清华上交发布FISHER,首个多模态工业信号基座模型,解决M5难题,现已开源赋能工业智能运维。
原文标题:首个多模态工业信号基座模型FISHER,权重已开源,来自清华&上交等
原文作者:机器之心
冷月清谈:
研究团队发现,尽管工业信号表面差异巨大,但在其内在特征、语义信息、产生机理和分析手段上却存在诸多相似之处,这为构建统一模型提供了可能。FISHER模型以此为切入点,创新性地采用子带作为建模单元,利用短时傅里叶变换(STFT)处理信号特征,并且能够直接应对不同采样率的工业信号,避免了传统重采样可能导致的高频信息丢失。其核心架构包含一个ViT Encoder和CNN Decoder,并采用“老师-学生”自蒸馏预训练模式,有效提升了模型的表征能力和泛化性。
为全面评估模型性能,研究团队还提出了RMIS基准,涵盖了多种模态下的异常检测和故障诊断任务。实验结果表明,FISHER模型在RMIS基准上表现卓越,其不同尺寸版本相较于现有基线模型均获得了显著提升。特别是在故障诊断任务上,FISHER凭借能利用完整频带的优势,大幅超越了多数基线模型。 此外,模型在不同模型尺寸下的Scaling效果也验证了其预训练模式的优越性,即使是最小的FISHER-tiny模型,也能超越所有基线系统,展现了强大的泛化能力和数据利用效率。研究者指出,未来在训练更大规模工业信号基座模型时,数据的配比和清洗将是关键。
怜星夜思:
2、文章里提到语音模型的效果普遍偏差,所以没有对比。那么,工业信号和语音信号在特性上到底有哪些根本区别,导致针对工业信号的模型需要有如此特别的设计?未来它们有没有可能在某种程度上相互借鉴甚至融合呢?
3、FISHER模型的目标是统一异质工业信号的建模,这听起来对企业是好事。实际应用中,这种统一建模能带来哪些具体的经济效益或潜在的商业模式创新?比如,真的能大幅降低运维成本,还是能开辟新的服务领域?
原文内容

近期,来自清华大学、上海交通大学、北京华控智加科技有限公司和华北电力大学的研究者联合发布首个多模态工业信号基座模型 FISHER,采用搭积木的方法对异质工业信号进行统一建模。目前技术报告和权重均已开源,欢迎使用!

-
论文链接:https://arxiv.org/abs/2507.16696
-
GitHub 仓库:https://github.com/jianganbai/FISHER
研究背景
近年来,越来越多的工业设备被安装上传感器以监控工作状态。然而安装传感器容易,如何高效分析工业信号却很难,因为不同传感器采集的工业信号具有极大的异质性。本文中,我们将其总结为 M5 问题:多模态、多采样率、多尺度、多任务和少故障。
受到 M5 问题影响,现有方法大多只分析小范围的工业信号,例如基于振动的轴承故障诊断,所采用的模型也均为在小数据集上训练的小模型。然而这些模型未能发掘大数据训练的优势,也未能利用不同模态之间的互补性。另一方面,对于工业运维的每个子问题,都需要单独开发和部署专门的模型,大大增加了实际应用的复杂度。
研究动机
尽管工业信号表面上差异大,其内在特征和语义信息却很相似:
-
语义信息相同:信号都反映了相同的健康状态。
-
产生机理相似:声音(鼓膜震动)和振动同根同源。
-
分析手段相似:基本都采用谱分析方法。
-
故障模式相似:设备由零件组成,不同设备之间有借鉴性。
-
任务特征共享:一个特征向量可表征多个健康管理任务。
基于此,我们认为是可以使用单一模型对异质工业信号进行统一建模。由于信号内部存在相似性,通过 scaling,可以让模型逐渐学会这些相似性,进而迸发出更为强大的表征能力,实现里程碑式提升。由此我们开发了 FISHER 模型。
FISHER 模型介绍

FISHER 模型是首个面向多模态工业信号的基座模型。它以子带为建模单元,通过堆积木的方式表征整段信号,可处理任意采样率的工业信号。详细介绍如下:
子带建模
谱分析是语音和信号分析常用的手段。与语音模型常采用的 Mel 谱不同的是,FISHER 采用短时傅里叶变换(STFT)作为信号输入特征,这是由于 1)故障分量往往出现在高频 2)对于旋转类机械,倍频关系往往很重要。为保证不同采样率下时频分辨率相同,FISHER 中的 STFT 采用固定时长的窗长和帧移。
当数据量增大时,多采样率是模型必须要应对的问题。之前方法将信号全部重采样至固定采样率(例如 16 kHz),从而丢失了关键的高频信息,特别是对于 44.1 kHz 及以上的高带宽信号。在 FISHER 中,我们不再进行重采样,而是利用信号在不同采样率下的特点进行建模。
如下图所示,对同一信号源使用不同采样率进行观测时,共有频带基本一致,而高采样率会有额外的高频子带,也就是说高采样率的增益来源于更多子带信息。而另一方面,工业信号常见的采样率有 16 kHz,32 kHz,44.1 kHz 和 48 kHz,这些采样率近似存在公约数(如 2 kHz 和 4 kHz),故 STFT 谱可视作多个固定宽度子带的拼接。

因此 FISHER 采用固定宽度的子带作为建模单元,将子带信息用搭积木的方式拼接成整段信号的表征。具体而言,STFT 谱被切分为固定宽度的子带,每个子带被模型单独处理。最终的信号表征是每个子带表征的拼接。
模型架构
FISHER 包括 1 个 ViT Encoder 和 1 个 CNN Decoder,采用「老师 - 学生」自蒸馏预训练。具体而言,老师 Encoder 是学生 Encoder 的指数滑动平均(EMA),仅学生 Encoder 和学生 Decoder 具有梯度。切分后的子带的 80% 被 mask,未被 mask 的 20% 送入学生 Encoder,处理后再与被 mask 部分按原位置拼接,送入学生 Decoder。老师 Encoder 则输入整个子带,输出则作为蒸馏的目标。自蒸馏过程分别在 [CLS] 层次和 patch 层次进行监督。预训练结束后,仅保留学生 Encoder 用于后续评估。
我们目前开源了 FISHER 的 3 个不同尺寸:tiny(5.5M),mini(10M)和 small(22M)。所有模型均在 1.7 万小时的混合数据集上进行预训练。
RMIS 基准介绍
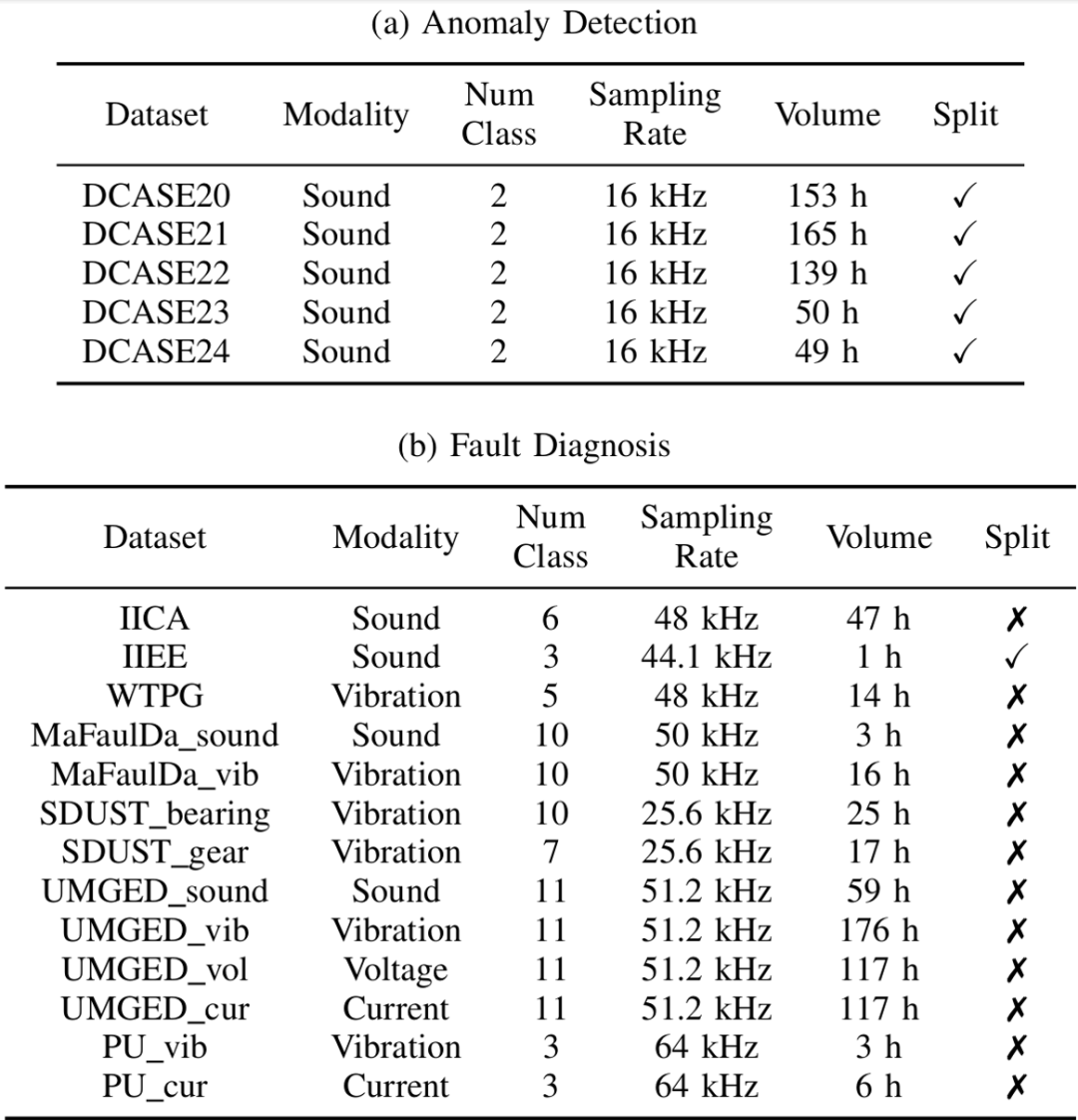
为评估模型在各种健康管理任务上的性能,我们提出了 RMIS 基准。RMIS 基准包含 5 个异常检测数据集和 13 个故障诊断数据集,涵盖 4 个模态。这里异常检测为正常 / 异常 2 分类问题,但训练集不包含异常;故障诊断为多分类问题,训练集和测试集均包含所有类别。为检验模型固有的性能,模型在所有数据集上均使用相同的 KNN 配置进行推断,不进行微调。
实验结果
我们先在 RMIS 基准上对常见预训练模型进行筛选,然后采用 5 个最好的模型作为基线,涵盖了 5M 到 1.2B 的多个尺寸。由于语音模型的效果普遍偏差,故我们并未对比。
基准得分

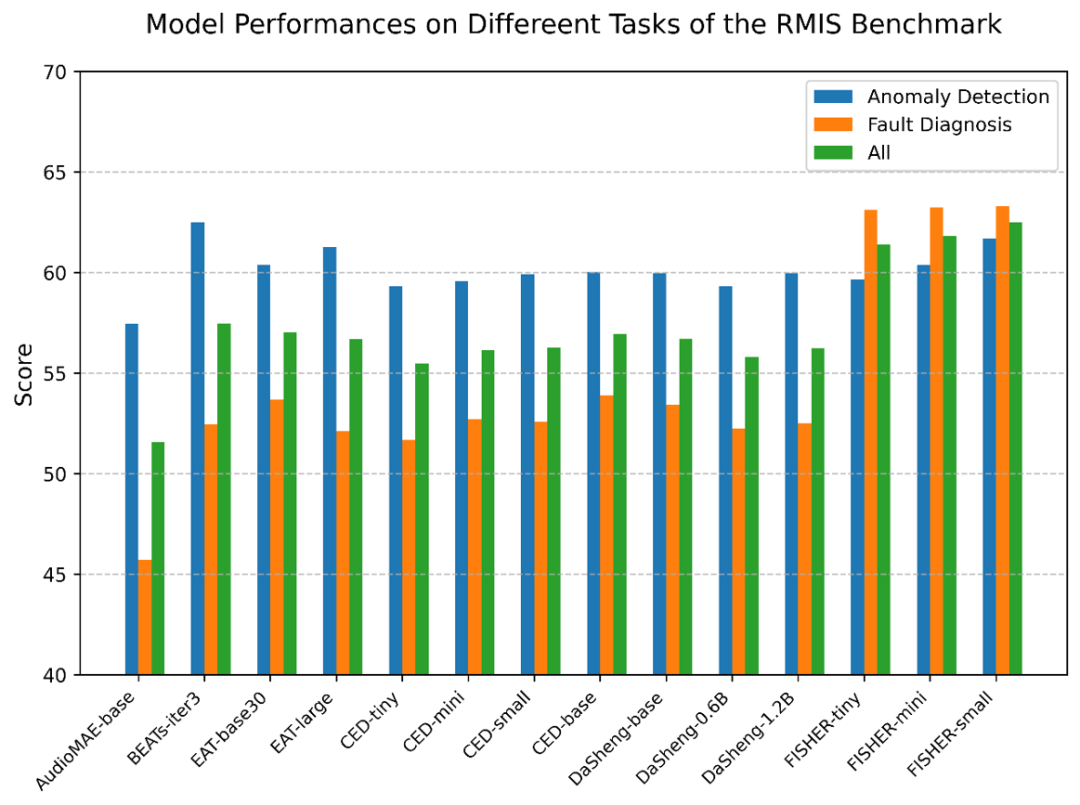
在 RMIS 基准上,FISHER 的 3 个版本分别较基线至少提升了 3.91%,4.34% 和 5.03%,展现出强大的泛化能力。按任务分析,在异常检测任务上,FISHER 仅略低于 BEATs;而在故障诊断任务上,FISHER 大幅超过 BEATs 在内的所有基线,这主要得益于 FISHER 能利用完整的频带,而基线模型只能利用到 16 kHz。此外,目前开源的 FISHER 模型最大也只有 22M,远小于基线常见的 90M。
Scaling 效果
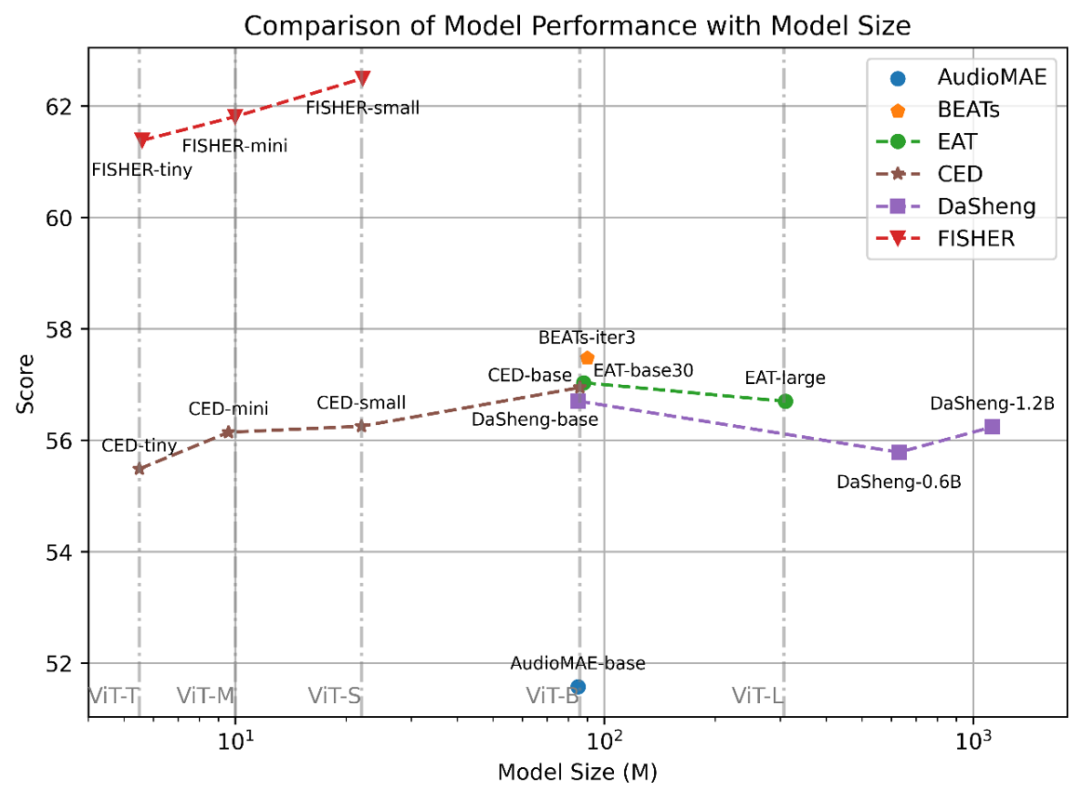
上图对比了各个模型的 RMIS 得分随模型大小变化的曲线。可以看到 FISHER 的曲线远高于基线系统的曲线,即使是最小的 FISHER-tiny 也能超过所有基线系统。这说明 FISHER 的预训练模式更优越,scaling 更有效。
另一方面,我们观察到 100M 似乎是 scaling 曲线的分界点。我们猜测这是由于工业信号重复度较高,现有大规模数据集中的工业信号去重后至多支持 100M 模型的训练。因此训练信号基座模型时,数据的配比需要增大,数据清洗将是 scaling up 的关键。此外,考虑到 FISHER 的成功,Test-Time Scaling 似乎也是可行的方向。
变切分比
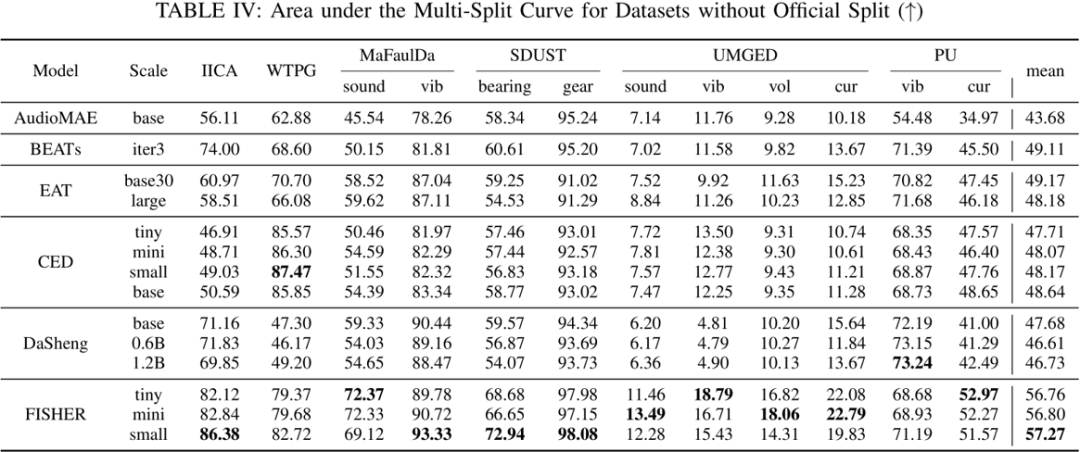
对于 12 个不提供官方切分的数据集,我们首先绘制了模型在变切分比场景下的工作曲线,然后估计了曲线下面积。如上表所示,FISHER 具有最大的曲线下面积,说明其在变切分比场景下依旧具有卓越的性能。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com