双活架构下数据库访问是否应使用智能DNS?本文深入分析其潜在问题和利弊。
原文标题:双活架构下应用访问数据库是否适合使用智能DNS
原文作者:牧羊人的方向
冷月清谈:
怜星夜思:
2、既然文章不建议数据库直接走智能DNS,那在双活架构下,数据库的高可用和负载均衡,现在业界主流或者说更靠谱的方案是啥?除了文里提的那些(如RAC+DataGuard),还有没有其他更先进的做法?
3、文章提到了用智能DNS可能导致分布式数据库出现“跨中心流量写入增加”。这个“增加”具体会对系统带来哪些实际影响?比如,除了带宽压力,还会不会影响延迟、一致性或者导致其他什么意想不到的问题?
原文内容
智能DNS已经广泛应用在系统的高可用架构设计中,实现故障场景下的自动切换。本文主要介绍智能DNS的基本概念和特点,并分析应用双活架构下应用访问数据库是否适合使用智能DNS,以解答一些争议性的话题。
1、智能DNS基本概念
智能DNS(也称为全局负载均衡-GSLB)是一种高级DNS解析服务。它可以根据域名查找IP地址,还会根据预先配置的策略和实时检测到的信息(如服务器健康状态、负载、地理位置、网络延迟、源IP地址等)动态返回最“优”或最符合策略的IP地址。其核心组件包括:
-
权威DNS服务器: 接收用户的DNS查询请求。
-
策略引擎: 根据配置的策略(如地理位置、轮询、加权、故障转移等)决定返回哪个IP地址。
-
健康检查模块:持续主动探测后端服务器(或服务端点)的健康状态(如HTTP/HTTPS/TCP/Ping响应)。
-
数据中心/节点信息库: 存储后端服务器的IP地址、状态、位置等信息。
智能DNS能够根据负载均衡算法动态的将流量分配到负载较轻的服务器上,并且可以当某个服务器出现故障时候,可以快速地将流量切换到备用服务器,确保服务的连续性和稳定性。
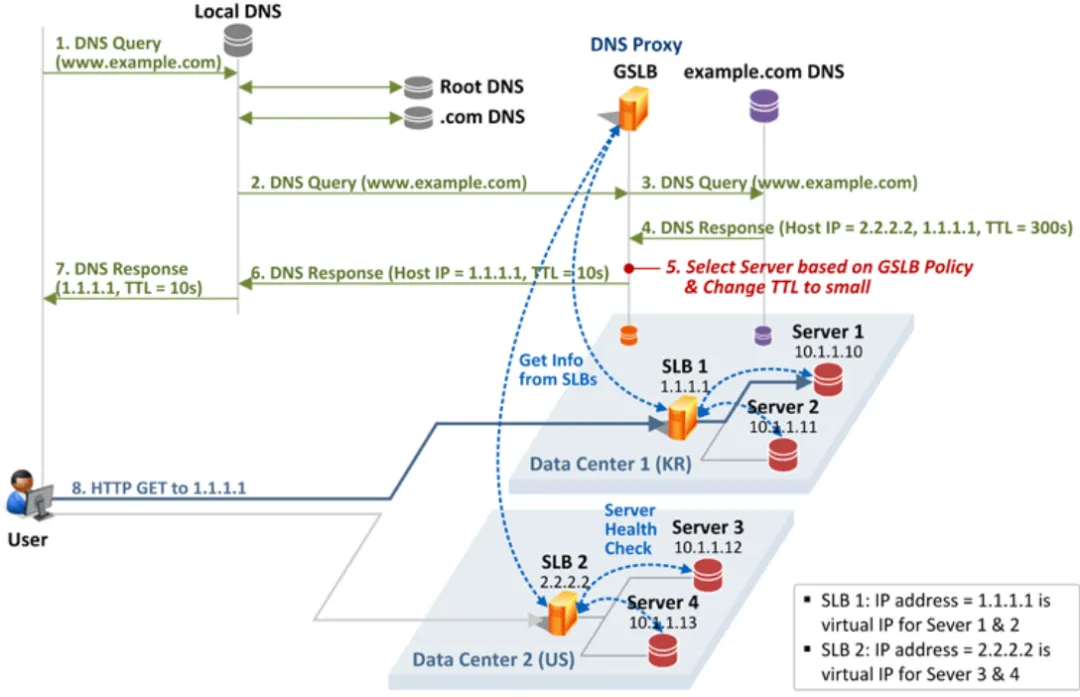
智能DNS解析过程如图所示,分为以下步骤:
-
用户在客户端发起域名(www.example.com)访问请求,首先会检查本地缓存,如浏览器缓存是否有记录,如有则直接返回IP地址;操作系统本地的DNS缓存;操作系统的hosts配置文件是否存在静态映射。然后会向本地DNS服务器进行递归查询,经过根服务器查询->TLD服务器查询->权威服务器查询,返回域名的记录。
-
向智能DNS发起域名www.example.com的查询请求;
-
智能DNS扮演起proxy的角色,将查询请求发送给DNS服务器;
-
DNS服务器中该域名配置了两个IP地址,将结果返回给智能DNS;
-
智能DNS根据自己的策略选择了最优的IP地址;
-
智能DNS将选择的返回给本地的DNS;
-
本地的DNS将智能DNS服务器返回的最优IP地址缓存并返回给用户;
-
用户客户端基于返回的IP地址与目标服务器建立连接(如TCP三次握手),完成域名解析过程。
在以上域名解析的过程中,智能DNS会根据定义好的策略选择最优的IP地址返回给请求方。
智能DNS的分发策略有多种,包括负载均衡算法(轮询、最小连接等)、地理位置优先、基于健康状态的优先级、业务流量比例等。下面重点介绍常用的本地优先和基于业务流量比例的策略。
本地优先是将用户请求路由到地理位置上距离用户最近,或者网络延迟最低的数据中心,以降低网络延迟并提升访问速度。对于外部用户的访问,本地优先策略的关键是智能DNS服务器内置IP地址库,记录IP地址段与地理位置的对应关系。当用户发起DNS请求时,系统提取用户IP地址,通过查询IP地址库确定其所在地区,并将 “最近”节点的IP地址返回给用户的本地DNS服务器。
对于内部的应用间通过域名访问时,比如生产中心的应用基于本地优先的策略优先访问的是本地的DNS并解析本地的服务地址。在内部客户端服务器上建议配置DNS服务器的IP地址顺序,优先将本地的DNS服务器地址放在前面,这样可以优先解析到本地的DNS服务。
本地优先策略的好处是用户可以直接连接最近的节点,减少网络传输时间,提升页面加载速度和响应性能。适用于内容分发网络CDN、多活的数据中心访问流量,将特定区域用户的请求锁定在本地数据中心。
自定义流量比策略允许管理员根据业务需求,将流量按预设比例分配至不同节点。例如,将70%流量导向生产节点,30%导向同城节点,以实现负载均衡或A/B测试。同时智能DNS有健康检查的机制,如果一个节点宕机,其权重会被忽略,流量将按剩余健康节点的权重比例重新分配。
基于流量的权重配置可以是静态配置,也可以通过API动态调整,实现节点流量的精细化管控,适合灰度发布/蓝绿部署验证、多数据中心同时承载业务流量的场景。
需要注意的是这里的流量比是一个宏观层面的统计,智能DNS会确保返回各节点IP的比例大致符合预设的权重比。并且如果没有配置会话保持或持久化,单个用户的多次请求可能被分配到不同节点。
智能DNS是SLB基础之上的高级特性,实现全局的负载均衡策略,能够实现故障自动转移、根据不同的策略分配流量、将用户访问路由到最近的节点提升响应速度。对于用户或应用客户端而言,只需要配置一个域名,由DNS解析最终的访问地址,IP地址发生变化对客户端或用户而言是透明的。
不过智能DNS的使用也有缺点,如缓存的时效性受限于TTL的配置,如果TTL配置过短会增加DNS服务器的负担,而TTL过长会增加故障转移的时间;智能DNS的动态路由可能导致客户端连接到不同的数据中心的节点,尤其是对于分布式数据库,可能会存在数据不一致;不理解上层的应用协议,只做IP层的决策,无法基于数据库的协议状态做决策。另外对于数据库这种长连接访问,在智能DNS故障时可能存在故障恢复时间过长的问题。
2、双活架构下智能DNS使用
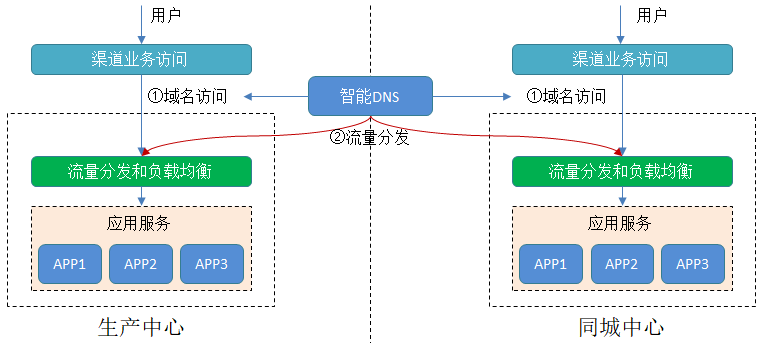
对于应用层是非常适合使用智能DNS的,通过智能DNS可以根据用户地理位置、数据中心负载和健康状态,将用户请求智能地分发到数据中心中的应用实例。
-
对于生产同城双活的应用,使用智能DNS按照不同的数据中心配置流量比例进行流量分发,并且通过API灵活的调整流量比例和切流,应用于版本站点级部署验证、滚动升级、容灾切换等场景。
-
对于内部应用系统间访问,通过配置本地优先的策略,本地的应用会优先访问本地的服务,可以减少网络传输时间,提升访问速率。
在应用双活部署架构下,应用层的访问是竖井式的,生产和同城的业务流量按照“业务流量->应用负载均衡->应用服务->数据库负载”这样的数据链路访问。当生产站点出现故障时或整个链路中某个节点出现异常时,只需要将上层的流量进行切换,即可完成站点级的应急。对于数据库层的流量或者高可用由数据库层自己去保证,主站点出现异常时,应急切换到同城站点即可。
1)传统集中式数据库的访问
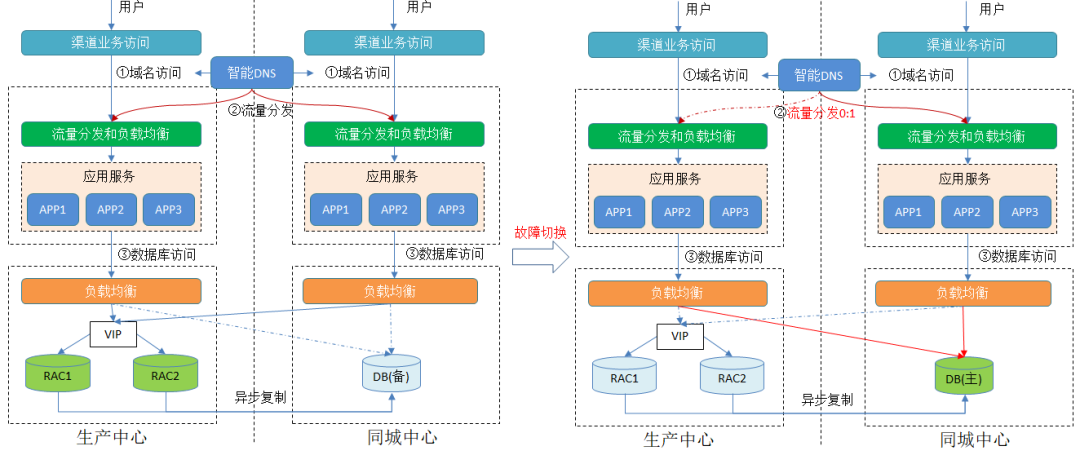
传统的集中式数据库如Oracle本地站点是RAC架构,同城通过dataguard实现异步复制,生产同城不能保证RPO=0,当生产站点出现异常时,将业务流量切换到同城访问。应用层通过负载均衡的方式接入,日常状态同城站点的后端成员是disable状态,同城站点的应用会跨站点访问生产主节点。当需要切换到同城站点时,再将成员启动并disable生产站点的节点,这样完成整个计划内或故障的切换流程。
2)分布式数据库访问
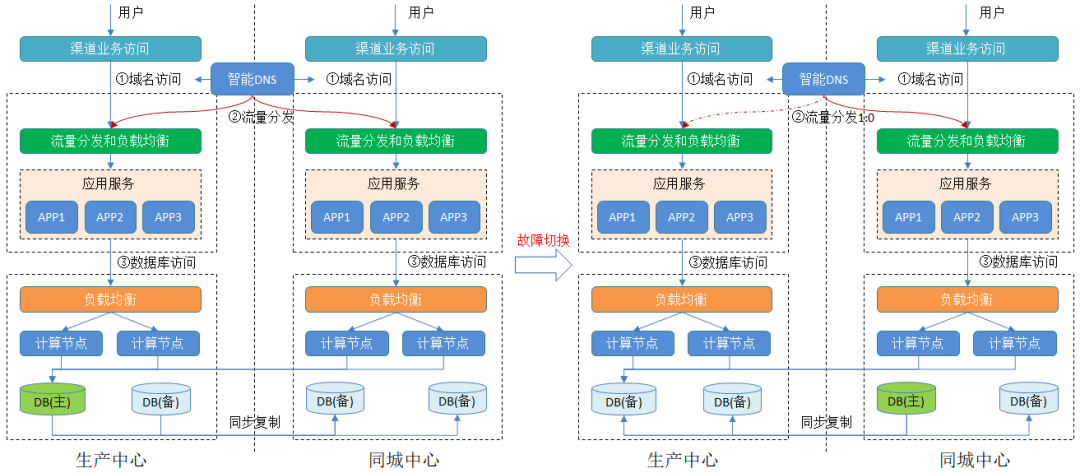
分布式数据库下,同城通过数据库的同步复制确保RPO=0,当生产主站点出现异常时,将业务流量切换到同城访问。应用层也通过负载均衡的方式实现竖井式接入,本站点的应用访问本站点的负载均衡,生产和同城的负载均衡都是可用状态,同城计算节点到数据主节点是跨站点访问。当业务链路中的某个节点(如应用服务异常、计算节点、负载均衡设备等)异常时,直接通过上层的应用切流完成同城切换。如果数据库主站点异常,触发数据库层的同城站点切换,此时主节点切换到同城,上层的业务流量也同步进行切换。
现在回到关键问题,应用层访问数据库是否适合通过智能DNS的方式访问,在技术层面使用智能DNS有几点潜在的问题。
1)数据库连接的持久性和DNS缓存/TTL的冲突
数据库层是长连接访问的,连接建立后可能持续几分钟或更长时间,但是智能DNS的故障转移依赖于客户端重新发起DNS查询。如果在数据库连接活跃期间,后端数据库发生故障且智能DNS已更新记录,现有的数据库连接不会自动重定向或恢复,它们会中断。此时应用需要感知到连接中断,并重新尝试建立连接,进行DNS查询。如果此时DNS缓存已过期或客户端TTL刷新,需要进行新的DNS查询才能获得更新后的健康节点IP。这个过程依赖于应用的重试逻辑和DNS缓存的失效,不是无缝透明的故障转移。TTL导致的延迟可能显著延长数据库不可用的时间窗口。
2)数据库协议感知缺失
智能DNS基于网络层(IP)和基础应用层(HTTP/TCP Ping)健康检查工作,它无法理解数据库特有的状态,如数据库实例是主库还是备库、数据库当前的负载是否过高、数据库进程是否假活无法响应SQL请求等。而通过负载均衡的方式可以支持数据库协议级别的检查(如执行SELECT 1 FROM DUAL),并且可以动态感知到后端负载压力的变化。
3)跨中心的流量写入增加
在分布式数据库架构中,配置智能DNS可能将生产中心应用访问数据库的流量接入到同城中心,或者相反,从而增加了应用访问数据库的跨中心的流量访问。尤其是在批量处理和复杂查询的大流量业务场景下,跨中心的流量带宽会承压,进而带来更为严重的故障。
4)连接池的管理
应用通常使用连接池访问数据库,使用智能DNS后连接池的连接可能指向不同的数据库IP。当节点异常时,智能DNS解析切换IP后,连接池中指向旧故障IP的连接都变成了无效连接。连接池需要及时驱逐这些无效连接并创建指向新IP的连接。这增加了连接池管理的复杂性,并且切换期间可能导致应用性能下降或短暂错误。
1)传统集中式数据库
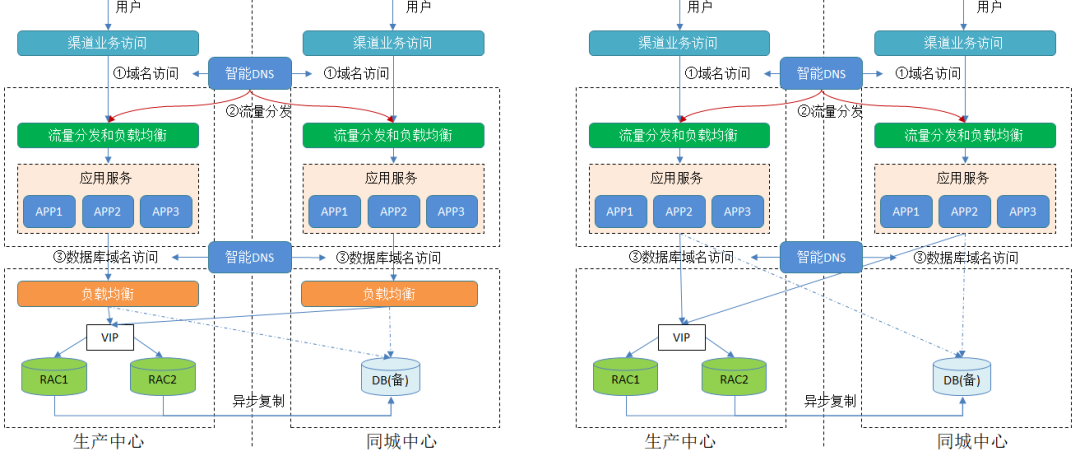
对于传统集中式数据库,如果在数据库的负载均衡之上再加一个智能DNS(如左图)必要性不大,因为负载均衡已经对数据库节点进行了可用性配置,两个站点的负载均衡是对等的。如果通过智能DNS直接将域名绑定到后端的数据库节点上(如右图),同样存在负载探测不精准、长连接和DNS缓存失效的问题。
2)分布式数据库
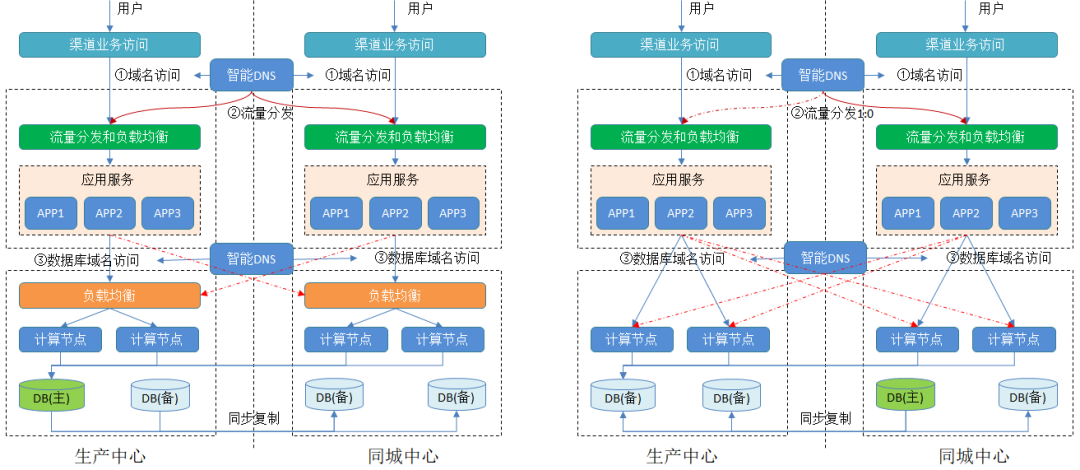
对于分布式数据库,如果在数据库的负载均衡之上再加一个智能DNS(如左图),可能会存在本地解析异常的跨站点流量访问,尤其是在批量处理和复杂查询的大流量业务场景下会引发站点级的网络带宽瓶颈。如果通过智能DNS直接将域名绑定到后端的数据库节点上(如右图),不仅负载管理上没有负载均衡设备灵活,而且存在多个计算节点解析缓慢的问题,同时也可能存在跨站点的流量访问。
总而言之,如果智能DNS的引入是为了解决单中心负载均衡故障能够自动切换,其实从上层的应用进行切流更符合应用层双活的设计初衷。并且引入智能DNS又带了新的故障点,如果智能DNS故障了,应用的连接访问也会出现问题。
参考资料:
-
https://cloud.tencent.com/developer/article/2094030