GHPO算法融合强化学习与模仿学习优势,显著提升大模型推理训练效率与稳定性,在多项数学基准测试中表现卓越。
原文标题:首次结合RL与SFT各自优势,动态引导模型实现推理?效训练
原文作者:机器之心
冷月清谈:
GHPO的核心创新在于,它利用了标准解题过程作为监督信号,有效地缓解了奖励稀疏问题。此外,该框架的另一个关键特性是引导式混合策略优化(GHPO),它包含两个核心模块:自动化难度检测和自适应提示切换。自动化难度检测模块能根据样本解答分布评估问题难度,无需外部辅助。自适应提示切换模块则依据检测到的难度,动态调整标准解题路径提示的比例,确保模型在需要时才获得指导,同时保留探索空间。
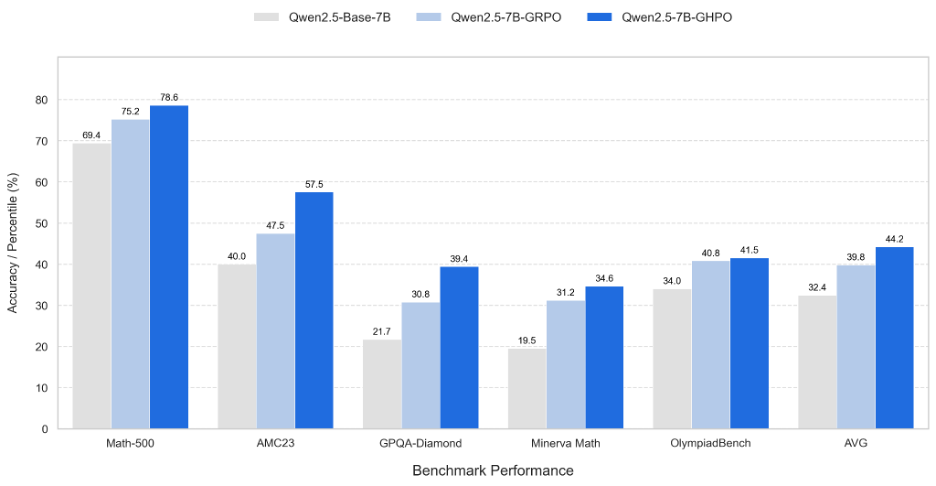
实验结果表明,GHPO在多个开源数学推理基准测试中表现卓越,相较于GRPO平均性能提升4.5%,尤其在GPQA-Diamond和AMC23上分别提升了9%和10%。它不仅显著提升了端侧模型的样本利用效率,还带来了更加稳定的梯度更新,并被证明适用于不同难度分布的数据集和多种模型类别。GHPO的推出为强化学习与监督微调的深度融合提供了新的视角,有望推动大模型后训练技术发展,助力AI探索。
怜星夜思:
2、GHPO解决奖励稀疏用了模仿学习,这招挺巧妙的。但现实中很多复杂场景,奖励信号还是很难给。除了模仿学习,大家还知道哪些办法可以解决大模型训练时奖励太“稀疏”这个问题?
3、文章里提到了GHPO对“端侧小模型”特别有用。那大家觉得,这种能让AI模型训练更有效率的技术,会不会大大加速我们手机、智能设备上AI功能的普及?具体能带来什么变化?
原文内容

刘子儒博士毕业于香港城市大学数据科学专业,导师为赵翔宇教授及数学家周定轩教授。目前就职于华为香港研究所小艺团队,负责 RLVR 算法与扩散语言模型方向的研究。龚成目前在香港城市大学攻读博士学位,导师为张青富教授。期间在华为香港研究所小艺团队进行研究实习,负责RLVR算法方向的研究。
新一代大型推理模型,如 OpenAI-o3、DeepSeek-R1 和 Kimi-1.5,在复杂推理方面取得了显著进展。该方向核心是一种名为 ZERO-RL 的训练方法,即采用可验证奖励强化学习(RLVR)逐步提升大模型在强推理场景 (math, coding) 的 pass@1 能力。相较于依赖高质量人工数据或从强大模型中提炼出的思维链的监督微调(SFT),基于强化学习(RL)的后训练在增强推理能力方面表现出更强的泛化性。
然而,目前以 Group Relative Policy Optimization (GRPO) 为代表的 RLVR 方法通常面临两个局限点:1. 训练数据难度与模型能力之间存在差距,导致奖励稀疏从而阻碍了学习过程的稳定性。2. 单纯基于 On-policy 强化学习算法的样本效率低下,这对于端侧小模型而言尤为突出。
为此,华为香港研究所小艺团队、诺亚方舟实验室与香港城市大学合作推出了 GHPO 算法框架,实现了在线强化学习与模仿学习的融合,并且能够自适应地进行切换。

-
论文标题:GHPO: Adaptive Guidance for Stable and Efficient LLM Reinforcement Learning
-
论文: https://arxiv.org/abs/2507.10628
-
Github: https://github.com/hkgc-1/GHPO
-
数据:https://huggingface.co/datasets/hkgc/math3to5_olympiads_aime
GHPO 不仅能大幅提升端侧模型的样本利用效率,同时针对性缓解了目前 RLVR 方法中的奖励稀疏现象。通过难度感知与动态引导模块设计,GHPO 不仅提升了模型训练过程中的稳定性,并且在 6 个不同的开源数学推理 Benchmark 上实现提升,尤其在 GPQA-Diamond 和 AMC23 上分别提升 9% 和 10%。该方法进一步被证明可以适用于不同难度分布的训练数据集与多个模型类别。
具体方法
在 RL 中引入模仿学习
源自于对在线强化学习算法与基于模仿学习方法的思考,该团队发现在传统 GRPO 算法的训练过程中,只有正确答案本身被用来提供监督信号,而标准解题过程未被利用。因此,团队提出了一个全新思路:通过将标准解题过程直接整合到强化学习循环中,来解决之前提到的奖励稀疏问题,并进一步提出假设:模型训练过程中通过标准解题过程的提示,从而获得有效的学习信号。并且该方法能提升模型在推理任务上的泛化能力。
后续通过一系列的实验证明该假设确实可行。
GHPO 算法框架
然而,以上的离线方案需要预先将一组训练数据集中的样本进行难度划分,并始终对其应用固定比例的提示。从而导致该方案无法实现全局最优的效果与有效的拓展。因此,该团队进一步提出了引导式混合策略优化(GHPO),实现了动态样本难度评估,并自适应地在强化学习和模仿学习之间切换。
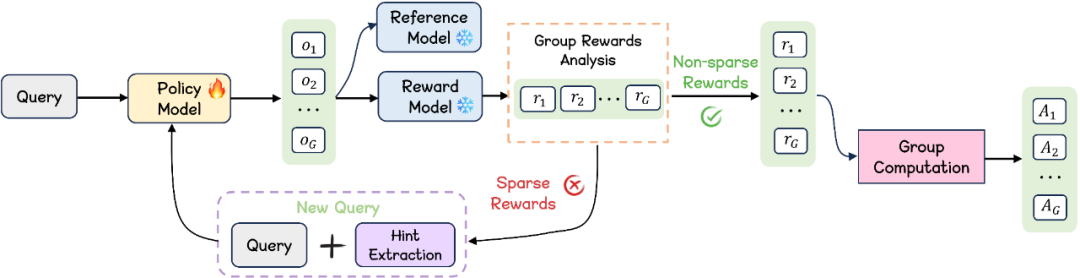
如图所示,GHPO 由两个核心模块组成:
-
自动化难度检测:该模块评估当前问题的内在难度,从而决定后续的学习过程。该模块不需要提前标准或引入其他大模型作为辅助,仅需要基于每个样本生成的解答的分布即可进行难度分类。该方案既能实现高效训练且随模型能力同步演进。
-
自适应提示切换:根据检测到的难度,该模块通过整合不同级别的标准解题路径来引导模型进行探索学习。团队提出了一种具有多阶段指导的自适应提示优化策略,该策略动态调整提示比例 ω。这种动态提示注入的核心思想是一个由学习阶段控制的线性调度。训练过程中会首先应用一小部分真实解作为初始提示,如果模型未能生成正确响应,提示的长度将在后续阶段逐渐增加。
基于以上的创新方案,GHPO 的目标函数可以表达为以下形式:
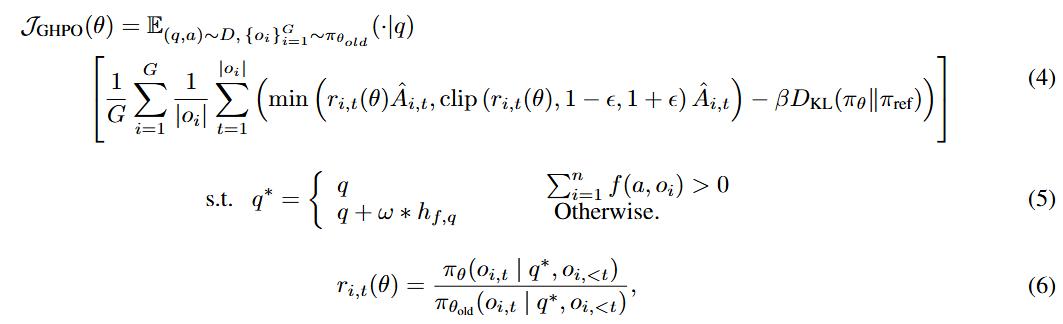
这种创新方法确保仅在模型真正需要时才提供对应指导,为模型当前能力范围内的任务保留了有价值的探索,同时为更具挑战性的场景提供了自适应的优化。
评测表现全面超越 GRPO 算法,代码数据全面开源
GHPO 的代码实现基于 Openr1 项目,训练框架的选择为 TRL,使用 vLLM 进行推理加速。团队在 TRL 的代码逻辑上直接实现了 GHPOTrainer,后续有望在 TRL 后续版本上集成。
实验设计上,基于 Qwen2.5-7B-base 模型进行了多种 RLVR 算法的实现,包括 GRPO、DeepScaleR 的课程学习,以及固定比例提示作为基线,并基于开源数据准备了两种不同难度设定的训练集,验证了 GHPO 算法在 6 个主流数学 Benchmark 上的表现:

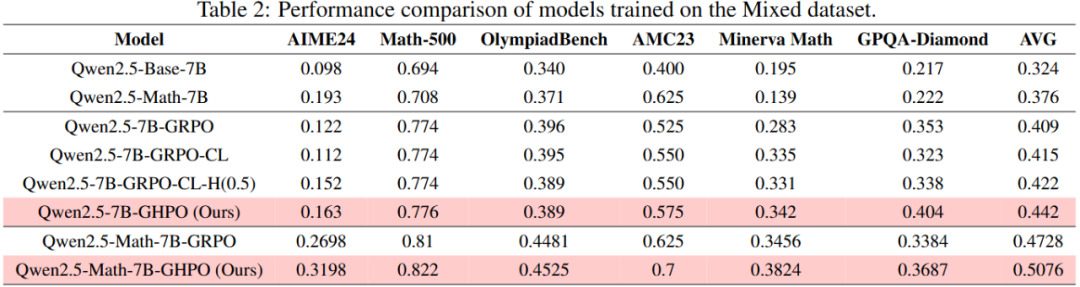
结果表明 GHPO 算法相较于 GRPO 可以实现平均 4.5% 的性能提升。
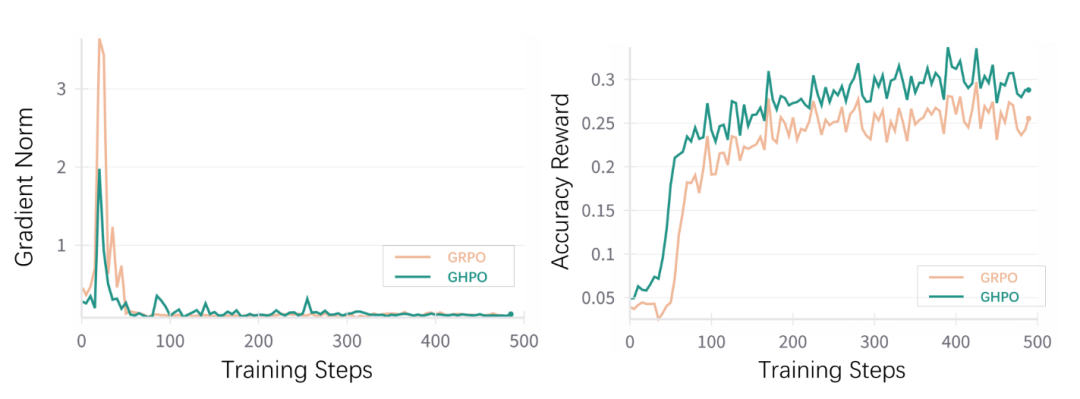
同时 GHPO 在训练过程中有着更加稳定的梯度更新。并且团队进一步证明该算法可以应用到其他模型上,如 Qwen2.5-Math-7B。
进一步提供了详细的案例展示:

总结与展望:GHPO 推动了强化学习与 SFT 之间的借鉴融合
自从 DeepSeek-R1 问世后,以 GRPO 为代表的强化学习算法一度成为大模型后训练的热点,相较于 SFT,被认为能带来更强的模型泛化能力。GHPO 不仅以一种巧妙地方式缓解了 RLVR 训练奖励信号稀疏带来的训练不稳定问题,同时实现了 on-policy 强化学习与模仿学习的自适应调整,为社区提供重新看待 SFT 与 RL 的视角以及提供两者未来深度融合的可能性,助力人类进一步探索人工智能本质。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com