ICLR 2025论文InterpGN,通过门控网络平衡时间序列分类的性能与可解释性,为关键应用提供透明且高效的解决方案。
原文标题:ICLR 2025 | 改进 Shapelet Transforms 构建可解释的时序分类门控网络
原文作者:数据派THU
冷月清谈:
InterpGN的核心创新在于其独特的门控函数设计。该框架引入了基于可解释专家置信度的门控机制,使得模型在可解释特性显著的样本上保持透明度,同时能自动识别并调度需要深度神经网络处理的复杂样本。这种动态分配策略有效地兼顾了效率与洞察力。
针对时间序列数据的特性,InterpGN采用了Shapelets作为其可解释专家模块。研究者进一步提出了**改进版的Shapelets Transforms算法,用于生成基于Shapelets的逻辑谓词**。通过使用径向基函数(RBF)而非传统的阈值,该方法能够将Shapelets与时间序列子序列的欧几里得距离转化为存在Shapelets的概率,显著提升了Shapelets的质量与可解释性。
在实验层面,InterpGN在多个基准数据集上展现出与前沿深度学习模型相当的性能,并且能为分类结果提供清晰的可解释性。定量评估表明,相比现有Shapelets学习方案,InterpGN在Shapelets质量和可解释性指标上均有显著提升。此外,该框架的通用性也得到了验证,可兼容多种先进网络架构,并成功应用于MIMIC-III医疗数据集和时间序列外源回归等真实世界任务中,有效突破了标准基准测试的局限。**这为医疗保健等对模型透明度要求极高的领域提供了可靠的解决方案。**
尽管InterpGN取得了显著进展,研究者也坦诚存在局限性,例如某些Shapelets可能未完全捕捉到数据本质趋势,且当前模型设计相对简单,未来可探索引入更多专家模块进行扩展。
怜星夜思:
2、InterpGN改进了Shapelet Transforms,提高了Shapelets的质量和可解释性。但文章也提到,现有Shapelets仍有局限性,比如“可能并不捕捉到动作的本质趋势”。你认为在未来,除了对Shapelets本身的改进,还有哪些可能的方法或技术可以帮助我们更好地从时间序列数据中提取“人类可理解的特征”,以进一步提升模型的可解释性?
3、InterpGN采用的“混合专家(MoE)”架构,即结合可解释模型和深度神经网络,本质上是一种灵活应对复杂任务的策略。在更广泛的AI应用场景中,如何有效地设计和训练这种多模型、多目标(如性能、可解释性、鲁棒性、效率等)的混合专家系统?你认为未来AI的发展会更趋向于这种“全能型选手团队”还是“精细化专业分工”?
原文内容

本文约3500字,建议阅读5分钟本文所提模型显著提升了 shapelets 质量与可解释性指标。
在时间序列分类任务中,可解释模型虽能提供额外洞见,但其性能往往被深度学习模型超越,这是因为人类可理解的特征在表达能力和灵活性上存在局限。本文介绍一篇 ICLR 2025 中接收的工作,该工作研究者提出了 InterpGN 框架,通过融合可解释模型与深度神经网络实现优势互补。该框架创新性地设计了基于可解释专家置信度的门控函数:当可解释特征显著时保持模型透明度,同时自动识别需要深度网络处理的复杂样本。针对时间序列数据特性,采用 shapelets 构建可解释专家模块,并提出改进版 Shapelets Transforms 算法来生成基于 shapelets 的逻辑谓词。
实验表明,该模型在保持与前沿深度学习相当性能的同时,能为多个基准数据集提供可解释分类器。定量评估显示,相比现有 shapelets 学习方案,本文所提模型显著提升了 shapelets 质量与可解释性指标。最后,验证了该框架可兼容先进网络架构,并能拓展应用于 MIMIC-III 医疗数据集和时间序列外源回归等现实场景任务,突破标准基准测试的局限。

【论文标题】
Shedding Light on Time Series Classification using Interpretability Gated Networks
【论文地址】
https://openreview.net/forum?id=n34taxF0TC
【论文代码】
https://github.com/YunshiWen/InterpretGatedNetwork
论文背景
-
提出了一种新颖的门控函数,根据可解释专家的置信度将样本分配给相应的专家。
-
提出了一种基于形状片段的 Shapelet Transforms 变体,与现有的基于 shapelet 的方法相比,提高了可解释性。
-
提出了用于评估可解释性和 shapelets 质量的量化指标,并证明了模型在这些指标上优于现有的 shapelets 学习方法。
-
在UEA多变量时间序列分类档案中的多个基准数据集上,InterpGN 的性能优于现有的最先进的方法,并且在 MIMIC-III 等真实世界任务上展示了模型的可解释性。
混合专家框架InterpGN
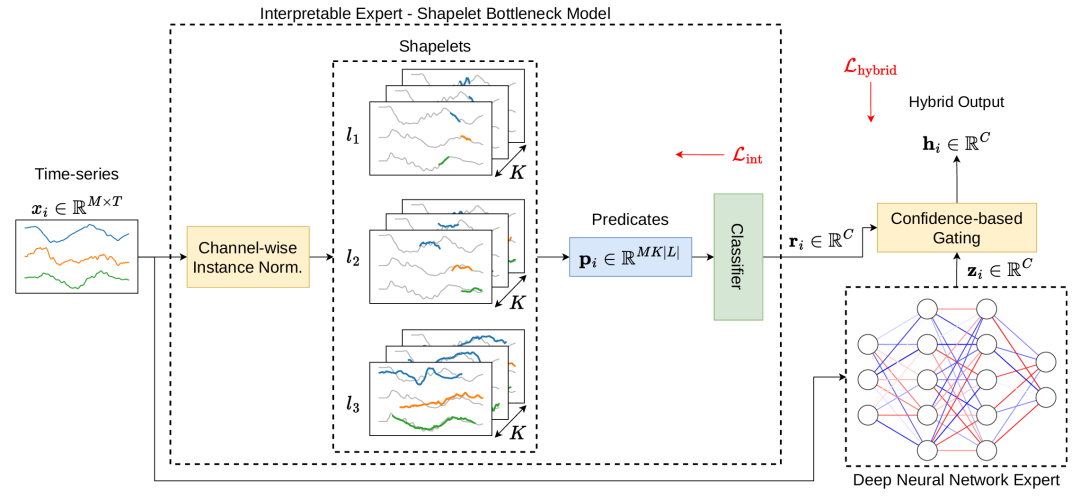
01 使用 Shapelets 构建逻辑谓词
研究者提出了一种基于 shapelets 距离构建逻辑谓词的新方法。与传统的基于阈值距离的方法相比,他们引入了一种基于径向基函数(RBF)的方法,使用高斯核函数来衡量 shapelets 在时间序列中出现的可能性。这种方法通过将 shapelets 与时间序列的子序列之间的欧几里得距离转换为存在 shapelets 的概率,从而提高了 shapelets 的质量和可解释性。
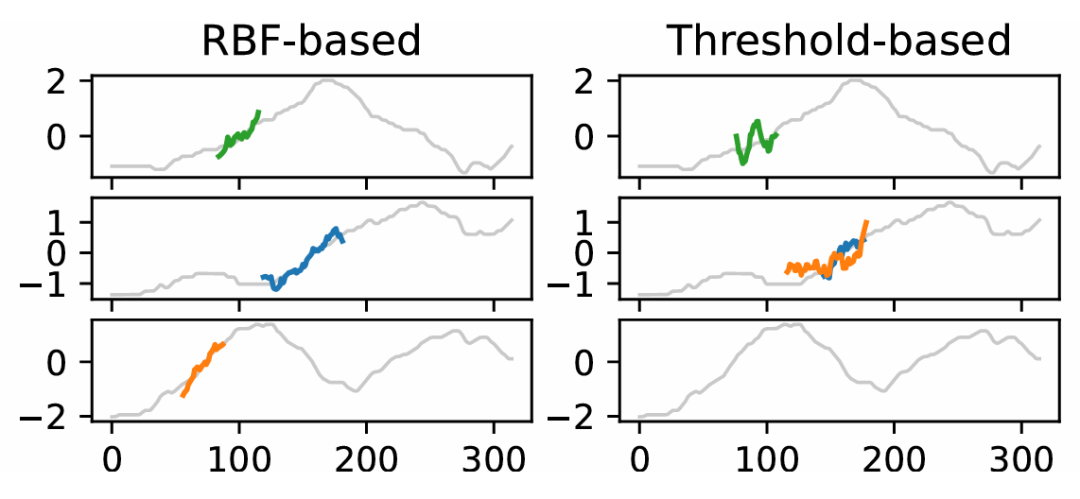
图3:基于RBF的谓词(左)与基于阈值的谓词(右)所学习到的shapelet对比。
02 形状片段瓶颈模型 - 可解释专家
形状片段瓶颈模型(SBM)是 InterpGN 中的可解释专家部分。它接收由 shapelets 变换生成的逻辑谓词作为输入,并通过一个线性层来计算输出结果。
SBM 的训练是端到端可微分的,并使用基于梯度的优化方法进行训练。训练目标函数包括分类损失(softmax 交叉熵损失)、shapelets 多样性损失(用于调节冗余 shapelets 的学习)和线性分类器权重的 L1 正则化(以鼓励稀疏性,选择最有信息量的概念,并产生简单的分类器)。
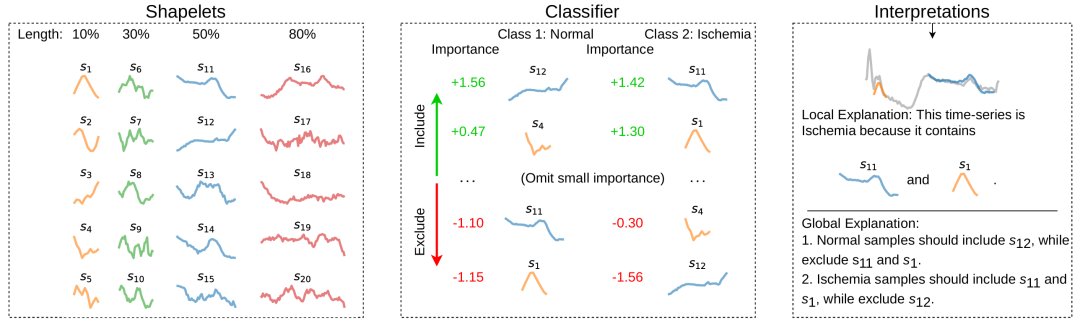
03 解释
SBM 提供了两种解释方式:局部可解释性和全局可解释性。局部解释回答了为什么对某个样本进行特定分类决策的原因,例如某个样本属于某个类别是因为它包含了特定的 shapelet。全局解释则提供了关于分类问题的知识,以归纳逻辑的形式表达,例如某个类别的样本应该包含或不包含特定的 shapelet。这些解释方式使得模型的决策过程更加透明,有助于用户理解和信任模型。
04 混合专家门控
为了克服 shapelets 瓶颈在某些情况下表达能力不足的问题,研究者采用了混合专家(MoE)方法来构建部分可解释的混合模型。在 InterpGN 中,可解释专家本身作为门控网络,根据其对样本的置信度来分配工作给专家。研究者设计了一个基于可解释专家置信度的门控函数,该函数通过修改的基尼指数来衡量可解释专家输出的多样性。在训练过程中,混合模型的输出是可解释专家和 DNN 输出的混合,而在推理过程中,如果可解释专家的置信度高,则仅激活 SBM 并丢弃 DNN,以最大化样本的可解释性。
05 InterpGN的训练
InterpGN 框架的总体目标是最小化混合损失函数,该函数包括可解释专家的损失函数和混合模型的交叉熵损失。可解释专家的权重 β 可以是一个常数超参数,也可以按照余弦退火计划进行调整。这种设计确保了 SBM 在训练过程中被积极鼓励寻找有意义的 shapelet ,从而防止 InterpGN 退化为纯 DNN 模型。整个混合模型仍然是端到端可微分的,并使用基于梯度的优化方法进行训练。
实验结果
01 多变量时间序列分类
研究者在 UEA 多变量时间序列分类档案中的 30 个数据集上评估了 InterpGN 的性能,并与其他基线方法进行了比较。实验结果表明,InterpGN在平均准确率、平均排名、获得第一名和前三名的数据集数量等方面均优于基线方法。具体来说,InterpGN 在30个数据集上的平均准确率为0.760,平均排名为3.500,获得第一名的数据集数量为8个,获得前三名的数据集数量为16个。
此外,文中还展示了 SBM 在多变量时间序列数据集上学到的 shapelet 的可视化,验证了模型能够捕捉到区分性的 shapelet 特征。

表1:UEA档案库30个数据集的分类准确率对比
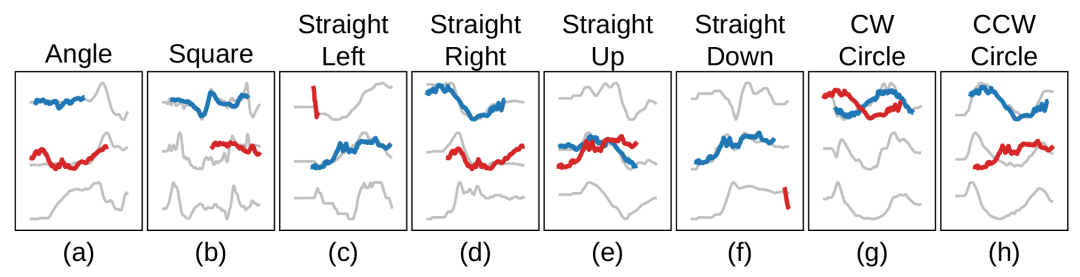
图4:UEA档案库UGL数据集中八种手势加速度计读数的可视化
02 预测院内死亡率
研究者使用 MIMIC-III 数据集对 InterpGN 进行了评估,以预测患者在进入重症监护病房后48小时内的院内死亡率。实验结果表明,InterpGN 在准确率、F1分数、召回率、精确度和 ROC-AUC 等指标上均优于或接近其他方法。具体来说,InterpGN 的准确率为0.703,F1分数为0.657,召回率为0.569,精确度为0.784,ROC-AUC 为0.703。
此外,研究者还提供了 SBM 对两个样本的局部解释示例,展示了模型如何根据患者的生命体征数据(如心率、平均血压和氧饱和度)中的 shapelet 来判断患者的生存情况。这些解释为临床应用提供了有价值的见解。
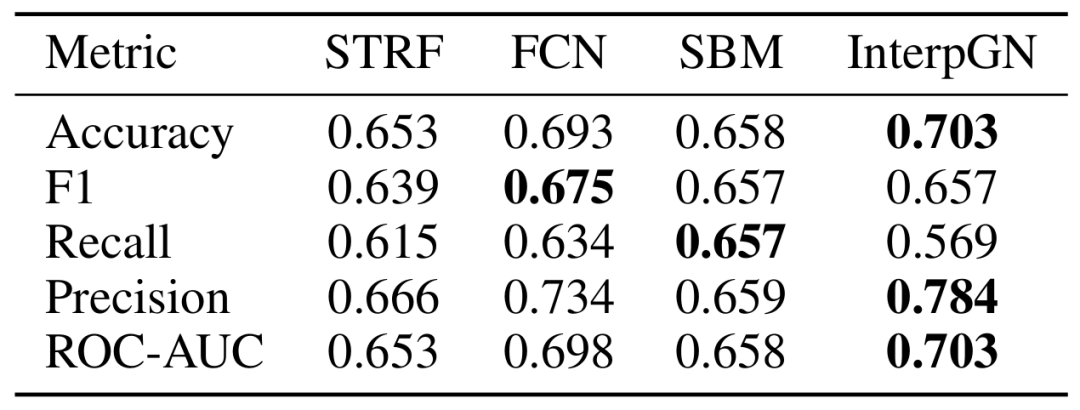
表2:MIMIC-III数据集院内死亡率预测结果
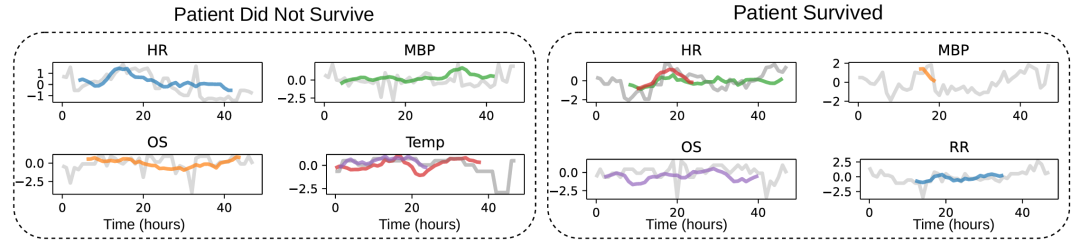
图:5:基于SBM的院内死亡率预测局部解释模型可视化
03 超参数对可解释性和shapelets质量的影响
研究者通过一系列的消融研究,分析了超参数对分类准确率、可解释性、shapelets 质量和可解释专家效用的影响。研究结果表明,shapelets 的数量K、损失权重 β 的调度方式、谓词类型、RBF 核函数的陡峭程度ϵ、权重正则化 λreg 和 shapelets 多样性正则化 λdiv 等因素都会对模型的性能产生不同程度的影响。
例如,增加 K 可以提高模型的表达能力和 shapelets 质量,但对可解释性的影响并不明确;使用余弦调度的 β 可以使模型在训练过程中更加关注可解释专家在样本上有用的情况,从而提高 shapelets 质量和可解释性;RBF 谓词在准确率、shapelets 质量和可解释性方面均优于线性谓词等。
04 扩展实验
研究者还进行了一些扩展实验,包括尝试不同的 DNN 专家架构(如 FCN、Transformer、PatchTST 和 TimesNet)、不同的 shapelet 距离度量(如余弦相似度和皮尔逊相关性)以及不同的 SBM 分类器架构(如双线性分类器和基于注意力的分类器)。
实验结果表明,这些变体在某些数据集上有时能够获得更好的性能,但并不具有普遍性。此外,研究者还对 SBM 学到的 shapelets 的保真度进行了评估,发现大多数数据集上的保真度都很高,表明学到的 shapelets 与预测之间存在正相关关系。最后,研究者将 InterpGN 应用于时间序列外在回归任务,并使用连续排序概率分数(CRPS)作为性能指标,初步验证了模型在回归任务上的可行性。
总结
本文提出了一种新颖的时间序列分类方法 InterpGN,该方法通过引入可解释性门控网络,在可解释性和性能之间取得了平衡。
然而,研究者认为该研究仍然存在一些局限性。首先,在某些分类规则中,某个类别的最重要 shapelet 可能并不类似于该类别的实际时间序列子序列。例如,图4(a)中的蓝色 shapelet 可能并不捕捉到 “Angle” 动作的本质趋势,但它仍然可以通过不包含其他类别的关键 shapelet 来正确分类。其次,本文研究的是一种简单的设计,其中包括一个可解释专家和一个 DNN。类似于 MoE 框架,InterpGN 可以通过引入更多专家来扩展。例如,可以使用分层门控方法包含多个可解释模型,同时使用原始 MoE 方法结合多个 DNN 模型。
编辑:王菁

