TPAMI 2025 SHIP范式:引入协同高阶交互,突破传统多模态图像融合瓶颈,显著提升融合效果。
原文标题:TPAMI 2025 | 基于协同高阶交互作用多模态图像融合
原文作者:数据派THU
冷月清谈:
SHIP范式创新性地从空间和通道两个维度系统研究多模态图像的协作关系:
1. **空间维度**:通过将频域融入自注意力机制,将计算复杂度高的矩阵乘法转化为高效的逐元素运算,首次实现从二阶交互向任意N阶交互的扩展,有效捕捉不同粒度的互补空间信息。
2. **通道维度**:扩展了传统的Squeeze-and-Excitation(SE)块,使其从一阶均值提升为能进行高阶通道交互,更深入地区分和探索源图像间复杂的相互依赖关系。
此外,论文还提出了SHIP的增强版本SHIP++,通过残差信息记忆机制、交叉阶信息整合机制和交叉阶注意力演化机制,进一步加强了跨模态信息交互表示,显著提升了模型性能。综合实验在全色锐化和红外与可见光图像融合等任务中验证了SHIP/SHIP++范式挖掘多模态协同效应的强大能力,性能超越了现有方法。
怜星夜思:
2、SHIP范式在全色锐化和红外与可见光图像融合中表现出色。那么,这种基于高阶交互的范式,是否可以直接或者经过简单修改就能应用到其他差异更大的多模态融合任务中?比如,医学图像融合(MRI+PET),或者遥感图像融合(光学+SAR)?这些任务可能会遇到哪些新的挑战?
3、论文中提到,通过将频域融入自注意力机制,将矩阵乘法的计算复杂度从二次降低为更高效的逐元素运算,从而实现高阶交互。这给我们一个启发:在当前的深度学习领域,除了这种频域转换,还有没有其他更普适的数学方法或计算技巧,能够在不牺牲模型表达能力的前提下,大幅降低现有计算密集型操作的复杂度,从而实现类似的“效率飞跃”?
原文内容

来源:计算机书童本文约3100字,建议阅读10分钟
多模态图像融合旨在通过整合和区分来自多个源图像的跨模态互补信息,生成融合图像。
论文信息
题目:Probing Synergistic High-Order Interaction for Multi-Modal Image Fusion
探索多模态图像融合中的协同高阶交互作用
作者:Man Zhou, Naishan Zheng, Xuanhua He, Danfeng Hong, Jocelyn Chanussot
论文创新点
-
提出SHIP范式:论文提出了协同高阶交互范式(SHIP),创新性地在空间和通道维度引入高阶交互作用,系统地研究多模态图像在空间细粒度和全局统计方面的协作关系,从而全面探索多模态间的协同效应。
-
设计高效高阶空间交互:通过将频域融入自注意力机制,把矩阵乘法的计算复杂度降低为更高效的逐元素运算,进而实现从二阶交互扩展到任意阶(N阶)交互,有效捕捉不同粒度的互补信息,丰富特征多样性。
-
设计高阶通道交互:对Squeeze-and-Excitation(SE)块进行扩展,使其从一阶通道交互提升为高阶通道交互,基于全局统计探索源图像间的协同相关性,深入区分不同模态间复杂的相互依赖关系。
-
改进提出SHIP++:对SHIP模型进行改进,提出SHIP++,通过残差信息记忆机制、交叉阶信息整合机制以及交叉阶注意力进化机制,增强跨模态信息交互表示,进一步提升模型性能。
摘要
多模态图像融合旨在通过整合和区分来自多个源图像的跨模态互补信息,生成融合图像。虽然具有全局空间交互的交叉注意力机制前景看好,但它仅捕捉二阶空间交互,忽略了空间和通道维度上的高阶交互。这一限制阻碍了多模态之间协同效应的挖掘。
为了弥合这一差距,作者引入了协同高阶交互范式(SHIP),旨在从两个基本维度系统地研究多模态图像之间的空间细粒度和全局统计协作:1)空间维度:作者通过逐元素乘法构建空间细粒度交互,这在数学上等同于全局交互,然后通过迭代聚合和演化互补信息来促进高阶形式,提高效率和灵活性。2)通道维度:在基于一阶统计量(均值)扩展通道交互的基础上,作者设计了高阶通道交互,以基于全局统计促进源图像之间相互依赖关系的识别。作者进一步引入了SHIP模型的增强版本,称为SHIP++,它通过跨阶注意力演化机制、跨阶信息整合和残差信息记忆机制,增强了跨模态信息交互表示。利用高阶交互显著提高了模型挖掘多模态协同效应的能力,在两个重要的多模态图像融合任务——全色锐化和红外与可见光图像融合中,通过各种基准测试的综合实验表明,其性能优于现有方法。
四、方法
(一)总体框架
如图2所示,所提出的范式操作如下:给定一幅红外图像 和一幅可见光图像 ,作者使用针对每个模态的单独卷积层提取相应的浅层特征,得到 和 。然后,这些模态感知特征经历一系列核心的协同高阶交互范式(SHIP),同时纳入空间和通道维度。这个过程探索两个模态在空间细粒度细节和全局统计方面的协同作用。最后,这些特征被投影回图像空间,生成融合结果 。

融合过程特别针对YCbCr颜色空间中的Y通道,遵循先前工作[68], [69]的方法。总之,该范式可以表述如下:
其中, 和 表示特征提取器,L表示作者的SHIP的迭代次数。在全色锐化中,该范式表示为 。
(二)高阶空间交互
-
回顾自注意力:自注意力机制是Transformer[16]的关键组成部分,通过键、查询和值组件之间的矩阵乘法促进二阶空间交互。这个过程使模型能够基于查询模态动态区分和聚合互补信息。对于红外与可见光图像融合,查询Q、键K和值V通过以下方式推导得出:
其中, 、 和 表示应用于投影模态感知特征表示的线性变换。以输入 为中心捕获二阶空间交互的自注意力机制,通过这些组件之间的点积运算实现:
其中, 表示键的维度, 表示点积运算, 是相关矩阵, 表示自注意力模块的输出,捕获关于输入特征 的二阶空间交互。
然而,尽管点积运算有效,但由于其二次时间复杂度,会带来巨大的计算开销,使得在级联自注意力机制中进行高阶操作不切实际。
-
等效高效形式:A的每个元素可以通过内积重新定义: , , , 表示内积。卷积定理指出,两个信号在空间域中的相关性或卷积等同于它们在频域中的哈达玛积,如图4所示。
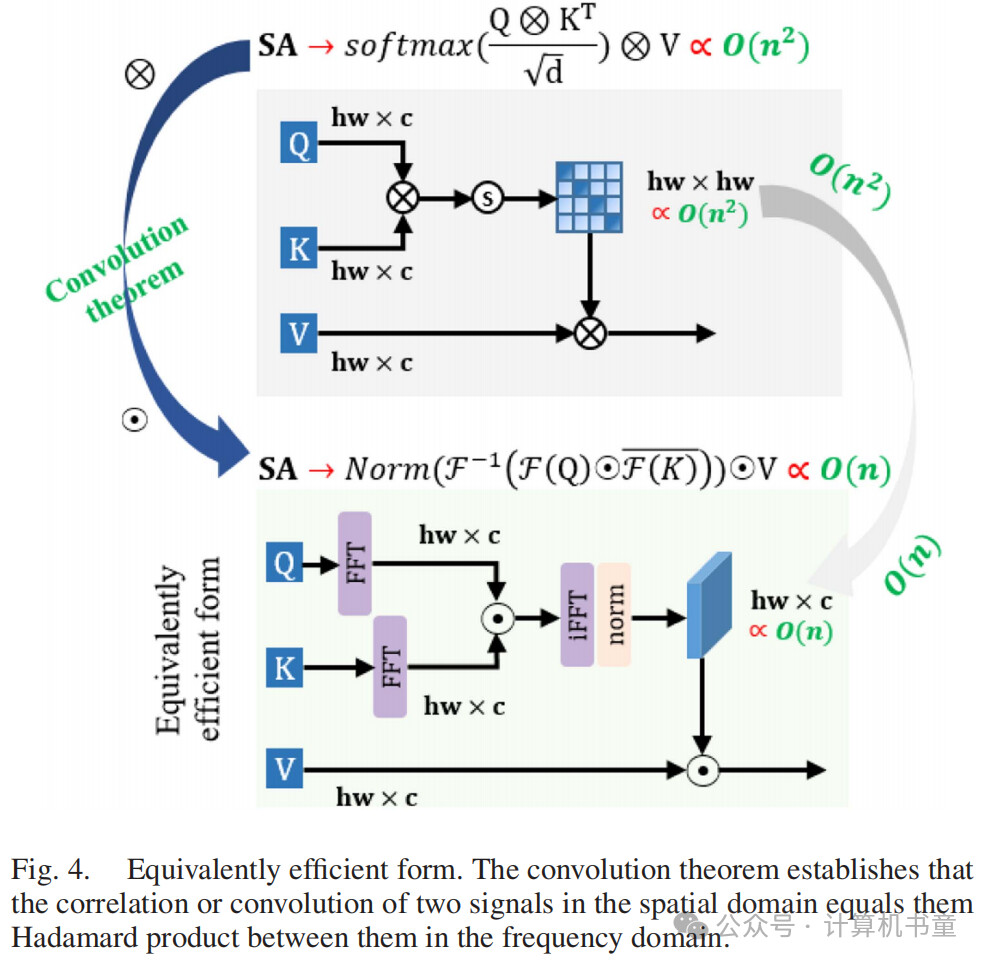
为了利用这一性质,作者将频域整合到自注意力机制中,将矩阵乘法的计算复杂度降低为更高效的逐元素操作。首先,作者使用快速傅里叶变换(FFT)将模态感知特征 和 变换到频域。相关性计算如下:
其中, 和 分别表示FFT和逆FFT, 表示哈达玛积, 表示共轭转置操作。此外,获得具有二阶空间交互的整合特征:
其中,Norm表示应用于A的层归一化。
-
深入高阶形式:最近的方法,如[70], [71],强烈倾向于采用自注意力机制。然而,这些方法,常见于级联自注意力块中,往往围绕查询特征生成多个二阶交互,而不是实现高阶建模。形式上,L个级联自注意力的递归格式可以表示为:
其中, 。显然,这个过程仅捕获关于输入特征 的二阶交互,同时带来巨大的计算成本。
相比之下,基于等效高效形式,作者超越二阶交互,在保持效率的同时将范围扩展到任意阶交互(N阶)。具体来说,对于每个第i次迭代,作者将(5)扩展为以下高阶公式:
其中, 。这个公式使作者能够有效地捕获高达N阶的交互。
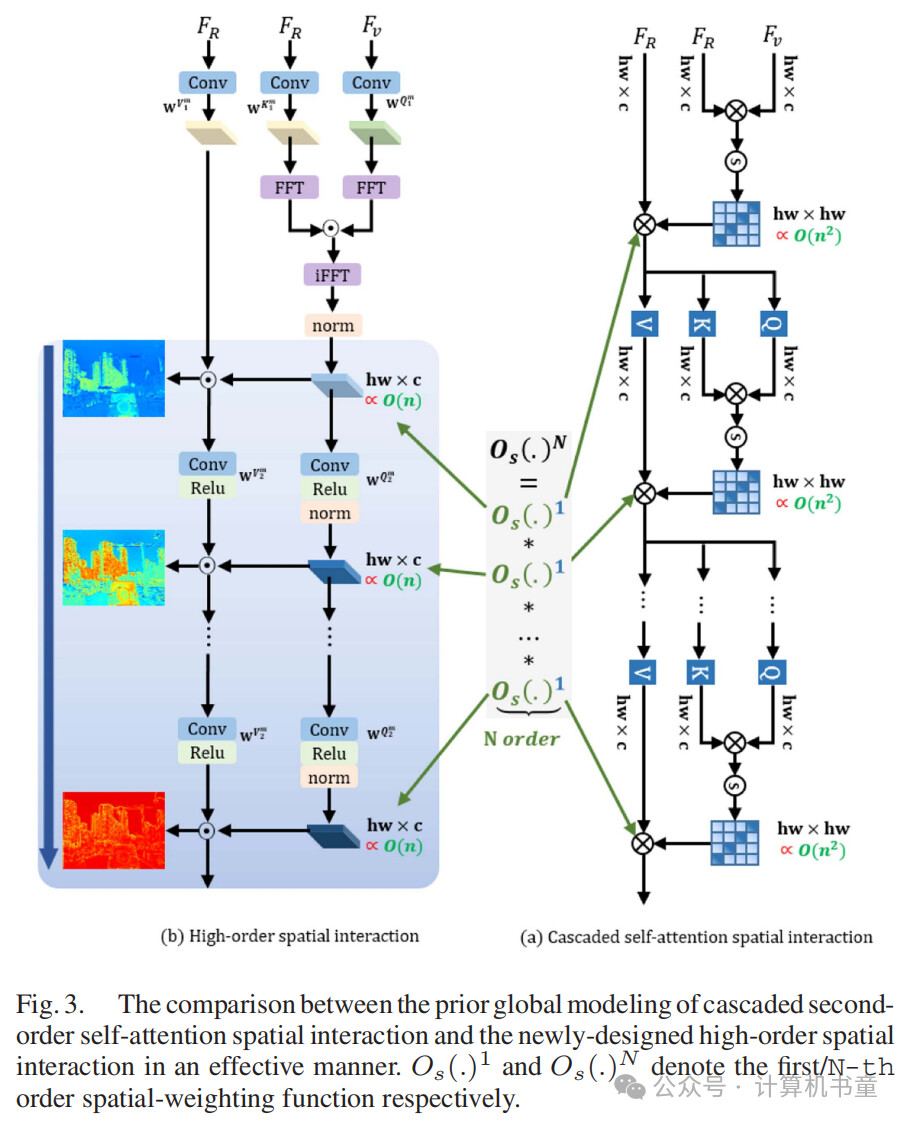
一般来说,对于图3中具有L的传统Transformer链,序列展开如下:
相比之下,作者的高阶建模将其替换为:
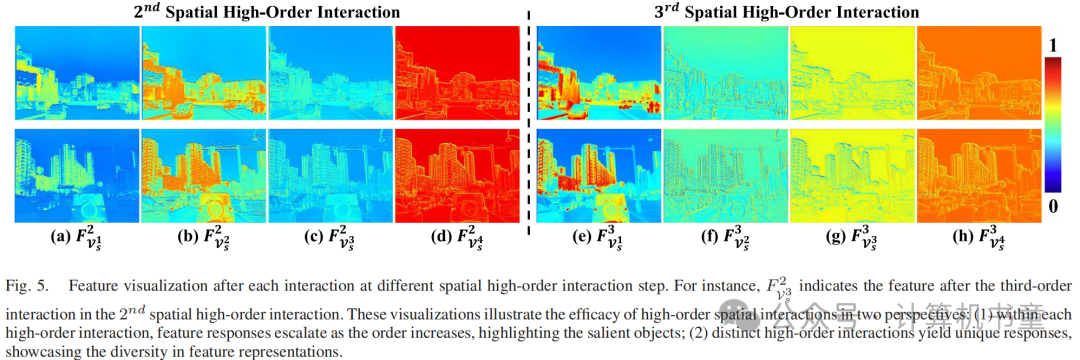
实际上,这种修改使作者能够在每次迭代中捕获高达N阶的交互。如图5所示,每个空间高阶交互中的不同阶整合了不同粒度的互补信息。此外,不同迭代的交互表现出判别性响应,在迭代过程中丰富了特征多样性。
(三)高阶通道交互
-
回顾挤压与激励块:挤压与激励(SE)块[66]利用一阶全局统计量(均值)对通道交互进行建模。这种方法使SE块能够明确捕获输入特征通道之间的相互依赖关系。对于红外与可见光图像融合,SE块将第i次高阶空间交互中红外和可见光特征之间的依赖关系表述如下:
其中, , 表示一阶统计量, 表示Sigmoid函数。 包括两个线性变换和一个ReLU函数。
-
深入高阶形式:与高阶空间交互类似,作者扩展SE块以实现高阶通道交互:
最后,一个卷积层将 整合到融合模态中,产生整合特征 。
通过在L次迭代中进行N阶空间和通道交互,交互链可以用数学表达式表示如下:
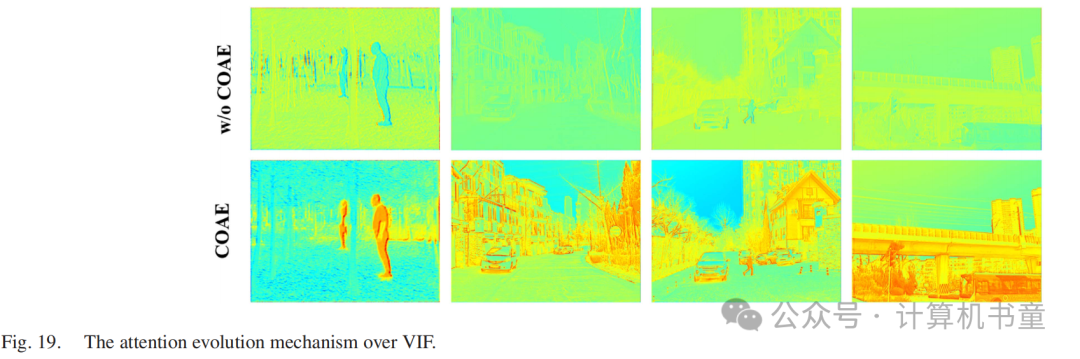
作者分析了第2次通道高阶交互沿通道维度的通道响应。与不同阶的一致响应相反,作者的高阶建模自适应地区分源模态之间的相互依赖关系,如图7所示。

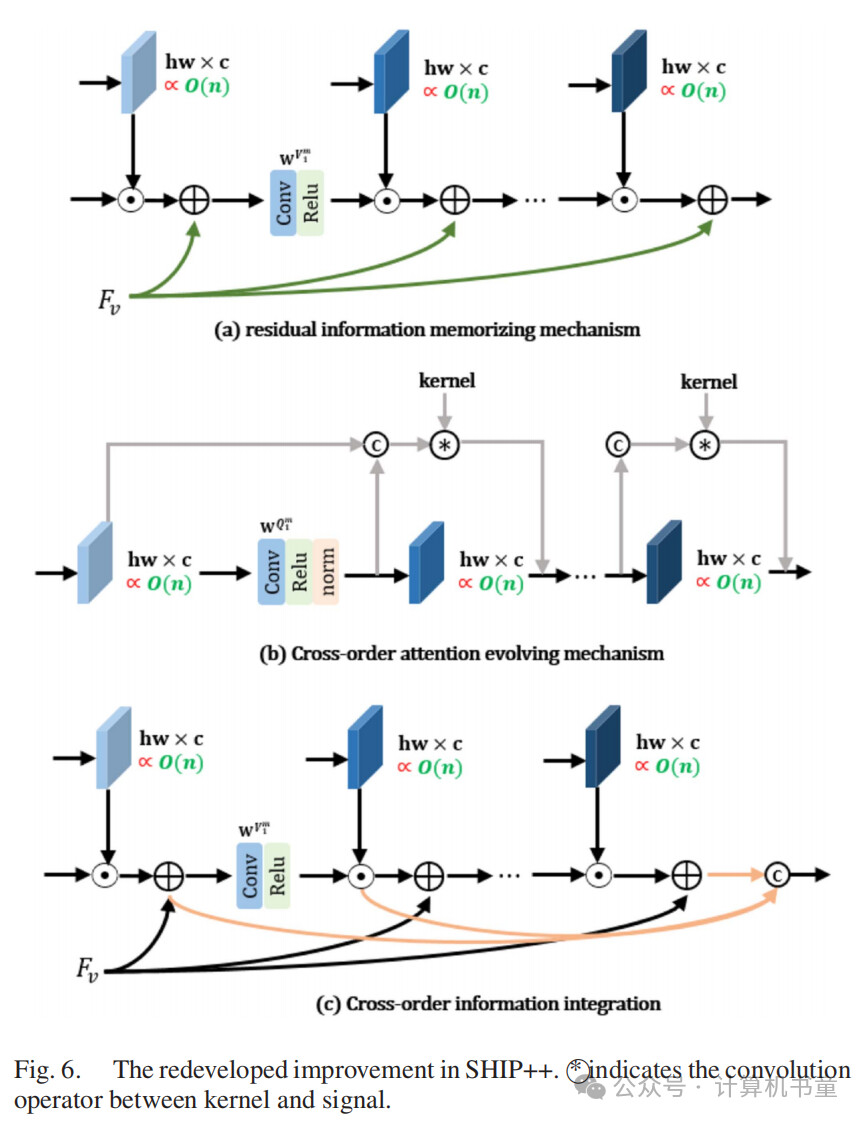
(四)SHIP++的重新开发组件
-
残差信息记忆:VIF致力于将红外图像中的显著成分聚合到可见光图像中,并生成增强的可见光图像。同样,全色锐化旨在在纹理丰富的PAN图像的指导下对低分辨率MS图像进行超分辨率。在这两种情况下,VIF中的可见光图像和全色锐化中的MS图像作为主要模态,包含任务所需的关键信息。鉴于它们的重要性,在网络的学习过程中保留这些模态的信息至关重要。然而,在作者的更新过程中,主导模态仅参与最终学习阶段,这导致在中间步骤中其信息保留不佳。为了保留重要细节,作者在突出模态中实现了残差信息记忆机制,如图6(a)所示:
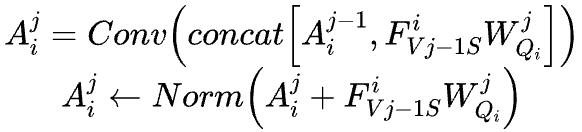
(五)全色锐化的损失函数
设IF和GT分别表示网络输出和相应的地面真值。为了提高全色锐化结果的清晰度,作者使用L1损失:
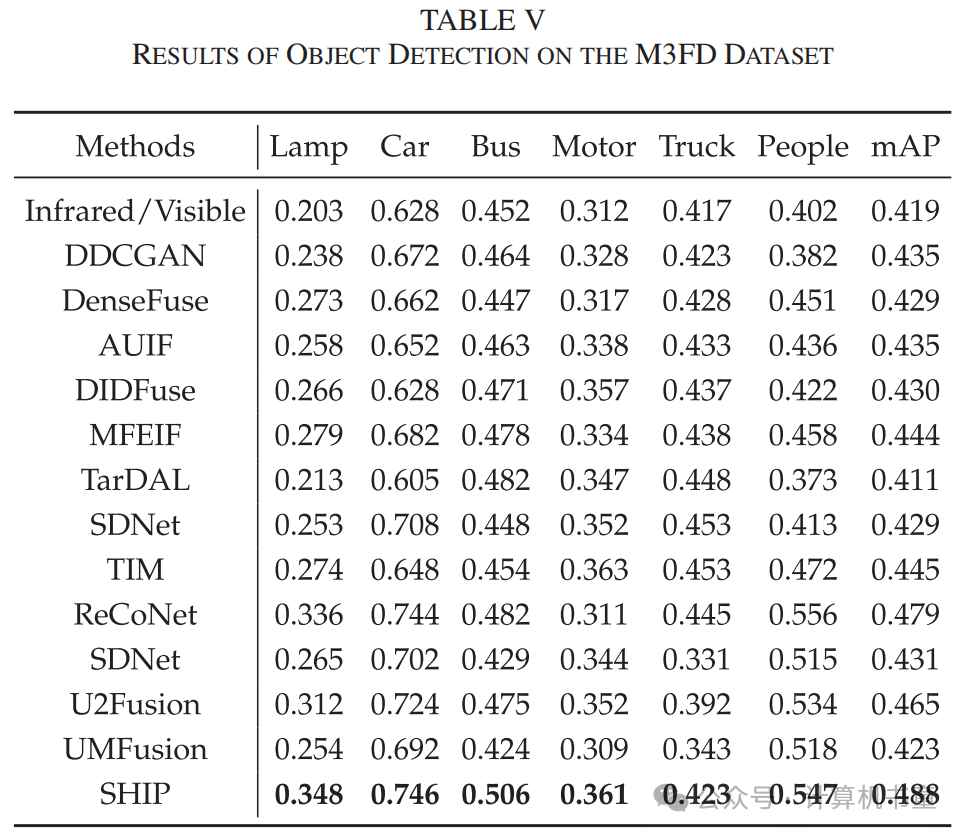
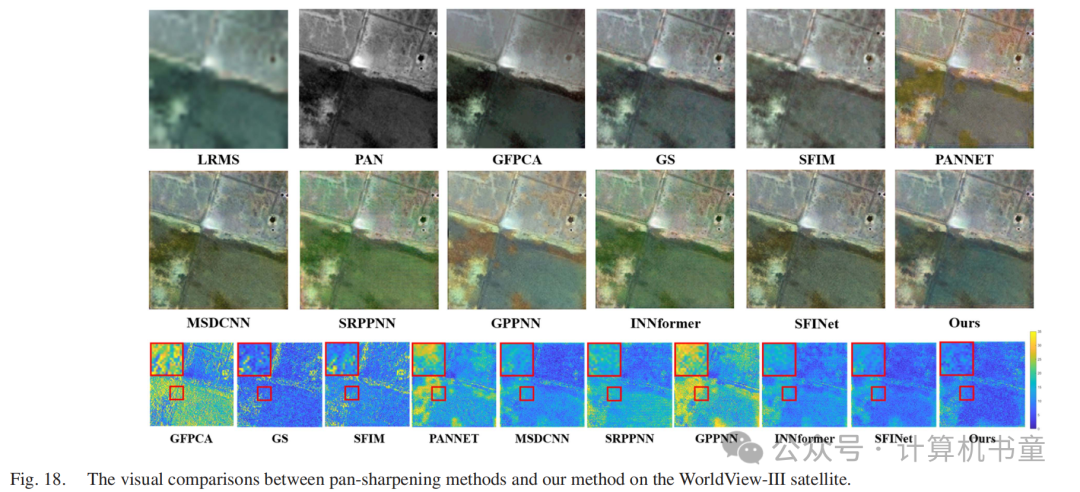
五、可见光与红外图像融合实验

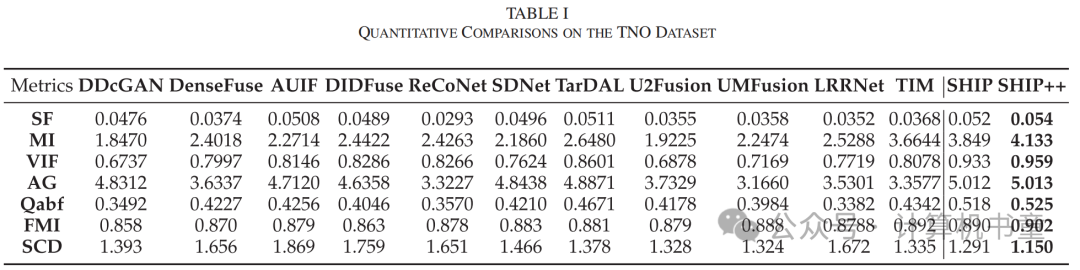
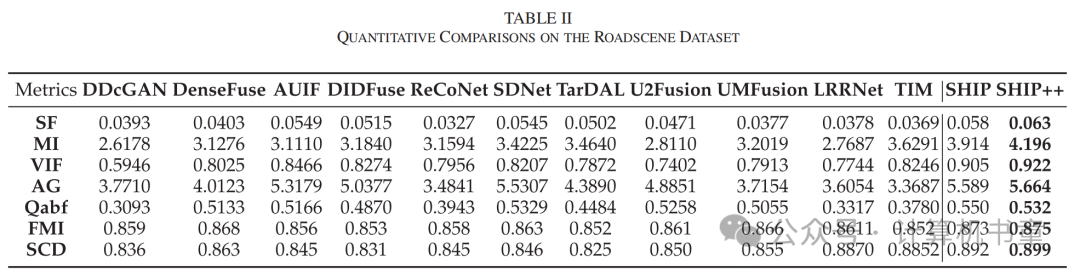
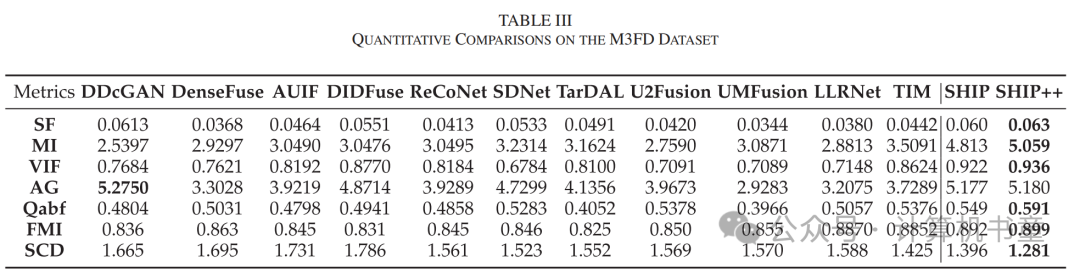






声明
本文内容为论文学习收获分享,受限于知识能力,本文对原文的理解可能存在偏差,最终内容以原论文为准。本文信息旨在传播和学术交流,其内容由作者负责,不代表本号观点。文中作品文字、图片等如涉及内容、版权和其他问题,请及时与我们联系,我们将在第一时间回复并处理。

