UV-CoT:无监督视觉思维链推理新框架。摆脱人工标注依赖,通过偏好优化实现图像级细粒度推理,显著提升视觉模型能力。
原文标题:ICCV 2025|UV-CoT:无监督视觉推理新突破,偏好优化重塑图像级思维链
原文作者:机器之心
冷月清谈:
为应对这些挑战,近期ICCV 2025录用的一篇论文提出了一种创新的无监督视觉思维链推理框架——UV-CoT(Unsupervised Visual Chain-of-Thought)。该方法借鉴人类“关键区域→推理过程”的视觉理解模式,旨在实现模型的动态区域聚焦与细粒度推理。
UV-CoT的核心创新在于其无监督的数据生成与偏好优化机制。它通过一套自动化流程,首先利用目标模型为图像-问题对生成多样化的中间推理响应,这些响应包含关键的边界框信息和推理结果。随后,一个评估模型综合衡量所选区域得分及对后续回答的影响,对这些响应进行评分。基于这些评分,UV-CoT能够自动构建偏好对数据集,从而在无需人工标注的条件下,自我学习并优化推理路径。
此外,UV-CoT引入了改进的直接偏好优化算法——sDPO(Score-DPO)。sDPO通过引入偏好分数差异,量化偏好响应与非偏好响应之间的强度,有效增强了模型对关键图像区域的影响建模能力。该框架还采用迭代学习策略,通过动态更新偏好数据来适应模型输出分布,显著提升了训练的鲁棒性。
实验结果表明,UV-CoT在多个视觉基准测试上性能显著,不仅超越了有监督的思维链模型,还展现出更强的泛化能力,并能胜任高分辨率场景下的推理任务。
值得一提的是,即使在不依赖外部评估模型,仅通过自评估的情况下,UV-CoT也能生成高质量的边界框,其性能接近甚至超越更大的有监督模型。
总体而言,UV-CoT为高效、可扩展的多模态推理提供了一种新思路,成功摆脱了对昂贵人工标注的依赖,为未来无监督视觉理解研究奠定了坚实的基础。
怜星夜思:
2、文章里提到UV-CoT能动态聚焦关键区域,这听起来很酷。那在OCR(光学字符识别)或者其他需要极高精度定位的任务中,这种动态聚焦在处理复杂、密集排布的文字或图案时,会不会遇到精度瓶颈或者遗漏部分信息的情况?
3、UV-CoT用了“偏好优化”这个词,它听起来有点像强化学习里的人类反馈机制(RLHF),但这里是机器自己生成反馈。这种“自我偏好”的机制,未来有没有可能被滥用,或者被恶意数据投喂,导致模型产生一些意想不到的,甚至是有偏见的推理?
原文内容

本文第一作者是来自南洋理工大学的博士生赵克森,主要研究方向为 Reinforcement Learning in MLLMs. 该论文已被 ICCV 2025 录用。
随着文本领域中思维链(Chain-of-Thought,CoT)推理机制的成功应用,研究者开始将该方法引入视觉理解任务,以提升模型的推理能力和可解释性。
然而,现有模型局限于文本级别的思维链推理,且处理图像的粒度固定,难以根据语义线索动态关注图像中的关键区域。针对上述问题,本文提出 UV-CoT(Unsupervised Visual Chain-of-Thought),一种无监督视觉思维链推理新框架。
该方法以「关键区域→推理过程」的人类视觉理解方式为参考(如下图所示),设计了无监督的数据生成与偏好优化机制,动态聚焦关键区域,实现细粒度推理,显著提升了模型的空间感知与图文推理能力。
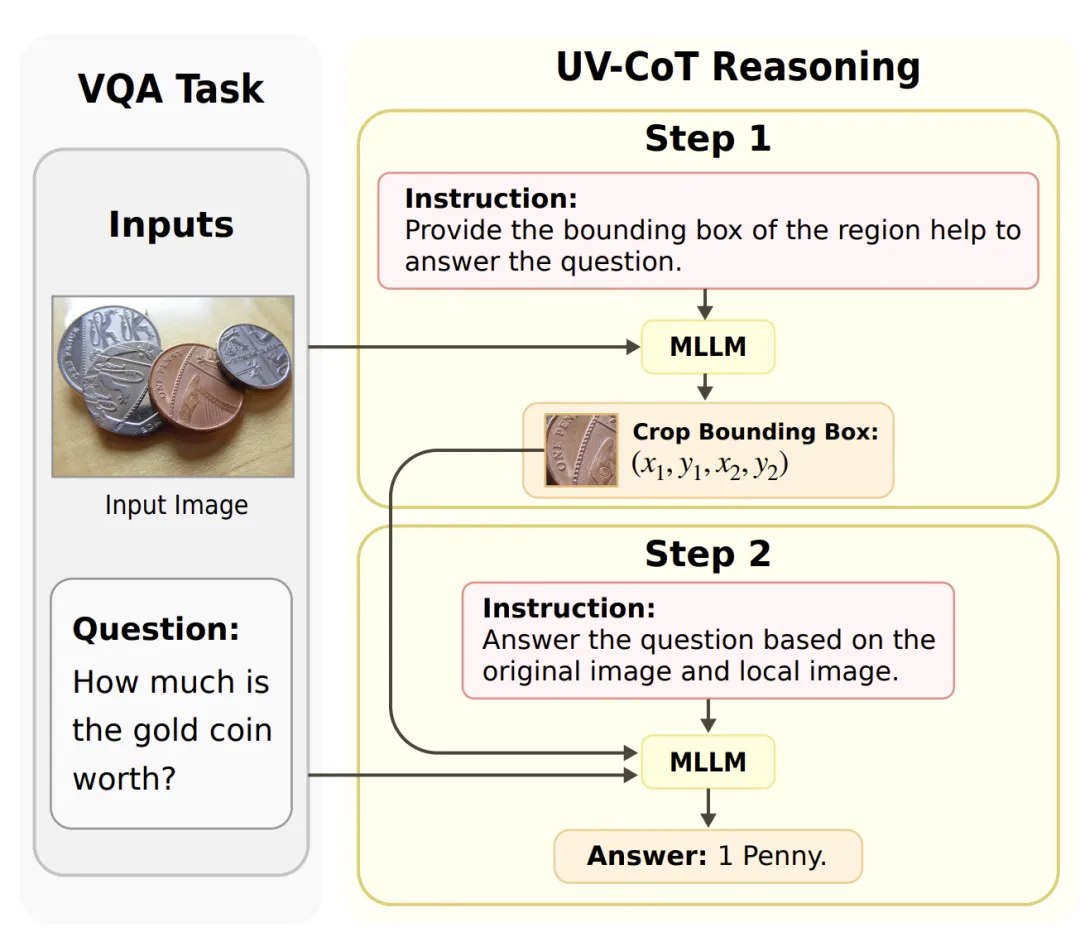

-
论文标题:Unsupervised Visual Chain-of-Thought Reasoning via Preference Optimization
-
论文链接:https://arxiv.org/abs/2504.18397
-
项目地址:https://kesenzhao.github.io/my_project/projects/UV-CoT.html
-
代码仓库:https://github.com/kesenzhao/UV-CoT
-
开源模型: https://huggingface.co/papers/2504.18397
背景:有监督训练
需要高昂的人工成本
现有方法采用有监督微调(Supervised Fine-Tuning, SFT)策略训练模型,使用大量有标签的思维链推理数据,由人工标注关键区域及其推理过程。这类方法面临以下挑战:
(1)人工标注成本高,扩展性差:标注关键图像区域和推理路径需要耗费大量人力和时间,尤其在复杂视觉语义理解任务中,难以适应多任务或大规模场景。
(2)训练信号单一,泛化能力有限: SFT 仅利用人工标注的「正样本」(正确区域及回答),忽略其他潜在合理或不合理的区域与推理路径,导致模型在未知场景下的泛化能力不足。
UV-CoT 设计了一套自动化的偏好数据生成与评估流程,结合改进的偏好优化算法 Score-DPO(sDPO),在不依赖人工标注的前提下,通过偏好评分排序引导模型实现无监督图像级思维链学习(如下图所示)。
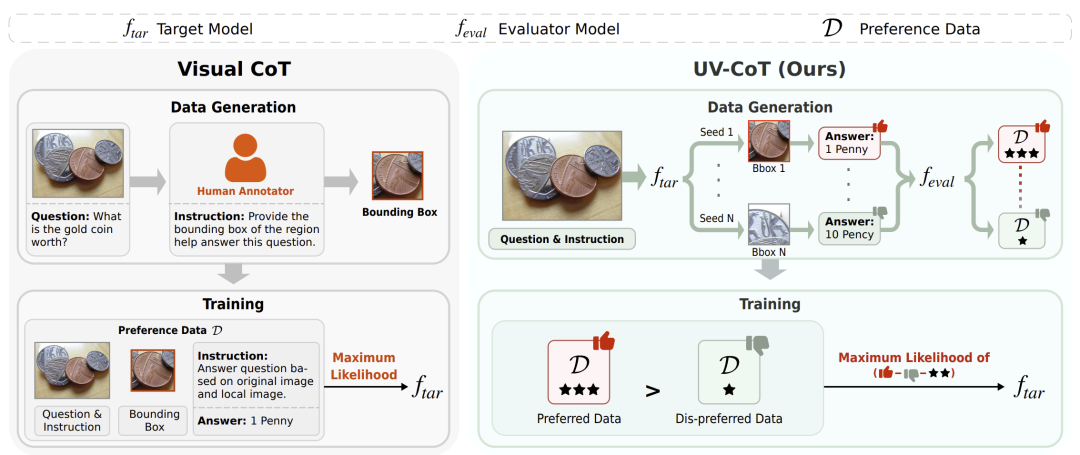
贡献一:无监督偏好数据生成与评估
UV-CoT 利用目标模型 和评估模型
和评估模型![]() ,为图像 - 问题对生成多样化的中间推理响应,并通过偏好评分构建偏好数据集。主要步骤如算法 1 所述:
,为图像 - 问题对生成多样化的中间推理响应,并通过偏好评分构建偏好数据集。主要步骤如算法 1 所述:
-
响应生成:在每个推理时间步 t,使用目标模型
通过随机种子生成 n 个多样化的响应(包括边界框和中间推理结果)。 -
响应评估:评估模型
 综合考虑所选区域的得分
综合考虑所选区域的得分 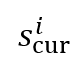 及对后续回答的影响
及对后续回答的影响 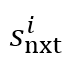 。
。
-
偏好对构建:从响应中随机选择 k 个偏好对(偏好和非偏好思维链),形成偏好数据集。
-
响应选择:保留最高评分的响应链,用于下一时间步的推理。
通过动态生成偏好数据,UV-CoT 减少了对高质量标注数据的依赖,能够在无监督数据条件下实现图像级思维链推理。

贡献二: sDPO 与迭代学习
UV-CoT 使用改进的直接偏好优化(DPO)算法 sDPO,通过引入偏好分数差异优化图像级思维链推理,并采用迭代学习策略动态适应模型输出分布。
sDPO 损失函数如下:
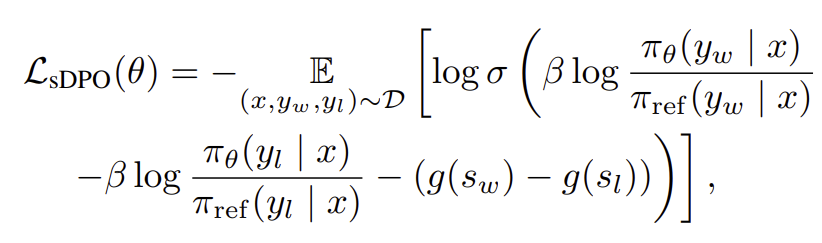
相比标准 DPO,sDPO 通过 ![]() 引入偏好分数的差异,量化偏好和非偏好响应之间的强度,提升对关键图像区域的影响建模。
引入偏好分数的差异,量化偏好和非偏好响应之间的强度,提升对关键图像区域的影响建模。
迭代学习 (如算法 2):将数据集分为 m 个子集,迭代 m 次,每次使用当前模型![]() 生成偏好数据 D_i,并用 sDPO 优化得到下一模型
生成偏好数据 D_i,并用 sDPO 优化得到下一模型 ![]() 。 通过动态更新偏好数据,缓解训练数据与模型生成分布的差异,增强训练鲁棒性。
。 通过动态更新偏好数据,缓解训练数据与模型生成分布的差异,增强训练鲁棒性。
实验亮点
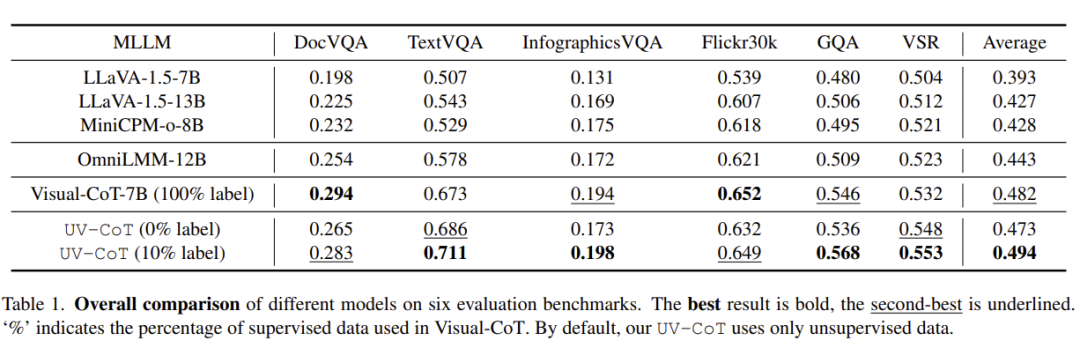
显著性能提升(表 1):在六大基准上,优于有监督的思维链模型 Visual-CoT-7B,远超目标模型 LLaVA-1.5-7B 和其他无思维链模型。
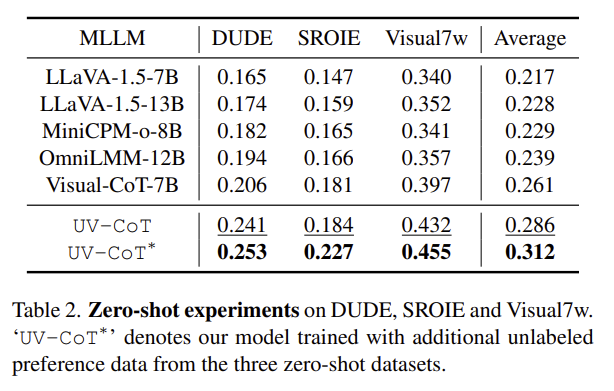
泛化能力强,易于拓展(表 2):在零样本设置下,UV-CoT 平均提升 2.5%,添加额外无标注数据后,平均提升达 5.1%。
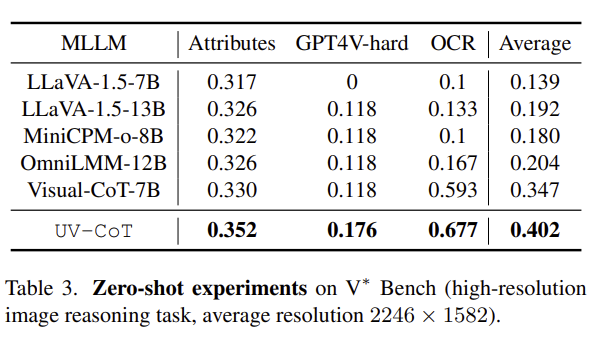
胜任高分辨率场景(表 3):在 V* Bench 上,UV-CoT 平均得分 0.402,平均提升 5.5%,尤其在 OCR 任务中提升 8.4%。
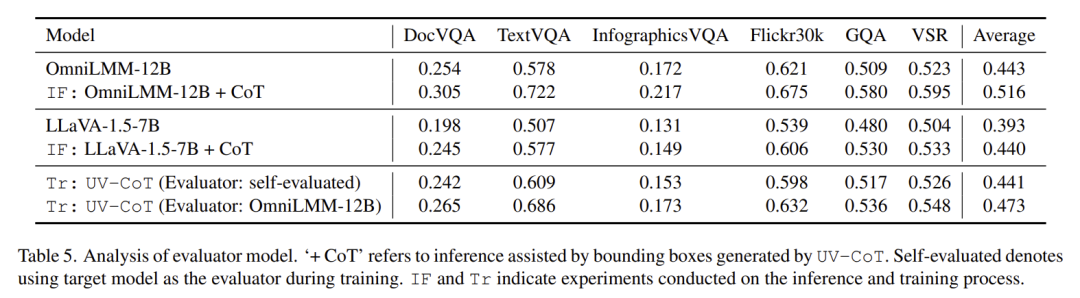
不依赖评估模型,边界框生成质量高(表 5):UV-CoT 通过自评估(目标模型作为评估器)表现仍远超目标模型 LLaVA-1.5-7B(+4.8%),接近 12B 模型 OmniLMM-12B(-0.2%)。将 UV-CoT 生成的边界框应用于 OmniLMM-12B 和 LLaVA-1.5-7B 辅助推理,性能分别提升 7.3% 和 4.7%。
偏好数据与思维链推理可视化:


结语
UV-CoT 提出了一种创新的无监督视觉思维链推理框架,通过自动化的数据生成与对比评估机制,成功摆脱了对人工标注的依赖,实现了关键图像区域的自动识别与推理优化。该方法为高效、可扩展的多模态推理提供了新思路,为未来无监督视觉理解研究奠定了坚实基础。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:[email protected]