悉尼大学LaVin-DiT:融合扩散Transformer和时空VAE,统一20+视觉任务,高效处理图像和视频,实现SOTA表现。#计算机视觉 #AI大模型
原文标题:CVPR-悉尼大学提出LaVin-DiT:扩散Transformer+时空VAE,20+ 视觉任务统一SOTA框架
原文作者:数据派THU
冷月清谈:
该框架主要包括两大核心组件:首先是**时空变分自编码器(ST-VAE)**,它能高效地将高维图像和视频数据压缩到紧凑的潜在空间,有效降低计算需求,同时保留关键的时空特征。ST-VAE通过因果3D卷积进行编码和重建,并分阶段训练以支持图像和视频的处理。
其次是**联合扩散Transformer(J-DiT)**,它在现有扩散Transformer的基础上进行了优化,引入了“全序列联合注意力机制”,能同时处理条件序列和噪声目标序列,增强任务特定的对齐。J-DiT为条件和目标潜在表示构建了独立的补丁嵌入和自适应归一化,以应对其值范围差异,并通过分组查询注意力(grouped-query attention)提升效率和内存使用。此外,LaVin-DiT采用了**上下文学习**机制,通过输入-目标对指导模型适应特定任务;并创新性地使用**3D旋转位置编码(3D RoPE)**,将视觉数据视为连续序列,以3D坐标精确表示时空关系,克服了1D位置嵌入的局限。
LaVin-DiT的训练过程基于流匹配方法,使J-DiT学习预测将噪声转换为干净潜在表示的速度场。在推理阶段,模型能够根据随机采样的任务定义输入-目标对和待查询的视觉数据,通过J-DiT生成潜在表示,再经ST-VAE解码器重建成最终的预测结果。这一创新框架为未来的统一视觉AI模型发展提供了新的范式。
怜星夜思:
2、论文里提到了ST-VAE用于降维和保持时空特征,避免了直接处理像素带来的巨大计算量。除了计算效率,大家觉得ST-VAE在模型理解和生成复杂视觉模式方面,还能发挥什么特别的作用吗?它对LaVin-DiT的“统一”能力有多重要?
3、LaVin-DiT用了3D旋转位置编码来处理时空信息,而不是传统的1D嵌入。这让我想,未来视觉大模型是不是都会越来越倾向于这种更复杂的空间编码方式?或者说,大家对视觉领域的位置编码技术发展有什么期待?
原文内容

来源:PaperEveryday 人工智能前沿讲习本文约4000字,建议阅读8分钟本文介绍了悉尼大学提出LaVin-DiT。
论文信息
题目:LaVin-DiT: Large Vision Diffusion Transformer
LaVin-DiT:大型视觉扩散 Transformer
作者:Zhaoqing Wang、Xiaobo Xia、Runnan Chen、Dongdong Yu、Changhu Wang、Mingming Gong、Tongliang Liu
源码:https://derrickwang005.github.io/LaVin-DiT/
论文创新点
-
引入时空变分自编码器:为处理视觉数据的高维性,LaVin-DiT纳入时空变分自编码器(ST-VAE)。它能将图像和视频数据编码到连续潜在空间,在保留关键时空特征的同时实现紧凑表示,降低计算需求,提升效率,且不影响模型捕捉复杂模式的能力。
-
提出联合扩散Transformer:在生成建模方面,LaVin-DiT对现有扩散Transformer改进,提出具有全序列联合注意力的联合扩散Transformer(J-DiT)。该模块通过并行去噪步骤合成视觉输出,减少序列依赖性,提高处理效率,还能维持视觉任务所需的空间连贯性。
-
采用上下文学习:为支持统一的多任务训练,LaVin-DiT引入上下文学习。输入-目标对作为任务上下文,引导扩散Transformer在潜在空间中使输出与特定任务对齐。
-
使用3D旋转位置编码:LaVin-DiT采用3D旋转位置编码(3D RoPE),将视觉数据视为连续序列,用3D坐标表示位置,为各种视觉任务提供统一且准确的时空位置编码,克服了1D位置嵌入在捕捉时空位置上的局限。
3. 方法
3.1 问题设定
计算机视觉包括一系列任务,如目标检测和全景分割,这些任务通常由为特定输入-目标映射设计的专用模型处理。虽然这种专业化在单个任务中有效,但限制了模型在多个任务或不同视觉数据上的适应性和可扩展性。为了克服这一限制,作者旨在设计一个条件生成框架,将多个视觉任务统一在一个紧密结合的模型中。具体来说,给定一个查询 (例如,一幅图像或一段视频),该框架在一组输入-目标对 的条件下,生成相应的预测 ,以逼近目标 。这些条件对提供了任务定义和指导,使模型能够根据提供的示例灵活地适应不同的任务。形式上,目标是对条件分布 进行建模。
3.2 框架概述
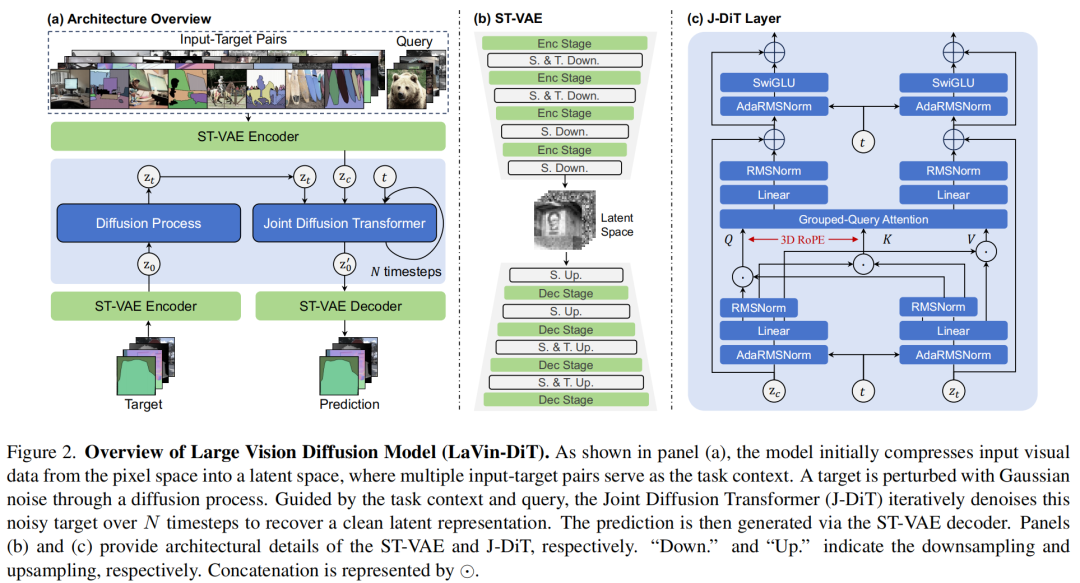
如图2(a)所示,所提出的大型视觉扩散Transformer(LaVin-DiT)框架将时空变分自编码器(ST-VAE)与联合扩散Transformer相结合,以统一多个视觉任务。给定一个视觉任务,例如全景分割,作者首先采样一组输入-目标对作为任务定义。然后,将这组对和其他视觉示例输入到ST-VAE中,编码为潜在表示。随后,将编码后的表示进行分块并展开为序列格式。这组对和输入视觉数据形成条件潜在表示 ,而目标则用随机高斯噪声进行扰动,得到噪声潜在表示 。 和 都被输入到联合扩散Transformer(J-DiT)中,J-DiT对 进行去噪,在共享潜在空间中恢复干净的潜在表示。最后,恢复的潜在表示通过ST-VAE解码器,在原始像素空间中重建目标。下面作者详细介绍ST-VAE和J-DiT的技术细节。
3.3 LaVin-DiT模块
3.3.1 ST-VAE
在原始像素空间中处理视觉数据计算成本很高。为了解决这个问题,作者提出使用时空变分自编码器(ST-VAE)。ST-VAE能够有效地压缩空间和时间信息,并将其从像素空间编码到紧凑的潜在空间中。如图2(b)所示,ST-VAE使用因果3D卷积和反卷积来压缩和重建视觉数据。它总体包括一个编码器、一个解码器和一个潜在正则化层。这些组件被结构化为四个对称阶段,交替进行2倍下采样和上采样。前两个阶段在空间和时间维度上都进行操作,而最后一个阶段仅在空间维度上起作用,实现了4×8×8的有效压缩,降低了计算负载。此外,作者应用Kullback-Leibler(KL)约束来正则化高斯潜在空间。
为了防止未来信息泄漏及其对时间预测的不利影响,作者在时间卷积空间的起始位置对所有位置进行填充。另外,为了支持图像和视频处理,作者将输入视频的第一帧单独处理,仅在空间上进行压缩以保持时间独立性。后续帧则在空间和时间维度上都进行压缩。ST-VAE的编码器将输入压缩到低维潜在空间,通过解码过程实现重建。ST-VAE的训练分两个阶段进行:作者首先仅在图像上进行训练,然后在图像和视频上联合训练。在每个阶段,作者使用均方误差、感知损失和对抗损失的组合来优化模型。
3.3.2 J-DiT
扩散Transformer(DiT)已成为一种强大的生成建模方法。作者的联合扩散Transformer(J-DiT)基于DiT构建,但进行了修改以支持任务条件生成。与原始DiT的一个关键区别是,作者考虑了两种概念上不同的潜在表示。条件潜在表示是干净的,而目标潜在表示受到高斯噪声的扰动,导致两者可能具有不同的值范围。为了处理这种差异并改善任务特定信息和视觉信息之间的对齐,作者为条件和目标潜在构建了单独的补丁嵌入。每个嵌入层使用2×2的补丁大小,以便为每种潜在类型定制表示。如图2所示,采样的时间步 ,以及条件和目标序列,被输入到一系列扩散Transformer层中。基于MM-DiT架构,作者引入了条件和目标特定的自适应RMS归一化(AdaRN),以独立调制每个表示空间。这通过在AdaRN层中为条件和目标设置不同的时间步嵌入来实现。
全序列联合注意力:全序列联合注意力是作者Transformer层的关键,它同时处理条件和噪声目标序列,以增强任务特定的对齐。如图2(c)所示,条件和目标序列被线性投影、连接,然后由双向注意力模块处理,使它们能够在各自的空间中操作,同时考虑对方。为了提高速度和内存效率,作者用分组查询注意力(grouped-query attention)代替多头注意力,分组查询注意力将查询头分组,共享一组键值头。这种方法在减少参数的同时保留了表达能力,性能与标准多头注意力非常接近。此外,为了在更大的模型和更长的序列中稳定训练,作者在查询-键点积之前添加QK-Norm,以控制注意力熵的增长。遵循相关工作,作者还在每个注意力层和前馈神经网络(FFN)层之后应用三明治归一化,以在残差连接中保持激活幅度。
3D旋转位置编码:与一些方法不同,作者认为将视觉数据建模为一维序列不是最优选择,因为一维位置嵌入在捕捉精确的时空位置方面存在局限性。相反,通过将多个图像-注释对或视频片段视为单个连续序列,作者可以使用3D旋转位置编码(3D RoPE)简洁地表示时空关系。这样,视频中的每个位置都可以用一个3D坐标表示。通过引入3D RoPE,作者为各种视觉任务提供了统一且准确的位置编码时空表示。
J-DiT的训练过程:作者在潜在空间中使用流匹配(flow matching)方法训练J-DiT。具体来说,给定一个表示 和噪声 ,流匹配定义了一个基于线性插值的前向过程: ,其中时间步 。这个前向过程诱导了一个随时间变化的速度场 ,它沿着线性路径朝着 的方向驱动流。速度场定义了一个常微分方程(ODE): 。作者使用由 参数化的J-DiT来预测将噪声转换为干净潜在表示的速度场。流匹配的训练目标是直接回归目标速度场,得到条件流匹配(CFM)损失:
J-DiT的生成过程:在J-DiT训练完成后,作者使用它从噪声分布向表示分布进行积分,以生成新的表示。具体来说,从 时的噪声 开始,作者将学习到的J-DiT向后积分到 ,以获得表示 。例如,使用欧拉方法,作者将时间间隔 离散化为 步,步长为 ,表示时间上的向后积分。在每一步 ,作者更新时间和生成的表示如下:
其中 , , , 。通过迭代应用这些更新,作者获得一个新的表示,用于后续ST-VAE的解码过程。
3.4 LaVin-DiT推理
在完成LaVin-DiT的训练后,该模型变得通用,可应用于一系列下游任务。具体来说,当为任何选定的任务给定一个查询(例如,一幅图像或一段视频)时,作者随机采样一组定义该任务的输入-目标对。这些对与视觉输入和高斯噪声分量一起被输入到联合扩散Transformer(J-DiT)中。在J-DiT中,这些元素被处理以生成潜在表示。最后,这个潜在表示通过ST-VAE解码器,转换到原始像素空间,产生所需的预测。为了更好地理解这个推理过程,请参考图2(a)。
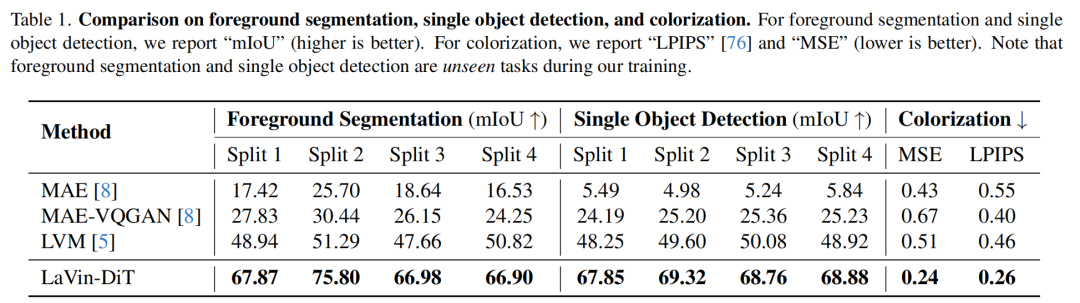
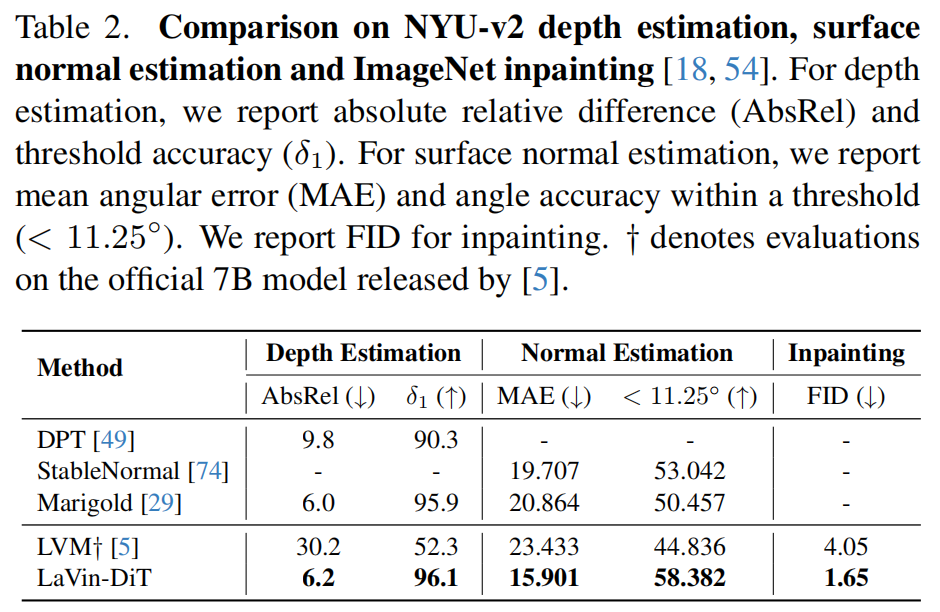
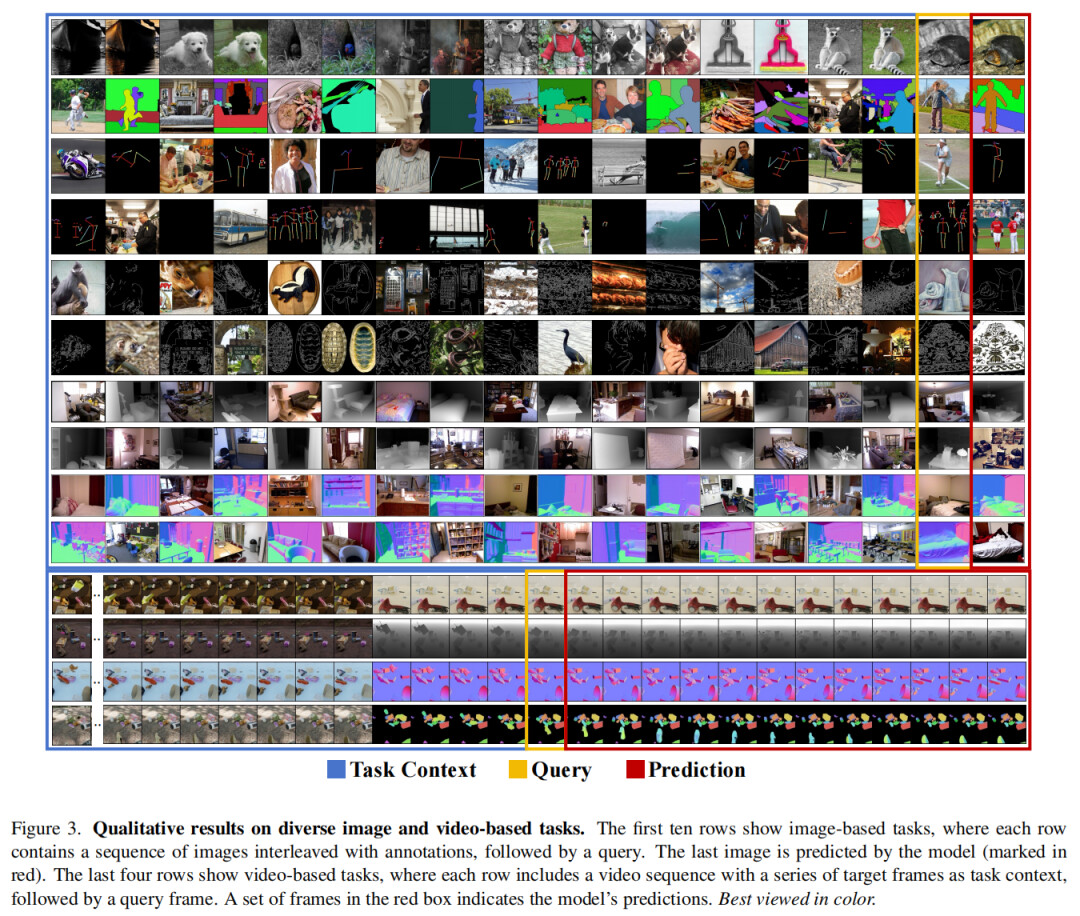
4. 实验