ACL 2025华人团队大放异彩,深思与北大团队斩获最佳论文,揭示大模型对齐挑战与长上下文突破。
原文标题:刚刚,DeepSeek梁文锋NSA论文、北大杨耀东团队摘得ACL 2025最佳论文
原文作者:机器之心
冷月清谈:
另一篇由北大杨耀东团队主导的最佳论文《大语言模型抵抗对齐:来自数据压缩的证据》则从理论与实验层面首次揭示了大型模型存在的“弹性”机制,即其结构性惯性会使其在微调后仍可能回弹到预训练状态,从而抵抗人类指令。这指出对齐的难度远超预期,可能需要与预训练相当甚至更多的后训练资源。这一发现对AI安全与对齐研究提出了严峻挑战,甚至暗示模型可能“装作学会了”而不是真正学会。此外,斯坦福大学与CISPA等团队也贡献了两篇最佳论文,分别探讨了LLM采样行为中的描述性与规范性偏差,以及在特定情境下通过“差异意识”实现公平性的新视角。大会还颁发了包括杰出论文、最佳Demo、最佳主题论文、TACL最佳论文、时间检验奖、终身成就奖(Kathy McKeown教授)和杰出服务奖(Julia B. Hirschberg教授)在内的多个重要奖项,共同展现了计算语言学和自然语言处理领域的最新进展与深远影响。
怜星夜思:
2、斯坦福那篇最佳论文提到“公平性可以通过差异意识实现”,甚至在某些情境下“区别对待是必要的”。这听起来有点挑战传统观念里“一视同仁”的公平原则。大家觉得在实际应用中,比如医疗、招聘或教育领域,这种“差异意识”的公平观应该如何平衡和落地?会不会导致新的偏见?
3、DeepSeek那篇NSA论文,主要解决了大模型长上下文处理的效率问题。除了稀疏注意力机制,业界还有哪些方向在努力突破大模型的长上下文瓶颈?未来会不会出现某种革命性的新技术,彻底改变模型的上下文处理能力?
原文内容
机器之心编辑部
在这届 ACL 大会上,华人团队收获颇丰。
ACL 是计算语言学和自然语言处理领域的顶级国际会议,由国际计算语言学协会组织,每年举办一次。一直以来,ACL 在 NLP 领域的学术影响力都位列第一,它也是 CCF-A 类推荐会议。今年的 ACL 大会已是第 63 届,于 2025 年 7 月 27 日至 8 月 1 日在奥地利维也纳举行。

今年总投稿数创历史之最,高达 8000 多篇(去年为 4407 篇),分为主会论文和 Findings,二者的接收率分别为 20.3% 和 16.7%。
根据官方数据分析,在所有论文的第一作者中,超过半数作者来自中国(51.3%),而去年不到三成(30.6%)。紧随中国,美国作者的数量排名第二,但只占 14.0%。

今年共评选出 4 篇最佳论文,2 篇最佳社会影响力论文、3 篇最佳资源论文、3 篇最佳主题论文、26 篇杰出论文,2 篇 TACL 最佳论文、1 篇最佳 Demo 论文以及 47 篇 SAC Highlights。

以下是具体的获奖信息。
最佳论文奖
在本届4篇最佳论文中,DeepSeek(梁文锋参与撰写)团队以及北大杨耀东团队摘得了其中的两篇,另外两篇则由CISPA 亥姆霍兹信息安全中心&TCS Research&微软团队以及斯坦福大学&Cornell Tech团队获得。
论文 1:A Theory of Response Sampling in LLMs: Part Descriptive and Part Prescriptive

-
作者: Sarath Sivaprasad, Pramod Kaushik, Sahar Abdelnabi, Mario Fritz
-
机构:CISPA 亥姆霍兹信息安全中心、TCS Research、微软
-
论文地址:https://arxiv.org/abs/2502.01926
论文摘要:大型语言模型 (LLM) 在自主决策中的应用日益广泛,它们从广阔的行动空间中采样选项。然而,指导这一采样过程的启发式方法仍未得到充分探索。该团队研究了这种采样行为,并表明其底层启发式方法与人类决策的启发式方法相似:由概念的描述性成分(反映统计常态)和规范性成分(LLM 中编码的隐含理想值)组成。
该团队表明,样本偏离统计常态向规范性成分的偏差,在公共卫生、经济趋势等各种现实世界领域的概念中始终存在。为了进一步阐明这一理论,该团队证明 LLM 中的概念原型会受到规范性规范的影响,类似于人类的「正常」概念。
通过案例研究和与人类研究的比较,该团队表明在现实世界的应用中,LLM 输出中样本向理想值的偏移可能导致决策出现显著偏差,从而引发伦理担忧。
论文 2:Fairness through Difference Awareness: Measuring Desired Group Discrimination in LLMs

-
作者:Angelina Wang, Michelle Phan, Daniel E. Ho, Sanmi Koyejo
-
机构:斯坦福大学、Cornell Tech
-
论文地址:https://arxiv.org/abs/2502.01926
论文摘要:算法公平性传统上采用了种族色盲(即无差异对待)这种数学上方便的视角。然而,该团队认为,在一系列重要的情境中,群体差异意识至关重要。例如,在法律语境和危害评估中,区分不同群体可能是必要的。因此,与大多数公平性研究不同,我们通过区别对待人们的视角来研究公平性 —— 在合适的情境下。
该团队首先引入了描述性(基于事实)、规范性(基于价值观)和相关性(基于关联)基准之间的重要区别。这一区别至关重要,因为每个类别都需要根据其具体特征进行单独的解释和缓解。
然后,他们提出了一个由八个不同场景组成的基准套件,总共包含 16,000 个问题,使我们能够评估差异意识。
最后,该研究展示了十个模型的结果,这些结果表明差异意识是公平的一个独特维度,现有的偏见缓解策略可能会适得其反。
论文 3:Language Models Resist Alignment: Evidence From Data Compression

-
论文地址:https://aclanthology.org/2025.acl-long.1141.pdf
-
项目地址:https://pku-lm-resist-alignment.github.io
该论文首次从理论与实验层面系统性揭示:大模型并非可以任意塑造的白纸,其参数结构中存在一种弹性机制 —— 该机制源自预训练阶段,具备驱动模型分布回归的结构性惯性,使得模型在微调后仍可能弹回预训练状态,进而抵抗人类赋予的新指令,导致模型产生抗拒对齐的行为。这意味着对齐的难度远超预期,后训练(Post-training)所需的资源与算力可能不仅不能减少,反而需要与预训练阶段相当,甚至更多。
论文指出:模型规模越大、预训练越充分,其弹性越强,对齐时发生回弹的风险也越高。换言之,目前看似有效的对齐方法可能仅停留在表面、浅层,要实现深入模型内部机制的稳健对齐仍任重道远。这一发现对 AI 安全与对齐提出了严峻挑战:模型可能不仅学不动,甚至可能装作学会了,这意味着当前 LLMs、VLMs 及 VLAs 的预训练与后训练微调对齐过程面临新的难题。
ACL 2025 审稿人及大会主席高度认可该项研究。一致认为,论文提出「弹性」概念突破性地揭示了大语言模型在对齐过程中的抵抗与回弹机制,为长期困扰该领域的对齐脆弱性问题提供了新的理论视角与坚实基础。领域主席则进一步指出,论文在压缩理论、模型扩展性与安全对齐之间搭建起桥梁,不仅实证扎实、理论深入,更具深远的治理和安全启发意义。
论文的(独立)通讯作者为杨耀东博士,现任北京大学人工智能研究院研究员、智源学者(大模型安全负责人)、北大 - 灵初智能联合实验室首席科学家。
论文的第一作者均为杨耀东课题组成员,包括:吉嘉铭,王恺乐,邱天异,陈博远,周嘉懿。合作者包括智源研究院安全中心研究员戴俊韬博士以及北大计算机学院刘云淮教授。

论文 4:Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention

-
作者:Jingyang Yuan, Huazuo Gao, Damai Dai, Junyu Luo, Liang Zhao, Zhengyan Zhang, Zhenda Xie, Y. X. Wei, Lean Wang, Zhiping Xiao, Yuqing Wang, Chong Ruan, Ming Zhang, Wenfeng Liang, Wangding Zeng
-
机构:DeepSeek、北大、华盛顿大学
-
论文地址:https://arxiv.org/pdf/2502.11089
论文摘要:这篇论文由幻方科技、DeepSeek 创始人梁文锋亲自挂名,提出了一种新的注意力机制 ——NSA。这是一个用于超快长上下文训练和推断的本地可训练的稀疏注意力机制,并且还具有与硬件对齐的特点。
长上下文建模是下一代大型语言模型(LLM)的关键能力,这一需求源于多样化的实际应用,包括深度推理、仓库级代码生成以及多轮自动智能体系统等。
实现高效长上下文建模的自然方法是利用 softmax 注意力的固有稀疏性,通过选择性计算关键 query-key 对,可以显著减少计算开销,同时保持性能。最近这一路线的进展包括多种策略:KV 缓存淘汰方法、块状 KV 缓存选择方法以及基于采样、聚类或哈希的选择方法。尽管这些策略前景广阔,现有的稀疏注意力方法在实际部署中往往表现不佳。许多方法未能实现与其理论增益相媲美的加速;此外,大多数方法主要关注推理阶段,缺乏有效的训练时支持以充分利用注意力的稀疏模式。
为了克服这些限制,部署有效的稀疏注意力必须应对两个关键挑战:硬件对齐的推理加速和训练感知的算法设计。这些要求对于实际应用实现快速长上下文推理或训练至关重要。在考虑这两方面时,现有方法仍显不足。
因此,为了实现更有效和高效的稀疏注意力,DeepSeek 提出了一种原生可训练的稀疏注意力架构 NSA,它集成了分层 token 建模。
如下图所示,NSA 通过将键和值组织成时间块(temporal blocks)并通过三条注意力路径处理它们来减少每查询计算量:压缩的粗粒度 token、选择性保留的细粒度 token 以及用于局部上下文信息的滑动窗口。随后,作者实现了专门的核以最大化其实际效率。

研究通过对现实世界语言语料库的综合实验来评估 NSA。在具有 260B token 的 27B 参数 Transformer 骨干上进行预训练,作者评估了 NSA 在通用语言评估、长上下文评估和链式推理评估中的表现。作者还进一步比较了在 A100 GPU 上内核速度与优化 Triton 实现的比较。实验结果表明,NSA 实现了与 Full Attention 基线相当或更优的性能,同时优于现有的稀疏注意力方法。
此外,与 Full Attention 相比,NSA 在解码、前向和后向阶段提供了明显的加速,且加速比随着序列长度的增加而增加。这些结果验证了分层稀疏注意力设计有效地平衡了模型能力和计算效率。
杰出论文奖
ACL 2025 共选出了 26 篇杰出论文,足足占据了 6 页幻灯片:

1、A New Formulation of Zipf's Meaning-Frequency Law through Contextual Diversity.
2、All That Glitters is Not Novel: Plagiarism in Al Generated Research.
3、Between Circuits and Chomsky: Pre-pretraining on Formal Languages Imparts Linguistic Biases.
4、Beyond N-Grams: Rethinking Evaluation Metrics and Strategies for Multilingual Abstractive Summarization
5、 Bridging the Language Gaps in Large Language Modeis with inference-Time Cross-Lingual Intervention.
6、Byte Latent Transformer: Patches Scale Better Than Tokens.
7、Capability Salience Vector: Fine-grained Alignment of Loss and Capabilities for Downstream Task Scaling Law.
8、From Real to Synthetic: Synthesizing Millions of Diversified and Complicated User Instructions with Attributed Grounding.
9、HALoGEN: Fantastic tiM Hallucinations and Where to Find Them,
10、HateDay: Insights from a Global Hate Speech Dataset Representative of a Day on Twitter.
11、IoT: Embedding Standardization Method Towards Zero Modality Gap.
12、IndicSynth: A Large-Scale Multilingual Synthetic Speech Dataset for Low-Resource Indian Languages.
13、LaTIM: Measuring Latent Token-to-Token Interactions in Mamba Models.
14、Llama See, Llama Do: A Mechanistic Perspective on Contextual Entrainment and Distraction in LLMs.
15、LLMs know their vulnerabilities: Uncover Safety Gaps through Natural Distribution Shifts.
16、Mapping 1,0o0+ Language Models via the Log-Likelihood Vector.
17、MiniLongBench: The Low-cost Long Context Understanding Benchmark for Large Language Models.
18、PARME: Parallel Corpora for Low-Resourced Middle Eastern Languages.
19、Past Meets Present: Creating Historical Analogy with Large Language Models.
20、Pre3: Enabling Deterministic Pushdown Automata for Faster Structured LLM Generation.
21、Rethinking the Role of Prompting Strategies in LLM Test-Time Scaling: A Perspective of Probability Theory.
22、Revisiting Compositional Generalization Capability of Large Language Models Considering Instruction Following Ability.
23、Toward Automatic Discovery of a Canine Phonetic Alphabet.
24、Towards the Law of Capacity Gap in Distilling Language Models.
25、Tuning Trash into Treasure: Accelerating Inference of Large Language Models with Token Recycling.
26、Typology-Guided Adaptation for African NLP.
最佳 Demo 论文奖
获奖论文:OLMoTrace: Tracing Language Model Outputs Back to Trillions of Training Tokens

-
作者:Jiacheng Liu 等
-
机构:艾伦人工智能研究所等
-
链接:https://arxiv.org/pdf/2504.07096
-
简介:论文提出了 OLMOTRACE—— 首个能够实时将语言模型的输出追溯回其完整、数万亿 token 级别训练数据的系统。
最佳主题论文奖

论文 1:MaCP: Minimal yet Mighty Adaptation via Hierarchical Cosine Projection.
-
作者:Yixian Shen, Qi Bi, Jia-Hong Huang, Hongyi Zhu, Andy D. Pimentel, Anuj Pathania
-
机构:阿姆斯特丹大学
-
链接:https://arxiv.org/pdf/2505.23870
简介:该论文提出了一种新的自适应方法 MaCP,即简约而强大的自适应余弦投影(Minimal yet Mighty adaptive Cosine Projection),该方法在对大型基础模型进行微调时,仅需极少的参数和内存,却能实现卓越的性能。
论文 2:Meta-rater: A Multi-dimensional Data Selection Method for Pre-training Language Models
-
作者:Xinlin Zhuang、Jiahui Peng、Ren Ma 等
-
机构:上海人工智能实验室、华东师范大学
-
链接:https://arxiv.org/pdf/2504.14194
简介:论文提出用四个维度来衡量数据质量:专业性、可读性、推理深度和整洁度,并进一步提出 Meta-rater:一种多维数据选择方法,将上述维度与既有质量指标通过习得的最优权重整合。
论文 3:SubLlME: Subset Selection via Rank Correlation Prediction for Data-Efficient LLM Evaluation
-
作者:Gayathri Saranathan、Cong Xu 等
-
机构:惠普实验室等
-
链接:https://aclanthology.org/2025.acl-long.1477.pdf
简介:大型语言模型与自然语言处理数据集的迅速扩张,使得进行穷尽式基准测试在计算上变得不可行。受国际数学奥林匹克等高规格竞赛的启发 —— 只需少量精心设计的题目即可区分顶尖选手 —— 论文提出 SubLIME,可在保留排名保真度的同时,将评估成本降低 80% 至 99%。
TACL 最佳论文奖
ACL 2025 颁发了两篇 TACL 最佳论文,分别如下:

论文 1:Weakly Supervised Learning of Semantic Parsers for Mapping Instructions to Actions.
-
作者:Yoav Artzi、Luke Zettlemoyer
-
机构:华盛顿大学
-
论文链接:https://www.semanticscholar.org/paper/Weakly-Supervised-Learning-of-Semantic-Parsers-for-Artzi-Zettlemoyer/cde902f11b0870c695428d865a35eb819b1d24b7
简介:语言所处的上下文为学习其含义提供了强有力的信号。本文展示了如何在一个具身的 CCG 语义解析方法中利用这一点,该方法学习了一个联合的意义与上下文模型,用于解释并执行自然语言指令,并可适用于多种类型的弱监督方式。
论文 2:Reading Subtext: Evaluating Large Language Models on Short Story Summarization with Writers.
-
作者:Melanie Subbiah, Sean Zhang, Lydia B. Chilton、Kathleen McKeown.
-
机构:哥伦比亚大学
-
论文链接:https://arxiv.org/pdf/2403.01061
简介:本文评估了当前主流的大型语言模型(LLMs)在摘要短篇小说这一具有挑战性的任务中的表现。该任务涉及较长文本,并常常包含微妙的潜台词或被打乱的时间线。本文进行了定量与定性分析,对 GPT-4、Claude-2.1 和 LLaMA-2-70B 三种模型进行了比较。研究发现,这三种模型在超过 50% 的摘要中都出现了事实性错误,并在处理细节性内容和复杂潜台词的理解方面存在困难。
时间检验奖
今年,ACL 宣布了两个时间检验奖: 25-Year ToT Award (2000) 和 10-Year ToT Award (2015),即二十五年时间检验奖和十年时间检验奖。
二十五年时间检验奖(来自 ACL 2000):Automatic Labeling of Semantic Roles

-
作者:Daniel Gildea、Daniel Jurafsky
-
机构:加州大学伯克利分校、科罗拉多大学
-
地址:https://aclanthology.org/P00-1065.pdf
这篇论文提出了一个系统,可用于识别句子成分在语义框架内所承担的语义关系或语义角色。该系统可从句法分析树中提取各种词汇和句法特征,并利用人工标注的训练数据来构建统计分类器。ACL 在官方声明中称,这是一篇奠定了语义角色标注及其后续研究的基础性论文。目前,该论文的被引量为 2650。
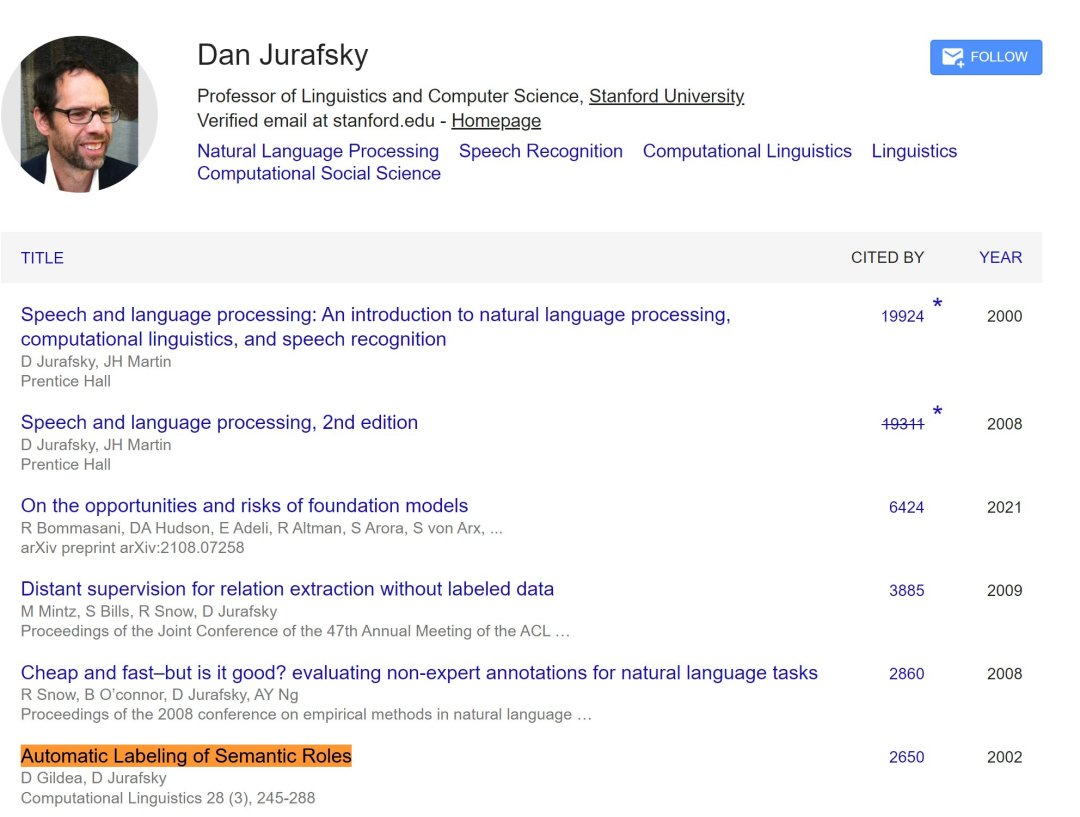
该论文的两位作者 ——Daniel Gildea 现在是美国罗切斯特大学计算机科学系的教授;Daniel Jurafsky 是斯坦福大学语言学和计算机科学系教授,也是自然语言处理领域的泰斗级人物,他与 James H. Martin 合著的《语音与语言处理》(Speech and Language Processing)被翻译成 60 多种语言,是全球 NLP 领域最经典的教科书之一。
十年时间检验奖(来自 EMNLP 2015):Effective Approaches to Attention-based Neural Machine Translation

-
作者:Minh-Thang Luong、Hieu Pham、Christopher D. Manning
-
机构:斯坦福大学计算机科学系
-
地址:https://aclanthology.org/D15-1166/
这篇论文由大名鼎鼎的 Christopher D. Manning 团队撰写。ACL 官方称其为有关神经机器翻译和注意力机制的里程碑之作。
当时,注意力机制已经被用于改进神经机器翻译,通过在翻译过程中选择性地关注源句子的部分内容来提升性能。然而,针对基于注意力的神经机器翻译探索有效架构的工作还很少。这篇论文研究了两类简单而有效的注意力机制:全局方法 —— 始终关注所有源词;局部方法 —— 每次只关注源词的一个子集。论文在 WMT 英德双向翻译任务上验证了这两种方法的有效性。使用局部注意力机制,作者在已经融合了 dropout 等已知技术的非注意力系统基础上取得了 5.0 个 BLEU 分数点的显著提升。他们使用不同注意力架构的集成模型在 WMT'15 英译德翻译任务上取得了新的 SOTA 结果,达到 25.9 BLEU 分数,比当时基于神经机器翻译和 n-gram 重排序器的最佳系统提升了 1.0 个 BLEU 分数点。
这篇论文提出的全局注意力和局部注意力简化了 Bahdanau 的复杂结构,引入了「点积注意力」计算方式,为后续 Q/K/V 的点积相似度计算奠定了基础。

目前,该论文的被引量已经超过 1 万。论文一作 Minh-Thang Luong 博士毕业于斯坦福大学,师从斯坦福大学教授 Christopher Manning,现在是谷歌的研究科学家。
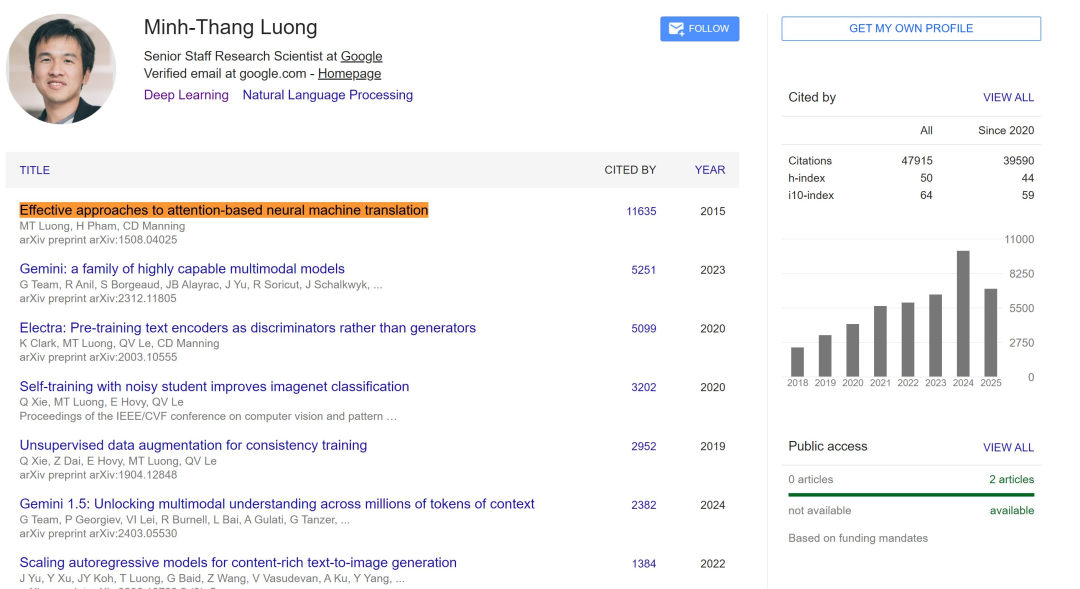
论文二作 Hieu Pham 则目前就职于 xAI;之前还在 AugmentCode 和 Google Brain 工作过。
至于最后的 Manning 教授更是无需过多介绍了,这位引用量已经超过 29 万的学术巨擘为 NLP 和 AI 领域做出了非常多开创性和奠基性工作,同时还在教育和人才培养方面出了巨大贡献。
顺带一提,Manning 教授参与的论文《GloVe: Global Vectors for Word Representation》也曾获得 ACL 2024 十年时间检验奖;另一篇论文《Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank》也获得了 ACL 2023 十年时间检验奖。因此,这是 Manning 教授连续第三年喜提 ACL 十年时间检验奖。
终身成就奖
本年度 ACL 终身成就奖的获得者是 Kathy McKeown 教授。

ACL 官方推文写道:「43 年来,她在自然语言处理领域进行了杰出、富有创意且成果丰硕的研究,研究领域涵盖自然语言生成、摘要和社交媒体分析。」McKeown 教授不仅奠定了 NLP 的基础,还通过她的远见卓识、领导力和指导精神激励了一代又一代的研究者。
目前,McKeown 是哥伦比亚大学计算机科学 Henry and Gertrude Rothschild 教授。她也是哥伦比亚大学数据科学研究所的创始主任,并于 2012 年 7 月至 2017 年 6 月担任该研究所所长。
1998 年至 2003 年,她曾担任工程与应用科学学院系主任,之后还担任了两年科研副院长。
McKeown 于 1982 年获得宾夕法尼亚大学计算机科学博士学位,此后一直在哥伦比亚大学任教。她的研究兴趣包括文本摘要、自然语言生成、多媒体解释、问答和多语言应用。
据谷歌学术统计,McKeown 教授目前的论文总引用量已经超过 3.3 万。

杰出服务奖
ACL 2025 还颁发了一个杰出服务奖(Distinguished Service Award),旨在表彰对计算语言学界做出杰出且持续贡献的人。
今年的获奖者是哥伦比亚大学计算机科学教授 Julia B. Hirschberg。

ACL 官方写道:「35 年来,她一直致力于服务 ACL 及其相关期刊《计算语言学(Computational Linguistics)》(包括担任《计算语言学》主编,并于 1993 年至 2003 年担任 ACL 执行委员会委员),同时也为自然语言处理和语音处理领域做出了卓越贡献。
对于Deepseek NSA论文获奖,你怎么看?欢迎评论交流。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com