深度解析Google Veo 3文本到视频模型。本文是复现指南上篇,聚焦数据预处理全流程,包括数据收集、去重、安全与质量过滤及标注。
原文标题:从零复现Google?Veo?3:从数据预处理到视频生成的完整Python代码实现指南(上)
原文作者:数据派THU
冷月清谈:
尽管Google Veo 3的官方训练依赖于JAX框架、TPU以及ML Pathways技术栈,但本复现教程为保持代码的清晰性与易理解性,选择使用PyTorch和NumPy进行实现。文章的核心部分详细阐述了构建高质量视频数据集的完整数据预处理流程。这一流程始于**原始数据的收集**,通过Pexels API获取视频素材;接着是**语义去重**,通过提取视频关键帧并利用多模态大型语言模型(如Mistral-24B vision)生成场景描述,再利用LLM(如LLaMA-3.3–70B)比较描述相似性以识别并移除冗余内容。第三步为**不安全内容过滤**,依据关键帧的场景描述,由LLM判断并剔除潜在的有害视频。随后进行**质量与合规性筛选**,通过检查视频中间帧的模糊度和光照等质量问题,移除不符合标准的视频。为统一模型输入,所有视频均被**修剪至固定时长**并**移除文件体积过大的视频**。最终,经过严格筛选和清洗的数据进入**数据标注**环节,使用Google Gemini等模型生成高质量、简洁的视频内容摘要。
这些细致且迭代进行的预处理步骤,为Veo 3模型后续的训练奠定了坚实的数据基础,确保了生成内容的质量和相关性。文章还提到,数据结构的进一步调整和模型训练将在后续篇章中详细介绍。
怜星夜思:
2、文章提到Google训练Veo 3用的是JAX+TPU+ML Pathways,而咱们复现时为了简洁用了PyTorch+NumPy+小数据集。这种“小而美”的复现项目对我们学习大模型开发到底有什么实际帮助?它跟Google原版模型在实际应用中会有多大差距呢?
3、文章里数据预处理这一章节讲得特别细,从视频收集、去重、安全过滤、质量筛选到最后的数据标注,链路很长。但在我们实际操作中,大家觉得哪个环节最消耗时间和资源?有没有什么独门秘籍或者踩坑经验可以分享一下?
原文内容

来源:DeepHub IMBA本文分为上下两篇共30000字,建议阅读15+分钟
本项目为理解文本到视频生成模型的工作原理以及如何使用 PyTorch 从零开始构建此类模型提供了一个基础框架。
Google Veo 3作为当前最先进的文本到视频生成系统,能够根据文本提示生成高质量、高分辨率的视频内容并同步生成音频。该系统在性能上已超越OpenAI SORA等同类模型,代表了视频生成领域的最新技术水平。
Google最近发布了Veo 3技术报告和模型规格说明,详细阐述了系统架构、训练流程等核心技术细节。本文将基于这些技术文档,从零开始复现Veo 3的实现方法,构建我们自己的小规模Veo 3模型。
Veo 3系统架构概览
根据Google提供的Veo 3高层架构图,我们可以了解其工作流程:
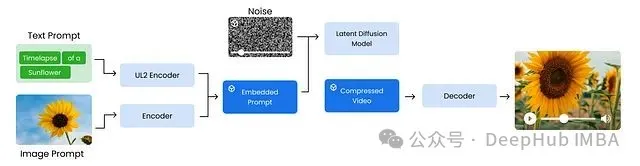
整个训练过程可以分解为四个主要阶段:首先,系统对输入提示进行编码,文本提示通过UL2编码器处理生成语义嵌入向量。同时系统还可以包含图像提示并进行编码以丰富输入信息。其次,这些嵌入向量被组合成嵌入提示,作为条件输入。系统初始化噪声压缩视频来模拟模型训练的生成空间。接下来,潜在扩散模型学习使用嵌入提示作为指导对压缩视频进行去噪处理,逐步生成精细化的压缩视频。最后,该输出通过解码器重建全分辨率视频,例如清晰的1080p向日葵绽放延时摄影。
这个高层图表隐藏了训练、预处理和安全措施等组件的技术细节。基于模型规格说明和技术报告,我们重新构建了Veo 3架构的详细分解图:
将Veo 3架构分解为四个核心阶段:数据预处理阶段负责输入数据的准备和预处理;训练阶段使用预处理后的数据训练Veo 3模型;评估阶段在各种指标上对训练后的模型进行性能评估。接下来我们将详细分析每个阶段的技术实现。
JAX框架及其重要性分析
AI模型训练涉及大量矩阵运算,随着训练过程的进行,内存消耗不断增加。Google在Veo 3模型规格说明中表示他们采用了JAX框架
JAX是Google开发的开源数值计算库,专门用于高性能数值计算。为了演示JAX的性能优势,我们使用以下多项式方程进行测试:
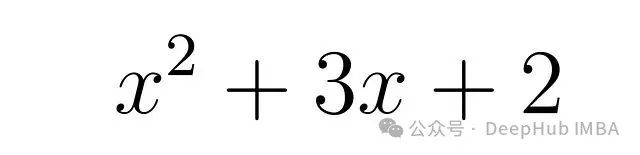
我们将比较在NumPy和JAX中实现该函数的执行时间差异。首先导入必要的库并创建两个函数实现:
# 导入必要的库
import jax
# 定义NumPy函数实现
def f_np(x):
return x**2 + 3*x + 2
# 定义采用JIT编译的JAX函数实现
@jax.jit
def f_jax(x):
return x**2 + 3*x + 2
可以看到JAX版本使用了@jax.jit装饰器,该装饰器用于编译函数以实现性能优化。
接下来创建包含1000万元素的数组并测量两个函数的执行时间:
# 导入性能测量所需的额外库
import numpy as np
import time
import jax.numpy as jnp
# 创建输入数组
x_np = np.arange(10_000_000, dtype=np.float32) # 为NumPy创建大型数组
x_jax = jnp.arange(10_000_000, dtype=jnp.float32) # 为JAX创建大型数组
# 测量NumPy函数性能
start_np = time.time()
result_np = f_np(x_np)
time_np = time.time() - start_np
# 测量JAX函数性能(首次调用)
start_jax_first = time.time()
result_jax_first = f_jax(x_jax)
time_jax_first = time.time() - start_jax_first
# 再次测量JAX函数性能以观察JIT编译效果
start_jax_second = time.time()
result_jax_second = f_jax(x_jax)
time_jax_second = time.time() - start_jax_second
# 输出时间测量结果
print(f"Numpy time: {time_np:.4f} seconds")
print(f"JAX first call time: {time_jax_first:.4f} seconds")
print(f"JAX second call time: {time_jax_second:.4f} seconds")
输出结果
Numpy time: 0.0493 seconds
JAX first call time: 0.1019 seconds
JAX second call time: 0.0148 seconds
JAX函数的首次调用由于JIT编译过程而耗时较长,但后续调用的性能显著提升。这种性能优化对于大规模计算场景至关重要,因为首次调用后无需重复编译开销。
此外,JAX还通过jax.grad支持反向模式微分(即反向传播),以及自动向量化和并行化等高级功能,进一步增强了复杂计算的性能表现。
虽然JAX支持众多训练组件,但在我们的实现中将使用PyTorch和NumPy,以保持代码的清晰性和可理解性。
TPU与ML Pathways技术栈
OpenAI和Meta通常采用NVIDIA GPU进行训练,而Google一直偏好TPU架构。他们在Veo 3训练以及许多其他模型中都采用了这种技术路线。
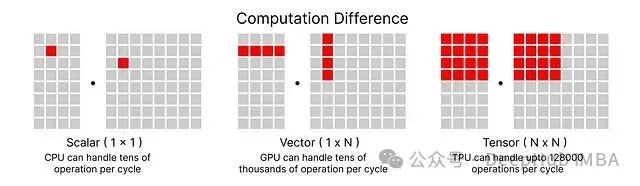
通过使用TPU,必须考虑ML Pathways这一Google的另一个项目,该项目旨在跨TPU Pod进行扩展,支持数千个TPU芯片而无需大量协调开销。该系统同时支持数据并行和模型并行。
在后续章节中,我们将深入了解为什么要使用JAX、TPU和ML Pathways的组合,因为Veo 3架构具有稀疏性特点,涉及多个模型和组件,而非单一模型训练。
数据预处理
第一阶段是数据预处理,此环节对于训练 Veo 3 模型前的数据准备工作至关重要。其目标是构建一个高质量、多样化且内容安全的数据集,为后续模型训练奠定基础。

具体流程包括:
-
首先,从 YouTube、Google 搜索及其他平台(例如包含鸟类喂食场景的视频)收集原始数据。
-
随后,执行语义去重,以移除内容高度相似的冗余条目,保留多样性的样本(例如,保留一张清晰的鸟类图像,移除其他相似图像)。
-
接着,应用不安全内容过滤机制,剔除有害或不适宜的内容(例如,移除一张描绘猫头鹰捕食的图像)。
-
之后,进行质量与合规性筛选,舍弃低质量、模糊或不符合规范的数据(例如,一段昏暗且不清晰的剧院录像)。
-
数据清洗完毕后,利用 Gemini 等模型生成字幕,以准确描述视频内容(例如,“向日葵盛开的延时摄影”)。
经过上述步骤,最终得到一个高质量、安全且带有标签的数据集,可直接用于模型训练。首先,导入数据预处理阶段所需的 Python 库:
# Google Generative AI SDK
# Google Generative AI SDK
import google.generativeai as genai
# Progress bar utility
# 进度条工具
from tqdm import tqdm
# File system operations
# 文件系统操作
import os
# Plotting and image display
# 绘图和图像显示
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
# Pickle for loading/saving Python objects
# 用于加载/保存 Python 对象的 Pickle
import pickle
# Parallel processing utilities
# 并行处理工具
from concurrent.futures import ThreadPoolExecutor, as_completed
# Encoding/decoding utilities
# 编码/解码工具
import base64
# OpenAI API
# OpenAI API
from openai import OpenAI
# Computer vision library
# 计算机视觉库
import cv2
# Request handling
# 请求处理
import requests
原始数据收集
数据预处理的首要环节是收集原始数据,涵盖视频与图像。虽然存在大量公开的 Hugging Face 数据集,但考虑到本项目旨在学习和演示,我们将主要从 Pexels 等免费资源平台随机抓取视频,并存储于本地。
Veo 3 的训练依赖于海量数据,以捕捉广泛的物体类别与多样化的场景。在本实现中,我们将目标聚焦于特定类别,如自然风光、动物以及城市场景。以下是用于从 Pexels 获取视频的预设类别:
search_queries = [
'cats', # 🐱 animals # 🐱 动物
'people walking', # 🚶♀️ humans / activity # 🚶♀️ 人类 / 活动
'cars', # 🚗 vehicles / objects # 🚗 车辆 / 物体
'hunting', # 🏹 activity / nature # 🏹 活动 / 自然
]
我们设定了有限的查询范围。接下来将使用 Pexels API 获取原始数据,需要配置相关参数。用户可从 Pexels 官网获取免费的 API 密钥(允许商业用途),并将其赋值给 PEXELS_API_KEY 变量。
根据设定的搜索查询及其他参数(如每类10个视频),预计总共将获取约 40 个视频。视频的画面方向设定为横向(主要适用于笔记本/桌面端观看),尺寸选择为小尺寸(高清画质)。
通过遍历预设的搜索查询,可以利用 Pexels API 获取视频,并将其下载至本地目录。
# Create directory for downloaded videos and set up headers for API requests
# 为下载的视频创建目录,并为API请求设置请求头
os.makedirs('pexels_videos', exist_ok=True)
headers = {'Authorization': PEXELS_API_KEY}
total_videos_downloaded = 0 # Initialize counter for total videos downloaded # 初始化已下载视频总数计数器
# Download videos for each search query
# 为每个搜索查询下载视频
for q in search_queries:
# Search for videos using Pexels API
# 使用 Pexels API 搜索视频
r = requests.get('https://api.pexels.com/videos/search',
headers=headers,
params={'query': q, 'per_page': per_page, 'orientation': orientation, 'size': size})
# Download each video from search results
# 从搜索结果中下载每个视频
for i, v in enumerate(r.json().get('videos', []), 1):
# Get highest quality video file
# 获取最高质量的视频文件
f = max(v['video_files'], key=lambda x: x['width'])
out = f'pexels_videos/{q.replace(" ", "_")}_{i}.mp4'
# Download and save video file
# 下载并保存视频文件
with requests.get(f['link'], stream=True) as s, open(out, 'wb') as o:
for chunk in s.iter_content(8192):
o.write(chunk)
total_videos_downloaded += 1 # Increment counter # 递增计数器
print(f"Total videos downloaded: {total_videos_downloaded}")
#### OUTPUT ####
Total videos downloaded: 40
40 个原始视频数据已准备就绪。接下来,我们将参照 Google 的处理流程,在获取原始数据后执行语义去重操作。
语义去重
语义去重旨在识别并移除数据集中内容相似或重复的条目,以确保信息的独特性。此步骤对于处理 PB 级别的大规模数据集尤为关键,有助于节约存储资源。这是 Google 在收集原始数据后执行的首要处理步骤。
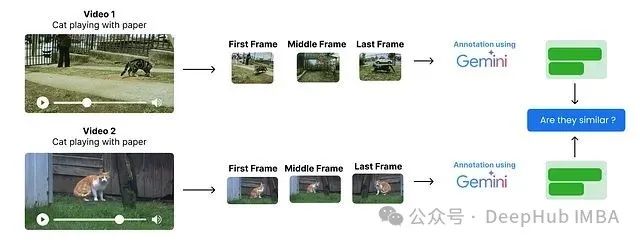
虽然本示例仅处理 40 个视频,但去重原则同样适用。其核心思路如下:
-
并非分析视频的每一帧,而是从各视频中提取起始帧、中间帧及结束帧作为关键帧。
-
利用多模态模型(如 Gemini、GPT、Claude 等)对这些关键帧进行标注,获取每帧的场景描述。
-
通过比较这些帧描述的相似性来识别潜在的重复视频。
逐帧处理视频的计算成本极高,尤其是在面对大规模数据集时。因此,本实现仅从每个视频中提取三帧进行分析。
首先,从视频中提取关键帧。以下函数实现了从每个视频中提取首、中、尾三帧的功能。
def extract_key_frames(video_path, output_dir):
cap = cv2.VideoCapture(video_path) # Open video file # 打开视频文件
if not cap.isOpened():
print(f"Failed to open {video_path}")
return []
frame_count = int(cap.get(cv2.CAP_PROP_FRAME_COUNT)) # Get total frame count # 获取总帧数
indices = [0, frame_count // 2, frame_count - 1] # Indices for key frames # 关键帧的索引
frame_paths = []
for i, idx in enumerate(indices):
cap.set(cv2.CAP_PROP_POS_FRAMES, idx) # Set frame position # 设置帧位置
ret, frame = cap.read() # Read frame # 读取帧
if ret:
out_path = os.path.join(
output_dir,
f"{os.path.basename(video_path).split('.')[0]}_frame_{i+1}.png"
) # Output path for frame # 帧的输出路径
cv2.imwrite(out_path, frame) # Save frame as PNG # 将帧保存为 PNG 格式
frame_paths.append(out_path) # Add path to list # 将路径添加到列表
cap.release() # Release video capture # 释放视频捕获对象
return frame_paths # Return list of saved frame paths # 返回保存的关键帧路径列表
执行该函数,从已下载的视频中提取关键帧。
os.makedirs('pexels_frames', exist_ok=True) # Create directory for frames if it doesn't exist # 如果帧目录不存在则创建
# Get list of all downloaded video files
# 获取所有已下载视频文件的列表
video_files = [os.path.join('pexels_videos', f) for f in os.listdir('pexels_videos') if f.endswith('.mp4')]
all_frame_paths = {} # Dictionary to store extracted frame paths for each video # 用于存储每个视频提取的关键帧路径的字典
# Use tqdm to show progress
# 使用 tqdm 显示进度
for video in tqdm(video_files, desc="Extracting key frames"):
frames = extract_key_frames(video, 'pexels_frames') # Extract key frames from video # 从视频中提取关键帧
all_frame_paths[video] = frames # Store frame paths # 存储帧路径
关键帧提取完成后,打印其中一个视频及其对应的关键帧,以验证提取过程的正确性。 # Pick a sample video and its frames #选取一个示例视频及其帧 sample_video = video_files[0] sample_frames = all_frame_paths[sample_video]
print(f"Sample video: {sample_video}")
print("Extracted key frames:")
plt.figure(figsize=(15, 5))
for i, frame_path in enumerate(sample_frames):
img = mpimg.imread(frame_path)
plt.subplot(1, 3, i + 1)
plt.imshow(img)
plt.title(f"Frame {i + 1}")
plt.axis('off')
plt.show()

然后将这些图像帧转换为有意义的文本表示,以便进行去重和相似性比较。为便于代码复现,此处选择使用兼容 OpenAI API 格式的开源大型语言模型(LLM)(例如通过 Ollama 或其他支持此 API 格式的服务调用 Mistral-24B vision 模型),而非必须使用 Gemini。
本例采用 Mistral-24B vision 模型进行图像内容的描述。
client = OpenAI(
base_url="https://api.studio.nebius.com/v1/",
api_key="YOUR_LLM_PROVIDER_API_KEY" # Replace with your OpenAI API key or any other API provider key (I am using Nebius AI) # 请替换为您的 OpenAI API 密钥或任何其他 API 提供商的密钥(此处使用 Nebius AI)
)
#Encode image file to base64 string
# 将图像文件编码为 Base64 字符串
def encode_image_to_base64(image_path):
with open(image_path, "rb") as img_file:
return base64.b64encode(img_file.read()).decode('utf-8')
# Get a concise scene description for a frame using Nebius API
# 使用 Nebius API 获取帧的简洁场景描述
def describe_frame(image_b64):
response = client.chat.completions.create(
model="mistralai/Mistral-Small-3.1-24B-Instruct-2503",
messages=[
{"role": "system", "content": "You generate concise scene descriptions for video frames."},
{
"role": "user",
"content": [
{"type": "text", "text": "Describe the scene in this frame in one line."},
{"type": "image_url", "image_url": {"url": f"data:image/png;base64,{image_b64}"}}
]
}
]
)
return response.choices[0].message.content.strip()
运行场景描述生成过程,并将结果存储于字典中。 # Generate scene descriptions for each video's key frames with progress bar # 为每个视频的关键帧生成场景描述,并显示进度条 video_descriptions = {}
for video, frames in tqdm(all_frame_paths.items(), desc="Describing frames"):
descriptions = []
for frame in frames:
img_b64 = encode_image_to_base64(frame)
desc = describe_frame(img_b64)
descriptions.append(desc)
video_descriptions[video] = descriptions
查看第一个视频生成的描述。
video_descriptions['pexels_videos\\cars_1.mp4']
#### OUTPUT ####
['A congested multi-lane highway filled ....',
'Heavy traffic flows on a rainy highway ...',
'A busy, multi-lane highway filled with various cars ...']
接下来,对视频描述进行语义去重。一种方法是利用嵌入模型 (embedding model) 将描述转换为向量表示,然后通过计算余弦相似度并设定阈值来识别重复项。
另一种方法是直接利用大型语言模型(LLM)进行语义去重。LLM 能够以类似人类的方式理解描述的上下文和深层含义。本实现将采用 LLM 来比较视频描述的语义相似性。
# Define the prompt template where two video descriptions are compared
# 定义比较两个视频描述的提示模板
compare_prompt_template = """
Compare the two videos based on their key frame descriptions.
Respond 'Yes' if they are near-duplicates, 'No' if different.
Video 1:
{desc1}
Video 2:
{desc2}
Is Video 2 a semantic duplicate of Video 1?
"""
此处将使用 LLaMA-3.3–70B 模型,通过一个比较函数来执行视频描述的语义去重。
# Use LLM to compare two videos' scene descriptions for semantic deduplication
# 使用 LLM 比较两个视频的场景描述以进行语义去重
def compare_descriptions(desc1, desc2):
"""
Returns 'Yes' if videos are semantic duplicates, 'No' otherwise.
# 如果视频在语义上重复,则返回 'Yes',否则返回 'No'。
"""
response = client.chat.completions.create(
model="meta-llama/Llama-3.3-70B-Instruct",
max_tokens=10,
temperature=0,
messages=[
{"role": "system", "content": "Answer strictly Yes or No."},
{"role": "user", "content": compare_prompt_template.format(
desc1=desc1,
desc2=desc2
)}
]
)
return response.choices[0].message.content.strip()
为加速视频描述的成对比较过程,避免因串行比较耗时过长,此处采用并行处理。具体实现将借助 concurrent.futures 库,并结合 tqdm 进行进度可视化。
# Prepare video list and names for pairwise comparison
# 准备视频列表和名称以进行成对比较
video_list = list(video_descriptions.keys())
video_names = [os.path.basename(v) for v in video_list]
n = len(video_list)
# Build all unique video pairs (including self-pairs)
# 构建所有唯一的视频对(包括自身与自身的比较)
pairs = [(i, j) for i in range(n) for j in range(i, n)]
# Function to compare two videos using their scene descriptions
# 使用场景描述比较两个视频的函数
def compare_pair(i, j):
vid1 = video_list[i]
vid2 = video_list[j]
if i == j:
return (video_names[i], video_names[j], "Self")
desc1_text = "\n".join([f"Frame {k+1}: {d}" for k, d in enumerate(video_descriptions[vid1])])
desc2_text = "\n".join([f"Frame {k+1}: {d}" for k, d in enumerate(video_descriptions[vid2])])
result = compare_descriptions(desc1_text, desc2_text)
return (video_names[i], video_names[j], result)
# Run pairwise comparisons in parallel and collect results
# 并行执行成对比较并收集结果
results = []
with ThreadPoolExecutor(max_workers=10) as executor: # adjust max_workers as needed # 根据需要调整 max_workers
futures = {executor.submit(compare_pair, i, j): (i, j) for i, j in pairs}
for f in tqdm(as_completed(futures), total=len(futures), desc="Comparing pairs"):
results.append(f.result())
#### OUTPUT ####
Comparing pairs: 100%|██████████| 820/820 [00:40<00:00, 20.44it/s]
成对比较完成后,分析结果以识别重复项。
# check if any pairs are duplicates
# 检查是否存在重复的视频对
[r for r in results if r[2] == "Yes"]
#### OUTPUT ####
[ ]
通过上述基于 LLM 的场景描述比较,我们成功地对视频对进行了语义相似性评估,并识别了潜在的重复项。根据提供的描述,结果显示当前数据集中不存在被判定为语义重复的视频对。因此,在此阶段无需移除任何视频。
接下来,我们将着手构建一个有害内容过滤系统。
不安全内容过滤
与语义去重环节相似,不安全内容过滤同样基于对视频关键帧(此处仍选用首、中、尾三帧)的分析。合并这些关键帧的描述可以形成对视频内容的概览,从而用于识别并过滤潜在的有害内容。
尽管可以进一步将视频划分为更多(如5至7个)关键帧以提升准确性,但这将显著增加处理成本。当前采用的三帧策略是在成本与准确性之间寻求平衡的折衷方案。
这些描述将用于识别并过滤潜在的有害内容。其流程可图示如下:
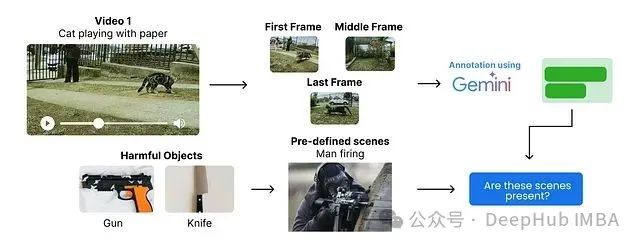
该过程的核心步骤包括:
-
从每个视频中提取首、中、尾三帧(此步骤已在语义去重环节完成)。
-
利用多模态模型为每个关键帧生成场景描述(此步骤同样已完成)。
-
根据预定义的有害内容类别(例如,涉及武器、血腥等场景),检查关键帧的场景描述是否匹配这些类别。
首先,定义基于场景描述的有害内容类别。以下为一个简化的示例列表;在实际应用中,应采用更全面的有害内容定义。
# Define harmful scenes to filter out
# 定义需要过滤的有害场景
harmful_scenes = ["man holding a gun and pointing it somewhere", "blood on the ground", "people fighting"]
# Or if you are targeting only categories of harmful content
# 或者,如果仅针对有害内容的类别
# harmful_categories = ["violence", "weapons", "blood", "fighting"]
我们已经定义了有害内容的标准。虽然可以直接采用基于有害物体识别的过滤方法,但这可能导致误将无害内容移除。
例如,若一把刀用于切割水果,而“刀”被列入有害物体清单,则包含此场景的视频将被错误删除。因此,本实现采用基于场景描述的方法进行有害内容过滤,这种方法通常更为准确,且不易产生误报。
创建一个函数来过滤有害内容,该函数将合并帧描述,并利用 LLM 判断是否包含任何有害关键词。
本例采用 LLaMA-3.3–70B 模型,通过一个比较函数对视频描述进行不安全内容过滤。
def classify_harmfulness(descriptions):
prompt = f"""
You are given descriptions of three key frames from a video.
Check if any of the following harmful scenes (or anything very close to them) are present in the descriptions:
Harmful scenes:
{chr(10).join(f"- {scene}" for scene in harmful_scenes)}
Frame descriptions:
{chr(10).join([f"Frame {i+1}: {desc}" for i, desc in enumerate(descriptions)])}
If any harmful scene or something very similar is present, respond strictly with 'Harmful'. Otherwise, respond strictly with 'Safe'.
"""
response = client.chat.completions.create(
model="meta-llama/Llama-3.3-70B-Instruct",
max_tokens=10,
temperature=0,
messages=[
{"role": "system", "content": "Answer strictly Safe or Harmful."},
{"role": "user", "content": prompt}
]
)
return response.choices[0].message.content.strip()
与去重步骤类似,可以采用并行处理来对视频描述中的有害内容进行分类。
with ThreadPoolExecutor(max_workers=10) as executor:
futures = {
executor.submit(classify_harmfulness, descriptions): video
for video, descriptions in video_descriptions.items()
}
for future in tqdm(as_completed(futures), total=len(futures), desc="Classifying harmful content"):
video = futures[future]
result = future.result()
if result == "Harmful":
harmful_videos_llm.append(video)
# Total harmful videos identified by LLM
# LLM 识别出的有害视频总数
print(f"Total harmful videos identified by LLM: {len(harmful_videos_llm)}")
#### OUTPUT ####
Total harmful videos identified by LLM: 3
根据场景描述分析,已识别出 3 个视频 包含有害内容。打印这些视频的 ID。
print(harmful_videos_llm)
#### OUTPUT ####
['pexels_videos\\hunting_1.mp4',
'pexels_videos\\hunting_4.mp4',
'pexels_videos\\hunting_9.mp4']
此结果符合预期。回顾原始数据收集阶段,我们曾使用搜索查询“hunting”。因此部分视频包含狩猎场景的可能性较高,而这类场景在某些标准下可能被视为有害。
打印其中一个被识别为有害的视频,以查看其描述信息。
# Plot the first frame of each harmful video detected by the LLM
# 绘制 LLM 检测到的每个有害视频的第一帧
n = len(harmful_videos_llm)
fig, axes = plt.subplots(1, n, figsize=(5 * n, 5))
if n == 1:
axes = [axes]
# Display the first frame for each harmful video
# 显示每个有害视频的第一帧
for ax, video in zip(axes, harmful_videos_llm):
frames = all_frame_paths[video]
if frames:
img = mpimg.imread(frames[0])
ax.imshow(img)
ax.set_title(f"Harmful Video: {os.path.basename(video)}")
ax.axis('off')
else:
ax.set_visible(False)
plt.tight_layout()
plt.show()
这些视频各不相同,尽管它们可能源自同一创作者。LLM 准确地将它们识别为有害内容,因为我们的有害场景列表中包含了“man holding a gun and pointing it somewhere.”(男性持枪指向某处)。接下来,从数据集中移除这些视频。
完成不安全内容过滤后,下一步是进行质量与合规性筛选。

质量与合规性过滤
质量与合规性过滤是预处理流程中在数据标注之前的关键步骤,在此阶段将依据特定要求对数据进行进一步的分析与筛选。
例如,若目标是构建高质量视频数据集,则需依据特定标准(如模糊度、分辨率等)剔除低质量视频。或者,若目标是特定类型的内容,则需过滤掉不符合要求(例如,包含知名人物、名人等)的视频。
其流程可图示如下:
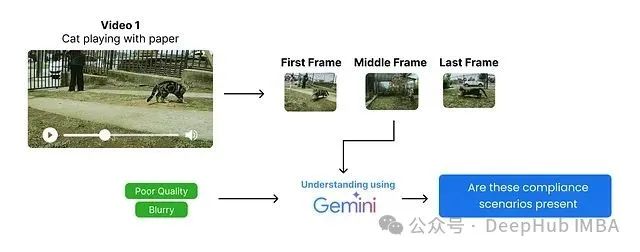
该过程的核心步骤包括:
-
从每个视频中提取首、中、尾三帧(此步骤已完成)。
-
根据具体需求定义质量与合规标准(例如,是否包含车牌、名人,视频是否模糊等)。
-
基于场景描述识别预定义的质量与合规问题,并检查关键帧的场景描述是否触发这些标准。
与不安全内容过滤步骤类似,可以分析多个关键帧以评估质量,但为简化起见,本实现仍聚焦于首、中、尾三帧。
以下为一个简化的质量标准定义;在 Veo 3 这样的实际大规模应用中,需要采用更全面的标准列表。
# We are focusing on Blurry, and Poor lighting as quality compliance issues
# 我们关注模糊和光照不足作为质量合规问题
quality_compliance = [
"Blurry: The video is so out of focus that the primary objects or subjects cannot be clearly seen or identified.",
"Poor lighting: The video is too dark, too bright, or has uneven lighting, making it difficult to see or recognize key objects or actions."
]
定义一个函数 check_frame_quality,该函数利用多模态 LLM 对每帧的质量进行分类。本例采用 Mistral 24B 模型执行此任务。
def check_frame_quality(image_b64):
issues = ", ".join(quality_compliance)
response = client.chat.completions.create(
model="mistralai/Mistral-Small-3.1-24B-Instruct-2503",
messages=[
{"role": "system", "content": (
f"You are an expert in video quality assessment. "
f"If the frame has {issues}, reply 'Non-compliant'. Else reply 'Compliant'."
)},
{"role": "user", "content": [
{"type": "text", "text": (
f"Does this frame have {issues}? Reply 'Compliant' or 'Non-compliant'."
)},
{"type": "image_url", "image_url": {"url": f"data:image/png;base64,{image_b64}"}}
]}
],
max_tokens=10,
temperature=0
)
return response.choices[0].message.content.strip()
质量合规性检查主要关注中间帧。因此创建一个函数从每个视频中提取中间帧。
def classify_middle_frame(video_path, frames):
# Try to check the quality of the middle frame (frame 2)
# 尝试检查中间帧(第2帧)的质量
try:
# Ensure frames list is not empty and has at least 2 elements (index 1)
# 确保帧列表不为空且至少包含2个元素(索引1)
if frames and len(frames) > 1:
image_b64 = encode_image_to_base64(frames[1]) # Encode middle frame to base64 # 将中间帧编码为base64
# Return video path if frame is non-compliant
# 如果帧不符合规定,则返回视频路径
return video_path if check_frame_quality(image_b64) == "Non-compliant" else None
else:
# If frames list is empty or too short, mark as non-compliant
# 如果帧列表为空或太短,则标记为不符合规定
return video_path
except Exception as e:
print(f"Error processing {video_path}: {e}")
# On error, mark as non-compliant for safety
# 发生错误时,为安全起见标记为不符合规定
return video_path
为避免处理时间过长,此处同样采用多线程并行处理。
# Non compliant videos list
# 不合规视频列表
non_compliant_videos = []
# Use ThreadPoolExecutor to classify middle frames in parallel
# 使用 ThreadPoolExecutor 并行分类中间帧
with ThreadPoolExecutor(max_workers=10) as executor:
# Create a dictionary to map futures to video paths for easier error tracking if needed
# 创建一个字典,将 future 映射到视频路径,以便在需要时更轻松地进行错误跟踪
future_to_video = {executor.submit(classify_middle_frame, v, f): v for v, f in all_frame_paths.items() if v not in harmful_videos_llm}
# Use tqdm for progress bar
# 使用 tqdm 显示进度条
for future in tqdm(as_completed(future_to_video), total=len(future_to_video), desc="Checking frame quality"):
result = future.result()
if result:
non_compliant_videos.append(result)
print(f"Total non-compliant videos found: {len(non_compliant_videos)}")
#### OUTPUT ####
Total non-compliant videos found: 8
根据中间帧质量检查,共发现 8 个不合规视频。可视化其中一个不合规视频的中间帧以分析问题。
# Pick the random non-compliant video
# 随机选取一个不合规的视频
video_path = non_compliant_videos[6]
middle_frame_path = all_frame_paths[video_path][1] # Middle frame is at index 1 # 中间帧的索引为1
img = mpimg.imread(middle_frame_path)
plt.imshow(img)
plt.title(f"Middle Frame: {video_path}")
plt.axis('off')
plt.show()

该帧确实存在模糊问题,所用方法已将其正确识别为不合规。接下来,从数据集中移除这些不合规视频。
for video in non_compliant_videos:
try:
os.remove(video) # Remove the video file # 删除视频文件
print(f"Removed non-compliant video: {video}")
except Exception as e:
print(f"Error removing {video}: {e}") # Handle any errors during removal # 处理删除过程中的任何错误
至此,数据集中所有有害及不合规的视频均已移除。统计筛选后剩余的视频数量。
# Count the number of videos remaining after filtering
# 统计筛选后剩余的视频数量
video_paths = [os.path.join('pexels_videos', f) for f in os.listdir('pexels_videos') if f.endswith('.mp4')]
print(f"Total remaining videos after filtering: {len(video_paths)}")
#### OUTPUT ####
Total remaining videos after filtering: 28
当前训练视频的长度各异。为统一输入,需将训练视频修剪至固定长度。Veo 3 能够生成长达 8 秒的视频。为简化实现,本例将所有视频统一修剪为 5 秒。
此举有助于减小数据集规模,并解决因视频过长导致的训练时间和资源消耗增加的问题。
执行视频修剪操作。
# Function to trim videos to a specified duration (in seconds)
# 将视频修剪到指定时长(秒)的函数
def trim_video(input_path, output_path, duration=5):
# Open the input video file
# 打开输入视频文件
cap = cv2.VideoCapture(input_path)
fps = cap.get(cv2.CAP_PROP_FPS) # Get frames per second # 获取帧率
total_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT)) # Total number of frames in the video # 视频总帧数
target_frames = int(fps * duration) # Number of frames to keep for the specified duration # 指定时长对应的帧数
# If the video is shorter than the target duration, skip trimming
# 如果视频时长短于目标时长,则跳过修剪
if total_frames < target_frames:
print(f"Video {input_path} is shorter than {duration} seconds. Skipping.")
cap.release()
return
# Set up the video writer for the output trimmed video
# 为输出的修剪后视频设置 VideoWriter
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
out = cv2.VideoWriter(output_path, fourcc, fps, (int(cap.get(3)), int(cap.get(4))))
# Write frames up to the target duration
# 写入帧直至达到目标时长
for _ in range(target_frames):
ret, frame = cap.read()
if not ret:
break
out.write(frame)
# Release resources
# 释放资源
cap.release()
out.release()
对所有视频执行此修剪函数。
os.makedirs('trimmed_videos', exist_ok=True)
def process_video(input_path):
output_path = os.path.join('trimmed_videos', os.path.basename(input_path))
trim_video(input_path, output_path, duration=5)
with ThreadPoolExecutor(max_workers=8) as executor:
list(tqdm(executor.map(process_video, video_paths), total=len(video_paths), desc="Trimming videos"))
视频已修剪至 5 秒并存储于 trimmed_videos 目录。可进一步执行筛选步骤,例如,仅保留文件大小小于 20 MB 的视频。这有助于确保视频文件轻量化,便于后续处理与分发。
执行此步骤,移除文件体积较大的视频,仅保留较小者。
# Remove videos that are more than 20MB in size with progress bar
# 移除体积大于20MB的视频,并显示进度条
def remove_large_videos(video_paths, max_size_mb=20):
for video in tqdm(video_paths, desc="Checking video sizes"):
if os.path.getsize(video) > max_size_mb * 1024 * 1024: # Convert MB to bytes # 将MB转换为字节
try:
os.remove(video)
print(f"Removed large video: {video}")
except Exception as e:
print(f"Error removing {video}: {e}")
# Call the function to remove large videos
# 调用函数移除大体积视频
remove_large_videos(trimmed_video_paths, max_size_mb=20)
# get all trimmed video paths
# 获取所有修剪后视频的路径
trimmed_video_paths = [os.path.join('trimmed_videos', f) for f in os.listdir('trimmed_videos') if f.endswith('.mp4')]
print(f"Total trimmed videos: {len(trimmed_video_paths)}")
#### OUTPUT ####
Total trimmed videos: 22
经过有害内容及不合规视频的过滤,最终剩余 22 个视频。现在进入预处理流程的最后一步:对这些经过筛选的视频进行内容标注。
数据标注
在 Veo 3 的实际构建流程中,前述的各项过滤步骤可能会迭代执行多次。数据预处理的最终环节是数据标注。尽管在先前步骤中尝试使用开源模型以控制成本,但高质量的视频内容标注通常需要依赖具备强大视频理解能力的模型,如 Google 的 Gemini 系列。

Veo 3 的训练数据预处理,包括标注环节,均多次迭代进行,其中标注任务主要由 Gemini 模型完成。本实现将遵循类似流程。用户可从 Gemini 官网获取免费 API 密钥(允许商业用途),并将其配置到 GEMINI_API_KEY 环境变量或代码变量中。
genai.configure(api_key="YOUR_GEMINI_API_KEY") # Replace with your Gemini API key # 请替换为您的 Gemini API 密钥
model = genai.GenerativeModel("gemini-2.0-flash") # We are using Gemini 2.0 Flash model # 本示例使用 Gemini 2.0 Flash 模型
对修剪后的视频进行标注。
# Iterate through each trimmed video and generate a summary annotation
# 遍历每个修剪后的视频并生成摘要式标注
for video_file_name in tqdm(trimmed_video_paths, desc="Annotating videos"):
with open(video_file_name, 'rb') as f:
video_bytes = f.read()
try:
# Use Gemini model to generate a 3-sentence summary for the video
# 使用 Gemini 模型为视频生成一个三句话的摘要
response = model.generate_content([
{
"mime_type": "video/mp4",
"data": video_bytes
},
"Summarize the video in 3 sentences. Provide only the summary and nothing else."
])
# Extract summary text from the response
# 从响应中提取摘要文本
summary = response.text if hasattr(response, "text") else str(response)
except Exception as e:
# Handle errors and store the error message as summary
# 处理错误并将错误信息作为摘要存储
summary = f"Error: {e}"
# Append the annotation result to the list
# 将标注结果追加到列表中
video_annotations.append({"video_path": video_file_name, "summary": summary})
# 打印一个标注示例
video_annotations[0]
#### OUTPUT ####
{'video_path': 'trimmed_videos\\cars_10.mp4',
'summary': 'The video shows two cars drifting in a parking lot track marked with tires, with a crowd watching from a building in the background. The yellow car takes the initial lead but is overtaken by the dark colored car, which then drifts around the tires leaving smoke. The cars continue to drift around the track marked with tires.\n'}
对生成的摘要进行必要的清理,例如移除固定的前缀(如 “The video shows”)并确保摘要的简洁性。
# Removing 'The video shows' prefix from summaries
# 从摘要中移除 "The video shows" 前缀
for annotation in video_annotations:
if annotation['summary'].startswith("The video shows"):
annotation['summary'] = annotation['summary'][len("The video shows"):].strip()
至此,已按照 Veo 3 的规范对数据进行了预处理,包括去重、质量合规检查及生成简洁标注。为适应 Veo 3 模型的训练需求,仍需对数据结构进行进一步调整。
此步骤属于 Veo 3 模型训练流程的一部分,将在后续章节中详细介绍。

