一次Java服务OOM全景复盘:从线程激增到RocksDB堆外内存泄漏,最终转向Flink写入Paimon,成功化解危机。
原文标题:OOM排查之路:一次曲折的线上故障复盘
原文作者:阿里云开发者
冷月清谈:
怜星夜思:
2、文章中提到,第二次OOM排查堆外内存泄漏的过程非常曲折,即使使用了NMT、async-profiler等工具也未能直接定位到根本原因。在实际工作中,除了文中提及的工具,你还认为有哪些有效的经验、方法论或进阶工具可以帮助我们排查复杂的堆外内存问题?
3、文章最终将Paimon的写入方式从“应用自行写入”切换到了“通过Flink写入”。除了文中提到的Flink在资源管理、Exactly-Once语义、批流一体等方面的优势之外,这种架构转变还可能带来哪些潜在的挑战或者说是需要权衡的方面呢?
原文内容
本文旨在将这段“曲折”的排查经历抽丝剥茧,分享我们是如何一步步逼近真相并最终解决问题的,希望能为使用相似技术栈的朋友带来一些启发。
一、问题的发现&解决
1.1 第一次OOM
现象
某天早上,收到了服务的线上告警,发现大批量RPC请求都失败了,登录相关的服务平台才发现,所有对外的RPC服务,全部都下线了。
根据故障排查的经验,此时应该先对服务进行止血,并且保留现场用于排查问题,于是在重启一台机器后,观察另一台机器的监控指标,在监控指标中,我们注意到了一个异常现象。
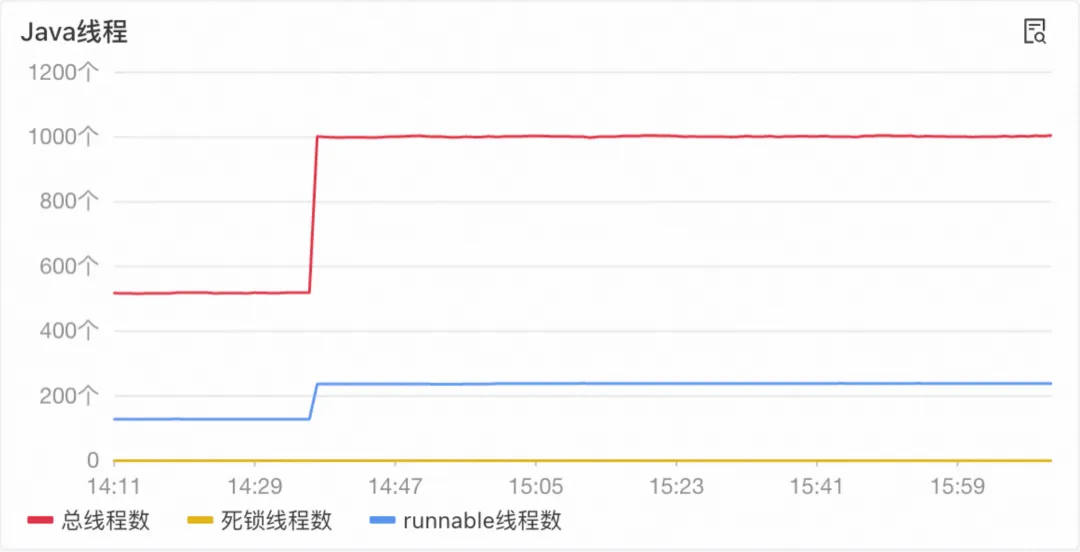
Java线程数量如上图所示,Runnable的线程数量在某个时间点突增(上图只截取了一部分时间的监控,实际上线程数量会在一些固定时间点突增)。
排查
这些固定时间,自然成为了我们首先怀疑的方向,这些固定时间,均是在整点附近,而我们的服务是在整点,通过定时任务调度SDK向Paimon表中写入数据。
我们询问了提供相关SDK的团队同学,一起排查后发现,我们所建的Paimon表是依赖公司内部其他中间建表的,在没有指定bucket数量时,会默认100个bucket,而SDK会在每张表的每一个bucket在写的时候都会开一个线程,最终就会有 表数量 x 100 个线程在跑,这个数量也符合我们观察到的Java线程数。
解决
后续和相关同学沟通后,决定减少bucket数量,根据查阅相关资料,Paimon表的bucket数量应该参考以下设置:
-
数据量较小的场景(OLTP场景)
-
设置较小的bucket数量,一般在4-16之间,较少的bucket数量也可以对查询效率有一些提升。
-
海量数据(高并发流式写入场景)
-
设置64、128、256个bucket
总体来说可以参考以下公式,设置为2的次方个bucket
bucket数量 ≈ (预计的最大写入并行度) * N (其中 N 通常取 1 到 4)
在调整bucket数量后,修复上线,线程数降到了理想范围,解决了线程数量突增的问题。
1.2 第二次OOM
现象
上次OOM问题解决后,我们加强了服务的相关告警。然而时隔20多天后,线上服务又告警了,现象依旧是所有对外的RPC服务全部下线了。
登录监控平台查看相关JVM信息,Java线程数一切正常,但是内存占用率已经到了95%+。
登录机器,使用如下命令,发现Java进程被Kill了。
dmesg | grep -i "killed process"
将监控平台对内存利用率的查询时间周期拉长后发现,自从上次重启之后,内存利用率一直在缓慢上升。
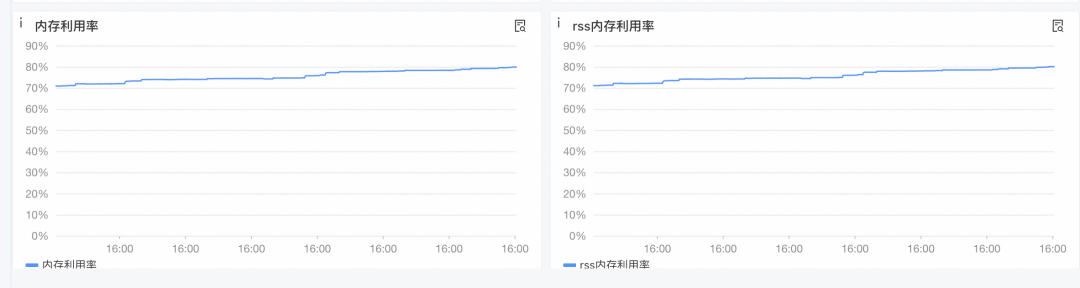
因为内存利用率是缓慢上升,而非突增,只能随着时间的推移,不断地排查内存泄漏的原因,于是我们开启了一段为期半个月的内存泄漏排查旅程。
排查
堆内排查
首先,我们对JVM内存相关的监控指标进行了排查,观察是否由堆内存泄漏导致的OOM。
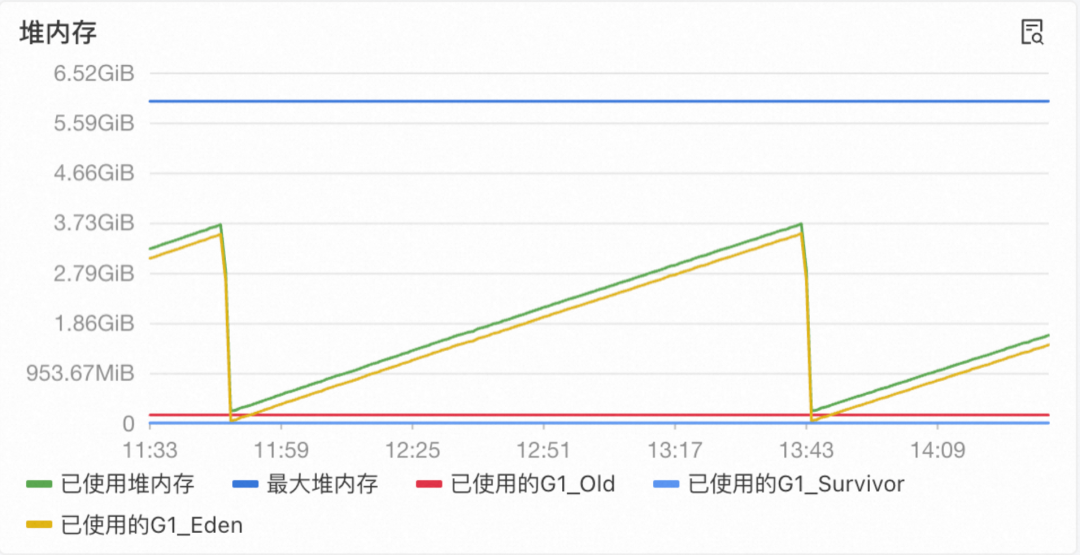
监控突变如上所示,从图中可以看到,“已使用堆内存”呈现周期性的波动,基本可以确认是正常的GC导致的波动,并且机器的内存是8G,堆内存最大也不过4G。而老年代的内存占用量也在0左右,并未出现波动。
基于以上分析,我们可以明确排除因Java对象持续堆积而导致的堆内存泄漏。故障的根源必定在于堆外内存。
堆外排查
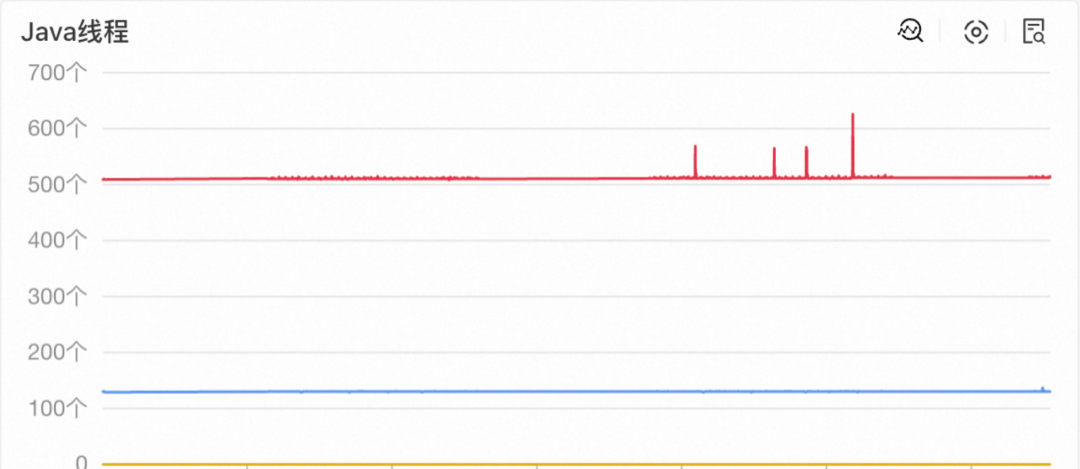
线程数量分析
对Java线程数量进行分析,可以看到在上次调整bucket数量之后,线程数量十分稳定,可以排除Java线程数量增长导致的OOM。
DirectMemory和JNIMemory
使用集团内部的MAT文件,分析了Dump文件,发现堆外内存中都是java.nio.DirectByteBuffer。
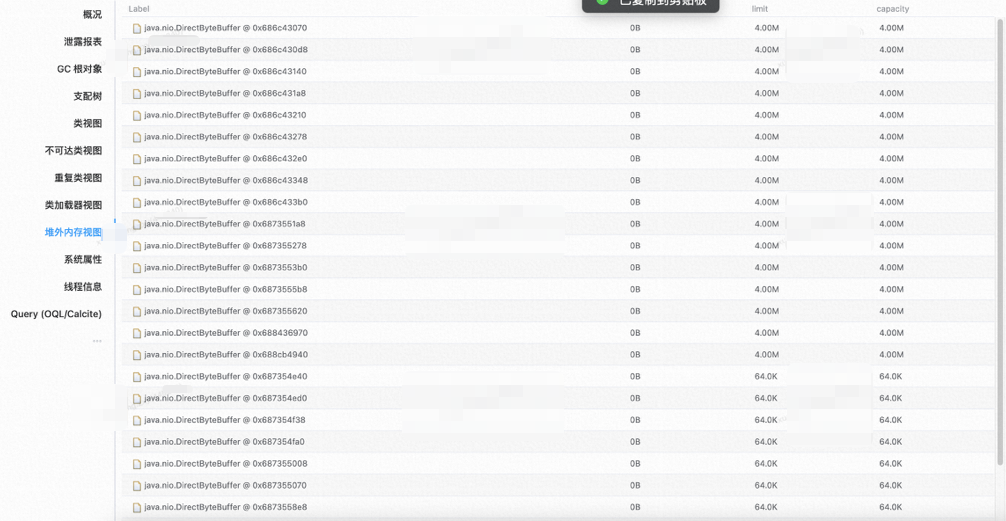
这个类是NIO的类,阅读相关文章后,找到相关资料,其中提到集团内部的RPC框架使用Netty,可能会申请堆外内存,且无法监控到,慢慢导致能存利用率上升。
使用Arthas 的 memory 命令分析了系统的内存分布,结果如下:

可以看到,direct占了312M,而其他应用的内存分布如下:

direct只有8M,这两者相差较多。
继续分析Netty占用,结果如下:
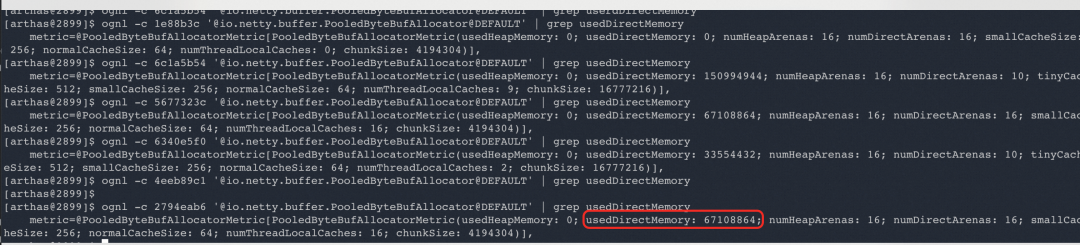
将所有的netty占用加起来,确实占用了300M。但300M也远远不会让我们的应用OOM,显然这不是系统OOM根因。
使用NMT工具排查,先记录了baseline,在一天过后执行了一次diff。

可以看到,committed一天不过增长了57M,这也和内存利用率的上涨对应不上。
用async-profiler,抓取了一段时间系统运行堆栈的内存分布火焰图,来观察哪些类的上涨比较多,当内存的RES上涨100m后,产出了火焰图,发现火焰图中记录的总共只有4M,这和RES上涨差的也很多。
最后用pmap命令对比了内存上涨前后的diff,也并未发现异常问题。
解决
尽管我们已将问题初步定位于堆外内存,但由于堆外内存泄漏的成因复杂且监控手段有限,此次排查并未直接定位到根本原因。
最后,我们与JVM专家团队紧密协作,制定了一系列手段来解决内存利用率上涨的问题。
1. 适度调低JVM堆内存上限(-Xmx),将更多物理内存预留给堆外空间使用。
2. 加上-XX:+AlwaysPreTouch参数。
默认情况下,JVM向操作系统申请的堆内存是“懒加载”的,只有在实际使用时才会触发物理内存的分配。这会导致监控到的容器内存曲线随时间推移而“自然”增长,对我们判断是否存在“额外”的内存泄漏造成视觉干扰。启用AlwaysPreTouch能让JVM在启动时就一次性占用所有分配的堆内存。
3. 增加机器内存。
4. 升级RPC框架的 netty共享sar包,减少netty占用。
1.3 第三次OOM
现象
在采用了一系列手段后,本以为不会发生OOM,然而观察到线上机器的内存利用率仍然不断上涨。
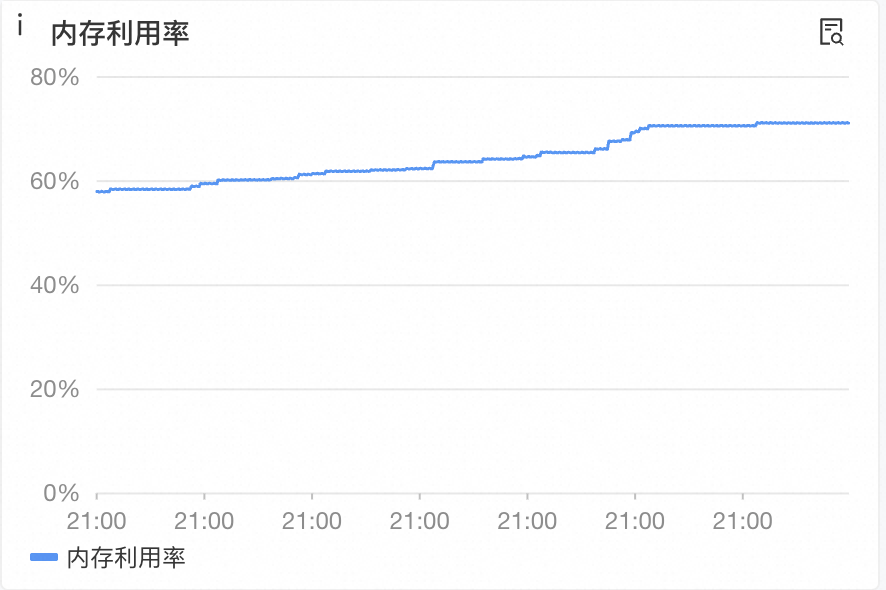
机器A的内存利用率:
机器B的内存利用率:
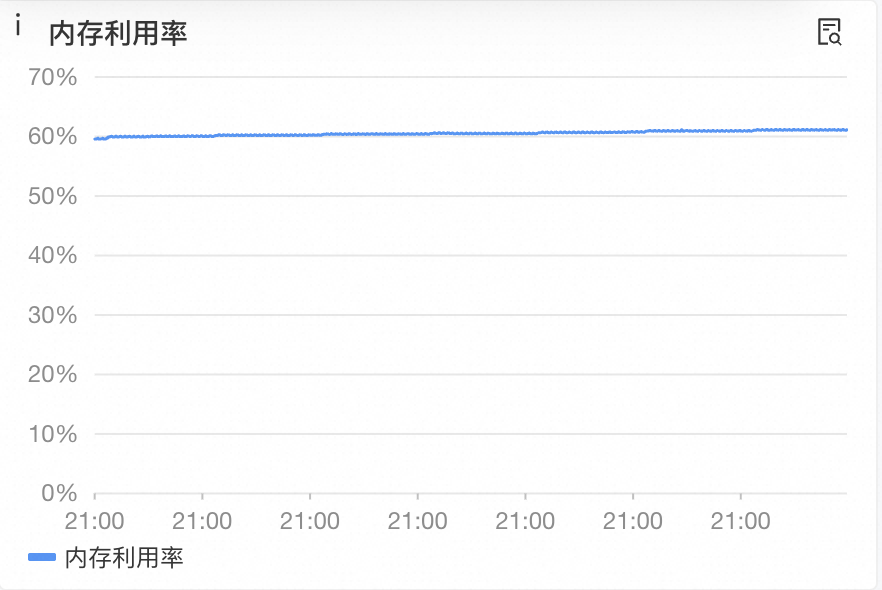
我们的服务在线上共有两台机器,在此我们将其称之为机器A和机器B,两台机器的七日内存利用率监控如上图所示。
从图中可以明显看到,机器A的内存利用率基本是呈阶梯状,每隔一段时间就会上涨一部分;机器B的内存利用率并未有什么大的变化。
这时,我们想到,第二次排查时使用的机器,并未有线上真实流量,但机器A和机器B是线上的真实机器。而机器A和机器B的唯一差别就是,线上大部分通过RocksDB写Paimon的请求,都由机器A执行,而机器A的内存利用率的阶梯上涨时间,都是写Paimon发生的时间。
通过控制变量法,我们再次将问题锁定在了相关团队提供的SDK上。
排查
1. NMT分析
使用ps -aux命令后,看到Java进程的RSS有12GB。
使用NMT工具后,产出了如下报告:

可以看到committed约为7G,这 5 GB 的差距主要由以下几部分组成,这些都是 NMT 无法追踪的:
-
第三方本地库(Native Libraries)内存占用
当Java代码通过JNI(Java Native Interface)调用C/C++等语言编写的本地库时,这些本地库内部使用malloc、new等方式申请的内存,完全不受JVM的NMT系统追踪。然而,这部分内存确实是属于该Java进程的,因此会被操作系统计入RSS。
而在NMT文件中,可以明显看到以下内容:
[0x00007f850c52a70f] rocksdb::JniCallback::getJniEnv(unsignedchar*) const+0x17f
我们的应用确实使用了RocksDB,向Paimon写数据。RocksDB是一个用C编写的高性能嵌入式键值数据库。它在运行时会管理大量的堆外内存(off-heap memory)用于缓存(Block Cache)、索引(Index)、布隆过滤器(Bloom Filter)等。这些内存都是RocksDB自己通过C的内存分配器向操作系统申请的,JVM的NMT对此一无所知。这部分内存往往非常大,几GB是很常见的。
-
Direct ByteBuffer(直接内存)
通过 java.nio.ByteBuffer.allocateDirect() 分配的内存虽然是堆外内存,但现代的JDK版本中,NMT通常能将其统计在 Internal 或 Other 类别下。
Other (malloc=67369KB ...)
Internal (malloc=16291KB ...)
我们的NMT文件中,这两部分并未占用大量内存。
-
加载的共享库/动态库
Java进程本身依赖于大量的共享库(.so文件),例如:libc.so (C标准库)、libpthread.so (线程库) 、libjvm.so (JVM核心库) 、应用依赖的其他任何原生库文件
操作系统会将这些库的代码段和数据段映射到进程的地址空间。这部分内存也会被计入RSS,而NMT不会统计它们。虽然多个进程可以共享同一个库的物理内存页,但RSS的计算方式仍会将这部分计入。
-
JNI本身的开销
JNI调用本身以及JNI句柄等也会占用少量内存,这部分也不在NMT的统计范围内。
-
内存分配器的碎片化
JVM向操作系统申请内存时,底层通常使用glibc的malloc。malloc本身为了性能,可能会预先分配比请求稍大的内存块,并且在释放后可能会持有这些内存以备将来使用(形成内存池),而不是立即归还给操作系统。这就导致了RSS(OS看到的)会比JVM实际使用的(NMT看到的)要高。
实际上,RocksDB使用JNI分配内存和我们根据内存利用上涨的猜测结果相似,为了确定问题的根源,我们又采用了async-profiler分析。
2. async-profiler火焰图
抓取了通过RocksDB写Paimon时期的堆栈,可以看到:

火焰图中大部分消耗也在RocksDB。
3. 询问SDK提供团队
我们带着以上两个排查结果,再次询问了RocksDB-Paimon SDK 提供团队的同学,他们查看了源代码后发现,我们现在使用的SDK存在RocksDB使用JNI分配内存,但无法释放的问题。
至此,困扰我们几个月的内存泄露问题终于找到了真正的原因。
解决
和相关团队同学沟通后,我们最终决定转换写Paimon的方式,从 通过自己的应用写 Paimon(旧架构),转换为应用发送消息通过Flink写Paimon(新架构)。
实际上,在业界一般来说都是通过Flink来写Paimon,因为Flink为数据入湖提供了一整套成熟、强大的能力,这是在业务应用中自行实现难以比拟的。
Flink写Paimon有以下优点:
1. 资源管理与并发控制:
-
无需关注线程管理:Flink通过其TaskManager和Slot机制,对任务的并发进行统一、精细化的管理。
-
背压机制:Flink内置了强大的反压机制。当Paimon写入变慢时(例如Compaction压力大),Flink能自动感知并将压力向上游传递,减缓数据消费速度,防止因数据堆积导致内存溢出,保证了整个数据链路的稳定性。
2. 状态管理与Exactly-Once语义:
-
状态后端:Flink拥有状态管理能力(其本身就是Paimon State Backend的来源)。无论是内存、文件系统还是RocksDB,Flink都能高效、可靠地管理算子的状态,这对于需要进行去重、聚合后再写入的复杂场景至关重要。
-
一致性保障:结合Paimon的Two-Phase Commit (2PC) Sink实现,Flink可以轻松实现端到端的Exactly-Once写入语义,确保数据在任何故障情况下都不重不丢。
3. 批流处理能力:
-
Paimon的核心设计理念是“流批一体的湖存储”。Flink作为流批一体计算引擎,可以与Paimon很好的结合。
二、排查工具
在排查问题的过程中,我们使用了很多工具来帮助我们排查问题,接下来是对这些工具的介绍。
2.1 MAT(Memory Analyzer Tool)
MAT是一个高性能、功能丰富的Java堆内存分析器。它能帮助开发者和运维工程师在复杂的内存快照(.hprof文件)中快速定位内存泄漏的根源,并分析应用在特定时刻的内存消耗详情。
一般我们可以通过在机器上生成Dump文件,然后通过MAT对Dump文件进行分析。
MAT一般有以下功能:
-
泄漏嫌疑报告
这是MAT的“一键诊断”功能。当你打开一个Dump文件时,MAT会自动分析并生成一个报告,直接指出最可疑的内存泄漏点,通常会以饼图展示内存占用最高的几个对象。这是排查的绝佳起点。
-
支配树
这是MAT最核心、最强大的功能。支配树会重新组织内存中的对象关系,清晰地展示出“谁支配谁”。如果对象A支配对象B,意味着对象A是B能存活在内存中的唯一“看门人”。一旦A被回收,B以及B所引用的所有对象都会被回收。
通过查看支配树,我们可以快速找到那些“支配”了大量内存的对象,它们通常就是内存泄漏的源头。按“Retained Heap”(保留堆大小)排序,排在最前面的就是最大的嫌疑对象。
-
直方图
以类的维度展示内存快照。你可以看到每个类的实例数量、占用的浅堆(Shallow Heap,对象自身大小)和深堆(Retained Heap,对象自身+其引用的所有对象总大小)。
-
对象查询语言
MAT提供了一套类似SQL的查询语言,允许你对堆内存中的对象执行复杂的查询。
-
GC根路径分析
这是定位内存泄漏的“铁证”。对于任何一个怀疑是泄漏的对象,可以使用此功能,MAT会清晰地展示出从该对象到GC根(如一个正在运行的线程、一个静态变量等)的完整引用链。这条引用链就是导致该对象无法被回收的原因。
2.2 NMT(Native Memory Tracking)
NMT(NativeMemoryTracking) 是一款JVM提供的一款Native Memory跟踪工具,可以帮助定位由 非 Java 堆内存 引发的内存泄漏或性能问题,例如元空间(Metaspace)、线程栈、JNI 代码、JVM 内部结构等的内存分配。
在我们的项目中加上-XX:NativeMemoryTracking=detail参数以后,就可以开启NMT,但这会带来5%-10%的性能损耗。
NMT的常用指令如下
一般来说,我们可以在应用启动时生成一个baseline,之后在应用运行一段时间后,采用diff命令,对比内存的增长情况。
对比时,我们主要关注committed的变化,找到增长较多的区域。
2.3 Arthas
arthas我们都不陌生,一般在我们的业务中,大家用它来查看接口耗时和方法追踪,但实际上,它的功能之强大远超我的想象。
arthas命令列表
可以看到使用arthas可以帮助我们对jvm、class等进行分析,帮助我们排查内存问题。
2.4 async-profiler
async-profiler 是一个基于 采样 的高性能 Java 分析工具,专注于 CPU 火花、内存分配 和 锁竞争 的低开销分析。它通过 异步信号(如 perf 事件或 itimer) 直接从 JVM 或原生代码中采集堆栈信息,无需修改代码或引入依赖,适合生产环境使用。
arthas内部也集成了async-profiler,我们一般可以使用async-profiler生成火焰图,帮助我们对内存进行分析。
最新版本的async-profiler提供了native memory分析能力,通过:
可以对native memory进行分析。
2.5 linux指令
常用的内存分析指令如top、pmap等,也可以对内存进行分析,尤其是pamp,可以使用pmap对进程的内存块进行观察对比,便于我们找出可以内存地址,再查找其中对象。
三、排查思路总结
对于内存问题的排查,工具千千万万,排查手段也非常多,笔者认为最重要的不是工具如何使用,而是如何找到正确的排查方向。在这里,分享一下我个人的思路,也许不够专业,但还是希望给阅读文章的同学一些参考,在面对内存问题时,不至于无从下手。
3.1 发生问题,保留现场
无论什么时候,发生问题一定要记得保留现场,不要因为服务崩溃,就急于重启机器。我们可以保留一台故障机器,用于问题排查 ,因为一旦丢失现场,就相当于侦探破案时犯罪现场被毁,会损失大量线索,极大地阻碍我们排查问题的进度。
但如果现场已经丢失,我们需要想办法复现这个问题,这是帮助我们最快找到问题原因的方法,模拟问题发生时的场景,如加大流量压测,根据日志模拟请求等。
3.2 查看系统监控,初步定位问题
公司内部一般会提供应用监控工具,没有的话,我们也应该自己尝试搭建一些简易的监控告警。如内存利用率上涨问题,我们可以观察堆和非堆内存与整体内存利用率上涨趋势的差异,初步定位问题。
3.3 使用工具,进行分析
初步定位到问题后,可以使用相关工具进行分析,如果是堆内问题,那么MAT就可以很好的帮助我们进行分析,堆外问题的情况相对来说比较复杂,可能需要使用NMT和gperftools等工具进行分析。
3.4 阅读文章,请教专家
大部分情况下,我们都可以找到问题的所在,但也会遇到一筹莫展的时候,这时候我们可以在Google上搜索相关文章,也许会有人遇到过和我们相同的问题,也可以在公司内部找技术支持团队帮助,当然,大模型也是帮助我们分析问题的利器,大部分时候,都可以帮我们快速定位到问题。
3.5 总结问题,记录心得
每一次问题排查,都需要记录下自己的排查过程,这对于我们个人来说,是帮助我们积累经验,理顺自己每次排查问题的思路,对于其他同学来说,也可以为他们提供经验。
参考文章
-
NMT(NativeMemoryTracking) :https://docs.oracle.com/javase/8/docs/technotes/guides/troubleshoot/tooldescr007.html
-
arthas命令列表:https://arthas.aliyun.com/doc/commands.html#jvm-%E7%9B%B8%E5%85%B3
Kimi K2,开源万亿参数大模型
先进的混合专家(MoE)语言模型,在前沿知识、推理和编码任务中性能卓越,并优化了工具调用能力。本方案支持云上调用 API 与部署方案,无需编码,最快 5 分钟即可完成,成本最低 0 元。
点击阅读原文查看详情。