SynCheck获MobiSys顶会最佳论文。它以创新框架,通过高质量无线合成数据,有效突破物理感知大模型的数据稀缺难题。
原文标题:无线合成数据助力破解物理感知大模型数据瓶颈,SynCheck获顶会最佳论文奖
原文作者:机器之心
冷月清谈:
为解决这一数据稀缺难题,北京大学许辰人教授团队与匹兹堡大学高伟教授联合推出了SynCheck框架。这项工作荣获了移动计算领域旗舰会议MobiSys 2025 的最佳论文奖。
SynCheck的核心在于提供与真实数据质量相近的合成数据,并提出了一套创新的评估与应用方法。
1. **数据质量评估**:SynCheck引入了两个关键质量指标——亲和力(衡量合成数据与真实数据的相似度)和多样性(评估合成数据覆盖真实数据分布的范围)。其通过贝叶斯分析和性能指标构建了通用的评估框架,并通过“边际”概念实现了跨数据集的公平比较。研究发现,现有无线合成数据普遍存在“亲和力不足”的问题,导致模型性能下降。
2. **合成数据应用**:基于上述质量评估,SynCheck框架将合成数据视为未标记数据,真实数据作为标记数据,采用半监督学习方法迭代训练。在此过程中,系统能够有效过滤低亲和力的合成样本,并为高质量样本分配伪标签。这种方法无需修改生成模型的训练或推理流程,可作为通用的后处理步骤灵活适配各种生成流程。
实验结果显示,SynCheck显著提升了任务性能,即使在质量相关方法表现最差的情况下,也能实现性能提升。更重要的是,它能动态校正合成数据的分布偏差,使得模型性能随数据规模扩展而稳定提升,有效缓解了其他基线方法中因分布差异导致的性能下降问题。
SynCheck的提出不仅为无线感知领域的数据匮乏问题提供了切实可行的解决方案,也为当前学术界关于合成数据“模型崩塌”现象的争论提供了新的视角与验证方法。它为未来无线大模型的训练范式革新奠定了基础,预示着通过高质量合成数据与多元数据源的融合,将有力推动具身智能系统在物理世界的深度融合与广泛应用。
怜星夜思:
2、无线感知听起来超酷的,除了文章里说的那些,大家觉得以后还能用在哪儿?比如家里、医院?还有就是,它要真的普及开来,会有啥难啃的骨头?
3、文章里的SynCheck提出了几个质量指标,那是不是所有搞合成数据的都能直接用这套标准?还有就是,到底什么时候该多用真实数据,什么时候能放飞自我用合成数据呢?这个“度”咋把握?
原文内容

在万物互联的智能时代,具身智能和空间智能需要的不仅是视觉和语言,还需要突破传统感官限制的能力;无线感知正成为突破这些物理限制的关键技术:通过捕捉无线信号的反射特性,它让不可见的目标变得可感知,使机器能够 "看见" 墙壁后的动静、"感知" 数米外的动作,甚至捕捉到人类难以察觉的微妙变化。这种全新的感知维度,能对环境中人机行为实现无感监测与精准解析,正在重塑人机交互的边界。
从感知到决策,离不开具有强大语义理解能力的大模型。但怎样构建一个除了视觉和语言之外,能够理解物理原理(电磁场、光学、声学等)、与物理世界交互的大模型?
这一问题并不能复制语言、视觉大模型的经验,因为大模型可以从人类几千年的文字资料中学习语言,可以从整个互联网的视频学习视觉;但除此以外,能提供给模型学习的数据微乎其微;仅依赖真实世界的数据采集,难以支持大模型所需的海量数据。
为解决数据稀缺这一最大挑战,北京大学的许辰人教授团队和匹兹堡大学的高伟教授联合提出 SynCheck,为机器学习提供与真实数据质量相近的合成数据。相关工作发表在移动计算领域旗舰会议 MobiSys 2025 上,并获得会议的最佳论文奖。

-
论文标题:Data Can Speak for Itself: Quality-guided Utilization of Wireless Synthetic Data
-
论文链接:https://arxiv.org/abs/2506.23174
-
代码链接:https://github.com/MobiSys25AE/SynCheck
1. 生成模型评估:数据导向的效率优化
在无线感知领域,生成模型已被广泛用于产生合成数据以补充真实数据集。然而,现有研究大多只关注数据量的扩充,而忽视了合成数据的质量问题。为解决这一问题,研究团队提出了两个创新性质量指标:
-
亲和力(affinity):衡量合成数据与真实数据的相似度
-
多样性(diversity):评估合成数据覆盖真实数据分布的范围
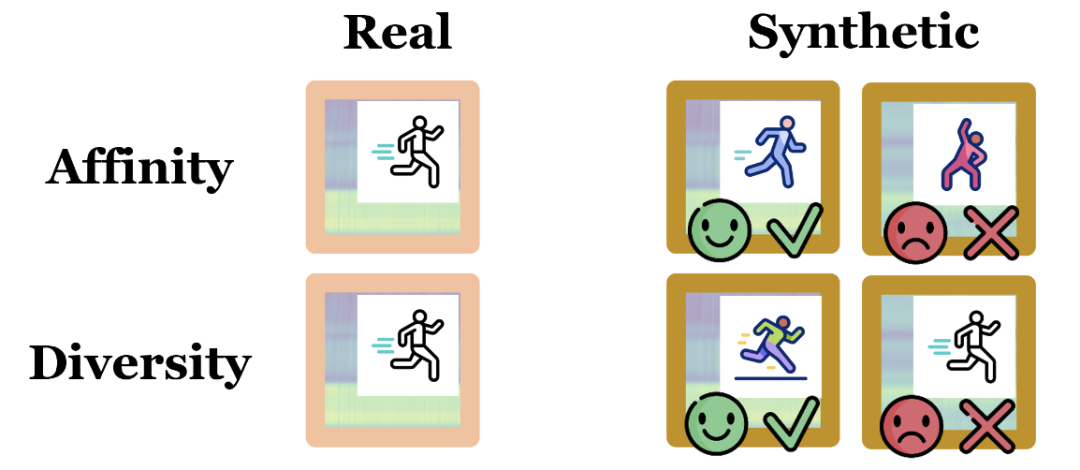
图:两类质量指标的解释
与以往依赖视觉启发或局限于特定数据集的质量评估方法不同,这项研究通过贝叶斯分析和性能指标建立了具有理论支撑的通用评估框架。研究还引入 "边际"(margin) 概念作为性能指标,利用训练集的边际分布作为自然参考标准,实现了跨数据集的公平比较。
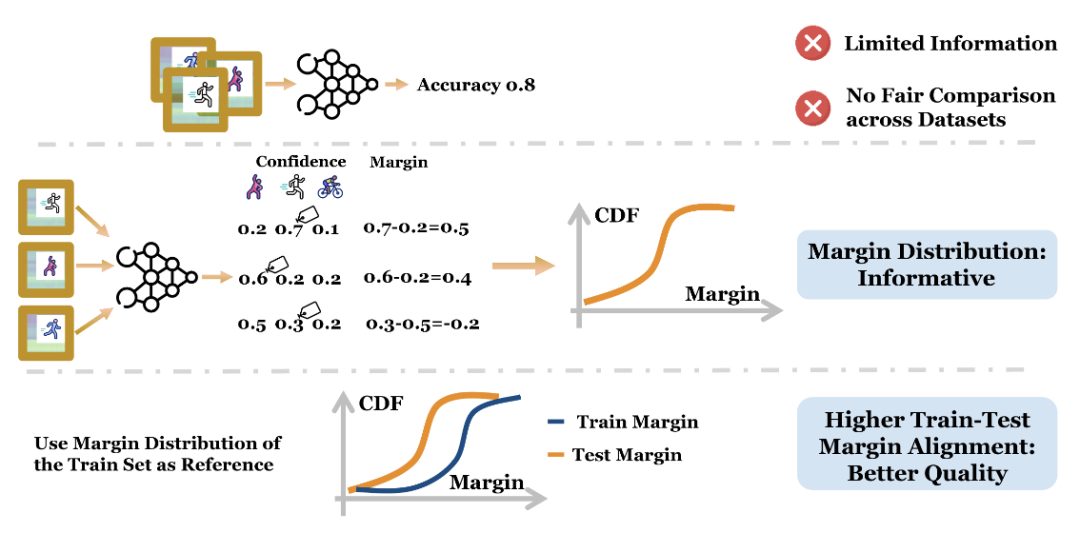
图:基于 margin 的质量评估方法
研究团队通过系统评估发现,现有无线合成数据普遍存在 “亲和力不足” 的问题,这会导致数据标签错误,进而降低任务性能。
2. 合成数据应用:质量优先的性能突破
基于质量评估结果,团队开发了 SynCheck 框架,其核心创新在于:
1. 将合成数据视为未标记数据,真实数据作为标记数据
2. 采用半监督学习框架结合两种数据源,在迭代训练过程中过滤低亲和力合成样本,为剩余样本分配伪标签
这种方法不需要修改生成模型的训练或推理过程,可以作为通用后处理步骤适配各种生成流程。
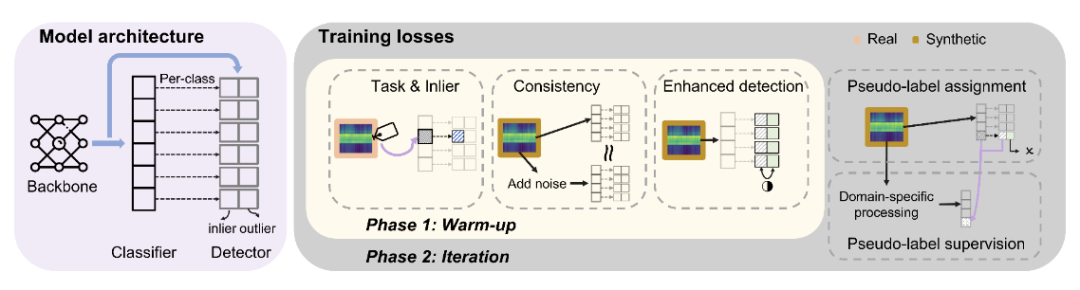
图:基于半监督学习的合成数据通用后处理使用方法
实验结果显示,SynCheck 在性能上实现了显著提升:
1. 在质量无关方法导致性能下降 13.4% 的最坏情况下,仍能实现 4.3% 的性能提升
2. 最佳情况下性能提升达 12.9%
3. 过滤后的合成数据展现出更好的亲和力,同时保持了与原始数据相当的多样性
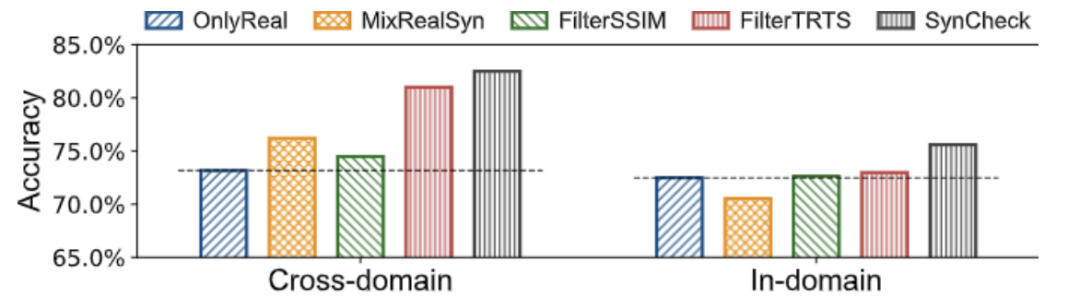
图:合成数据的不同使用方法的性能对比
在逐步提升合成数据占比的过程中,由于合成数据与真实数据存在分布差异,其他基线方法的任务性能会随着合成数据比例增加而显著下降,这种分布偏移现象破坏了任务性能与训练数据之间的 scaling law 规律。相比之下,SynCheck 方法通过动态校正合成数据的分布偏差,使得模型性能能够保持稳定提升,最终收敛至最优状态。
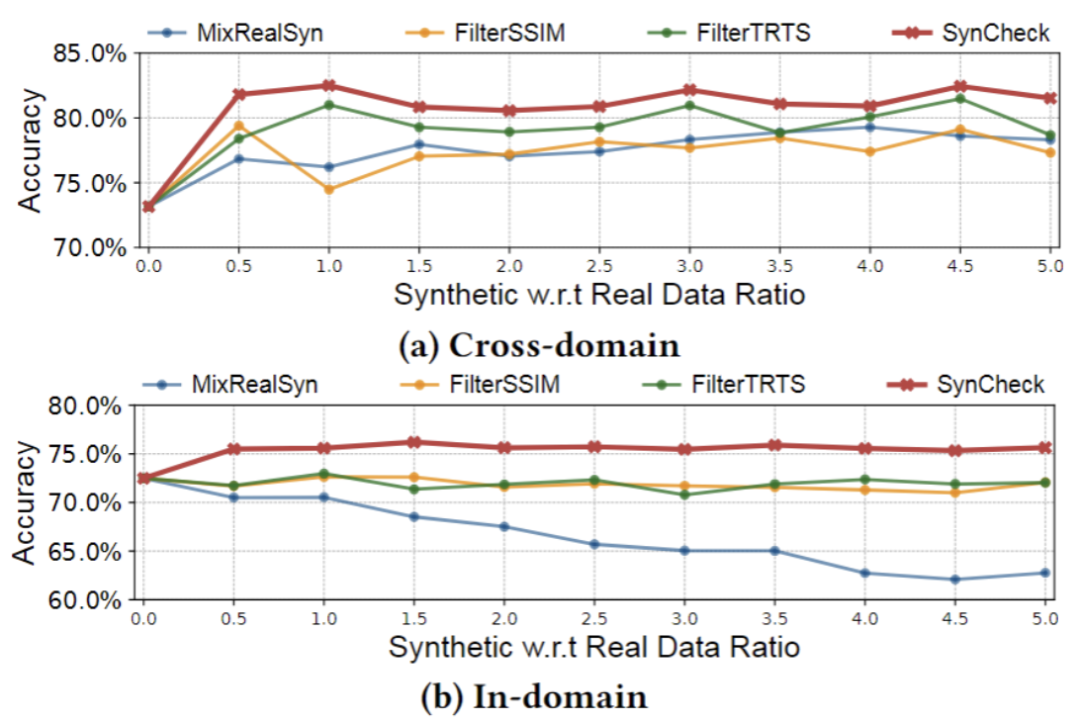
图:任务性能随合成数据规模扩展的变化趋势
3. 超越数据瓶颈:无线大模型的规模化应用前景
当前学术界对合成数据的研究呈现明显的观点分野。持审慎态度的学者从理论推演和实证研究出发,提出了 "模型崩塌"(model collapse)的警示 —— 这类似于生物学上的近亲繁殖现象,当模型持续消化自身生成的数据时,其性能将不可避免地出现退化。然而,另一批研究者则持乐观态度,他们认为通过引入验证器(verifier)机制,完全可以规避模型崩溃的风险。值得注意的是,现有研究多集中于数学、代码等具有明确评价标准的领域,而在复杂度更高的任务场景中,这一问题的验证仍面临挑战。
北京大学和匹兹堡大学的研究团队创新性地提出了以目标任务模型为桥梁的研究范式,成功建立了合成数据与真实数据条件分布之间的映射关系。这一突破性进展为无线感知这一真实数据匮乏但性能导向的领域,确立了切实可行的数据质量评估标准与筛选方法。
未来,研究团队将致力于推动无线大模型的训练范式革新,通过拓展数据源的多样化泛化路径,探索更高效的预训练任务架构,实现合成数据与多元数据源的有机融合。在此基础上,团队将进一步构建面向各类无线感知任务的通用预训练框架,积极拓展多样化的数据来源,依托更强大的无线大模型,为具身智能系统提供坚实的感知与决策支撑。这些研究不仅将深化对合成数据质量标准的理论认知,更将为新一代具身智能系统的创新发展奠定基础,推动人工智能在物理世界的深度融合与广泛应用。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com