前Meta团队创办Memories.ai,获800万美元融资。他们正打造AI的视觉记忆大脑,彻底解决视觉模型“金鱼记忆”难题,赋能AI深度理解海量视频数据。
原文标题:Meta出走华人创业团队,种子轮800万美元,要打造视觉AI记忆大脑
原文作者:机器之心
冷月清谈:
Memories.ai的核心创新成果是其自主研发的“大视觉记忆模型”(LVMM),它为AI系统创建了一个革命性的视觉记忆层。有别于传统AI对视频的片段式分析,LVMM能够持续捕获、存储并结构化海量的视觉数据,赋予AI永久保留上下文信息、精准识别时序模式以及智能对比分析的能力。这意味着AI系统不再局限于对单一帧或短时片段的理解,而是能够深入理解事件的因果链,实现对人脸、物体和行为在时间轴上的持续追踪。
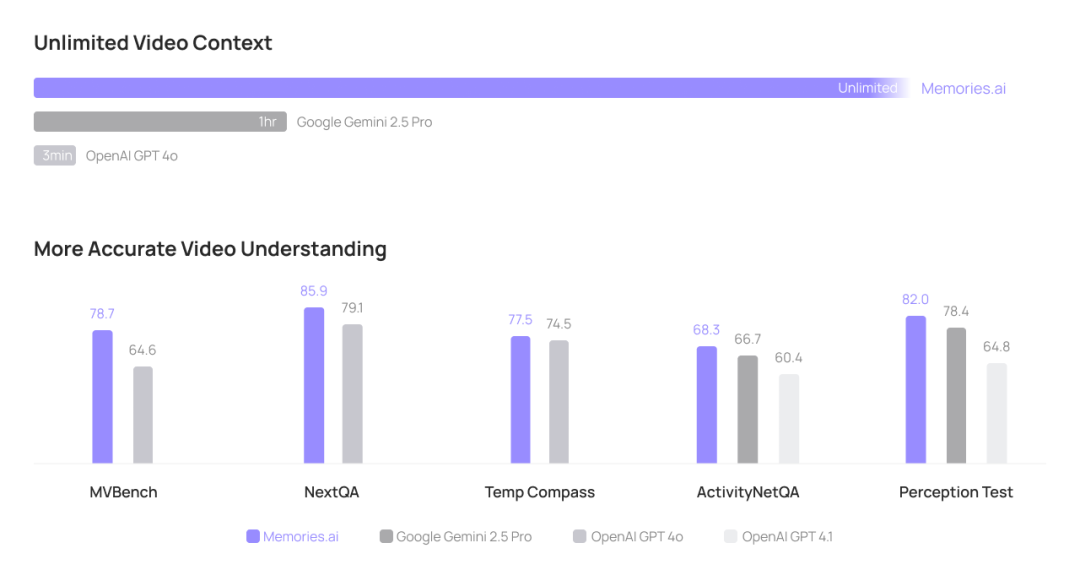
该技术已在多个视觉理解任务中刷新了SOTA(State-of-the-Art)基准,并在视频分类、视频检索和视频问答领域展现出卓越性能,特别是在处理需要大规模内容检索支持的复杂查询时表现出色。LVMM展现出巨大的应用潜力,包括但不限于安防安全(数秒内检索数月监控数据)、媒体娱乐(即时查找数十年内容库中的特定场景)、市场营销(深度分析社交视频趋势)以及消费电子领域(如与三星合作,提升手机的视觉记忆功能)。
为了方便用户体验LVMM的强大能力,Memories.ai已通过API接口开放其核心技术,并同步推出直观的网页应用,用户可便捷地上传视频或接入现有视频库进行快速、精准的内容检索和深度分析。团队还发布了多款Demo Agents,如基于LVMM的Video Creator(对话式视频创作助手)和Video Marketer(智能营销工具),进一步展示了其在不同场景下的应用可能性。
怜星夜思:
2、文章提到LVMM技术未来会应用于消费电子,比如手机。想象一下,未来配备了“视觉记忆大脑”的手机、智能眼镜或者其他穿戴设备,除了文中简单提到的“引入强大视觉记忆能力”,还能给我们日常带来哪些意想不到的便捷或变化?甚至是一些我们现在还没想到的新交互模式?
3、Memories.ai解决了大模型的“金鱼记忆”痛点,让AI在视觉领域有了长时记忆。那么,除了视觉,AI在其他模态(比如文本、音频)的“记忆”问题是否也同样严重?如果未来这类长时记忆技术能推广到所有模态,AI的认知能力和应用边界又会如何被彻底重塑?
原文内容
机器之心编辑部
大家都在关注硅谷 AI 领头羊们的抢人大戏,尤其是 Meta 近期又挖去了三位来自谷歌的 IMO 金牌研究者。
虽然说小扎(扎克伯格)铆足了劲儿要重振 Llama 雄风,正如火如荼的进行人才大引进。
但是吧,挖进去的人在 Meta 显山露水还需要一段时间,而从 Meta 离开的人的创业成果已经崭露头角了。

Dr. Shawn Shen,联合创始人兼首席执行官(左);Ben (Enmin) Zhou,联合创始人兼首席技术官(右)。
由前 Meta Reality Labs 顶尖科学家团队创立的 AI 研究实验室 Memories.ai,正式宣布完成 800 万美元种子轮融资。本轮融资由 Susa Ventures 领投,三星风投(Samsung Next)、Fusion Fund 等知名机构跟投。
Memories.ai 团队已经在大模型领域完成了一项重大的突破成果,剑指 AI 系统的「记忆缺失」问题,为视觉模型创造了强大的「记忆大脑」。
「最强大脑」
众所周知,大模型是标标准准的「金鱼记忆」。
比如,大多数 AI 系统都缺乏对历史画面的记忆,难以理解前后之间的关联。
就像我们经常开的玩笑,「记忆是个先进先出栈」,只不过大模型的栈容量似乎总是不够用。
这种「金鱼记忆」限制了它们在需要深入理解场景和动态变化的应用中发挥作用,尤其是在视频密集型任务里表现不佳。
为了彻底解决这个问题,Memories.ai 通过其核心创新 —— 大视觉记忆模型(LVMM),为 AI 系统引入了一个革命性的视觉记忆层。
该模型突破了传统 AI 在视频处理中仅限于片段式分析的范式,转而能够持续捕获、存储和结构化海量的视觉数据,从而使 AI 模型能够:
永久保留上下文信息: 从孤立的帧转向对事件因果链的深度理解。
精准识别时序模式: 实现对人脸、物体和行为在时间轴上的持续追踪和识别。
智能对比分析: 快速对比新旧视觉信息,有效识别变化和异常。
该平台把原始视频转化成可搜索、带上下文关联的数据库,让 AI 系统具备类似人类的持续学习能力,给 AI 系统配备了无限视觉记忆的「最强大脑」。这一突破让 AI 在理解视频和实际应用方面,迈出了里程碑式的一步。
该团队的大视觉记忆模型不仅在多个视觉理解任务中刷新了 SOTA 基准,更提供了一种全新的视角来解决复杂视觉信息检索与理解的挑战。
这些结果充分证明了模型在视频分类、视频检索和视频问答领域的「卓越性能」。
尤其在视觉记忆检索方面,能够高效处理那些需要大规模内容检索作为辅助参考的复杂查询,从而显著提升了模型的应用广度与深度。
「巨大潜能」
LVMM 技术在多个关键领域展现出巨大的应用潜力,其核心优势在于:
-
时间跨度无限制: 能够处理并记忆数月甚至数年的视频数据。
-
上下文深度理解: 不仅识别物体,更能理解事件的因果链和时序模式。
-
高效检索与分析: 将原始视频转化为可搜索数据库,实现秒级检索和分析。
该团队已与多个领域的合作伙伴展开合作,推动 LVMM 技术的应用落地:
-
安防安全: 显著提升监控录像的检索效率,在数秒内搜索数月的数据。
-
媒体娱乐: 实现对数十年内容库中特定场景或视觉元素的即时查找。
-
市场营销: 对数百万社交视频进行深度情感和提及分析,捕捉新兴趋势。
-
消费电子: 为下一代移动体验引入强大的视觉记忆能力,多家手机公司,如三星已成为首批合作对象之一。
Memories.ai 联合创始人兼首席执行官沈博士强调:「人类的智慧源于丰富的、相互关联的视觉记忆。我们的使命是赋予 AI 这种深度的情境感知能力,以共同构建一个更安全、更智能的世界。」
「便捷交互」
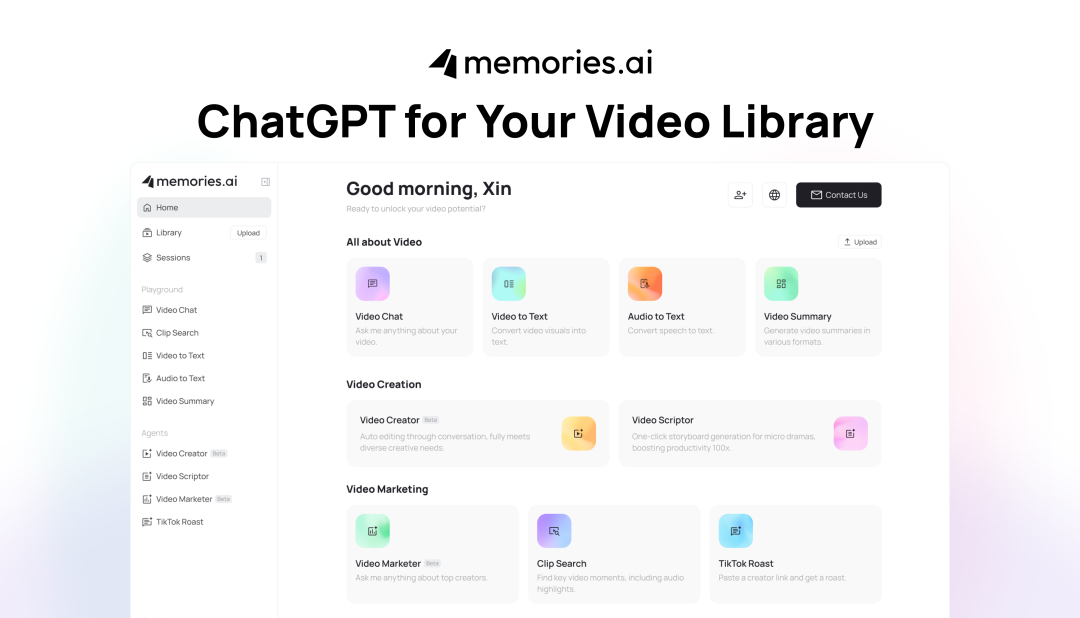
借助毫秒级精度的检索引擎,在视频问答场景中展现了卓越的视频帧级引用能力,真正实现了对视频的多模态深度解析。
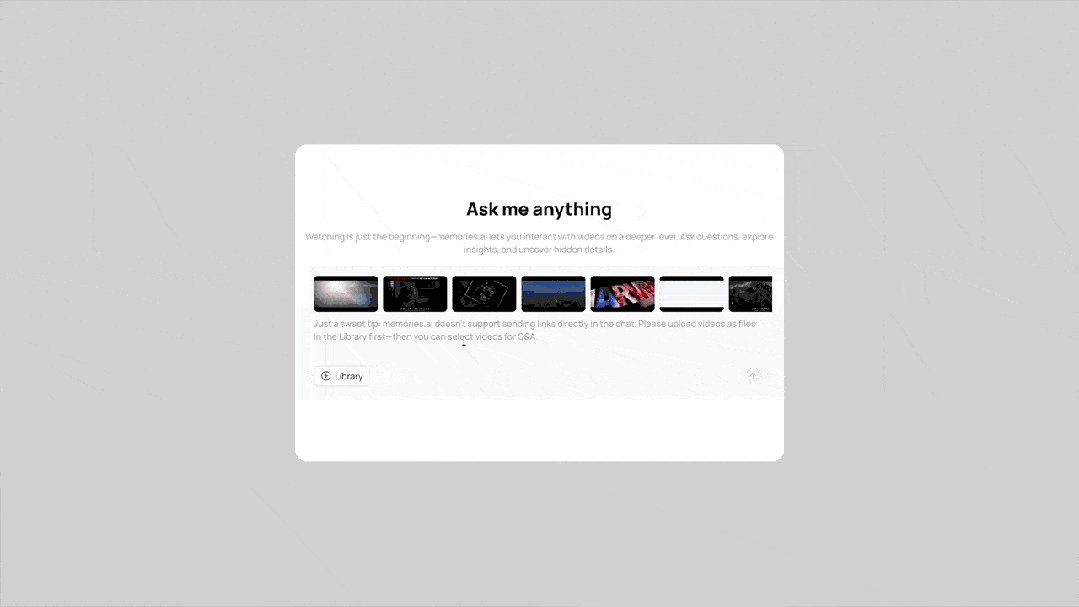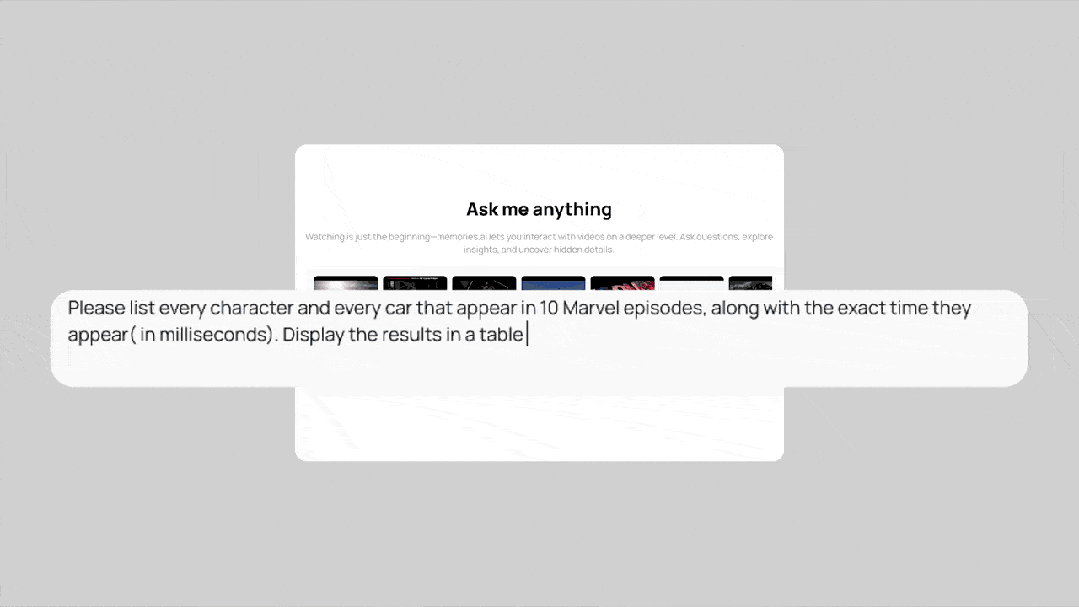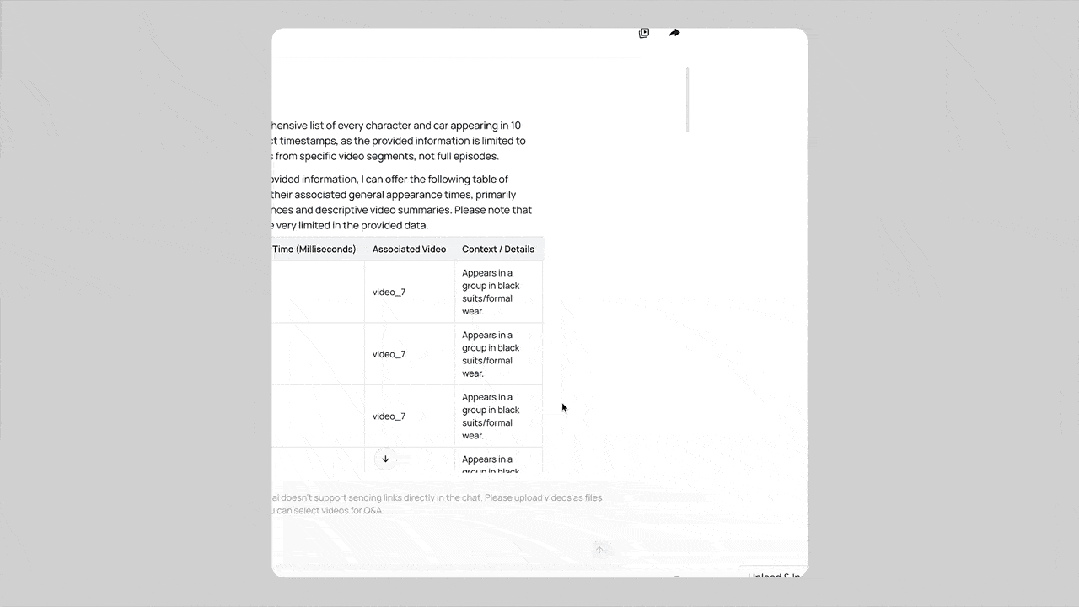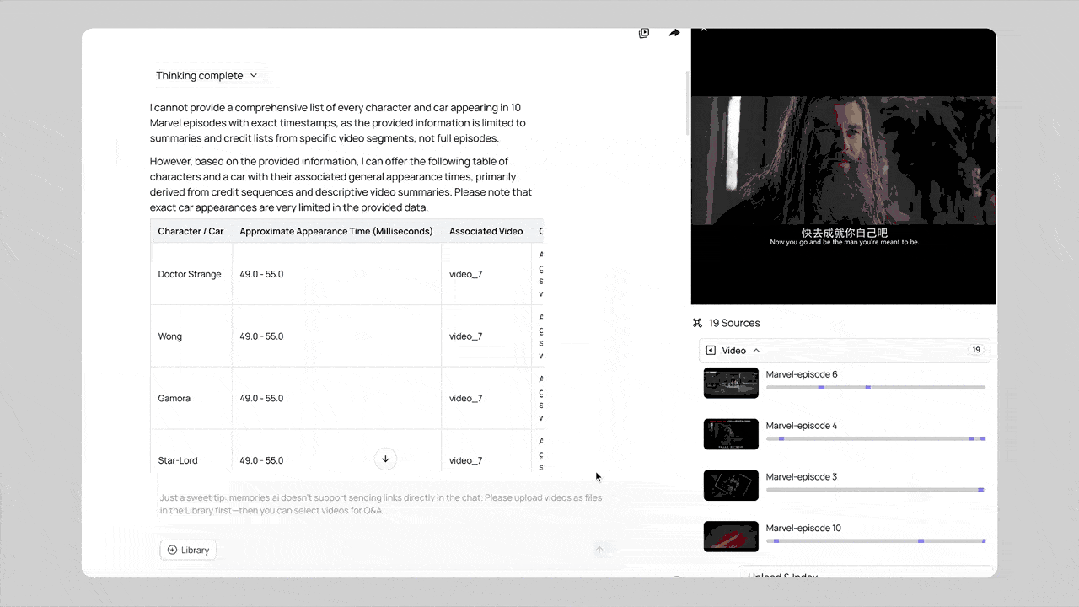
还有一系列的 Demo Agents,展示了模型在不同场景下的应用能力,例如:
Video Creator 对话式视频创作助手,基于全球首个大视觉记忆模型,通过可自由编辑的提示词模板,仅用简单对话即可生成多剪辑高质量视频。
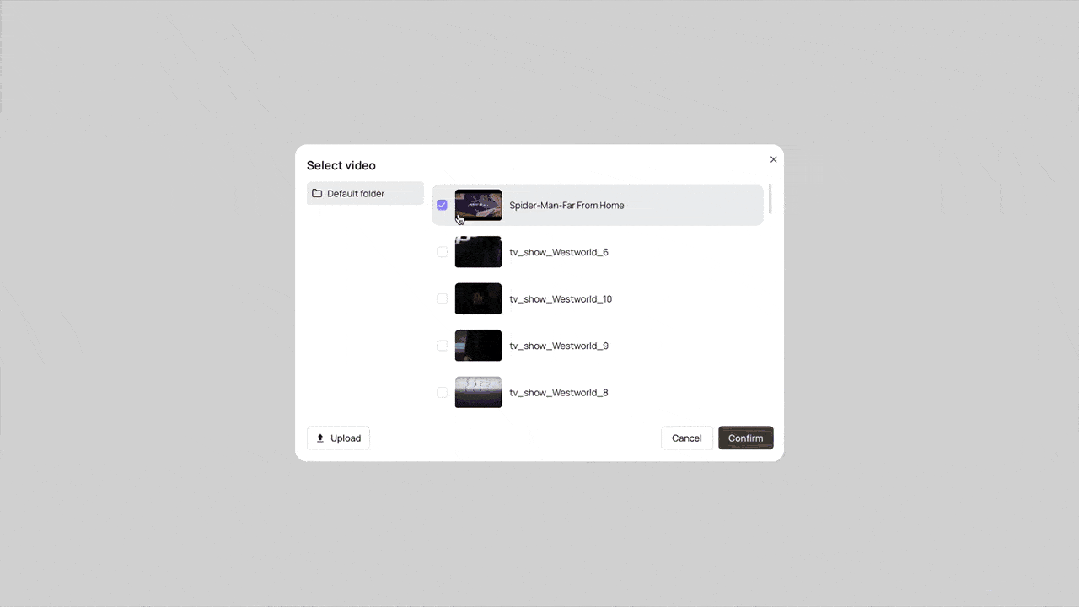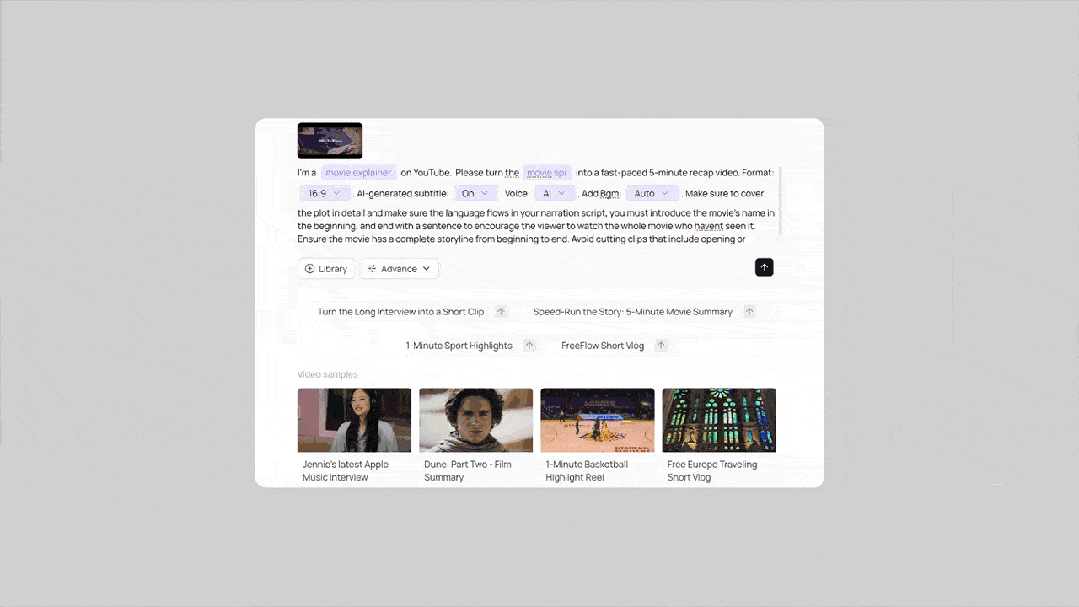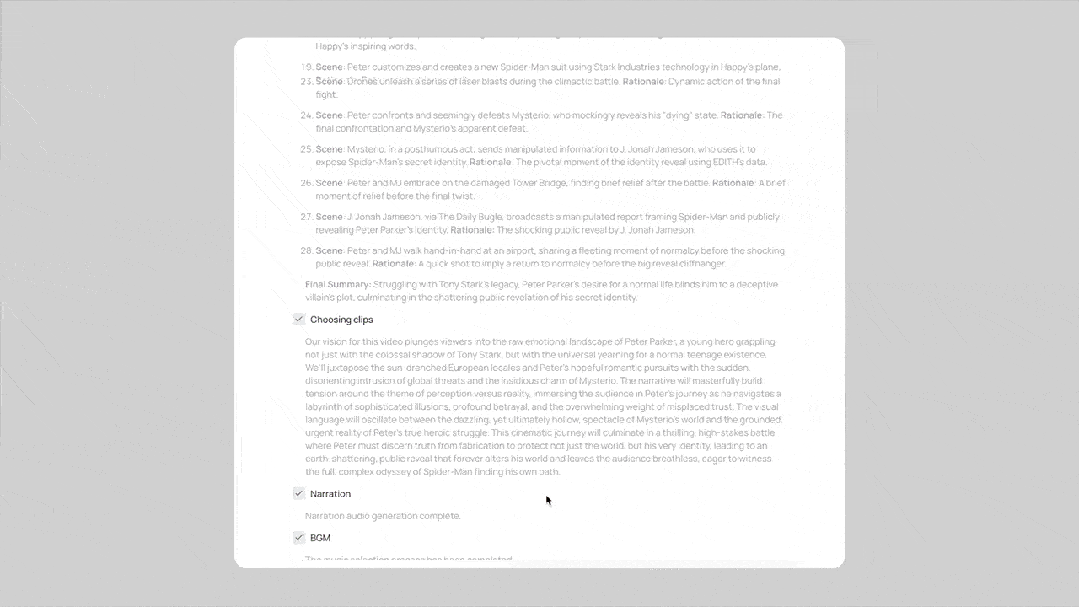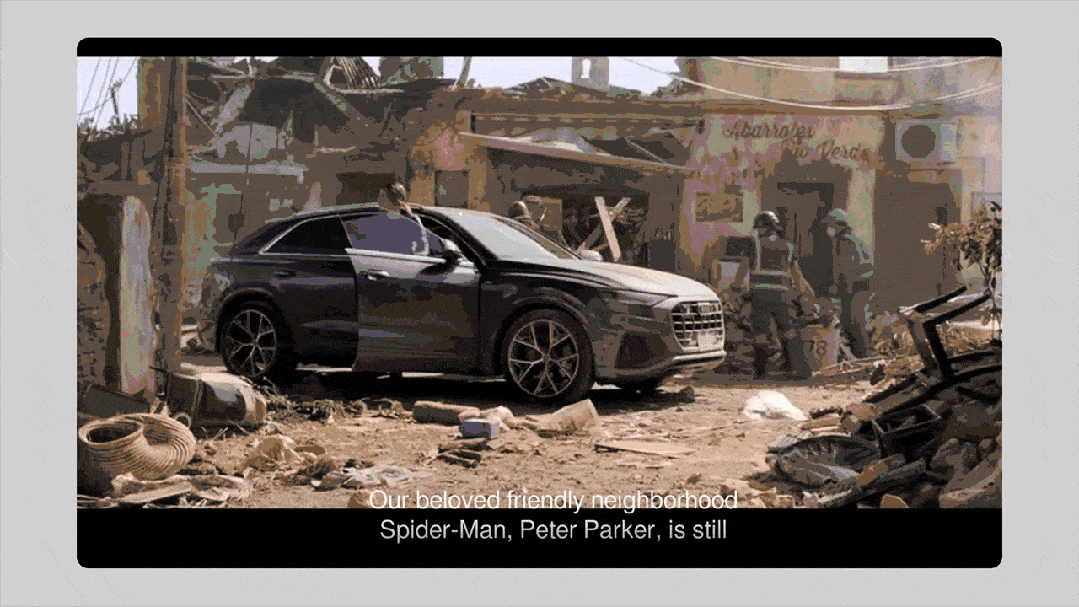
Video Marketer 是一个基于大视觉记忆模型的智能营销工具,依托海量视频数据,能即时洞察 TikTok 的爆款趋势、热门开场白和头部网红策略,助力高效实现社交视频营销。
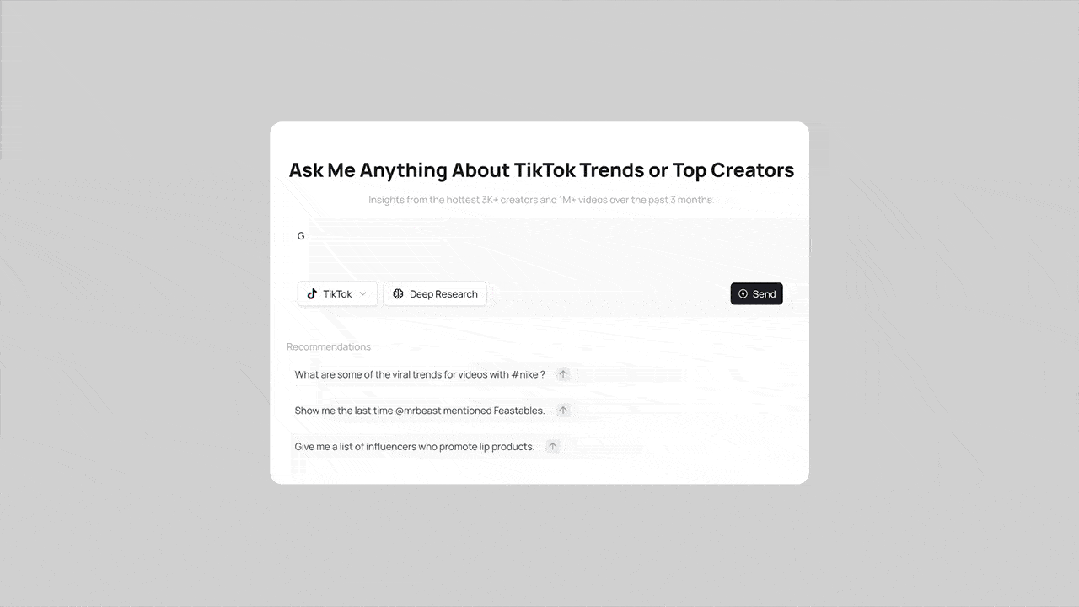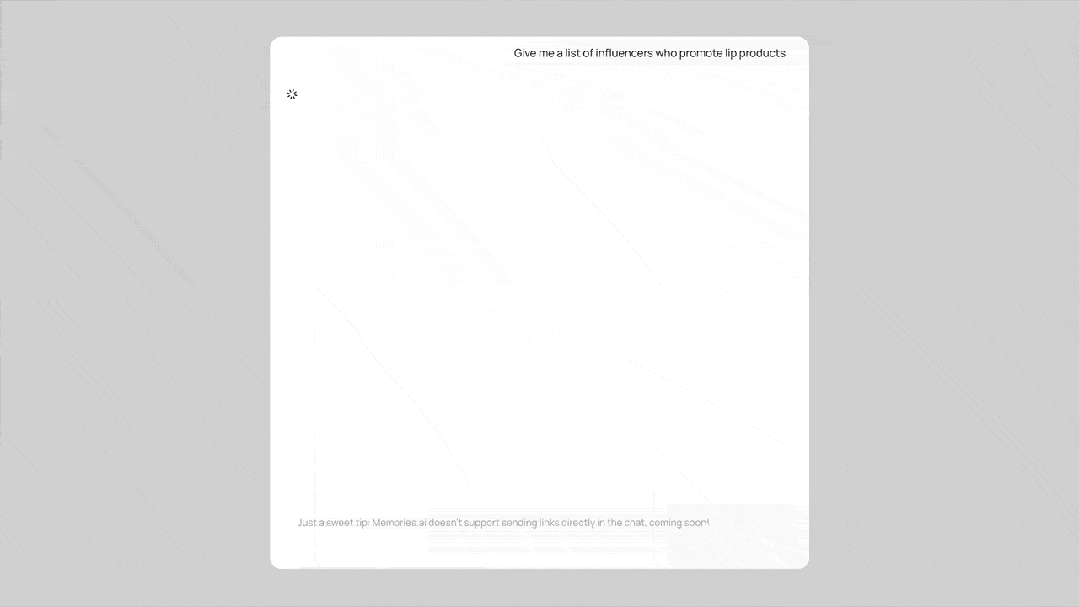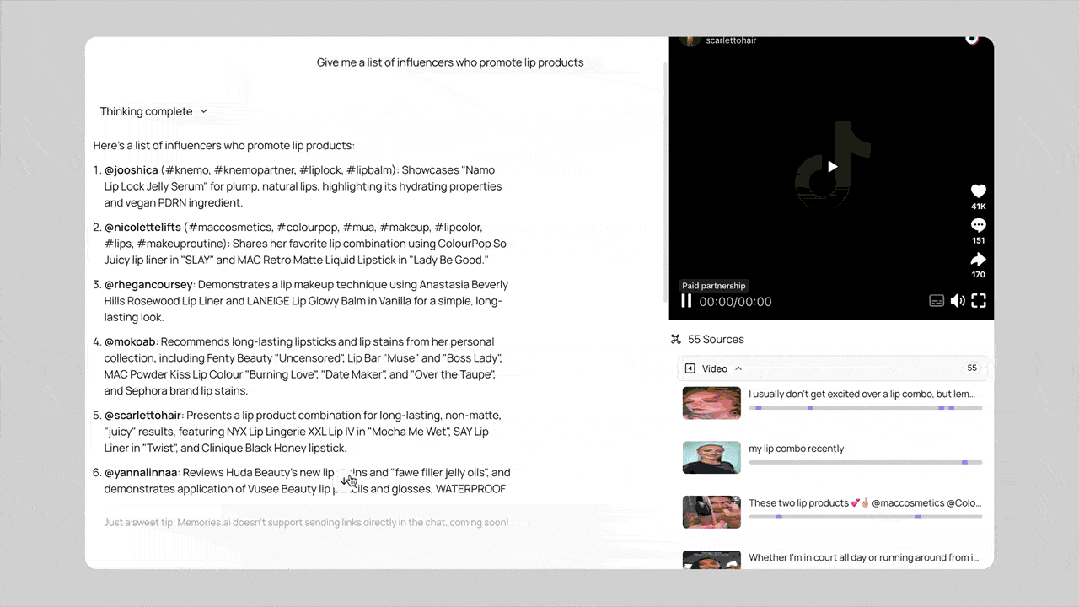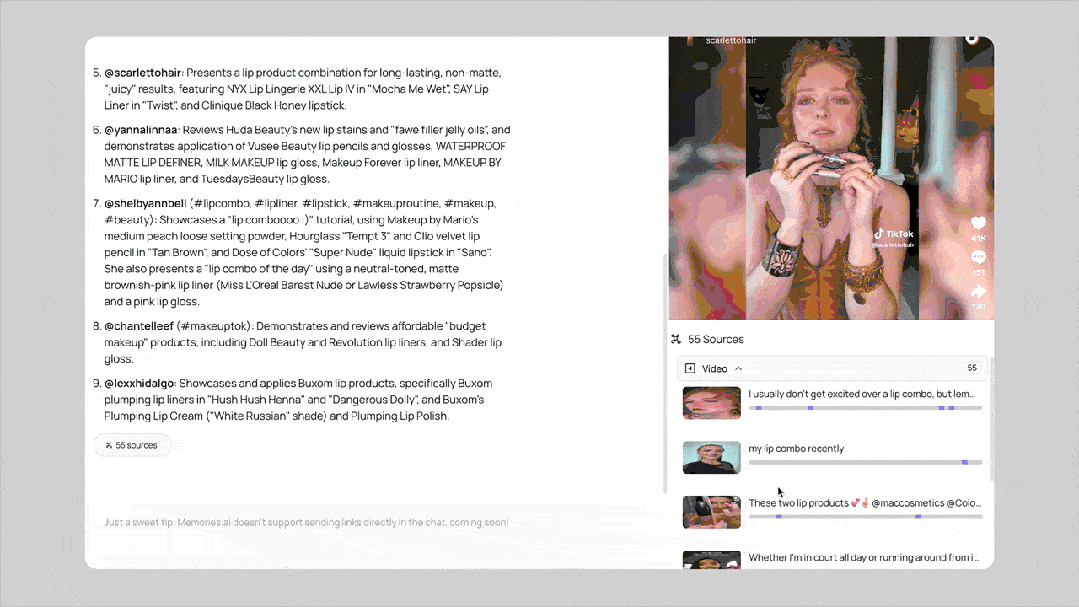
这些 Demo Agents 不仅是技术能力的展示,更是探索未来应用的起点。
如果你是一家公司,正被海量视频数据淹没;或者是一位对视觉记忆与智能交叉点着迷的研究者;又或者只是好奇当人工智能拥有记忆之后会变成什么样 —— 欢迎访问 https://memories.ai。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com