《图解DeepSeek技术》:全彩图解,深度剖析DeepSeek大模型推理与架构,助你轻松掌握核心技术。
原文标题:全彩图解,从根上搞懂 DeepSeek 技术
原文作者:图灵编辑部
冷月清谈:
怜星夜思:
2、《图解DeepSeek技术》这本书主打全彩图解,强调“看图学”。你认为这种视觉化的学习方式,对于理解大型复杂技术(比如大模型)有多大帮助?有没有可能在某些情况下,过度依赖图解反而会让人忽视一些关键的细节或者底层的原理?
3、文章提到《图解DeepSeek技术》会解答“DeepSeek到底牛在哪里?”。抛开文章中提到的MoE架构和强化学习,你觉得DeepSeek作为国产大模型的代表,还有哪些方面是它特别“牛”或者值得我们关注的?
原文内容
100多幅高清彩图,系统了解DeepSeek背后的技术。
“大模型到底是怎么推理的?”
“DeepSeek 到底牛在哪里?”
诸如此类拷问灵魂的问题,你还有点没摸透。
你可能读过几篇文章,但还远未形成系统的认知,想过专门拿个时间来研究一番,但啃英文论文实在有点让人发怵——我知道面临这个问题的肯定不是一两位朋友——如果能有一本书专门解读一下上述两个问题,这本书绝对值得每一位读者好好阅读。话说,我们确实为了回答这两个问题专门做了一本书,这就是《图解DeepSeek技术》。

看到「送朋友」这个按钮了吗(直接能看到,或者点进去)?简直是送礼神器,送 Ta 一本全彩高清、美惨了的《图解DeepSeek技术》大概是最极客风的礼物了吧!
——回到正题
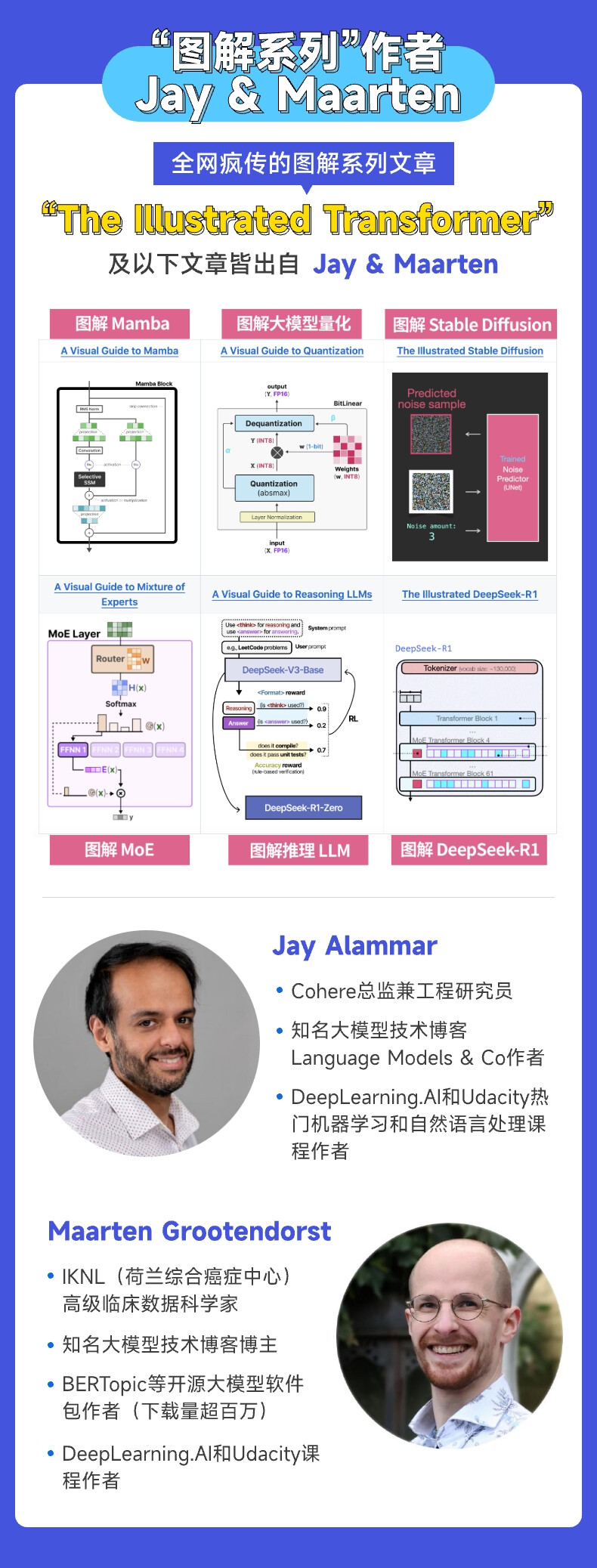
这本书的作者大家都很熟悉,就是大名鼎鼎的 Jay & Maarten(袋鼠书《图解大模型》作者、技术解读名家、大模型专家)—— 能请到两位大佬来做这本书,不瞒大家说,真的是让编辑老师兴奋地整夜都睡不着觉啊。
原计划,这本书很快就能出版,没想到内容打磨了个来回,就到了2025年的下半场。好书不怕晚,今天,非常隆重地为大家推荐这本最新上市的白鳍豚书《图解DeepSeek技术》——也是咱们的袋鼠书《图解大模型》的姊妹篇——传承《图解大模型》的精神,继续扛着图解的大旗,为大家提供更通俗易懂、更形象生动的大模型核心技术解读。
我们还是先简单看看两位作者以及译者吧,可能有部分朋友还没来得及认识他们。
作者 Jay & Maarten
译者李博杰 & 孟佳颖
Jay & Maarten 这俩名字你可能知道,也可能不知道,但他们解读大模型技术的系列文章风靡全世界的互联网圈子,恐怕技术社区无人不知、无人不晓,比如全网热度最高的“The Illustrated Transformer”,据说是让无数网友真正搞懂了 Transformer 的内部机制。《图解大模型》(袋鼠书,英文版HandsonLLM)是两位的代表作,很多读者都开始读了吧?在解读大模型原理方面,袋鼠书绝对是屈指可数的好书。如果你还没了解过袋鼠书,请查看。
两位不止是写作高手,还妥妥的是实战高手——Jay 在枫叶国大模型独角兽公司 Cohere 炼丹,Maarten 手搓的 BERTopic 等开源大模型包下载量超百万——这样的两位作者推出的新作品,期待值绝对拉满。
了解完了作者,来插播解答一下部分朋友的困惑。有一部分朋友可能有点好奇:这本书是从外版引进的吗?怎么国外并没有看到原版图书呢?唉,朋友,你的观察力真的很强哦!
这本书是咱们图灵的原创外版翻译书,是我们邀请 Jay & Maarten 直接来创作的英文版(英文版未发行,所以市面上搜不到)。紧接着呢,图灵又邀请译者将其翻译成了中文版——所以市面上只有中文版,且全球独一份,别的地方找不到(话说虽然其中有几篇文章来自 Jay 和 Maarten 的博客,但经过系统打磨、添加内容、剔除内容等梳理工作后,即使你阅读了两位的所有博客文章,这本书也非常值得系统阅读)。
白鳍豚书的译者大家也熟悉,博杰大佬领衔翻译。2025 年 3 月前后,博杰在翻译完《图解大模型》之后就投入了《图解DeepSeek技术》的翻译工作。在此也感谢博杰,非常认真、细致、专业。(话说博杰从华为离职之后,一跃而入大模型的浪潮,当前在做智能体的创业,期待他的新产品跟大家见面。)

核心内容
我们一开始就提到,这本书最初想回答两个问题:
“大模型到底是怎么推理的?”
“DeepSeek到底牛在哪里?”
你觉得回答这两个问题需要多大的篇幅?
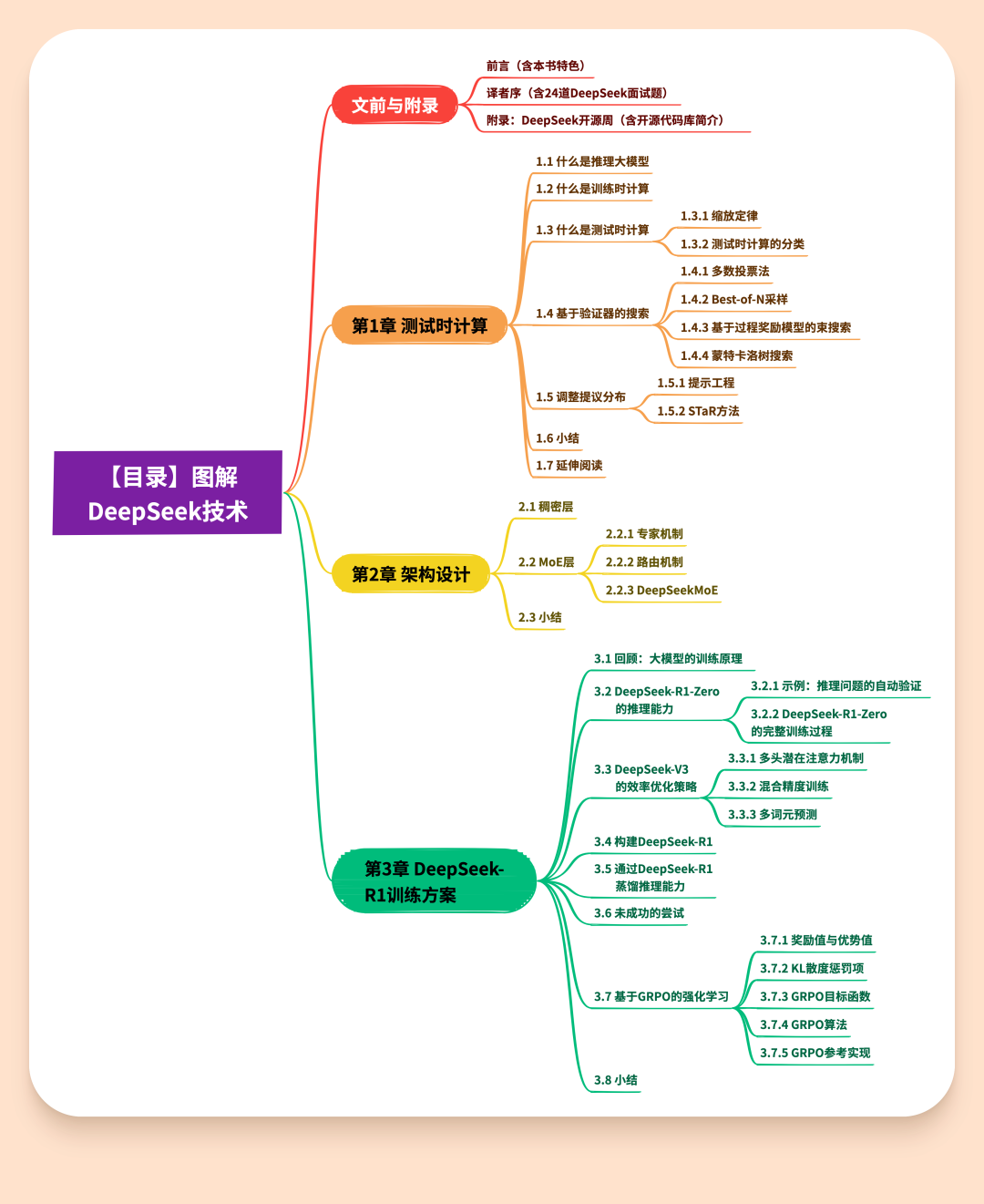
或者说,你期待这本书有多厚呢?——好吧,直接给你答案,白鳍豚书成书是104 页,内容有 3 章 + 1 个附录:
-
第1章,测试时计算(到底改变了什么?)
-
第2章,MoE 架构(DeepSeek 的推理底座)
-
第3章,DeepSeek-R1 训练全过程拆解(涵盖基于 GRPO 的强化学习等核心技术)
-
附录:DeepSeek 开源周活动一览
104 页可能是你见过的书中最薄的,但绝对也属于干货密度最高的。这本书从一开始定位就是:短小精悍,希望能契合你的阅读期待。
把目录贴在下面,大家看一眼就知道章节组织了:
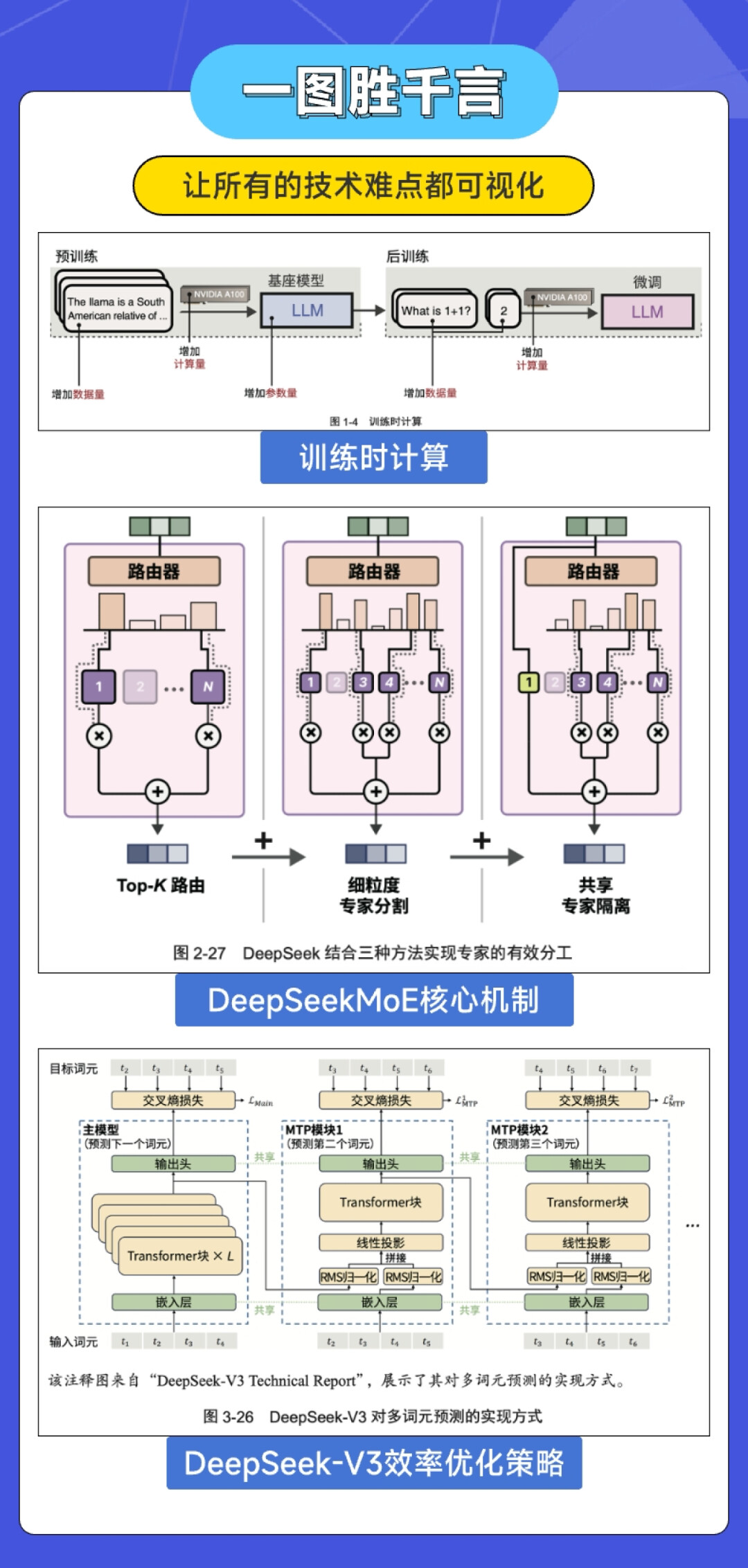
图书特色:全彩图解
全书 104 页,118 幅图
这是啥概念?
每页至少一幅图,真正的用图说话。
全书近 120 幅全彩插图,主打一个看图学,就算没有任何大模型背景的朋友也能迅速 Get 相关技术的精髓。
基于多年来向数百万读者讲解复杂 AI 概念的经验,Jay & Maarten 逐渐形成了一套成熟的视觉语言和叙事方法。《图解DeepSeek技术》同样基于这套方法精心设计,引导读者先聚焦最重要的思想,然后循序渐进地构建更完整的知识图景,从而逐步加深对该主题的理解并增强掌握相关知识的信心。
给大家展示几张图,感觉感觉:

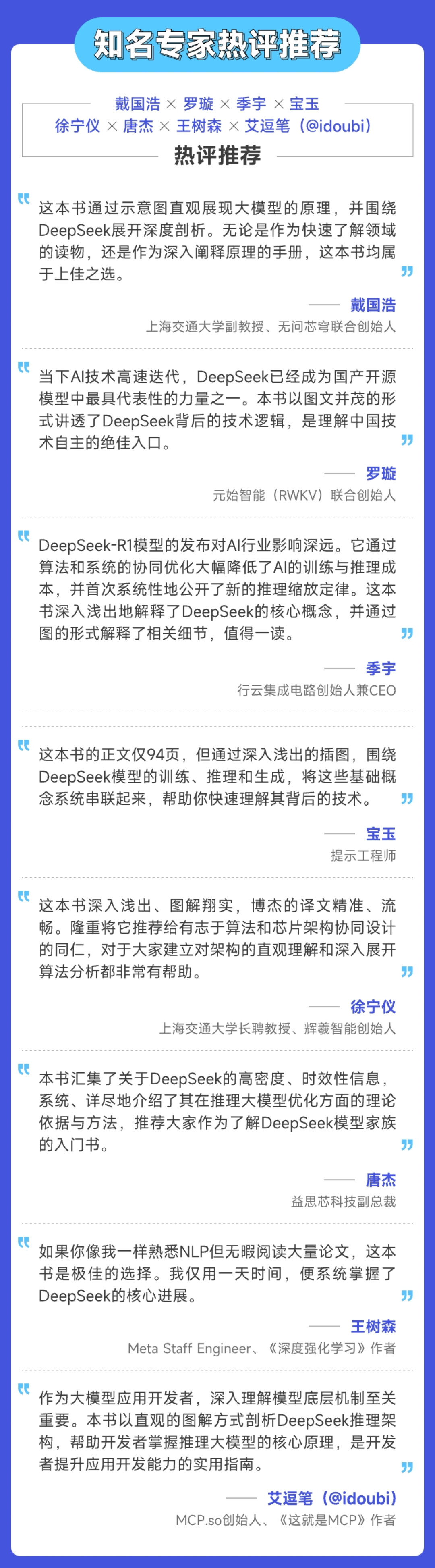
领域专家热评推荐
本书得到了领域内专家与一线开发者的热评推荐,感谢诸位提前审阅本书,并给出诚挚的评论。
谁适合阅读
谨以本书献给每一位:
-
想深入理解大模型工作机制的开发者
-
想追上 AI 热潮但被原理劝退的普通读者
致敬了不起的“图解”叙事,让复杂的原理变得简单、形象。不妨以这本书为起点,真正从根上搞懂大模型、推理大模型以及各种代表产品。
超级福利,签名版限时抢
图灵的新书现在已经罕见 5 折购了,这本书给大家把价格打下来了,限时昂,真的别犹豫,29.9 且免运费,这么亮的价格哪里找去!