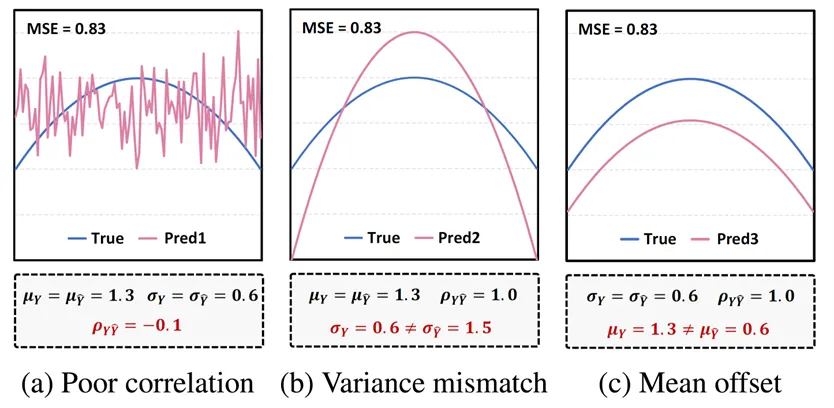
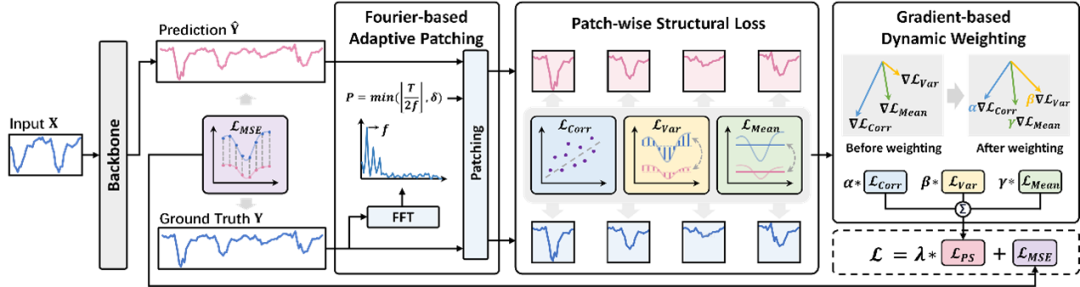
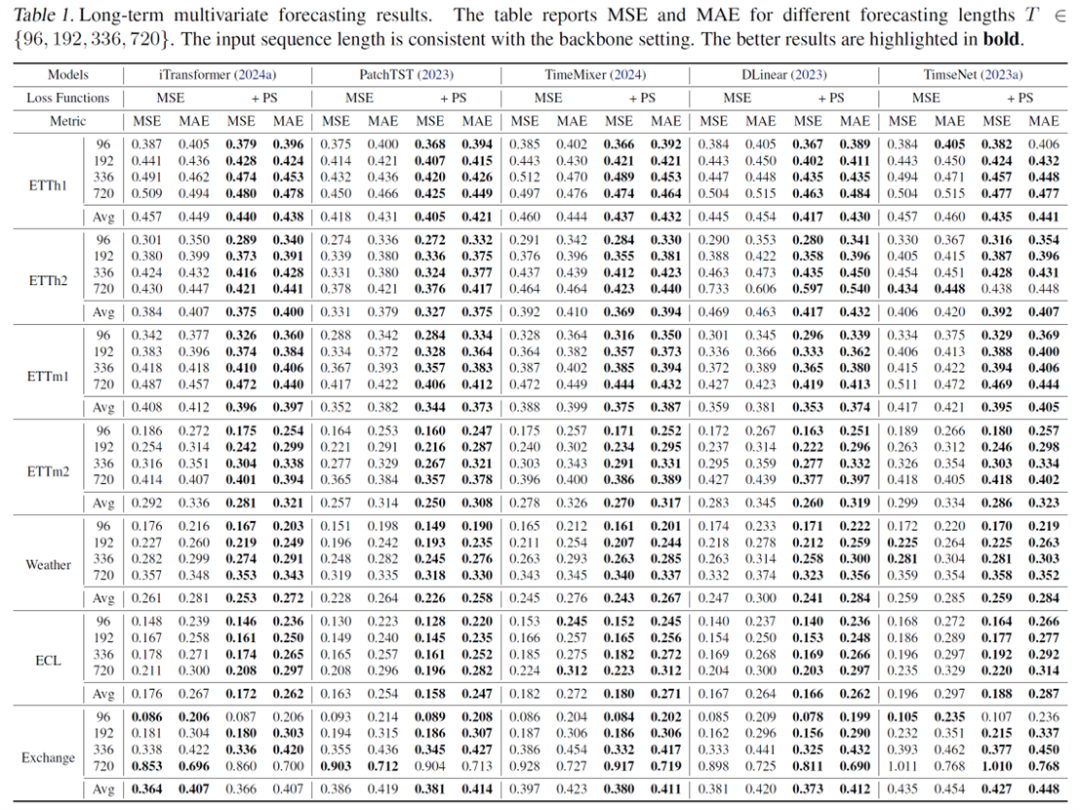
问:除了这三类,还有没有其他在时序结构对齐上可能有效的统计量或距离度量?
答:有啊!我觉得一个很直接的思路是考虑峰值和谷值的对齐。比如,医疗数据心电图的R波,或者地震波的震级,这些关键点的出现时间和幅度,对预测结果的解读至关重要。
* 方法:可以设计一个专门的损失项,比如检测预测序列和真实序列中的峰值(或谷值),然后计算这些峰值对之间的距离(比如时间差和幅度差的加权和)。
* 优势:这能更直观地捕捉序列的“特征事件”,对周期性或突发事件的预测特别有效,因为它直接关注这些“里程碑式”的点。
* 劣势:通用性可能不如均值、方差和相关性,因为它依赖于特定“峰值”或“谷值”的定义和检测算法,而且对于没有明显周期性或峰谷结构的数据,效果可能不佳。而且,如果预测的峰值稍微偏离一点点时间,但幅度对了,怎么惩罚也需要仔细设计。PS Loss那种更宏观的结构对齐,能抓住主要矛盾,这个则更偏向细节。
哈哈哈,除了这些“正经”的统计量,我倒是希望能有一个能衡量“气质”的损失函数!比如说,我们预测的股价走势,除了相关性、方差、均值要对,可能还有一个微妙的“情绪”或“风格”要像原版。比如,如果原始股市是小打小闹,突然预测出来一个暴涨暴跌,那即使相关系数很高,感觉上还是不对劲。
但这可能就太科幻了,毕竟“气质”这东西怎么量化呢?不过话说回来,PS Loss用KL散度来衡量方差分布,有点像在捕捉这种“波动气质”了,毕竟KL散度反映的是两个分布的差异,而不仅仅是单一的方差数值。如果能结合像CNN那种提取特征的方式,是不是可以提炼出更“高级”的时序特征,然后对这些特征做对齐呢?感觉这已经超出统计范畴,有点深度学习的味儿了。
非平稳性嘛,简直是时序预测的“魔鬼”!我听过比较有意思的是“对抗性学习”(Adversarial Learning)在时序数据上的应用。简单说就是,训练一个生成器去生成预测序列,再训练一个判别器去判断生成序列和真实序列是不是来自同一个分布。如果判别器分不出来,就说明生成器学到了真实数据的分布特性,包括它的非平稳性。这跟PS Loss直接去对齐相关性、方差、均值不太一样,对抗性学习更像是让模型“盲测”过关,整体感觉上像就行,PS Loss则更像是给出了具体的“打分项”。各有各的妙处,对抗性学习更玄乎一点。
关于λ的权重分配,这在实际应用中是个典型的超参数调优问题,需要根据具体的业务场景和数据特性来决定。没有一劳永逸的普适值,但有一些经验和方法可以参考:
1. 业务需求驱动:
* 侧重数值精度(λ小,甚至为0):如果你的应用对预测的绝对数值误差要求极高,比如金融交易中对具体价格的毫厘不差,或者工业控制中对某个关键参数的精确预测,那么MSE的权重就应该更高。此时,即使预测趋势稍有偏差,但只要数值非常接近,就认为是有价值的。
* 侧重结构对齐(λ大):如果更关心预测序列的整体趋势、波动模式、周期性以及异常点的捕捉能力,比如宏观经济预测、负荷曲线预测(需要把握峰谷变化)、疾病传播趋势预测(关注波峰出现时机),那么PS Loss的权重就应该更高。在这种情况下,允许预测数值在小范围内波动,但要求其“走势”与真实数据高度吻合。
2. 数据特性分析:
* 如果数据噪声较大,或者突变频繁,纯MSE可能容易过拟合噪声点,此时增加PS Loss的权重可以帮助模型学习更鲁棒的结构。
* 如果数据具有明显的周期性或季节性,且你希望模型能准确捕捉这些模式,那PS Loss中的FAP和相关性损失会很有帮助,应适当提高其权重。
3. 调优策略:
* 网格搜索/随机搜索:这是最直接的方法,设定一个λ的范围,然后通过交叉验证来寻找最优值。
* 贝叶斯优化:更高效的超参数搜索方法,尤其在搜索空间较大时。
* 多目标优化/帕累托前沿:可以将MSE和PS Loss视为两个独立的优化目标,通过生成帕累托前沿来观察不同λ值下两者之间的权衡关系,然后根据业务需求选择一个平衡点。
* 动态调整:某种程度上GDW已经做了类似的事情,但在更高的层次上你也可以尝试在训练的不同阶段动态调整λ,比如初期偏向MSE快速收敛,后期增加PS Loss权重精调结构。但这种方法更复杂,需要仔细设计。
总的来说,λ的设置是一个艺术与科学结合的过程,需要反复尝试和评估。
这是一个很好的拓展性问题,能激发我们对时序相似性度量的深入思考。除了文章提到的三类,确实还有很多统计量或度量方法,各有利弊:
1. 动态时间规整(Dynamic Time Warping, DTW):DTW是一种衡量两个时间序列相似程度的算法,即使它们在时间轴上存在拉伸或压缩,也能找到最佳对齐路径。
* 优势:在形状相似性方面表现卓越,对时间轴上的局部偏移和非线性变形有很强的鲁棒性。
* 劣势:计算复杂度较高($$\mathcal{O}(NM)$$,N和M是序列长度),不适用于大规模或长序列的批处理训练;且DTW不直接可微,难以将其直接作为损失函数进行梯度下降优化,需要做近似或特殊处理。
2. 互信息(Mutual Information):衡量两个随机变量之间相互依赖的程度,可以捕捉到非线性的依赖关系。
* 优势:能够发现更复杂的非线性相关性,不局限于线性相关。
* 劣势:计算复杂,对数据分布的估计依赖较大,且直接作为损失函数同样存在可微性问题和优化难度。
3. Earth Mover’s Distance (EMD) / Wasserstein Distance:衡量将一个分布“转换”成另一个分布所需的最少“工作量”,可以用于比较序列的整体分布。
* 优势:比KL散度对离群值更鲁棒,且能更好地反映两个分布之间的“距离”,尤其在分布没有重叠时表现优秀。
* 劣势:计算成本相对较高,且可能过于关注整体分布,而忽略了序列内部的局部排序或趋势。
4. 格兰杰因果(Granger Causality):虽然更多用于分析因果关系,但也可以看作一种特殊的时序依赖性度量。
* 优势:能够揭示序列间的领先-滞后关系。
* 劣势:要求序列是平稳的,且只能用于线性关系,不适合作为通用结构相似性度量。
文章选择皮尔逊、KL散度和MAE,可能是因为它考量了计算效率、可微性(便于梯度下降)和对时序结构多角度(方向、波动、水平)的捕捉能力,是一个非常实用的组合。
哎呀,非平稳性啊,就是数据老是变来变去,没有个固定模式,比如股价一会儿跌一会儿涨,你不能用一个放之四海而皆准的公式去套。PS Loss靠“分段”来解决,这就像是在说,“虽然全国气温不平稳,但我们可以把全国分成南区、北区、东区、西区,每个区的天气在短时间内还是相对稳定的,那我就在每个区内分别预测。”
其他常见方法呢,除了“差分”让数据变平稳外,还有些模型直接就去捕捉这"不平稳"本身,比如一些基于注意力机制的Transformer模型,它们可以动态地关注序列中不同位置的信息,有点像“哪里重要看哪里,哪段不稳定学哪段”。或者一些混合模型,把平稳部分和非平稳部分分开处理。PS Loss的FAP功能,有点像把区域划分,再用结构损失去细化每个区域,是不是感觉更精准了?
问:在实际项目应用中,我们该如何权衡MSE和PS Loss的权重(也就是那个参数λ)呢?
答:这个问题问到点子上了!作为调参侠,我常常在想这事儿。我个人觉得,决定λ值可以从以下几个维度考虑:
1. 可解释性需求:如果你的模型结果需要给非技术人员看,而且他们更关心趋势和模式,比如“下周温度会不会有大幅波动”,那PS Loss的权重就高一点,因为它的结果在视觉上通常更符合直觉。
2. 异常检测需求:如果你需要用时序预测来辅助异常检测,那么结构对齐能力至关重要。一个好的结构对齐能让你更容易地发现那些不符合正常模式的“异常点”,这时PS Loss会发挥更大的作用。
3. 计算资源限制:PS Loss加入了更多计算(傅里叶变换、多个子损失计算、梯度动态调整),肯定会增加训练时间和资源消耗。如果你的计算资源有限,或者模型本身已经非常庞大,可能就要适当减小λ,避免训练时间过长。
4. 模型稳定性和收敛速度:有时候纯PS Loss可能会导致模型训练不稳定或者收敛慢,因为它的优化目标更复杂。结合MSE,可以提供一个更稳定的优化基线。
我的建议是,先从一个较小的λ值开始,比如0.1到0.5,然后通过可视化预测结果来观察。如果发现趋势和波动匹配得不够好,再逐渐增加λ。这是一个迭代的过程,没有银弹,得根据具体场景“试”出来。
哈哈,这个λ啊,就像是你在点外卖,纠结于是味道要好(MSE,数值对得上),还是卖相要好(PS Loss,结构对齐)。
如果你是那种“只要能吃饱,管它摆不摆盘”的实用主义者,那MSE权重就高点,只要预测值八九不离十就行。
但如果你是个“颜值控”,不仅要好吃,还得拍个照发朋友圈那种,那PS Loss的权重就要拉满了!比如你想预测一个产品的销量走势,具体到每天差个一两单没关系,但你更想知道这个月销量会不会爆,或者下次促销后会不会有个大起伏,那这时候结构对齐就非常重要了。
经验嘛,我觉得可以先从0.5开始,然后根据实际预测出来的图(可视化很重要!)和你对结果的满意度去微调。如果图看起来歪七扭八的,那λ就调大点;如果数值总是差一点,就调小点。调参嘛,就是一门玄学,外加亿点点耐心。
关于非平稳性,确实是时序分析的老大难问题。除了PS Loss的分段思路,还有几种主流方法:
1. 数据变换:比如差分(Differencing),通过将序列转化为其一阶或高阶差分序列来消除趋势或季节性,使其变得平稳。对数变换、Box-Cox变换也可以用来稳定方差。它的思路是直接改变数据,而PS Loss是在损失函数层面做文章。
2. 多尺度/多频率分析:像小波变换(Wavelet Transform)就能在不同尺度上捕获信号特征,可以看作是一种从频率域解决非平稳性的方法,因为它能分离出不同频率的成分。相较于PS Loss基于傅里叶变换做分段,小波更注重多尺度的细节捕捉。
3. 自适应模型:一些模型本身就具备适应非平稳性的能力,比如卡尔曼滤波(Kalman Filter),它能根据实时观测动态更新状态估计。或者在深度学习中,使用更复杂的注意力机制或门控机制(如GRU/LSTM的门),让模型"学"会关注不同时间步的重要性,间接处理局部特性。PS Loss相当于是给这些模型加上了一个“结构老师”,指导它们训练得更准。
PS Loss的独特之处在于,它不是直接变换数据或改变模型结构,而是通过损失函数来"规范"模型的学习方向,让模型在优化数值误差的同时,也兼顾局部结构的一致性,这是一种后验的、更灵活的优化策略。