北大团队推出MP1机器人学习新范式:首次引入MeanFlow范式,实现毫秒级推理与SOTA成功率,并通过分散损失提升少样本泛化能力。#机器人 #AI
原文标题:MeanFlow再下一城,北大提出机器人学习新范式MP1,实现速度与成功率双SOTA
原文作者:机器之心
冷月清谈:
怜星夜思:
2、分散损失(Dispersive Loss)听起来很有用,能解决“特征坍塌”,提升少样本学习能力。但有没有什么潜在的缺点或者适用局限性呢?比如数据量特别大时,它还会这么有效吗?
3、MP1在操作成功率和实时性上都做得挺好。大家觉得,如果这种技术大规模普及,对咱们普通人的生活会有啥具体影响?是像电影里那样机器人管家遍地走,还是更偏向工业领域?
原文内容

在目前的 VLA 模型中,「A」— 动作生成模型决定了动作生成的质量以及速度。具体而言,生成式模型在推理速度与任务成功率之间存在 「根本性权衡」。
其中,Diffusion Models(如 Diffusion Policy 和 DP3)通过多步迭代生成高质量动作序列,但推理速度较慢,难以满足实时控制要求;而 Flow-based 模型(如 FlowPolicy)尽管能提供快速推理,但需要额外的架构约束或一致性损失(consistency loss)来保证轨迹的有效性,这增加了设计复杂性并可能限制性能和泛化能力。
此外,机器人操作面临另一个挑战,即数据高效的少样本泛化。标准模仿学习策略容易出现 「特征坍塌(feature collapse)」,即将需要不同动作的关键状态错误地映射到相似的潜在表征 latent representation)上,导致模型在新情境下无法做出准确反应。因此,提升模型对不同状态的区分能力是提高策略泛化性的关键。
为应对上述挑战,来自北大的研究团队提出名为 MP1 的全新机器人学习框架。该框架首次将近期在图像生成领域取得突破的 MeanFlow 范式引入机器人学习,实现毫秒级推理速度,为 VLA 动作生成模型打下基础。

-
论文标题:MP1: MeanFlow Tames Policy Learning in 1-step for Robotic Manipulation
-
论文链接:https://arxiv.org/abs/2507.10543
-
代码链接: https://github.com/LogSSim/MP1
MP1 的核心引擎 ——Mean Flow 范式
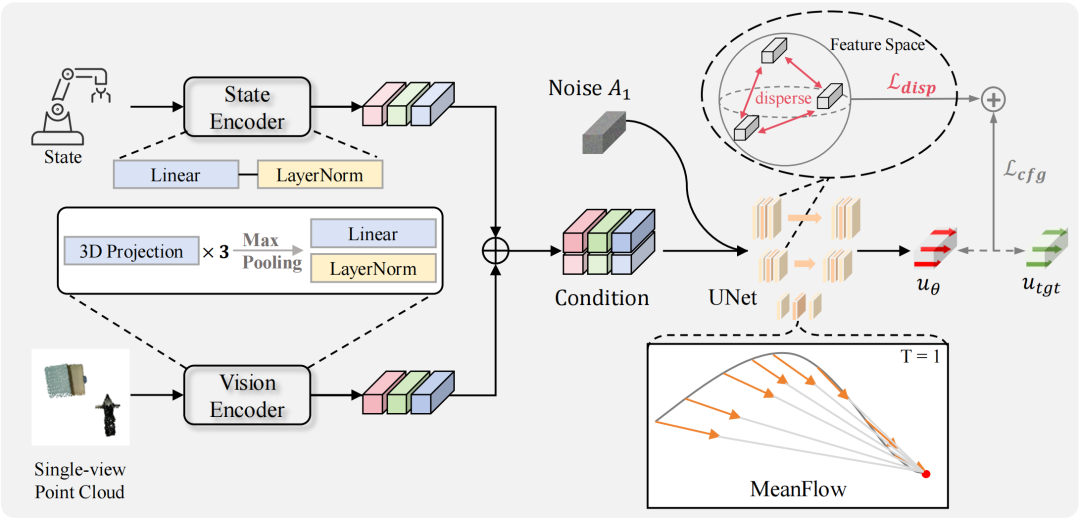
MP1 的核心创新在于其生成范式的根本转变。传统 Flow Matching 学习的是一个瞬时速度场(instantaneous velocity field),在推理时需要通过迭代式求解常微分方程(ODE)来积分生成轨迹,这一过程不仅耗时,且会引入并累积数值误差。与之相反,MP1 直接学习从初始噪声到目标动作的区间平均速度场(interval-averaged velocity field)。
技术上,MP1 利用了 「MeanFlow Identity」,使模型能够直接对平均速度场进行建模,而无需在推理时进行任何积分求解。这一设计带来了两大核心优势:
-
真正的单步生成(1-NFE):模型仅需一次网络前向传播,即可从随机噪声直接生成完整动作轨迹,彻底摆脱了对迭代式 ODE 求解器的依赖。
-
无约束的简洁性:得益于其数学形式的完备性,MP1 天然保证了轨迹质量,无需引入 FlowPolicy 等方法所依赖的外部一致性约束,使模型设计更为简洁、优雅。
这种从数学原理上解决问题的方式,而非依赖工程技巧进行修补,使得 MP1 不仅实现了速度的飞跃,更重要的是,其单次、确定性的前向传播过程保证了推理时间的高度稳定,这能够保证机器人操作任务中的实时性。
分散损失提升少样本泛化能力
在解决轨迹生成的动态问题后,MP1 针对机器人学习中的 「表征坍塌」 问题进行了改进。该问题指的是策略网络将需要不同动作的关键状态错误地映射到相近的潜在空间位置,从而导致模型在少样本学习中泛化能力下降。
MP1 引入了来自表征学习领域的最新方法 —— 分散损失(Dispersive Loss)。这是一种轻量级、仅在训练阶段生效的正则化项,旨在直接优化策略网络的内部表征空间。其核心思想是在训练的每个 mini-batch 中,对不同输入样本的潜在表征施加一种 「排斥力」,强制它们在特征空间中相互分散。该损失可以被理解为一种 「无正样本的对比损失」:策略网络主要的回归目标负责将每个状态 「拉向」 其对应的专家动作,而分散损失则负责将不同状态的表征相互 「推开」,从而塑造出一个更具辨识度的特征空间。
分散损失的关键优势在于它是一个仅在训练时生效的正则化器,在不增加任何推理开销的前提下,显著提升了模型区分细微场景差异的能力,完美保留了 MP1 标志性的毫秒级响应速度。在数据采集成本高昂的机器人领域,这种能从极少量(如 5-10 个)示教中高效学习的能力至关重要。
MP1 的仿真测试表现
MP1 的性能优势在涵盖 37 个复杂操作任务的 Adroit 与 Meta-World 基准测试中得到了验证。
出色的任务成功率与稳定性

在任务成功率方面,MP1 平均成功率达到 78.9%,相较于当前先进的流模型 FlowPolicy (71.6%) 和扩散模型 DP3 (68.7%),分别实现了 7.3% 和 10.2% 的显著提升。
尤为关键的是,MP1 的优势在更高难度的任务中愈发凸显。在 Meta-World 的 「中等」、「困难」 及 「非常困难」 任务集上,MP1 相较于 FlowPolicy 的成功率增幅分别高达 9.8%、17.9% 和 15.0% 。此外,MP1 展现出极高的性能稳定性。在多次随机种子实验中,其成功率的平均标准差仅为 ±2.1%,远低于其他基线方法,证明了其结果的高度可靠性与可复现性。
卓越的推理效率与实时控制能力
在实现更高成功率的同时,MP1 的推理速度同样刷新了纪录。在 NVIDIA RTX 4090 GPU 上,其平均推理耗时仅为 6.8ms。

这一速度比当前最快的流模型 FlowPolicy (12.6 ms) 快了近 2 倍,更比强大的扩散模型 DP3 (132.2 ms) 快了 19 倍。如此低的延迟意味着 MP1 的决策环路完全满足机器人领域典型的实时控制频率(通常为 20-50 毫秒)。
少样本学习能力验证
为了进一步验证分散损失在提升模型数据效率上的作用,研究团队还进行了少样本学习的消融实验。
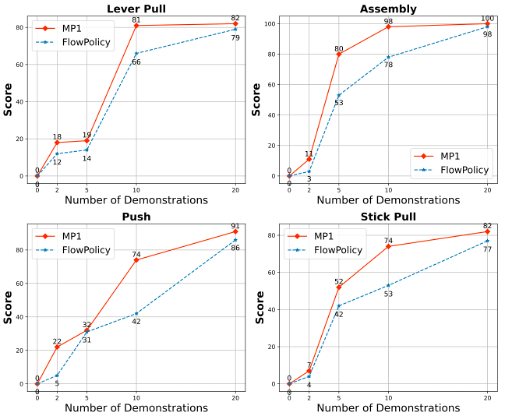
实验结果表明,MP1 在所有数据量级上均一致地优于 FlowPolicy,尤其是在示教数据极为稀少(如 2-5 个)的极端少样本场景下。这有力地证明了分散损失通过优化内部表征空间,能够有效提升策略少样本学习的泛化能力,这可以降低真机部署时大量数据的需求。
MP1 的真机验证

研究团队将 MP1 部署于一台 ARX R5 双臂机器人上,并在五个真实的桌面操作任务中进行了测试。
实验结果进一步印证了 MP1 的性能。在所有五项任务中,MP1 均取得了最高的成功率和最短的任务完成时间。以 「Hummer」 任务为例,MP1 的成功率高达 90%,远超 FlowPolicy 和 DP3 的 70%;同时,其平均任务耗时仅 18.6 秒,显著快于 FlowPolicy(22.3 秒)和 DP3(31.1 秒)。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com