ACL 2025研究揭示过程级奖励模型(PRMs)在LLM推理细粒度错误检测上陷信任危机。PRMBench基准旨在推动更可靠AI系统发展。
原文标题:ACL 2025|驱动LLM强大的过程级奖励模型(PRMs)正遭遇「信任危机」?
原文作者:机器之心
冷月清谈:
为解决这一评估空缺,复旦大学等机构联合提出了PRMBench,这是一个专为评估PRMs精细化错误检测能力而设计的、极具挑战性的基准。PRMBench的独特之处在于其史无前例的海量与精细化标注(6216个问题,83456个步骤级标签)以及创新性的多维度评估体系,涵盖简洁性、合理性和敏感性三大核心维度及九个子类别。这项研究通过对25个代表性模型(包括开源PRMs和提示为Critic的LLMs)进行广泛实验,首次系统性地揭示了当前PRMs在细粒度错误检测上的深层缺陷。
主要发现包括:即使是最佳模型,其PRMScore也仅略高于随机猜测;开源PRMs普遍落后;“简洁性”维度(识别冗余步骤)成为最大挑战;模型存在显著的“阳性偏好”(善于识别正确步骤,难识别错误步骤);错误位置对性能有影响(错误越靠后越易发现);以及PRMs易受“假阳性”影响,存在“奖励黑客”风险。
PRMBench的发布旨在推动PRM评估研究的范式转变,为未来PRM的设计、训练和优化提供关键指导,最终助力构建更可靠、更接近人类推理水平的人工智能系统。
怜星夜思:
2、PRM评估能力不足,甚至有“信任危机”,这除了文章提到的可能导致“奖励黑客”攻击,对我们普通用户来说,使用基于LLM的应用时,还可能带来哪些不明显的潜在风险或挑战呢?
3、PRMBench的发布旨在“推动PRM评估研究的范式转变”,并“助力构建更可靠的AI系统”。你认为在未来,除了技术层面的突破,我们还需要在哪些非技术层面(如伦理、法规、教育、社会认知等)做出哪些努力,才能真正建立起一个对PRMs乃至整个AI系统的“信任”基石?
原文内容

然而,它们真的足够可靠吗?一项最新研究——已荣幸被 ACL 2025 Main 接收——揭示了现有 PRMs 在识别推理过程中细微错误方面的显著不足,其表现甚至可能不如随机猜测,敲响了「信任危机」的警钟!

-
标题:PRMBench: A Fine-grained and Challenging Benchmark for Process-Level Reward Models
-
论文链接: https://arxiv.org/abs/2501.03124
-
项目主页: https://prmbench.github.io/
-
讲解视频: https://www.bilibili.com/video/BV1kgu8z8E6D
-
单位:复旦大学、苏州大学、上海人工智能实验室、石溪大学、香港中文大学
PRM 真的过时了吗?基于规则奖励的强化学习不断暴露假阳性及推理过程幻觉严重等问题,因此我们需要针对过程的有效监督,而如何评测过程监督的质量就是一个值得探索的问题,目前主流的评估方法往往过度关注最终结果的正确性,而忽视了对推理过程中细致入微的错误类型的识别。
例如,一个推理步骤可能存在冗余、部分正确、甚至完全错误等多种状态,简单的「正确/错误」标签远不足以捕捉其内在的复杂性与细微差别。这种评估粒度的缺失,使得我们难以真正理解 PRMs 的局限性,也阻碍了其能力的进一步提升。
为填补这一空白,复旦大学、苏州大学、上海人工智能实验室、石溪大学、香港中文大学等机构联合提出了 PRMBench,一个专为评估 PRMs 精细化错误检测能力而设计、且极具挑战性的基准。这项被 ACL 2025 接收的突破性研究,不仅深入剖析了现有 PRMs 的「软肋」,更首次系统性地揭示了它们在复杂推理评估中的深层缺陷,为未来研究指明了清晰的方向。
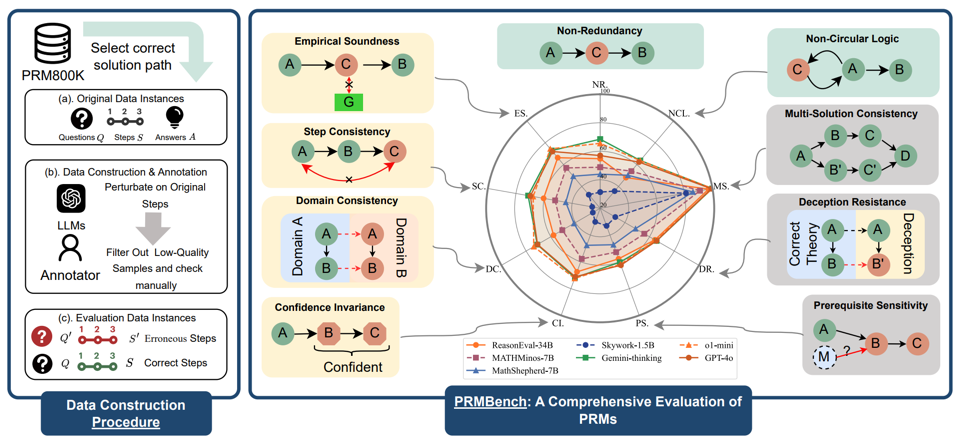
图 1 PRMBench 的主要结构,左侧展示了数据整理的流程;右侧展示了评估主题的示例以及测试模型的相对性能表现。
PRMBench:一次针对 PRMs 的「全方位体检」
PRMBench 并非简单的数据集扩充,而是一套经过精心构建的「全方位体检方案」,旨在系统性、多维度地考察 PRMs 的各项核心能力。
PRMBench 的独特优势
-
史无前例的海量与精细化标注:PRMBench 包含 6216 个精心设计的问题,并拥有高达 83456 个步骤级别的细粒度标签。这确保了评估的深度和广度,能够全面覆盖 PRMs 可能遇到的各种复杂推理场景。
-
创新性的多维度评估体系:PRMBench 从简洁性(Simplicity)、合理性(Soundness)和敏感性(Sensitivity)三大核心维度出发,进一步细分为九个子类别:「非冗余性」(Non-Redundancy)、「非循环逻辑」(Non-Circular Logic)、「评价合理性」(Empirical Soundness)、「步骤一致性」(Step Consistency)、「领域一致性」(Domain Consistency)、「置信度不变性」(Confidence Invariance)、「前提条件敏感性」(Prerequisite Sensitivity)、「欺骗抵抗」(Deception Resistance)和「一题多解一致性」(Multi-Solution Consistency)。这一全面而细致的评估框架,力求捕捉 PRMs 在各种潜在错误类型上的表现。
-
首次系统性揭示现有 PRMs 的深层缺陷:研究团队对包括开源 PRMs 和将主流 LLMs 提示为 Critic 模型的 25 个代表性模型进行了广泛而深入的实验。实验结果令人震惊且引人深思,首次系统性地揭示了当前 PRMs 在细粒度错误检测上的显著弱点。
本文的主要发现
-
整体表现远低于预期:即使是表现最佳的模型 Gemini-2-Thinking,其 PRMScore 也仅为 68.8,远低于人类水平的 83.8,且勉强高于随机猜测的 50.0。这明确指出,即使是最先进的 PRMs,在多步过程评估中仍有巨大的提升空间。
-
开源 PRMs 普遍落后:相较于将强大通用语言模型提示为 Critic Model 的表现,当前的开源 PRMs 通常表现出更低的性能,这凸显了其在实际应用中的可靠性问题和潜在的训练偏差。
-
「简洁性」成为最大挑战:在「简洁性」维度上,即使是表现相对较好的 ReasonEval-34B,其 PRMScore 也骤降至 51.5。这表明,PRMs 在识别推理过程中冗余、不必要的步骤方面存在明显的能力不足。
-
显著的「阳性偏好」现象:实验发现,部分模型,例如 ReasonEval-7B 和 RLHFlow-DeepSeek-8B,在评估中表现出显著的「阳性偏好」。它们在正确步骤的判断上准确率很高(超过 95%),但在识别错误步骤(阴性数据)时平均准确率仅为 17%,这严重影响了其可靠性。
-
错误位置对性能的影响:研究深入分析了错误步骤在推理链中位置对 PRMs 性能的影响。结果显示,PRMs 的性能会随着错误步骤在推理链中位置的逐渐后移而呈现出渐进式提升。
-
「假阳性」影响严重:过程级奖励模型(PRMs)往往难以识别那些假阳性步骤,这使得它们存在被模型「钻空子」、易受「奖励黑客」攻击风险。
在一项需要举出反例的复杂证明题实践中,我们观察到一个令人担忧的现象:即使像 o1 这样强大的大语言模型,在推理过程中自身已意识到问题,仍可能产生错误的推理步骤。更令人警惕的是,当我们调用现有过程级奖励模型(PRMs)去检测 o1 生成的推理过程时,结果却发现多数 PRMs 无法检测出这种细粒度的错误。这一发现直指核心问题:当前的 PRMs 是否真正具备检测推理过程中细粒度错误的能力?

图 2 当询问模型一道拉格朗日中值定理相关问题时,o1 和 PRM 可能会产生的错误。
然而,现有针对 PRM 评测而设计的基准,大多仅仅关注步骤判断的宏观对错,而忽视了对错误类型本身的细致分类。这意味着当前业界急需一个能够全面评测 PRMs 在细粒度错误上表现的综合基准。而这,正是我们推出 PRMBench 这一精细化基准的根本驱动力。我们希望通过 PRMBench,打破现有评估的局限,真正遴选出能够有效识别细粒度错误的「优秀」PRM,并为未来 PRMs 的发展提供精确的诊断工具。
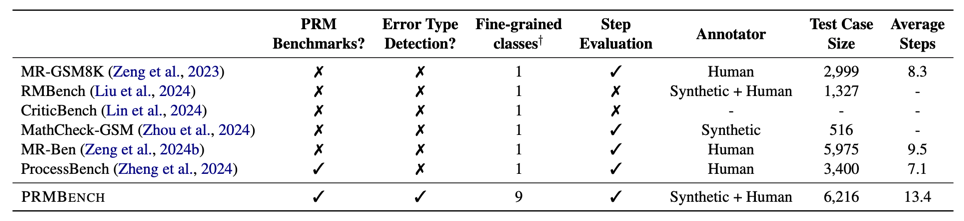
表 1 PRMBench 与其他现有基准的对比。
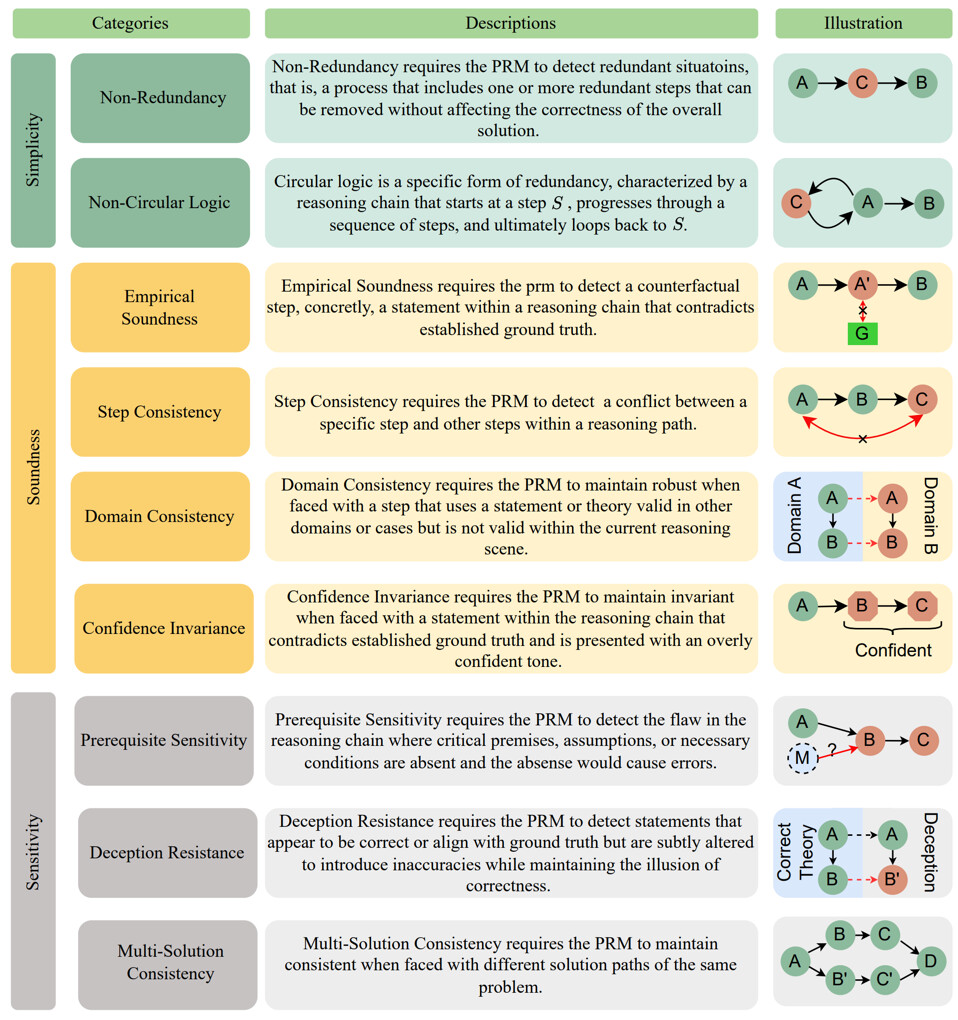
图 3 PRMBench 包含三大评测主题:「简洁性」(Simplicity)、「合理性」(Soundness)和「敏感性」(Sensitivity)。
数据来源与构建:
-
元数据提取:基于 PRM800K 数据集,筛选出其完全正确的问题、答案及解题步骤,作为构建我们基准的元数据。
-
细粒度错误注入:针对 PRMBench 的多数评测主题(前 8 个子类别),我们策略性地使用先进的 LLMs(特别是 GPT-4o)将各种细粒度的、预设的错误类型注入到原始的正确解题推理步骤中。对于「一题多解一致性」这一特殊情况,则利用多步推理增强型语言模型为同一问题生成多种不同的、但均正确的解法及其推理步骤,以测试 PRM 的一致性判断能力。
-
严格的人工验证:所有注入错误的实例均经过严格的人工审查,以确保错误类型引入的质量和相关性,保证数据集的真实性和可靠性。
-
大规模数据集统计:最终,PRMBench 构建了包含 6,216 个精心设计的问题,并带有总计 83,456 个步骤级别的细粒度标签的评估数据集。
评估维度与指标:
PRMBench 的评估体系分为三大主要领域,旨在对 PRMs 进行全方位的深度剖析:
-
简洁性(Simplicity):评估 PRMs 识别和排除冗余推理步骤的能力,包括「非冗余性」和「非循环逻辑」两个子类别。
-
合理性(Soundness):核心评估 PRM 所生成奖励信号的准确性和对错误类型的正确识别能力,涵盖「评价合理性」、「步骤一致性」、「领域一致性」和「置信度不变性」四个子类别。
-
敏感性(Sensitivity):衡量 PRMs 在面对细微变化或误导性信息时的鲁棒性和精确识别能力,细分为「前提条件敏感性」、「欺骗抵抗」和「多解一致性」三个子类别。
评估模型:我们对 25 个主流模型进行了广泛测试,其中包括了各种开源 PRMs(如 Skywork-PRM、Llemma-PRM、MATHMinos-Mistral、MathShepherd-Mistral、RLHFlow-PRM 等)以及通过巧妙提示作为 Critic Models 的优秀闭源语言模型(如 GPT-4o、o1-mini、Gemini-2-Thinking 等)。
评估指标:
-
负 F1 分数(Negative F1 Score):作为评估错误检测性能的核心指标,着重衡量模型识别错误步骤的准确性。
-
PRMScore:这是一个综合性、统一化的分数,通过将 F1 分数(衡量正确识别)和负 F1 分数(衡量错误识别)有机结合,更全面、均衡地反映了模型的整体能力和可靠性。
关键发现:
-
PRMs 整体表现令人担忧:我们的实验结果表明,现有 PRMs 在多步过程评估中的能力非常有限。即使是性能最佳的模型,其得分也常常仅略高于随机猜测,这预示着巨大的提升空间。
-
开源 PRMs 普遍落后:相较于将强大通用语言模型提示为 Critic Model 的表现,当前的开源 PRMs 通常表现出更低的性能,这凸显了其在实际应用中的可靠性问题和潜在的训练偏差。
-
「简洁性」构成最严峻挑战:在所有评测维度中,检测推理过程中的冗余步骤(即「简洁性」类别)被证明对 PRMs 来说尤其困难,成为它们面临的最大挑战之一。
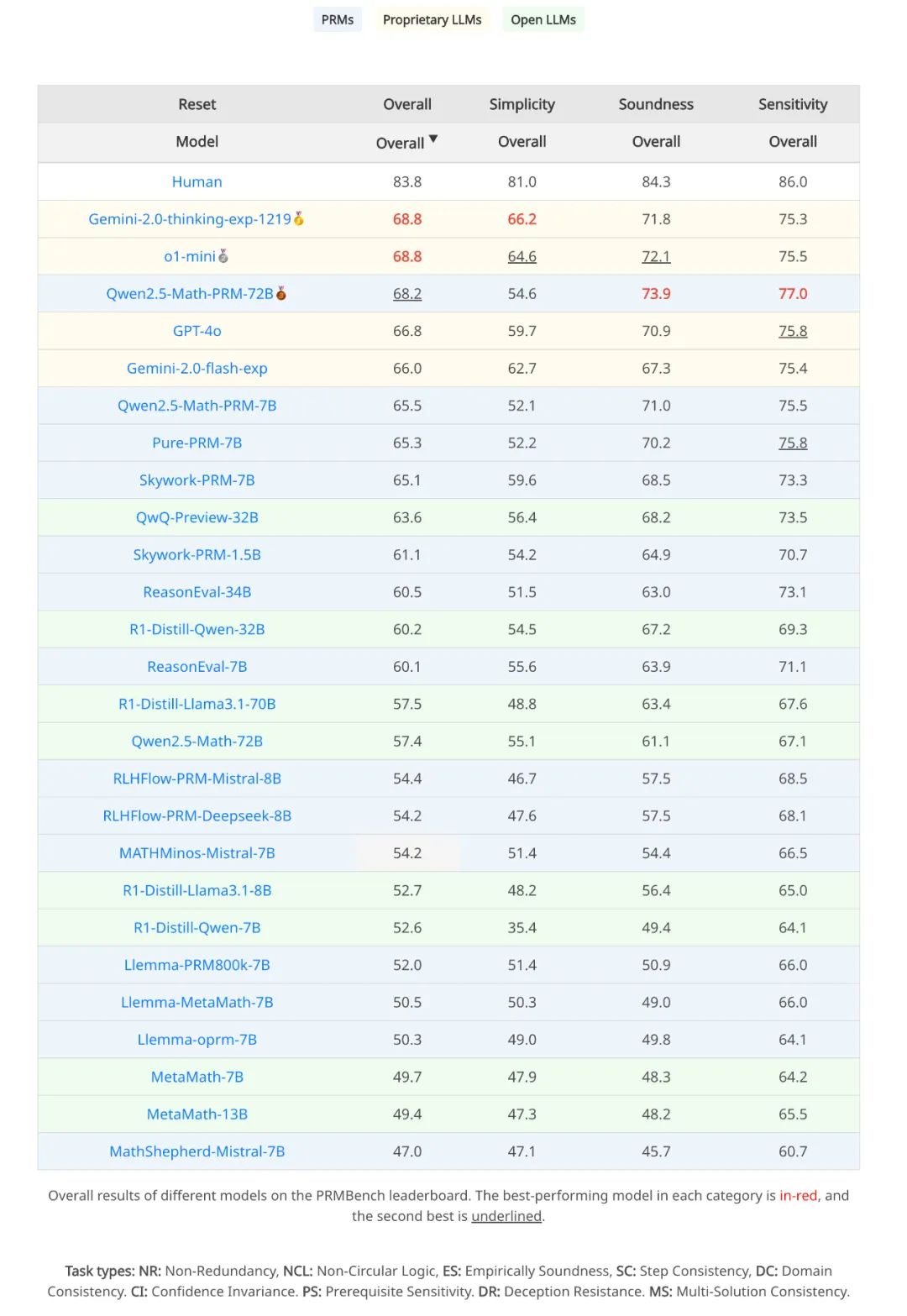
表 2 PRMBench 的主要结果概览。
「正确标签偏好」显著:许多 PRMs 在评估中表现出对「正确」标签的明显偏好,导致它们在识别错误标签测试样例(即「阴性数据」)时存在困难,这严重影响了其公正性和全面性。
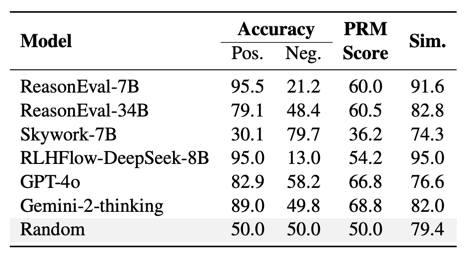
表 3 PRMBench 下模型对于正确标签测试样例(阳性数据)和错误标签测试样例(阴性数据)的得分对比及相似度。
错误位置的影响:深入分析发现,PRMs 的性能会随着推理步骤在推理链中位置的逐渐靠后而呈现出渐进式提高。这一现象揭示了 PRMs 在处理推理早期阶段错误时的潜在挑战。
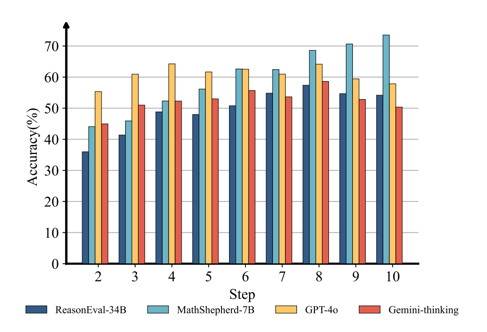
图 4 推理步骤位于推理链中不同位置对模型 PRMScore 的影响。
少样本 ICL 的影响有限:实验结果表明,在奖励模型评估过程中使用不同数量的 In-Context Learning(ICL)示例,对闭源模型的性能影响甚微。这提示我们,对于 PRMs 的提升,可能需要更深层次的模型结构或训练范式创新,而非仅仅依赖提示工程。
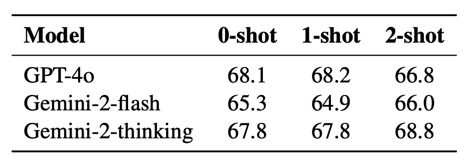
表 4 不同 Few-shot 数目对于提示为 Critic Model 的通用语言模型表现影响。
PRM 易受「假阳性」影响,暴露「奖励黑客」问题:过程级奖励模型(PRMs)往往难以识别那些表面上看似合理、实则存在错误的推理步骤,也难以识别结果正确,但过程存在错误的「假阳性」现象,这使得它们存在被模型「钻空子」、易受「奖励黑客」攻击的风险。为验证这一现象,作者将各模型在 PRMBench 与常用的 Best-of-N(BoN)评估方法上的表现进行了对比。结果显示,PRMBench 在区分模型能力方面具有更高敏感性,而 PRMBench 与 BoN 之间的明显不一致也进一步揭示出当前 PRMs 在应对「假阳性」问题上的显著不足。
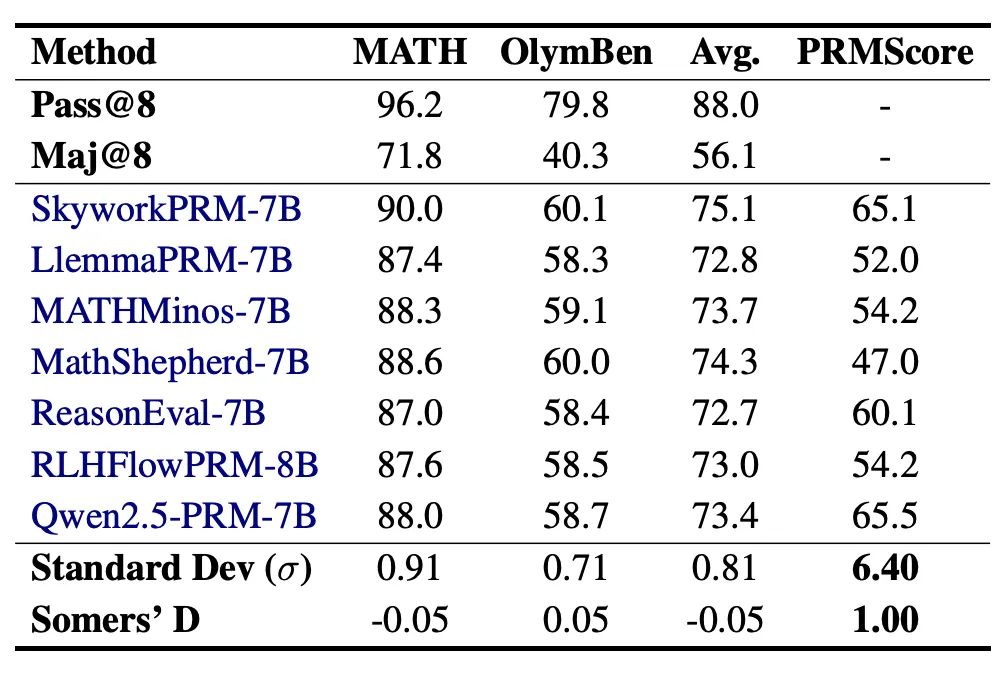
表5. 使用不同 PRM 在 Best-of-8 评估与 PRMBench 评估下的得分,可区分性和相似性对比
PRMBench 的发布,不仅是一个新的、更高标准的评估基准,更是一声警钟,提醒我们必须重新审视现有 PRMs 的能力边界,并加速其在复杂推理场景下细粒度错误检测能力的发展。
研究的深远意义与展望:
-
推动 PRM 评估研究的范式转变:PRMBench 提供了一个前所未有的全面、精细化评估工具,能够更有效地识别 PRMs 的潜在缺陷和「盲区」,从而促进相关算法和模型的根本性改进。
-
指引未来 PRM 的开发方向:通过详尽揭示现有 PRMs 在不同维度上的优缺点,PRMBench 为未来 PRM 的设计、训练和优化提供了关键的指导性洞察,助力研究人员开发出更具鲁棒性和泛化能力的模型。
-
助力构建更可靠的 AI 系统:只有拥有更可靠、更精确的 PRMs,才能有效提升 LLMs 在复杂推理任务中的表现,从而最终构建出更加值得信赖、更接近人类推理水平的人工智能系统。
「我们坚信,PRMBench 的发布将成为推动过程级奖励模型评估和发展研究的坚实基石,为构建新一代高度可靠的 AI 系统贡献力量!」研究团队表示。
立即探索PRMBench,共同迎接挑战!
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:[email protected]