DCE框架创新解决不平衡领域增量学习难题,平衡新旧知识,提升模型性能。
原文标题:通过双重平衡协同专家解决不平衡的领域增量学习问题
原文作者:数据派THU
冷月清谈:
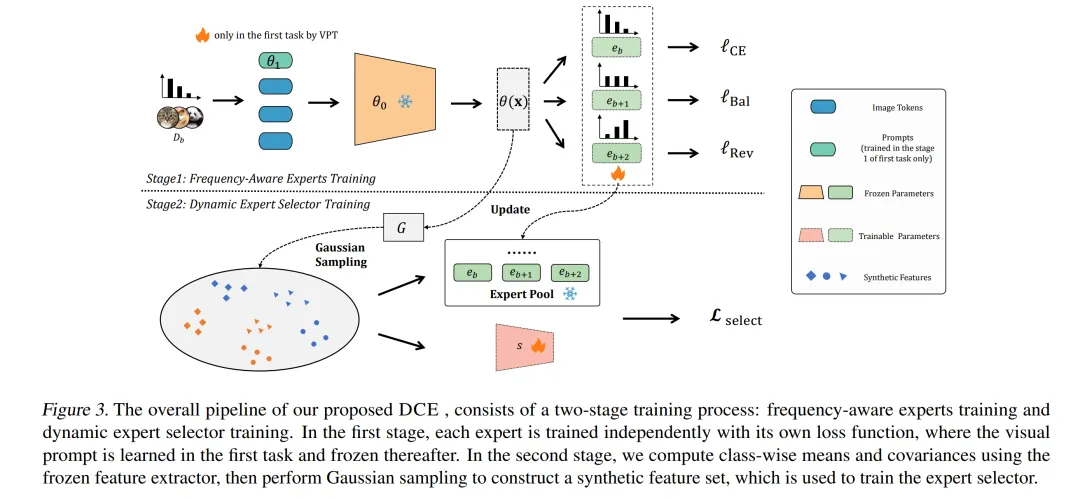
领域增量学习(DIL)旨在让模型在动态环境中持续适应新领域,同时保留旧知识。然而,当数据存在不平衡时,DIL面临两大挑战:域内类别不平衡导致少样本类别欠拟合,以及跨域类别分布转移要求在保持旧知识的同时提升旧领域少样本表现。为应对这些问题,本文提出了双重平衡协同专家(DCE)框架。DCE引入了一个频率感知的专家组,每个专家学习特定频率组的特征,从而有效处理域内类别不平衡。此外,它通过平衡高斯采样历史类别统计信息合成伪特征,以此训练一个动态专家选择器。该机制巧妙地权衡了保留旧领域多样本类别知识与利用新数据提升旧任务中少样本类别性能。实验结果表明,DCE在不平衡领域增量学习任务中表现卓越,达到了当前领先水平。
怜星夜思:
1、双重平衡协同专家(DCE)框架听起来很厉害,但这种又是多个专家又是动态选择器的,实际部署起来会不会很吃资源?比如对计算能力或者内存的要求,小型企业或者个人开发者用得起吗?
2、文章提到“领域增量学习”主要应对的是不断变化的领域和数据不平衡。除了文章里说的图像分类之类的,还有哪些现实场景的需求特别需要这种增量学习的能力,而且对数据不平衡非常敏感?比如金融风控或者医疗诊断?
3、DCE里用到的“频率感知的专家组”和“平衡高斯采样”感觉是解决不平衡问题的核心。除了这两种方法,大家还知道哪些比较有效的处理数据不平衡的技术?它们在增量学习里有没有什么特殊表现?
2、文章提到“领域增量学习”主要应对的是不断变化的领域和数据不平衡。除了文章里说的图像分类之类的,还有哪些现实场景的需求特别需要这种增量学习的能力,而且对数据不平衡非常敏感?比如金融风控或者医疗诊断?
3、DCE里用到的“频率感知的专家组”和“平衡高斯采样”感觉是解决不平衡问题的核心。除了这两种方法,大家还知道哪些比较有效的处理数据不平衡的技术?它们在增量学习里有没有什么特殊表现?
原文内容

来源:专知本文约1000字,建议阅读5分钟本文提出了双重平衡协同专家(Dual-Balance Collaborative Experts, DCE)框架。

领域增量学习(Domain-Incremental Learning,DIL)旨在应对非平稳环境中的持续学习问题,要求模型能够适应不断变化的领域,同时保留已有的历史知识。在面对不平衡数据时,DIL 面临两个关键挑战:域内类别不平衡和跨域类别分布转移。这些挑战严重阻碍了模型性能的发挥:域内不平衡会导致少样本类别的欠拟合,而跨域分布转移则要求模型在保持多样本类别知识的基础上,提升旧领域中少样本类别的表现。
为解决上述问题,本文提出了双重平衡协同专家(Dual-Balance Collaborative Experts, DCE)框架。DCE 引入了一个频率感知的专家组,每个专家通过特定的损失函数进行引导,学习对应频率组的特征,从而有效应对域内类别不平衡问题。随后,DCE 通过对历史类别统计信息进行平衡高斯采样,合成伪特征,从而学习一个动态专家选择器。该机制在“保留旧领域中多样本类别知识”与“利用新数据提升旧任务中少样本类别性能”之间实现了有效权衡。
在四个基准数据集上的广泛实验结果表明,DCE 在不平衡领域增量学习任务中达到了当前最先进的性能水平。