阿里云RDS Supabase:全托管服务简化AI应用开发,结合Agentic RAG,助你高效构建智能应用!
原文标题:附部署代码|云数据库RDS 全托管 Supabase服务:小白轻松搞定开发AI应用!
原文作者:阿里云开发者
冷月清谈:
怜星夜思:
2、文章提到RDS Supabase能将开发部署周期从月级缩短到天级,成本也降低一半以上。这种效率和成本的巨大提升,对于初创公司或者独立开发者来说,意味着什么?真的有那么大的颠覆性吗?
3、文中的Agentic RAG概念引起了我的兴趣,它比传统的RAG多了一个“Agentic”的能力。大家觉得这个“Agentic”具体体现在哪些方面?它和我们平时理解的普通RAG有什么本质区别,能带来哪些更智能的体验?
原文内容

阿里妹导读
本文通过一个 Agentic RAG 应用的完整构建流程,展示了如何借助 RDS Supabase 快速搭建具备知识处理与智能决策能力的 AI 应用,展示从数据准备到应用部署的全流程,相较于传统开发模式效率大幅提升。
前言
云数据库 RDS PostgreSQL全托管Supabase服务,为客户提供AI应用开发的新范式。

相比于传统开发模型,基于RDS Supabase的开发模型有以下几个核心优势:
-
开发部署效率:传统应用通常有多层架构,并且前后端服务以及数据库之间紧密耦合,Supabase则提供开箱即用的一体化服务能力,应用开发部署周期从月级缩短至天级,快速将应用推向市场。
-
成本优化:传统应用需要大量人力维护多个应用组件以及数据库的资源,而基于全托管的RDS Supabase以及RDS PostgreSQL的全生命周期管理能力,在资源成本以及人力成本上,均能减小50%以上。
-
可扩展性:相比传统应用开发的基于新组件的扩展模型,RDS Supabase可基于PostgreSQL的插件以及第三方应用扩展,并且在资源上具备Serverless弹性扩展能力,轻松应对流量的增长。
什么是Supabase
Supabase是一个开源的,建构于开源PostgreSQL之上的后端即服务(BaaS)平台,旨在替代Firebase等商业化BaaS平台,Supabase整合了多个优秀的开源框架,并基于PostgreSQL进行了深度适配,提供了API化的数据库管理能力、用户管理、身份认证、对象存储服务以及基于PostgreSQL CDC和Websocket的实时通信服务,基于这些平台化基础能力,能够使开发者简化全栈应用开发的流程,帮助开发者快速构建高性能,可扩展的应用程序,同时避免传统开发流程中需要维护复杂后端基础设施的问题。

Supabase适用场景
Supabase 通过整合数据库、认证、存储、实时通信等开箱即用的能力,为开发者和企业提供「开发即交付」的后端即服务(BaaS)解决方案。开发者可基于此快速构建最小可行性产品(Minimum Viable Product,MVP)核心功能,以最低成本、最短周期完成产品原型开发与市场验证。这种「功能模块即插即用」的模式,将传统开发中耗时的基础设施搭建转化为自动化服务,显著降低试错风险,助力企业在创新探索阶段实现资源最优配置。
基于Supabase开发的典型应用场景:
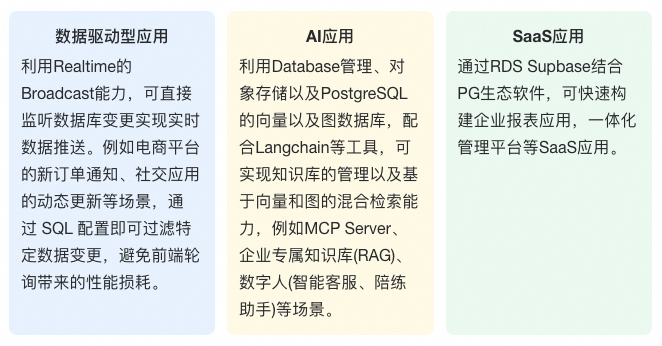
Supabase核心能力
Supabase可提供认证&用户管理(Auth)、数据库管理( REST& GraphQL)、实时通信(Realtime)、存储(Storage)等能力。
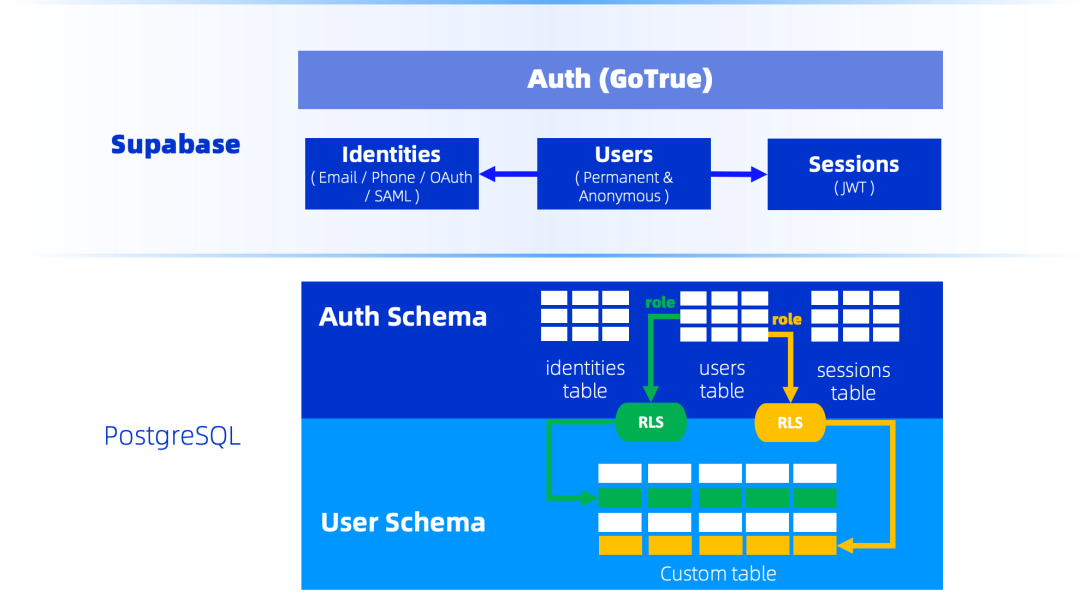
认证 & 用户管理 (Auth)
-
用户管理:提供用户注册、注销、角色管理以及匿名用户等能力;
-
认证授权:通过GoTrue提供了开箱即用的多种认证授权方式,支持邮箱、密码、手机登录、无密码登录、SAML SSO单点登录以及OAuth 授权,同时具备灵活的扩展性,支持第三方平台认证(Github, Google, Apple, Facebook等);
-
会话管理:基于标准的 JWT(JSON Web Tokens) 提供细粒度的权限控制;
-
Auth模块中的每个用户通过对应的role与PostgreSQL内核提供的 Row-Level Security (RLS) 行安全策略绑定,使得多个用户的数据虽然都存在一张表内,但是每个用户只能访问到自己的数据,达到安全隔离的效果。例如,在任务管理应用中,可设置“用户仅能查看自己创建的任务”。此外,Supabase身份认证的用户数据存储于 PostgreSQL 的Auth Schema中,并可通过外键关联至应用自定义表(如用户个人资料表)。
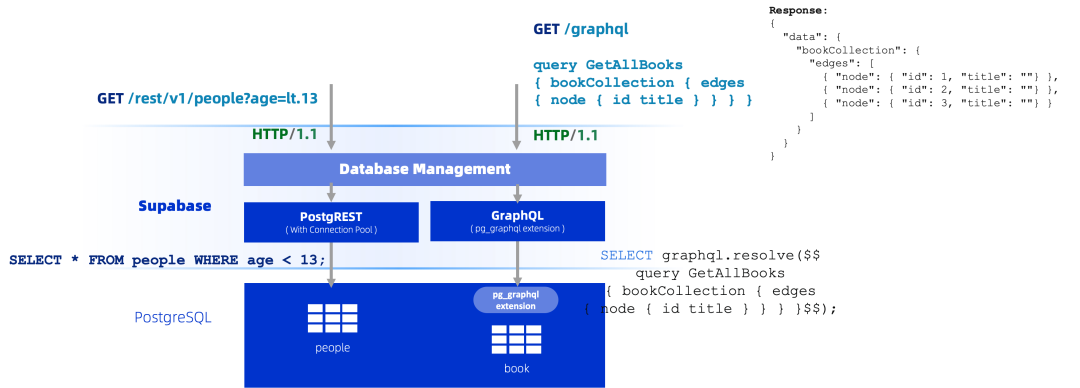
数据库管理(REST & GraphQL)
Supabase 支持通过RESTful接口以及GraphQL接口管理并操作数据库中的库、表、函数、存储过程等对象,相比传统的应用DAO层的开发方式,通过API接口的方式操作不需要新增DAO层,只需要增加对应表的业务处理逻辑即可。
-
RESTful接口:基于PostgREST框架实现,实现API接口到SQL的转换,并且在PostgREST框架中内置了一个连接池,能够在承接高流量HTTP请求时,保证PostgREST与数据库之间的连接数稳维持在一个较低的水平,防止PostgreSQL数据库出现内存占用过多的问题;
-
GraphQL:基于pg_graphql插件实现,result一般返回JSONB类似的格式;
例如,创建一张 messages 表后,Supabase 会自动提供 /rest/v1/messages 端点,实现数据的增删改查操作,显著减少后端开发时间。
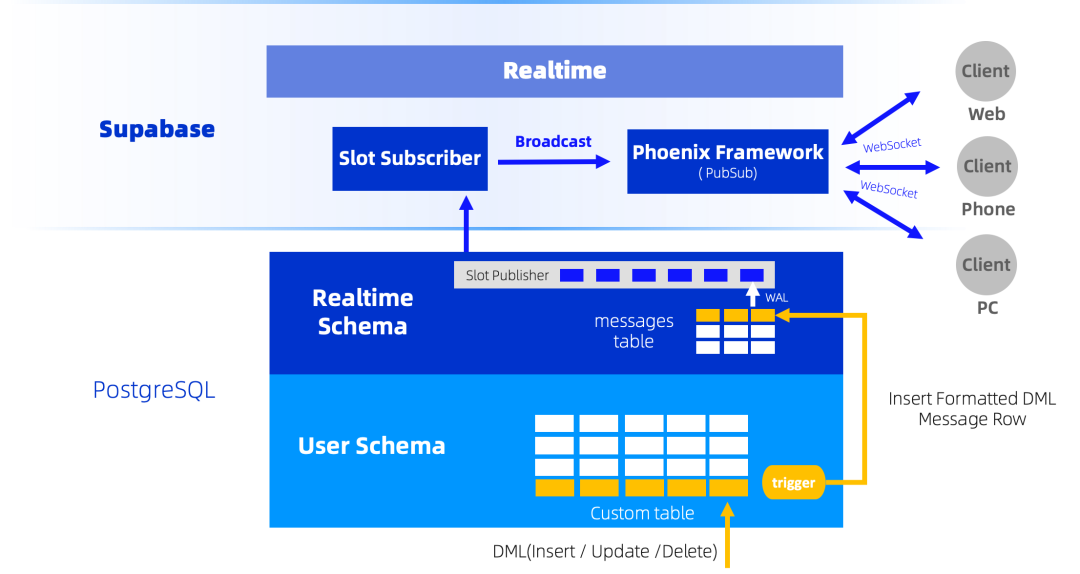
实时通信(Realtime)
Supabase 通过Realtime组件提供实时消息通信以及消息广播能力,客户端与Realtime之间支持 WebSocket 协议,结合PostgreSQL数据库自带的逻辑复制Slot,trigger触发器,配合监听Realtime的messages系统表的变更,能够实现将数据库中的纪录变更及时广播推送至多个客户端,并且在Realtime中能够实现跨地域,多Realtime服务之间的消息传播,这一特性在需要高交互性的场景中尤为重要,例如实时聊天应用或协作工具。以聊天应用为例,当用户 A 发送消息后,所有连接至该频道的客户端(如用户 B 的设备)会立即收到更新,无需轮询服务器 。
Storage(兼容S3标准的OSS对象存储)
Storage主要封装的兼容S3标准的对象存储接口,利用PostgreSQL存储对应OSS Bucket信息以及文件信息,结合Auth的RLS策略对OSS访问实现权限控制。
RDS Supabase:
全托管Supabase + RDS企业级数据库能力保障
RDS Supabase是基于云数据库RDS PG的全托管 Supabase 应用开发平台,为企业客户提供 BaaS (Backend as a service)服务。通过全托管Supabase服务+RDS PG企业级数据库能力+开箱即用的架构设计,RDS Supabase为企业提供无需维护底层基础设施的后端服务部署方案,加速企业AI应用业务上线进程。
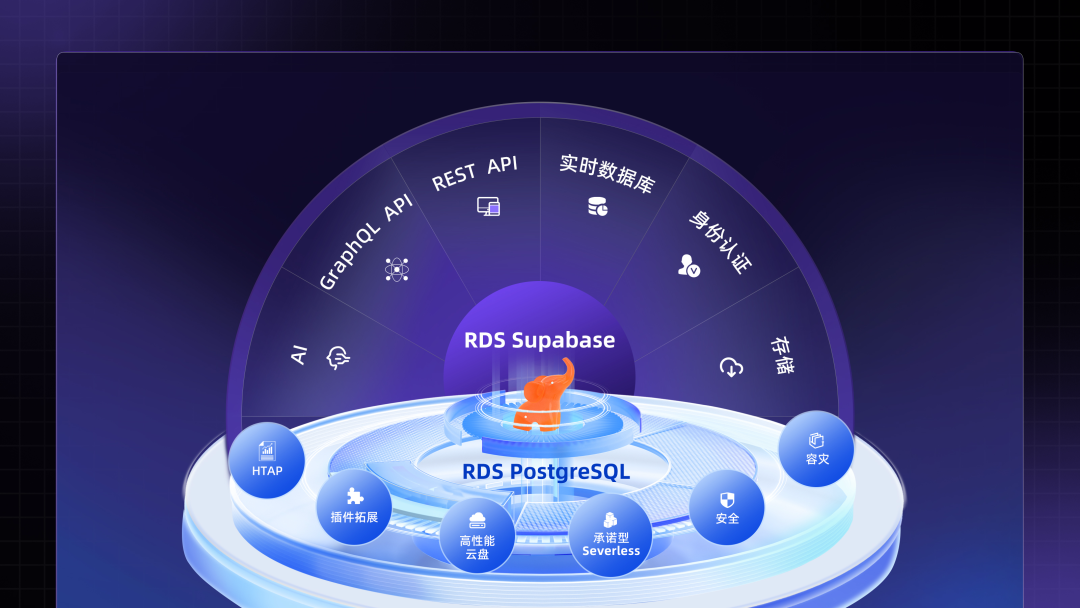
整体架构

RDS Supabase增强能力
RDS Supabase 服务基于阿里云数据库 RDS PostgreSQL 构建,为企业提供涵盖计算、存储、网络及大模型资源的全托管解决方案。该服务与开源版 Supabase 100%兼容,支持通过可视化的RDS控制台或 OpenAPI 实现实例的灵活管理。相较于开源版 Supabase 和开源 PostgreSQL 数据库,RDS Supabase 不仅提供 RDS PostgreSQL 的完整功能集,更在性能稳定性、弹性扩展能力及自动化运维层面实现显著突破,助力开发者高效构建现代化后端服务。
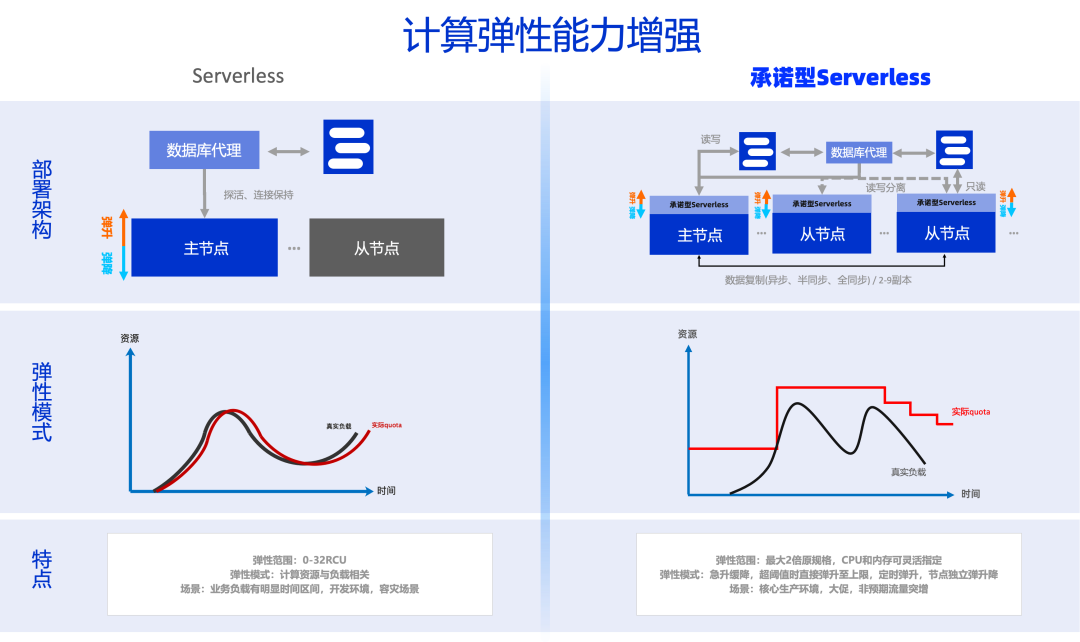
性能
RDS PostgreSQL 在计算与存储层面均具备灵活的弹性能力。存储层面,RDS PG支持按需扩展、自动分层存储等能力,满足海量数据的高吞吐处理需求。在计算层面,RDS PG 提供 传统 Serverless 与承诺型 Serverless 两种弹性能力:
-
传统 Serverless: 适用于开发测试、容灾备份等对 SLA 要求较低或业务流量波动明显的场景,实现按需自动扩缩容。
-
承诺型 Serverless :通过 '急弹缓降' 策略(快速扩容 + 慢速缩容),结合 '本地化扩容' 机制,避免因跨机扩容导致的业务中断问题。其核心优势在于:
-
业务无损:基于基本规格的性能兜底保障,确保核心业务持续稳定运行;
-
突破瓶颈:解除传统实例规格对 I/O 带宽的限制,依托 RDS 高性能云盘,单实例最大吞吐量可达 4GB/s;
-
智能调度:通过动态资源池化技术,实现资源利用效率与业务响应速度的双重优化。
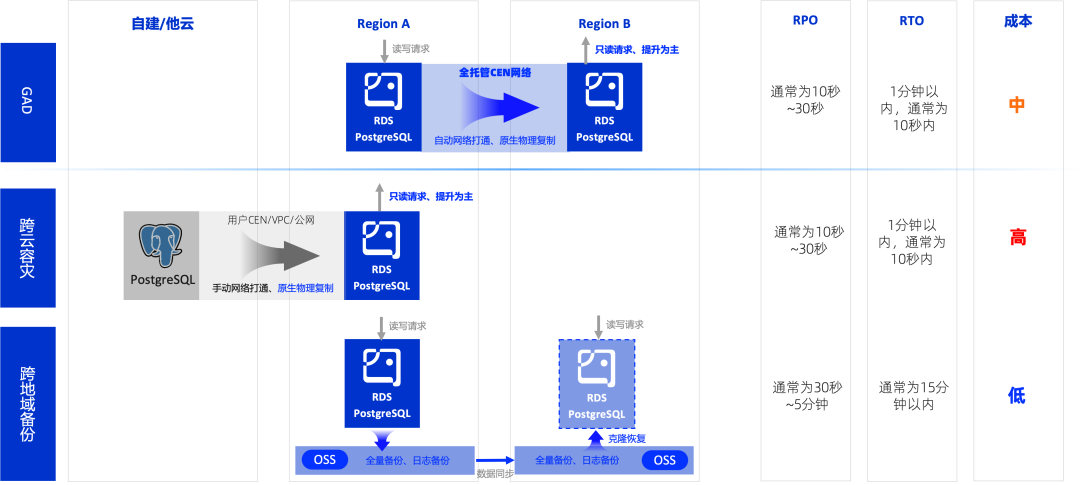
容灾
RDS PostgreSQL开放了物理复制权限,基于原生原理物理以及云盘快照能力,并通过全托管的CEN网络,免去了繁琐的手动CEN搭建过程,实现了一键跨Region RDS PostgreSQL实例间的容灾、云上云下容灾以及跨Region的PITR恢复能力,满足用户在成本,RTO,RPO上的不同需求,最大限度的保证Supabase的数据安全。
AI增强
RDS PostgreSQL 通过插件市场提供100+个可扩展插件,开发者可通过安装 pgvector(向量检索)、Apache Age(图数据库)及 RUM(全文检索)等插件,结合 RDS Supabase ,快速构建 GraphRAG、知识库混合搜索等 AI 应用。
在向量数据库性能优化方面,RDS PostgreSQL 也能针对性提供Vector类型构建和查询性能的优化。传统pgvector(如适用于高向量纬度但小数据集场景的ivfflat 索引,适用于大数据集场景但低向量唯独的HNSW 索引)在高向量纬度、大数据集场景的表现均不佳。RDS PostgreSQL引入开源 disk_ann 索引,在确保查询精度的前提下,在索引构建速度和索引空间上均有大幅提升;同时,在硬件层面,RDS PostgreSQL通过承诺型Serverless和高性能云盘,为向量索引构建和查询提供更高的IO吞吐以及更大的内存空间进行加速。

实战演练:
基于RDS Supabase开发一个
简易Agentic RAG应用
Project背景
本项目演示通过 RDS Supabase + LangChain 快速搭建具备以下能力的Agentic RAG 应用:
1. 知识处理链路
-
向量化:通过 DashScope Embedding 将 PDF/Word 等格式的文档转换为向量表示;
-
向量存储:通过RDS Supabase + pgvector 构建高性能向量数据库,存储向量;
-
智能决策:LangChain 自动管理「检索-生成」流程,通过 tool_call 机制动态选择检索策略;
2. 对话交互系统
-
大模型驱动:集成通义千问作为Chatbot模型,进行自然语言理解和生成;
-
会话管理:Streamlit 框架维护上下文状态,支持连续多轮对话;
该类 Agentic RAG应用可广泛使用于如下真实场景中:
-
企业知识库问答:快速构建支持 PDF/Word 文档语义检索的智能助手;
-
医疗健康咨询:基于专业医学文献提供个性化健康建议;
-
多模态客服系统:结合 Qwen 的多模态能力,处理图文混合咨询;
通过该方案,开发者可在RDS控制台快速完成从数据准备到应用部署的全流程,相较传统开发模式效率有大幅度提升。
操作步骤
1. 登录云数据库RDS控制台,创建 RDS Supabase。
https://rdsnext.console.aliyun.com/rdsList/cn-hangzhou
2. 安装vector插件、建表、设函数,使pg拥有处理向量的能力。
-- Enable the pgvector extension to work with embedding vectors create extension ifnot exists vector;– Create a table to store your documents
create table
documents(
id uuid primary key,
content text, – corresponds to Document.pageContent
metadata jsonb, – corresponds to Document.metadata
embedding vector (1536) – 1536 works for OpenAI embeddings, change if needed
);
– Create a function to search for documents
create function match_documents(
query_embedding vector (1536),
filter jsonb default’{}’
) returns table(
id uuid,
content text,
metadata jsonb,
similarity float
) language plpgsql as formula-0
;
3. 准备环境变量: DASHSCOPE_API_KEY、SUPABASE_URL、SUPABASE_SERVICE_KEY。
DASHSCOPE_API_KEY = "sk-*****" SUPABASE_URL = "http://*.*.*.*:*" SUPABASE_SERVICE_KEY = "eyJhbGc****BBNWN8Bu4GE"
4. 准备RAG材料,编写代码,将材料进行Embedding(使用DashScope Embedding)。
将documents/ 目录下的pdf文件进行embedding存入Supabase。
import os from dotenv import load_dotenvimport langchain
from langchain_community.document_loaders import PyPDFDirectoryLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import SupabaseVectorStorefrom langchain_community.embeddings.dashscope import DashScopeEmbeddings
import supabase
from supabase import create_client, Client
加载环境变量
load_dotenv()
获取配置
supabase_url = os.environ.get(“SUPABASE_URL”)
supabase_key = os.environ.get(“SUPABASE_SERVICE_KEY”)
简化初始化
supabase: Client = create_client(supabase_url, supabase_key)
initiate embeddings model
embeddings = DashScopeEmbeddings(model=“text-embedding-v2”, dashscope_api_key=os.environ.get(“DASHSCOPE_API_KEY”))
load pdf docs from folder ‘documents’
loader = PyPDFDirectoryLoader(“documents”)
split the documents in multiple chunks
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=100)
docs = text_splitter.split_documents(documents)store chunks in vector store
vector_store = SupabaseVectorStore.from_documents(
docs,
embeddings,
client=supabase,
table_name=“documents”,
query_name=“match_documents”,
chunk_size=1000,
)
5. 构建Agentic RAG,进行单次对话(使用Qwen作为对话LLM)。
# import basics import os from dotenv import load_dotenvfrom langchain.agents import AgentExecutor
from langchain.agents import create_tool_calling_agent
from langchain_community.vectorstores import SupabaseVectorStore
from langchain import hubfrom supabase.client import Client, create_client
from langchain_core.tools import tool
from langchain_community.embeddings.dashscope import DashScopeEmbeddings
from langchain_community.chat_models.tongyi import ChatTongyiload environment variables
load_dotenv()
initiate supabase database
supabase_url = os.environ.get(“SUPABASE_URL”)
supabase_key = os.environ.get(“SUPABASE_SERVICE_KEY”)supabase: Client = create_client(supabase_url, supabase_key)
initiate embeddings model
embeddings = OpenAIEmbed dings(model=“text-embedding-3-small”)
embeddings = DashScopeEmbeddings(model=“text-embedding-v2”, dashscope_api_key=os.environ.get(“DASHSCOPE_API_KEY”))
initiate vector store
vector_store = SupabaseVectorStore(
embedding=embeddings,
client=supabase,
table_name=“documents”,
query_name=“match_documents”,
)initiate large language model (temperature = 0)
llm = ChatOpenAI(temperature=0)
llm = ChatTongyi(streaming=True)
fetch the prompt from the prompt hub
prompt = hub.pull(“hwchase17/openai-functions-agent”)
create the tools
@tool(response_format=“content_and_artifact”)
def retrieve(query: str):
“”“Retrieve information related to a query.”“”
retrieved_docs = vector_store.similarity_search(query, k=2)
serialized = “\n\n”.join(
(f"Source: {doc.metadata}\n" f"Content: {doc.page_content}")
for doc in retrieved_docs
)
return serialized, retrieved_docscombine the tools and provide to the llm
tools = [retrieve]
agent = create_tool_calling_agent(llm, tools, prompt)create the agent executor
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
invoke the agent
response = agent_executor.invoke({“input”: “why is agentic rag better than naive rag?”})
put the result on the screen
print(response[“output”])
6. 使用streamlit维护会话状态,在前端进行多轮对话。
streamlit run agentic_rag_streamlit.py
# import basics import os from dotenv import load_dotenv # import streamlit import streamlit as st # import langchain from langchain.agents import AgentExecutor from langchain_openai import ChatOpenAI from langchain_core.messages import AIMessage, HumanMessage from langchain.agents import create_tool_calling_agent from langchain import hub from langchain_community.vectorstores import SupabaseVectorStore from langchain_openai import OpenAIEmbeddings from langchain_core.tools import tool # import supabase db from supabase.client import Client, create_client from langchain_community.embeddings.dashscope import DashScopeEmbeddings from langchain_community.chat_models.tongyi import ChatTongyi # load environment variables load_dotenv() # initiating supabase supabase_url = os.environ.get("SUPABASE_URL") supabase_key = os.environ.get("SUPABASE_SERVICE_KEY") supabase: Client = create_client(supabase_url, supabase_key) # initiating embeddings model embeddings = DashScopeEmbeddings(model="text-embedding-v2", dashscope_api_key=os.environ.get("DASHSCOPE_API_KEY")) # initiating vector store vector_store = SupabaseVectorStore( embedding=embeddings, client=supabase, table_name="documents", query_name="match_documents", )initiating llm
llm = ChatTongyi(streaming=True)
pulling prompt from hub
prompt = hub.pull(“hwchase17/openai-functions-agent”)
creating the retriever tool
@tool(response_format=“content_and_artifact”)
def retrieve(query: str):
“”“Retrieve information related to a query.”“”
retrieved_docs = vector_store.similarity_search(query, k=2)
serialized = “\n\n”.join(
(f"Source: {doc.metadata}\n" f"Content: {doc.page_content}")
for doc in retrieved_docs
)
return serialized, retrieved_docscombining all tools
tools = [retrieve]
initiating the agent
agent = create_tool_calling_agent(llm, tools, prompt)
create the agent executor
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
initiating streamlit app
st.set_page_config(page_title=“Agentic RAG Chatbot”, page_icon=“
”)
st.title(“initialize chat history
if"messages"not in st.session_state:
st.session_state.messages =display chat messages from history on app rerun
for message in st.session_state.messages:
if isinstance(message, HumanMessage):
with st.chat_message(“user”):
st.markdown(message.content)
elif isinstance(message, AIMessage):
with st.chat_message(“assistant”):
st.markdown(message.content)create the bar where we can type messages
user_question = st.chat_input(“How are you?”)
did the user submit a prompt?
if user_question:
# add the message from the user (prompt) to the screen with streamlit
with st.chat_message(“user”):
st.markdown(user_question)
st.session_state.messages.append(HumanMessage(user_question))
# invoking the agent
result = agent_executor.invoke({“input”: user_question, “chat_history”:st.session_state.messages})
ai_message = result[“output”]
# adding the response from the llm to the screen (and chat)
with st.chat_message(“assistant”):
st.markdown(ai_message)
st.session_state.messages.append(AIMessage(ai_message))
总结
通过阿里云RDS与Supabase的深度融合,开发者将能以更低成本、更高效率地构建下一代AI应用,真正实现"代码即基础设施"的开发愿景。
对RDS Supabase感兴趣,欢迎加入 RDS Supabase 钉钉技术交流群(群号:103525002795)。
欢迎点击查看 AI应用构建 实战演练视频:
自建数据库迁移到云数据库
本方案介绍如何将网站的自建数据库迁移至云数据库 RDS,解决您随着业务增长可能会面临的数据库运维难题。数据库采用高可用架构,支持跨可用区容灾,给业务带来数据安全、可用性、性能和成本方面收益。
点击阅读原文查看详情。