丰田研究院发布LBM模型,严谨验证机器人通用能力和数据效率,或预示具身智能“GPT时刻”的来临。
原文标题:机器人的「GPT时刻」来了?丰田研究院悄悄做了一场最严谨的VLA验证实验
原文作者:机器之心
冷月清谈:
该研究的核心在于,在近1700小时的机器人数据上训练了一系列基于扩散的LBM,并通过1800次真实世界和超过47000次模拟部署进行严格评估。论文设计了细致的评估流程,引入“任务完成度”等指标,确保了结果的统计置信度。实验结果显示,相对于从头开始训练的策略,LBM提供了显著且一致的性能提升,尤其在应对分布偏移的任务时表现出更强的鲁棒性。
更重要的是,LBM能够在具有挑战性的新任务中,使用3-5倍更少的数据达到与传统方法相似的性能,甚至在相同数据量下获得更优表现。研究还发现,LBM的性能随着预训练数据量的增加而稳步提高,即便预训练数据量远未达到“互联网级”规模,也能带来持续稳定的性能增益。 这一发现预示着通过数据获取与性能自举的良性循环是完全可能实现的。通过混合多样化的真实和模拟数据进行训练,LBM能够处理多模态输入(图像、本体感知、语言提示),并预测连续的动作序列,展现了其强大的通用性和泛化能力。
这些积极的结论似乎预示着机器人领域的通用大规模模型即将到来,让具身智能的“GPT时刻”不再遥远。
怜星夜思:
2、文章里丰田研究院的LBM主要展示了机器人在操作层面的能力,比如双臂协作、纠错等。如果想让机器人具备更广泛意义上的“通用具身智能”,它还需要哪些更深层次的能力?这些能力和LBM这种行为模型之间,又是一种怎样的关系?是LBM的扩展,还是需要完全不同的技术栈?
3、丰田研究院的这项LBM研究,如果未来能够广泛应用,它最有可能给哪些行业带来颠覆性的变革?除了文章中提到的操作任务,你觉得它还能解决工业界哪些目前被忽视,但非常重要的痛点?
原文内容
编辑:冷猫
提到机械臂,第一反应的关键词是「抓取」,高级些的机械臂也就做做冰淇淋和咖啡之类的小任务。
但若要机械臂自主完成繁重且复杂的任务,如布置餐桌、组装自行车,难度便呈指数级上升。这类任务对感知、理解与动作控制的协同提出了极高要求。
近年来,随着视觉 - 语言 - 动作(VLA)模型的迅速发展,机器人已逐步具备整合多模态信息(如图像、指令、场景语义)并执行复杂任务的能力,朝着更智能、更通用的方向迈进。
但是目前 VLA 的研究尚未达到里程碑式的成果,具身智能的「GPT」似乎离我们还很遥远。
直到我看到了这两段视频:
机械臂在现实世界中已经能够实现双臂写作,完成如此复杂的组合任务,并且还能够在操作过程中纠错。这相比过去的 VLA 研究成果有了非常明显的提高。
深入探索了一下这份研究,作者在 VLA 的思路基础上更进一步,在扩散模型策略的基础上,完全构建了一个针对机器人的大型行为模型(Large Behavior Model,LBM),经过训练和微调,便能够实现机械臂自主执行复杂操作中如此令人惊艳的结果。
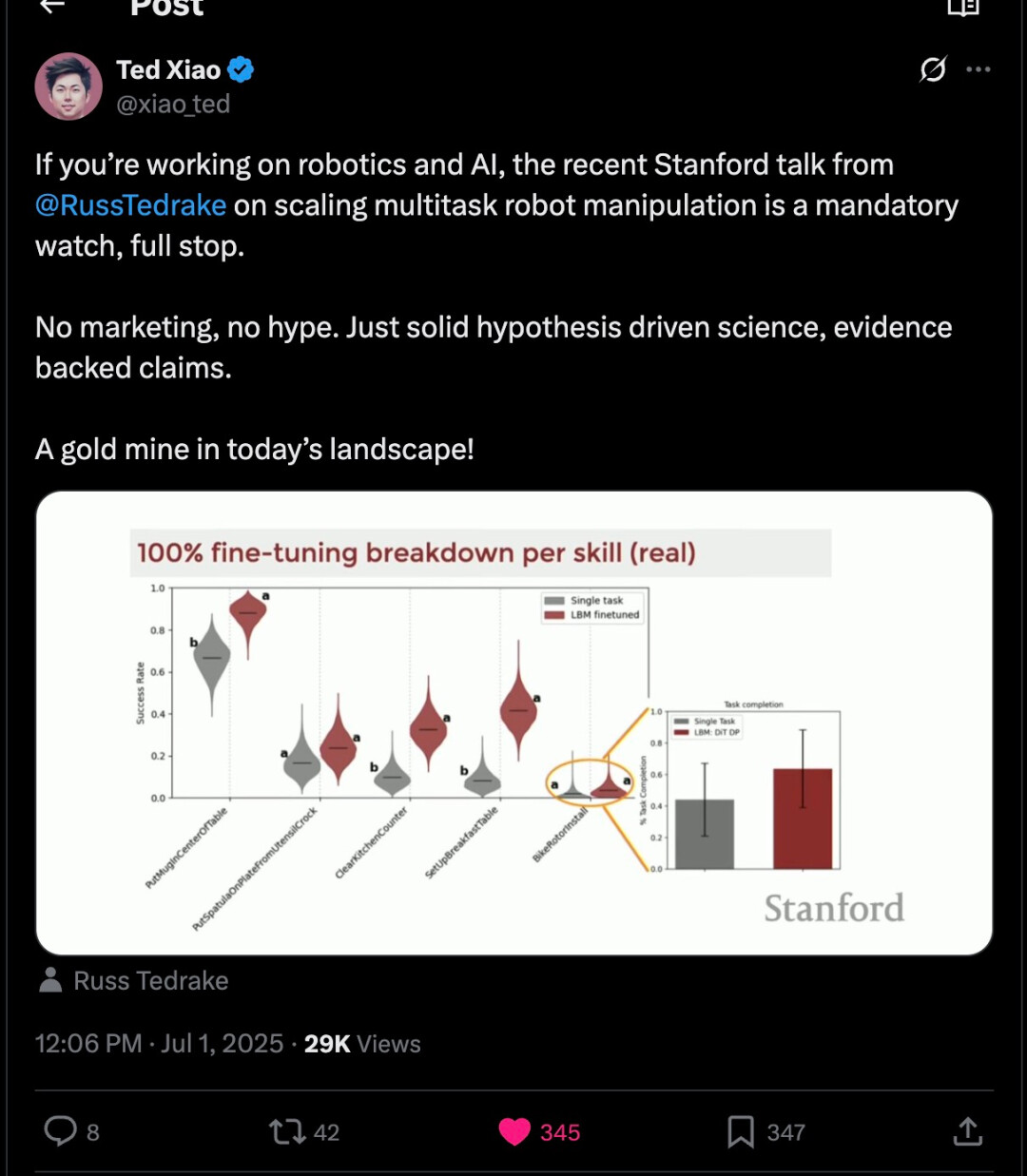
来自谷歌的研究者 Ted Xiao 说:
「如果你从事机器人技术和人工智能领域,最近在斯坦福大学关于扩展多任务机器人操作的视频是必看的,毫无疑问。 没有营销,没有炒作。只有基于坚实假设的科学,有证据支持的断言。 在当今的背景下,这是一个宝藏!」
前英伟达学者 Jiafei Duan 表示:
「我是 TRI 这项工作的忠实粉丝,严格的评估是机器人领域真正进步的催化剂。」
这份工作来自丰田研究院(TRI)的大型行为模型团队。作者之一是麻省理工学院教授,丰田研究院机器人研究副总裁 Russ Tedrake。
据说,Russ 是一位低调但极其严谨的学者,对于这篇论文,仅在推特和领英各发了一则短文进行简要介绍。然而,有限的宣传并未掩盖这项工作的卓越价值 —— 论文本身足以说明一切。
该论文通过在模拟与真实机器人数据集上扩展扩散(Diffusion)策略框架,系统性评估了一类多任务机器人操作策略,称为大型行为模型。论文设计并验证了一套严谨的评估流程,以统计置信的方式分析这些模型的能力。通过盲测与随机试验,在控制环境下将多任务策略与单任务基线模型进行了对比,涵盖仿真与现实实验。

-
论文标题:A Careful Examination of Large Behavior Models for Multitask Dexterous Manipulation
-
论文链接:https://arxiv.org/pdf/2507.05331
-
项目链接:https://toyotaresearchinstitute.github.io/lbm1/
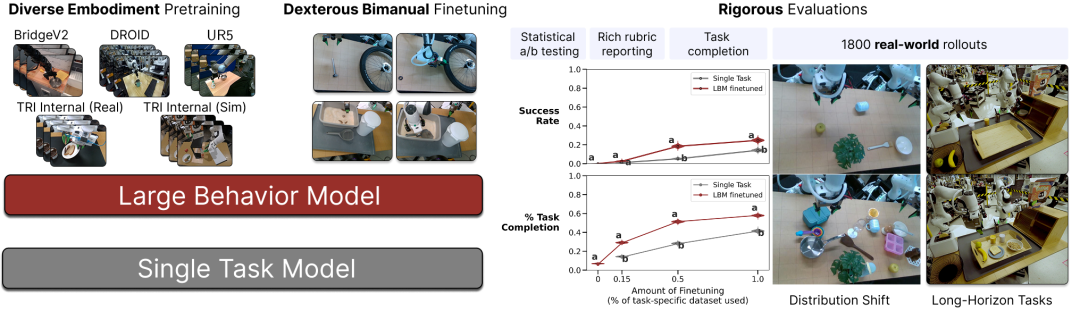
大型行为模型是一类视觉 - 运动策略,基于多样化的模拟与真实世界操作数据进行训练。
采取传统的单任务行为策略的机器人在面对任务变化或训练分布之外的环境时表现出有限的泛化能力。为了克服这种脆弱性,该领域正越来越多地采用 LBM —— 在包含动作级演示的大规模多任务数据集上训练的视觉运动基础模型。尽管 LBM 的研究与开发蓬勃发展,但关于观察到的成功主要是否源于多任务预训练,仍然存在重大不确定性。
为了严谨地研究多任务预训练的影响,论文在近 1,700 小时的机器人数据上训练了一系列基于扩散的 LBM,并进行了 1,800 次真实世界的评估部署和超过 47,000 次模拟部署,以严格研究它们的能力。
论文发现:
-
相对于从头开始的策略,LBM 提供一致的性能提升;
-
在具有挑战性的环境中,LBM 使用 3-5 倍更少的数据来学习新任务,并要求对各种环境因素具有鲁棒性;
-
随着预训练数据的增加,LBM 的性能稳步提高。
即便只有数百小时多样化的数据、每种行为仅有几百条演示,模型的性能依然实现了显著提升。预训练在远小于预期规模的条件下,便能带来持续稳定的性能增益。虽然当前还没有如同「互联网级」的机器人数据量,但令人欣喜的是,性能收益在远未达到那一规模时就已显现 —— 这是一个积极信号,预示着通过数据获取与性能自举的良性循环是完全可能实现的。
这样积极的结论,似乎预示着机器人领域的通用大规模模型的到来,具身智能的「GPT 时刻」还有多遥远?
LBM 架构
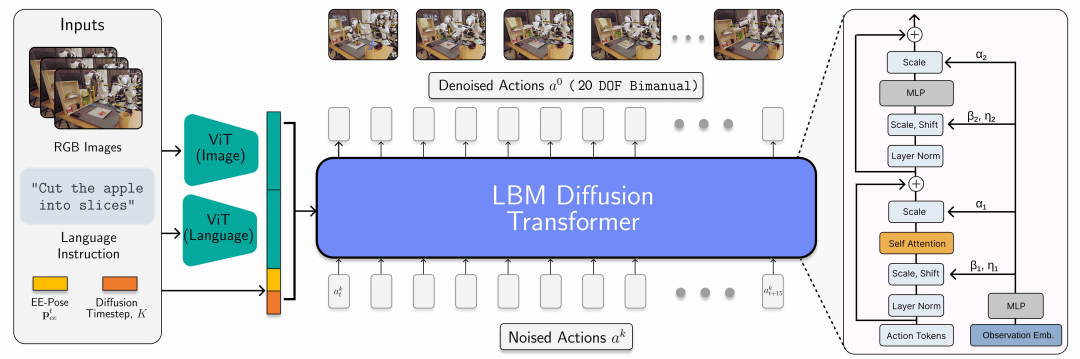
LBM 架构:论文采用了一种 Diffusion Transformer 架构,该模型以语言、视觉和本体感知(proprioception)作为条件输入,并输出 20 维动作序列,覆盖未来 16 个时间步长。
在部署阶段,策略以 10 Hz 的频率运行,机器人会执行前 8 个时间步的预测动作,然后重新规划后续动作。
本文的 LBM(Large Behavior Models)是一类扩展的多任务扩散策略模型,具备多模态的 ViT(视觉 Transformer)视觉 - 语言编码器,并采用基于 AdaLN 的 Transformer 去噪头对编码观察进行条件建模。这些模型能够处理手腕摄像头和场景摄像头图像、机器人本体状态(proprioception)以及语言提示,并预测连续 16 步(1.6 秒)的动作片段(action chunks)。
论文在一个混合数据集上训练 LBM,包含:
-
468 小时的内部采集的双臂机器人遥操作数据,
-
45 小时的模拟环境中的遥操作数据,
-
32 小时的通用操作接口(UMI)数据,
-
以及约 1,150 小时从 Open X-Embodiment 数据集中整理的互联网数据。
尽管模拟数据所占比例较小,但它的纳入确保了可以在模拟环境和真实世界中使用同一个 LBM 检查点进行评估。
实验细节
测试平台
本文的 LBM 在采用 Franka Panda FR3 手臂和最多六个摄像头的物理和 Drake 模拟的双臂工作站上进行了评估 —— 每只手腕最多两个摄像头,以及两个静态场景摄像头。
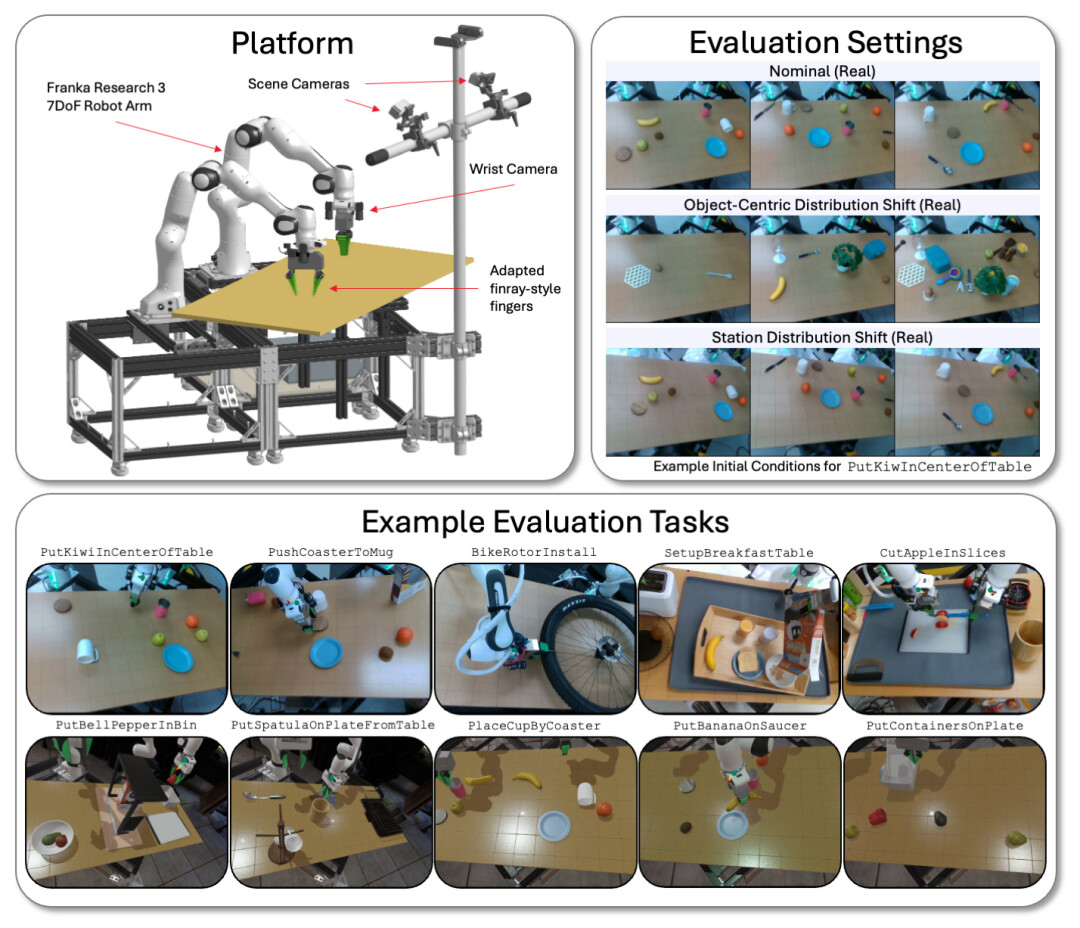
在双手操作平台上,在模拟和现实世界中,针对多种任务和环境条件,评估了的 LBM 模型。
论文衡量策略性能的主要指标包括:成功率(Success Rate)和任务完成度(Task Completion)。
其中,成功率是机器人学习领域的标准评估指标,能有效反映策略能否完成任务的整体表现,但它无法全面刻画策略的细节表现。例如,一个策略「几乎完成任务」与「完全没有动作」在成功率上表现相同,然而实际能力差异极大。为了更细致地区分这些情况,论文引入了任务完成度指标。
具体来说:
-
在真实世界评估中,设计了打分量表(rubrics),用于基于任务的中间目标(milestones)来量化完成度。该评分过程由人工填写,并引入了一套质量保证(QA)流程来确保量表评估结果的可靠性。
-
在仿真环境中,采用自动化谓词(predicates)来判断是否达到各个中间目标,进而计算任务完成度。
尽管报告了绝对成功率,但论文认为相对成功率才是对比不同方法性能的核心依据。因为绝对成功率高度依赖任务本身的设计 —— 例如起始条件的随机性、演示数量的多少都能显著改变任务难度,进而影响最终结果。
因此,论文研究者在实验设计上刻意提高任务难度,期望策略成功率在 50% 左右,以便更清晰地区分方法之间的优劣。不过在实际运行中,成功率可能会显著高于或低于这个目标值。
实验结果
LBM 在「已见」任务上的性能
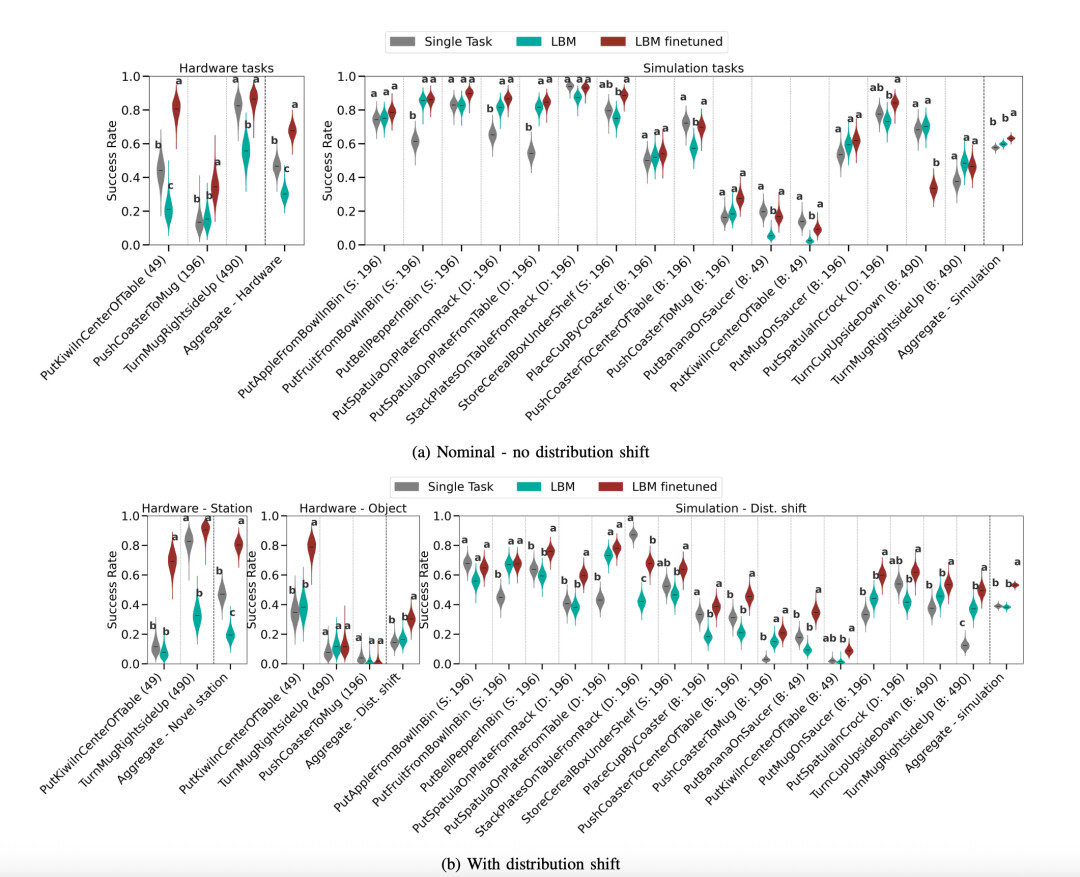
LBM 在真实世界和仿真环境中的「已见任务」表现:(a)无分布偏移,(b)有分布偏移。论文比较了单任务模型、预训练的 LBM 以及微调后的 LBM。
在这一组实验中,研究者们发现:
1. 微调后的 LBM 在「已见任务」上表现优于单任务基线模型。
2. 微调后的 LBM 对「已见任务」的分布偏移更具鲁棒性。
3. 未经微调的 LBM 在「已见任务」中也有非零成功率,且性能与单任务模型相近。
LBM 在「未见」任务上的性能
对于「未见」任务,尤其是那些复杂任务,研究者并不指望预训练的 LBM 能够成功完成。因此只比较微调后的 LBM 与单任务基线模型的表现。
此外,针对这些复杂任务,预期其成功率较低,因此更侧重于通过任务完成度(task completion)图来获得直观见解。
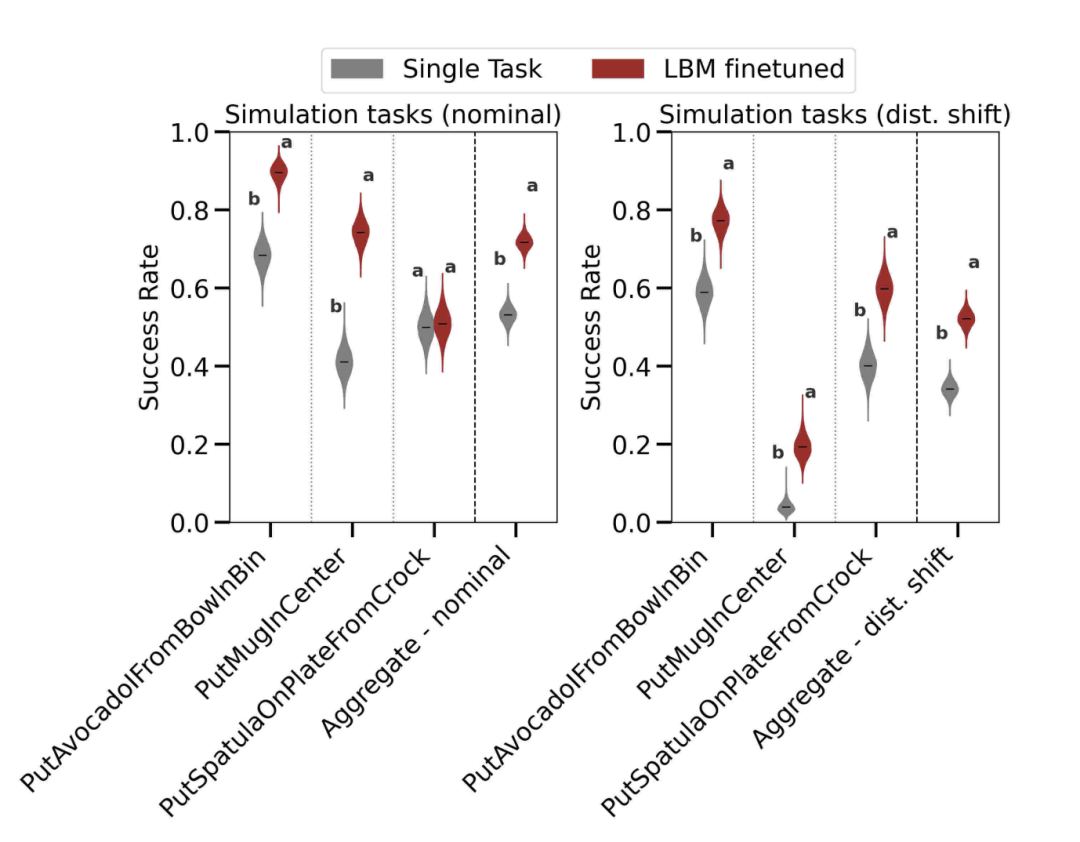
LBM 在来自仿真训练集场景的「未见」仿真任务上的表现。左图:在正常条件下进行评估。右图:在分布偏移条件下进行评估。
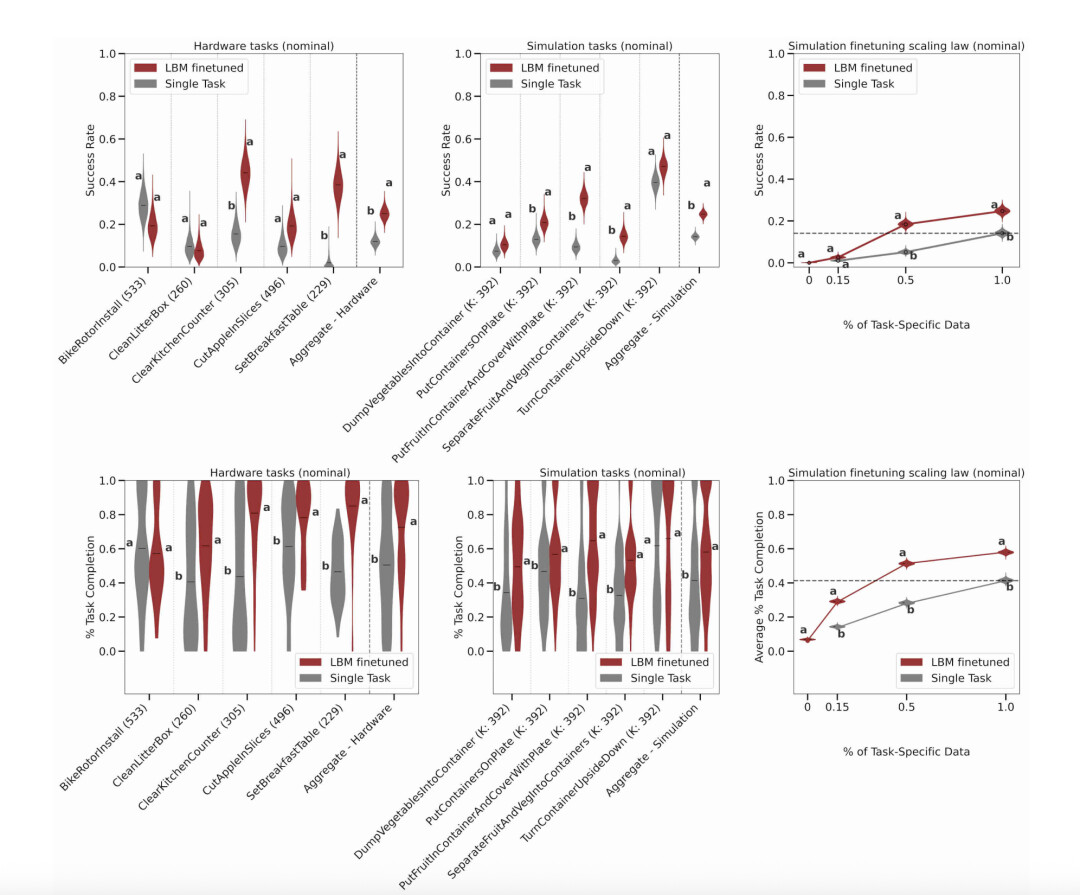
LBM 在现实世界和仿真环境中「未见」任务下的表现(在正常条件下评估)。论文将单任务基线方法与微调后的 LBM 进行对比。上排展示的是成功率结果,下排展示的是任务完成度结果。
在「未见」的任务评估中,研究者得出结论:
1、微调后的 LBM 在「未见」任务上优于单任务基线模型。
2、微调 LBM 达到与单任务基线模型相似的性能所需的任务特定数据更少。
综合来看,通过插值可估算出,若对 LBM 进行微调,仅需不到 30% 的任务特定数据即可达到从零开始训练所需全部数据的效果。
并排比较设置早餐桌的模型:(左) 单任务基线,(右) LBM。
预训练规模法则
这是这篇论文中作者最喜欢的图表,它概括了所有内容。
这个图表比较了在训练新任务之前使用不同数量的预训练数据时的性能:0%(即单任务),25%,50% 或 100% 的 TRI 数据,然后是 100% 的 TRI 数据加上整理的所有开源机器人数据(红线)。
「任务完成分布如此紧密,而且随着数据量的增加,趋势如此一致,这真是太棒了。」
结果表明,通过预训练,可以用更少的数据量训练出新的技能,或者使用相同的数据量并获得更好的任务性能。而且,随着数据量的增加,这些优势似乎会持续下去。
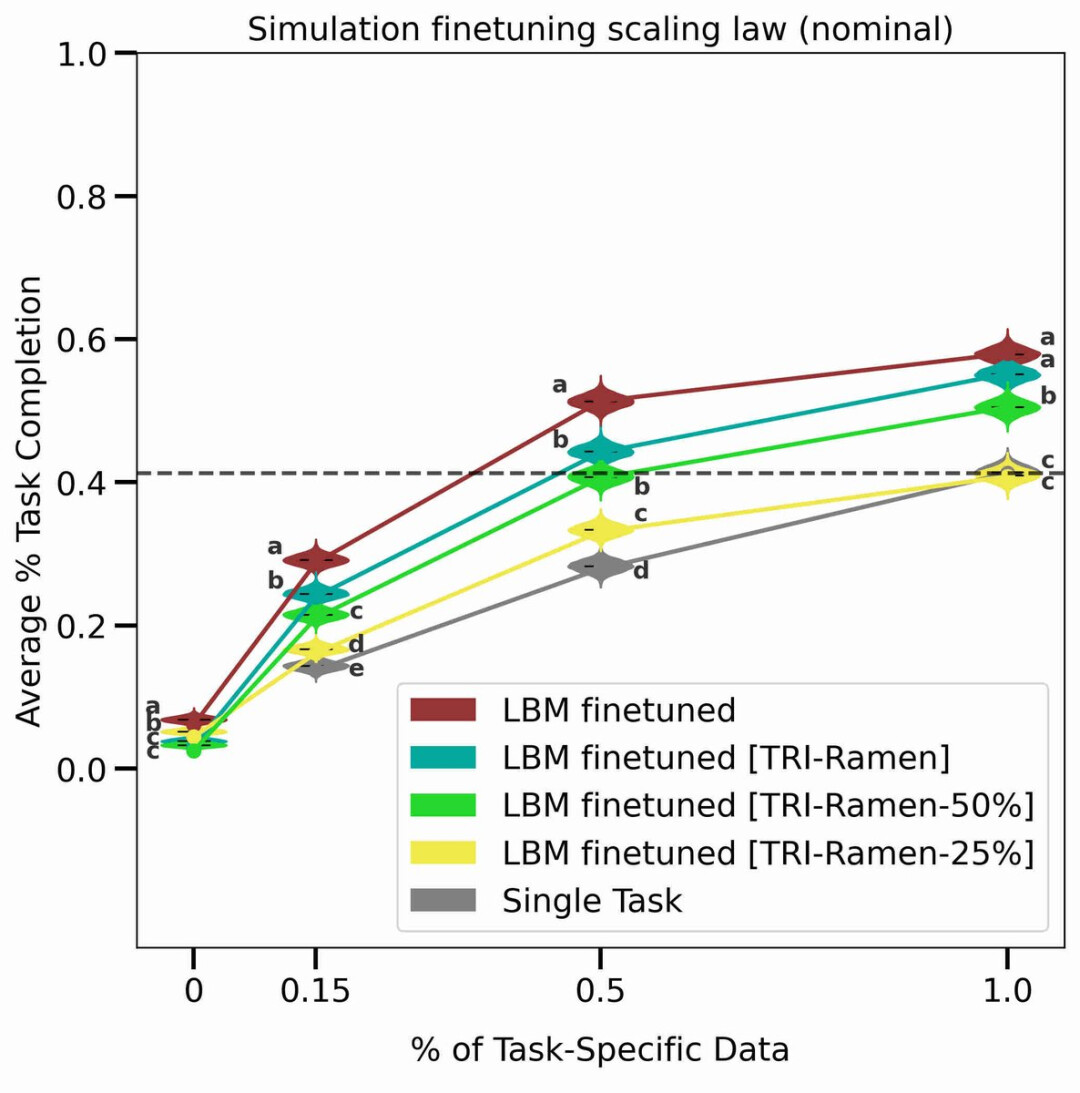
在标准条件下对五个模拟环境中的「未见」任务进行评估,并报告所有任务的平均任务完成度指标。
论文用极其长篇的篇幅,系统地阐述了实验流程、平台设计、仿真与真实世界评估细节、数据分析方法以及数据集构建等各个方面,做了大量的完备的实验,最终凝练成 Russ 推文中的:「LBM 有效!」
论文包含LBM完整架构与训练策略,海量实验细节与评估细节,请参阅原论文。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com