源,这是我们常做的根因分析。这是一类重要的数据分析工作。
理解根因分析,需要区分相关与因果。从事数据分析工作时,因果关系往往是用相关关系来发现的。但做优化和控制时,手段和目的之间需要是因果关系。数据分析师一个常见的错误是混淆相关和因果。

因果关系本质都是通过相关分析得到。从相关关系获取因果关系的困难是什么呢?是存在干扰。在发现科学真理的时候,一定会有干扰,比如,发现牛顿第一定律的困难,就是现实中往往存在摩擦力。发现因果关系的过程,往往就是排除干扰的过程。但在做工业数据分析的时候,我们往往只能用现有的数据做分析,没有办法像科学家一样设计实验。
在科学结论出现之前往往先有很多的假说,发现科学规律的过程其实就是排除错误假说的过程。在这个过程中,要对比哪个假说更准确、简单、解释的问题更多、能预言新事物等。工业分析也往往是这样,需要首先提出各种猜测,然后用数据来检验这些猜测。
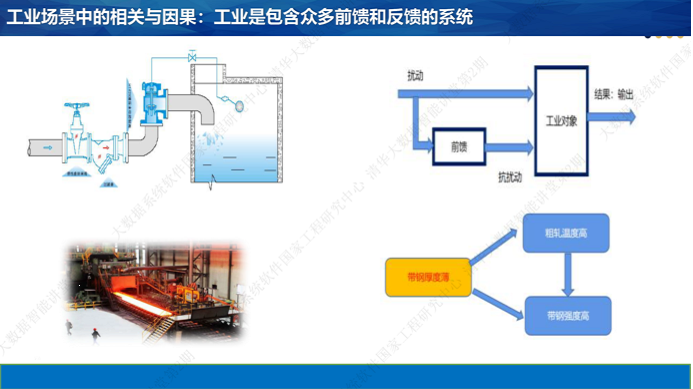
接下来谈工业数据的特点。工业系统往往是复杂的系统,经常存在各种前馈和反馈的环节。存在前馈和反馈时,就容易出现因果混淆。比如用一个阀门控制水的流量。水压大的时候阀门开小一点,压力小的时候阀门开度大一点。所以,我们会发现阀门开度不断变化,但流量基本不变。如果计算两个变量的相关系数,会发现二者接近于0。在这个例子中,阀门开度和流量大小之间存在因果关系,但相关系数机会为0。再如,我研究普通碳钢的力学性能时发现:开始轧钢时的温度越高,带钢的强度越高。从冶金原理上看,二者没有因果关系。但相关性又是如何产生的呢?原来,温度高和带钢强度提升是由带钢薄引发的。带钢薄时散热快,开始轧钢时的温度一般会设置得高一些。同时,带钢薄导致冷却快,冷却快会导致带钢性能提升。如果厚度是固定的,就会发现:开始轧钢时的温度和强度之间的相关性就非常低了。

工业上有个概念叫“工作点”。一类产品的参数往往限制在一个很小的范围之内,这个范围往往在某个关键参数的最优点附近。学会微积分的人都知道:最高点附近的导数为0。所以,在最优点附近,自变量和因变量之间的相关系数接近于0。但这并不说明两者没有因果关系。在工作点附近,往往就把关键自变量控制得特别稳定,检测出来的波动中,检测误差占据了很大的比例。在这种情况下,自变量和因变量之间相关性也特别小。所以在工业系统中,重要变量的作用反而不容易通过相关性分析看出来。
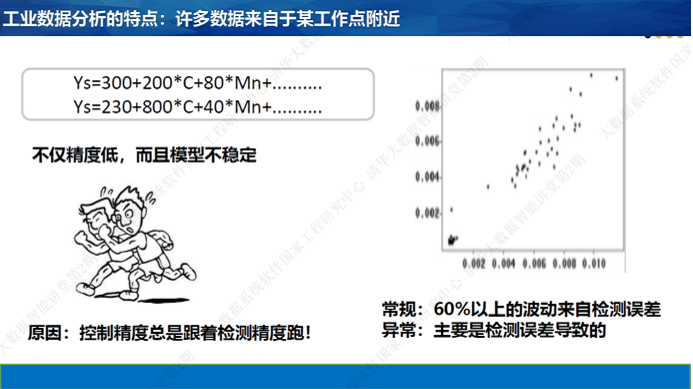
我过去做过一个模型,根据钢铁材料的成分和工艺预报性能。对于同一个钢种,用不同月份数据做模型,系数却相差很远。系数代表某类参数的敏感度。从科学原理上看,系数不应该有大的变化。这种现象曾经让我百思不得其解。后来突然意识到:一种钢种可以理解为一个工作点,成分和工艺参数本身变化很小。这时,检测误差的相对值就就可能比较大了。这种误差对建模的影响很大,就不能忽略了。
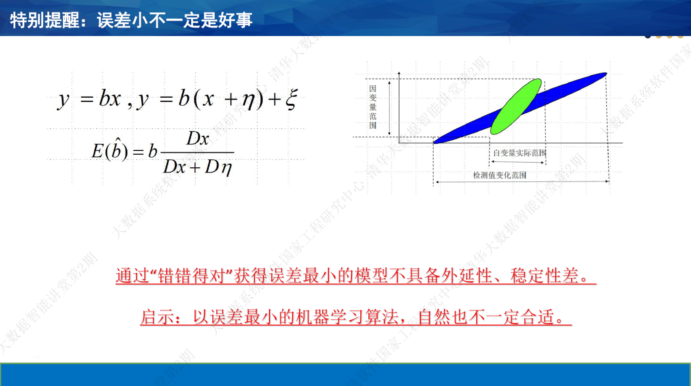
在检测误差相对较大时,最小二乘法会成为有偏估计。也就是说,模型的系数不会逼近真实的物理规律。换句话说,不是误差越小越接近真实。很多人做数据分析或建模时,仅仅追求精度。但在有偏估计的背景下,模型可能不能用来从事控制和优化。注意到:教科书上的最小二乘法往往假设自变量误差可以忽略不计。但这个要求在工业现场往往不能保证,自变量误差往往不能忽视。

数据采集的标准问题也很重要。2020年2月20日,湖北省疫情新增病例349例,武汉市新增615例。武汉市病例数量比整个湖北省还要多,为什么会产生这样的情况?这与当时计算确诊病例标准有关。人们用当日新发现的病例减去过去误判的人数。所以,根据报出来的数据,人们并不知道当日真正新增了多少病例。这种标准会导致疫情防控的误判。所以,后面来的领导明确要求,不准核减过去的误判人数。这在工业上也有类似情况。我们要认识到:每一个数据都是在一定标准下得到,数据采集的标准不同,会导致对分析结果的失真。

在工业过程中,少分析一个变量也会带来很大的问题。统计学上有一种案例叫辛普森悖论。有人做了统计发现:抽烟的人得癌症少,不抽烟的人得癌症多。这个结果与人们的直觉和过去的研究结论相悖。后来,有人把数据拿过来重新分析。前面的分析,是不区分性别的。但如果把男女分开分析,就发现:在男女两组数据中,抽烟得癌症的热多,不抽烟得癌症的人少。之所以有这样的差异,是因为女性吸烟人数少但得癌症人数多。
我们前面提到:企业要持续改进,往往要发现异常。所谓的异常,就是偏离了标准。这个原则很简单,但实际计算起来却可能很麻烦。比如今天生产一万吨钢,是多还是少呢?其实,不同钢种、不同规格,生产效率是不同的。有的钢种一天生产1.3万吨,另一个钢种可能每天只能生产0.8万吨。要计算一天生产多种产品算正常,需要考虑它们的加权平均,还要考虑产品切换以及设备维护所占用的时间。由于统计过程麻烦,很多结论不能及时做出,也就不能及时采取行动、创造价值。
《黑天鹅》中有一个故事。同一个问题,问不同的人。这个问题是:如果硬币连续扔了99次,都是正面朝上。请问第100次正面朝上的概率是多少?对于这一个问题,学术专家会说:这是个随机的独立同分布的事件。不管前面有多少次正面朝上,第100次正面朝上的概率是0.5。但是,如果问到一个有实际经验的人,他会说:第100次仍然正面朝上的一定非常高,专家的观点是错的。专家的观点为什么是错的呢?因为专家假设正面朝上的概率是0.5。但是,你连续扔了99次都正面朝上,你凭什么仍然假设正面朝上的概率是0.5呢?
传统的做数据分析的人,往往都要学习概率统计理论。但是,做工业数据分析时,发现很多统计学办法都失效了。其中的原因是:概率统计理论的成立,是有许多先验性的假设条件的。现实中,这些假设条件往往不成立!
第三部分是根因分析方法。我的感觉是:根因分析问题有三种难度。第一种是根据数据和规则很容易给出答案;第二种是可能的原因有很多却不知道到底是哪个引发;第三种是关键参数都是正常的,但异常却发生了。

第一种很简单,但值得用计算机进行数据分析。计算机的优势在什么地方呢?就是处理复杂问题。很多生产过程极其复杂,比如生产钢铁产品时,有几十、几百道工序。在这种背景下,想要查明原因就要分析大量的数据,特别耽误时间。此时可以发挥计算机的优势,将所有数据集中在一起,按照人的逻辑用计算机分析,可以极大地提升分析效率。这种工作没有什么太高的科技含量,但对工业企业来说价值非常大。

第二种情况是参数出现了问题,但不知道具体是哪个因素导致的。按照前面的观点,遇到这样的问题时,首先是分析师要产生猜测。然后通过数据分析,在猜测中选择正确的。给出猜测时,专业知识会发挥重要的作用。当然,相关性分析、决策树、回归分析等传统的统计方法,也可能帮助我们提出一些猜测。
用机器猜测时常遇到的问题是:有些真正的原因可能看不到相关性。有种典型的情况,就像前面提到的“辛普森悖论”:数据混在一起的时候,就不容易发现因果关系了。比如氮元素对强度有正贡献也有负贡献,如果把不同钢种凑在一起,难以区分正贡献和负贡献。这时,要对数据进行分类、分别进行分析。而分类的依据,往往也是依靠专业知识。
让专业人员猜测时,要尽量把问题细化、分解成尽量基本的“原子问题”。比如,分析机器故障时,要把每种故障当做单独的问题,而不是混在一起分析故障率。再如,如果同一故障有多少种引发可能性,就要尽量每一种可能性分解成单独的问题。分解成原子问题之后,再用数据分析的方法进行筛选或认证。
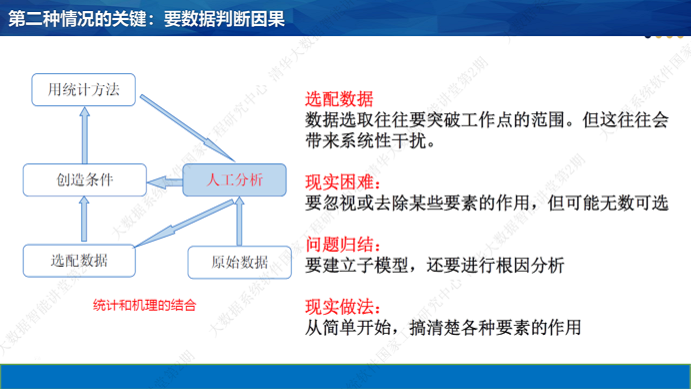
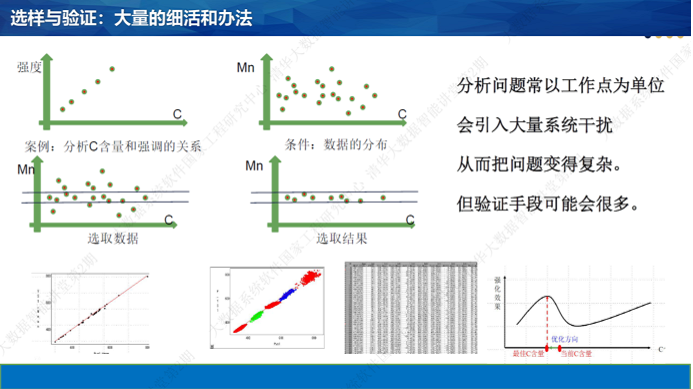
猜测之后的验证。前面曾经提到,在大数据时代,许多传统的统计分析方法无效了。我们如何用数据进行验证呢?对于这类问题,我们的思路是:传统的数据分析方法之所以无效,是因为数据不符合特定的条件和要求。在大数据的背景下,我们可以设法对数据进行筛选和处理,让它们符合概率统计理论的要求。这时的关键,往往是选择和配置数据。就像王进喜说的:没有条件,创造条件也要上。
然而,“创造条件”也很不容易。选数据最好的办法是其他因素不变,只有单个因素变化。很多情况下,我们没有理想的数据可以选择。典型的情况就是:受数据分布的约束,我们无法固定一些干扰因素。这时,我们就要设法把干扰因素的作用搞清楚,在分析问题时设法扣除他们的影响。分析干扰因素的影响时,往往要为干扰因素的作用建立模型。于是,就产生了众多“子模型”问题要解决。
我常用一种去除随机干扰的方法:把一个工作点(比如一个钢种)作为一个单位,对工作点的自变量和因变量取平均值。当一个工作点附近的数据足够多的时候,随机误差基本上可以消除。
数据分析很像科学探索的过程。往往不能把问题看成一个整体,而是要把一个大问题分解成若干个子问题。如果问题分解得好,就比较容易解决。
确认因果关系的时候,我们往往需要多找些证据、学会从不同角度看待问题。数据分析师也应该秉持这样的原则。认定一个结论成立时,首先必须符合机理,其次要从多角度用数据来验证。
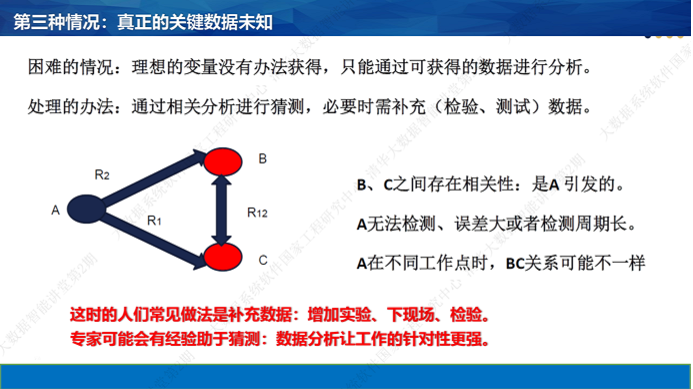
第三种数据分析问题,本质上是没有采集到关键的数据。这时候,还是要设法从发现相关性入手,深入分析下去。相关而非因果的情况,往往可以归纳到一个逻辑上:B和C之间存在相关性,但引发两者发生的原因A是看不到的。所以,看到奇怪的相关性的时候,可以把专家叫过来,讨论什么问题能引发这两种现象。必要时需要采集新的数据。这时,数据分析本身无法给出答案,但有助于人们尽快地找到答案。
大家都知道数据是黄金,但现实发挥的作用却有限。一个重要的原因是挖掘数据成本太高、难度太大。数据分析的过程往往需要既有丰富的专业知识,又具备良好的数据分析和处理能力。这样的人才非常难以培养。人们希望不同专业的人协同完成这样的工作,但现实却往往是协同的效率太低,使得数据分析工作不具备经济性。
随着AI技术的发展,解决这个问题有了新的思路。这就是让懂得专业知识和价值的人,通过AI进行数据分析。这种做法,有可能极大地提升数据分析的效率和质量,从本质上改善数据分析工作的经济性。
视频末尾有完整PPT获取方式~

