MoFE-Time结合时频域特征与MoE,刷新6大数据集SOTA,在时间序列预测中表现卓越,尤其在商业场景具实用价值。
原文标题:「把傅立叶塞进 MoE」——Li Auto团队发布 MoFE-Time,刷新 6 大数据集 SOTA!
原文作者:数据派THU
冷月清谈:
在数据处理方面,MoFE-Time采用了可逆实例归一化(RevIN)来减少非平稳性影响,并通过点嵌入与扩张卷积捕捉局部时序依赖并扩大感受野。监督机制则结合了Huber Loss处理预测误差及MoE辅助损失以优化专家选择平衡性。实验结果显示,MoFE-Time在六个公共数据集上均取得了新的SOTA(State-of-the-Art)成绩,相较主流模型Time-MoE,其MSE和MAE分别平均下降了6.95%和6.02%,显著提升了预测精度。尤其在真实业务场景的专有数据集NEV-sales上的优异表现,进一步验证了其在商业应用中的有效性和实用价值。消融实验也证实了预训练、FTC模块以及RevIN在模型性能提升中的关键作用。
怜星夜思:
2、MoFE-Time引入了“专家混合(MoE)”架构,这听起来有点像“集思广益”。在实际的时间序列预测任务中,专家混合模型相比传统的单一模型,有哪些特别的优势?我们应该怎么理解这里的“专家”?
3、MoFE-Time在新能源汽车销售预测这种真实业务场景下表现优异。除了销售预测,大家觉得这种结合时频域特征+MoE的模型,还能在哪些我们日常生活中不那么显眼的领域大放异彩?比如跟我们生活息息相关的场景?
原文内容

本文约1700字,建议阅读5分钟本文提出 MoFE-Time,一种结合时频域特征的专家混合(MoE)时间序列预测模型。
时间序列预测作为重要的数据建模任务,在多个领域中发挥关键作用。随着大语言模型(LLMs)的发展,将 LLMs 作为时间序列建模的基础架构受到广泛关注。然而,现有模型在预训练-微调范式下难以同时建模时间与频率特征,导致复杂时间序列(需同时捕捉周期性和信号先验模式)的预测性能不足。
本文提出 MoFE-Time,一种结合时频域特征的专家混合(MoE)时间序列预测模型,通过预训练-微调范式迁移不同周期分布的先验模式知识。模型在注意力模块后引入时频单元(FTC)作为专家,利用MoE路由机制构建输入信号的多维稀疏表示。在6个公共基准上,MoFE-Time 均取得新SOTA成绩,MSE 和 MAE 相较主流模型 Time-MoE 分别下降6.95%和6.02%。此外,在真实业务场景的专有数据集 NEV-sales 上的优异表现,验证了其商业应用有效性。”
论文背景
方法介绍
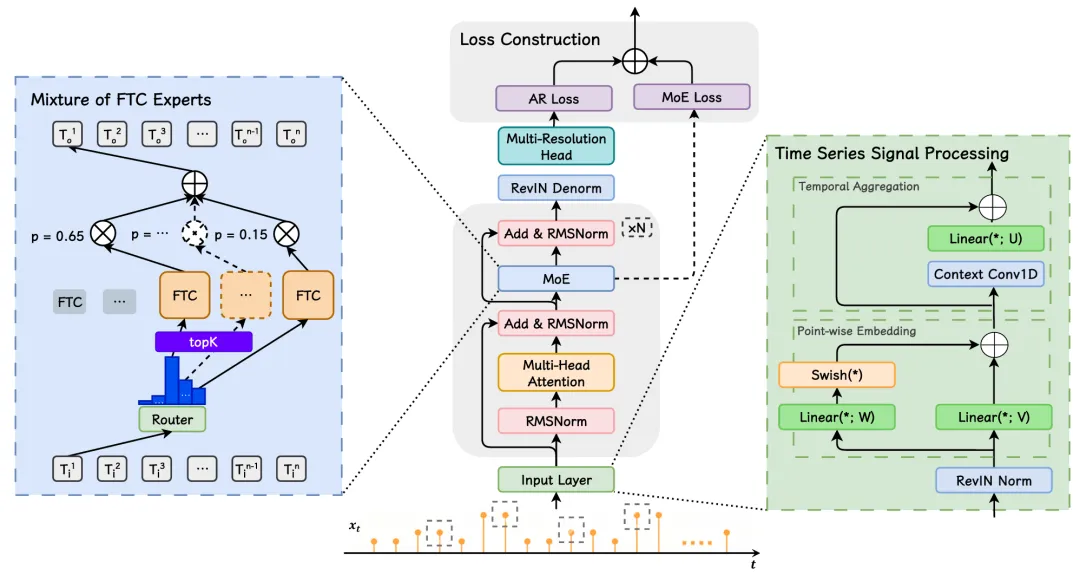
01 时间序列信号处理
-
可逆实例归一化(RevIN):通过实例特异性均值和标准差归一化输入,减少非平稳性影响,公式如下:
输出通过对称反归一化恢复原始分布。
-
点嵌入与扩张卷积:将浮点信号映射至高维空间,通过扩张卷积(kernel=3,dilation=2)捕捉局部时序依赖,扩大感受野。
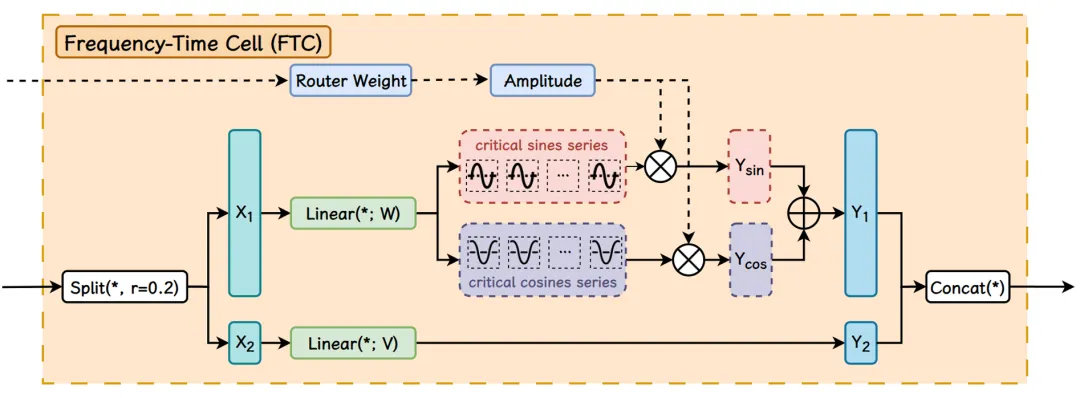
02 时频域处理单元(FTC)模块
-
核心功能:同时学习信号的频域(关键频率分量(\omega_i)及振幅(a_i))和时域特征。
-
工作机制:
-
预训练阶段学习 个关键谐波频率( 为专家数, 为每个专家的频率数);
-
MoE路由算法选择重要谐波,通过加权和生成周期性表示:
03 监督机制
-
回归损失(Huber Loss):针对预测值与真实值的差异,采用分段损失函数,减少极端值影响:
-
MoE 辅助损失(Aux Loss):优化专家选择的平衡性,公式为:
实验设置
01 数据集
|
类型
|
数据集
|
领域
|
时间点数量
|
粒度
|
|---|---|---|---|---|
|
预训练
|
Time-300B
|
多领域
|
3000 亿
|
秒至年
|
|
微调与评估
|
ETTh1/2
|
能源
|
17,420
|
1 小时
|
|
微调与评估
|
ETTm1/2
|
能源
|
69,680
|
15 分钟
|
|
微调与评估
|
Weather
|
气候
|
52,696
|
10 分钟
|
|
微调与评估
|
Exchangerate
|
金融
|
7,588
|
1 天
|
|
专有数据集
|
NEV-sales
|
新能源销售
|
330,000
|
1 天
|
02 模型参数与训练
-
预训练:AdamW 优化器(学习率 1e-3,权重衰减 0.1),batch size=2,bf16 精度,1 个 epoch;
-
微调:学习率 5e-6,无预热,1 个 epoch,其他参数与预训练一致。
实验结果
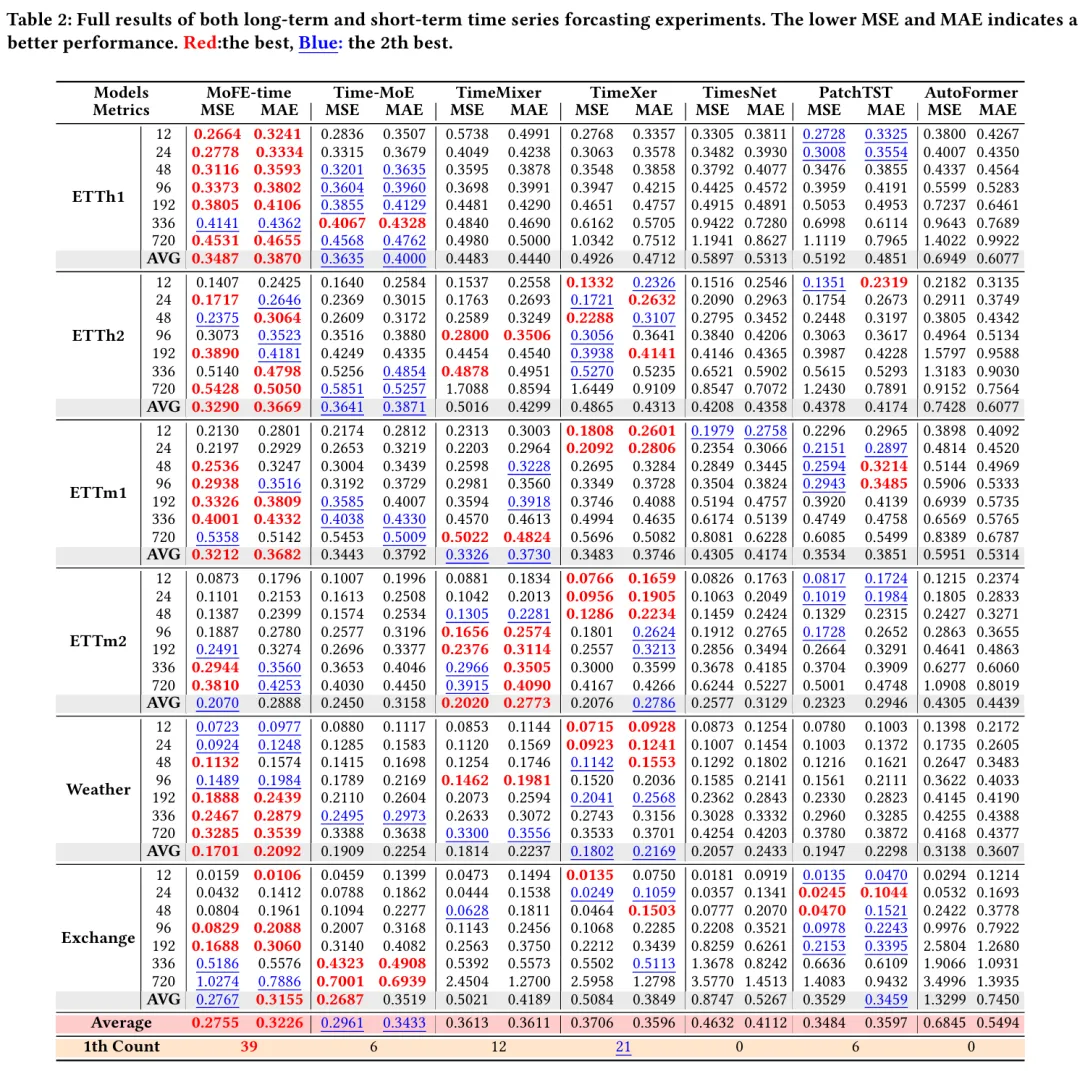
01 公共数据集性能
-
MSE 降低 6.95%,MAE 降低 6.02%;
-
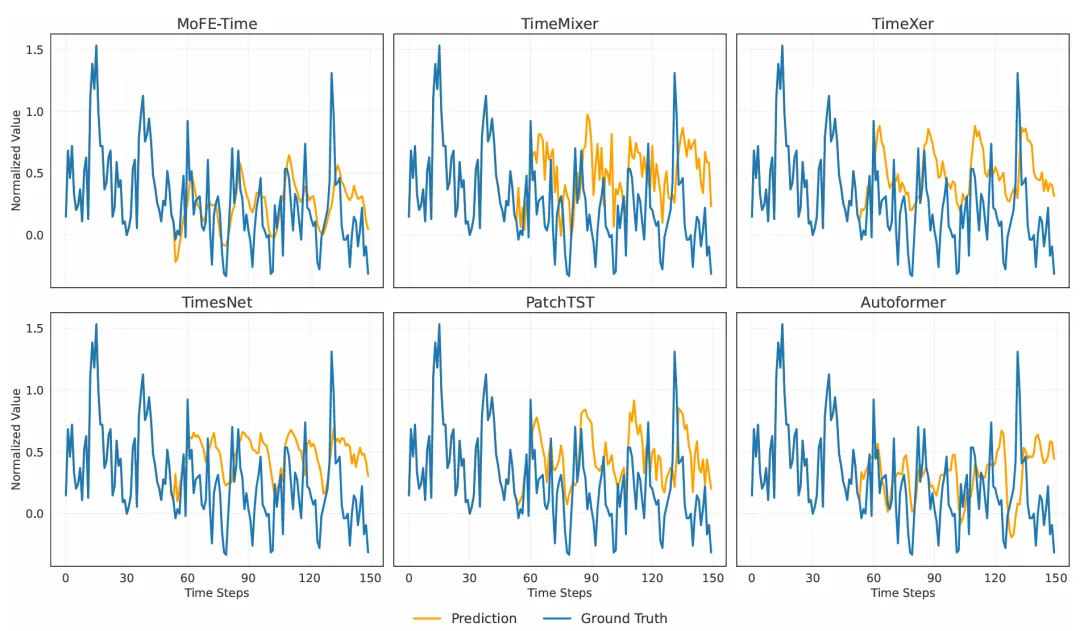
例如在 ETTh1 数据集,96 步预测的 MSE 为 0.3373(Time-MoE 为 0.3604)。
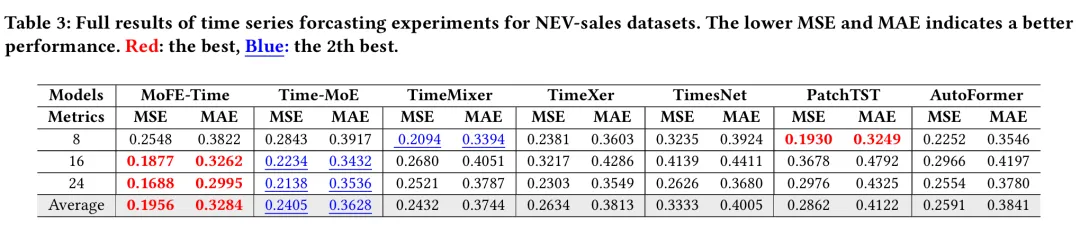
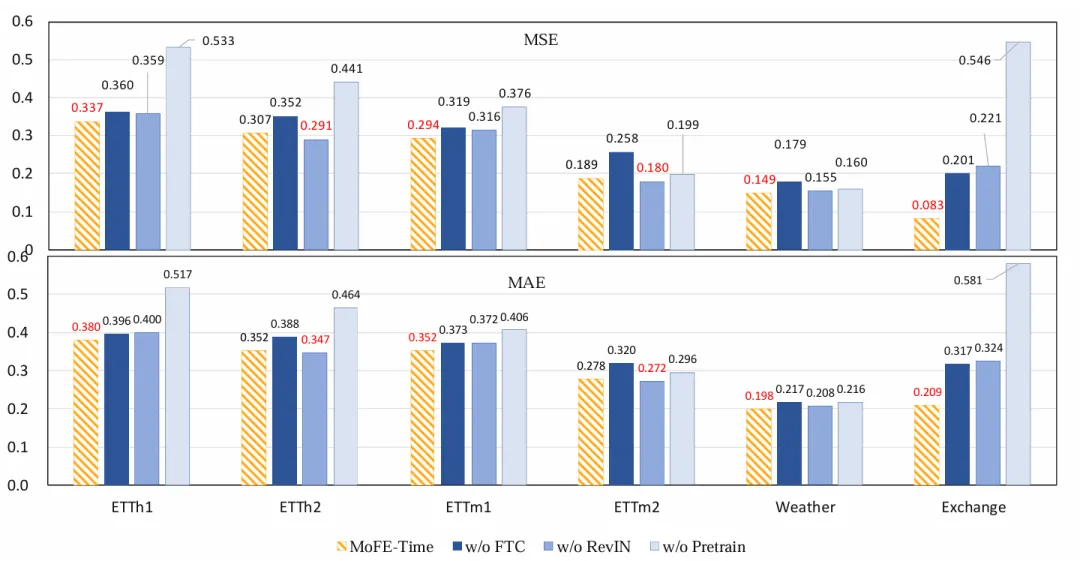
MoFE-Time 通过频域-时域特征整合与基座模型的预训练-微调范式,在时序预测任务中表现优异,尤其在商业场景(如新能源汽车销售流量预测)中具备实用价值。其设计为解决时序数据的复杂周期性和非平稳性提供了新思路。
编辑:文婧
