《图解大模型》:图文并茂,手把手带你理解AI大模型核心原理,掌握实战开发技巧。
原文标题:我力荐这本书,贼好懂,还讲得特别细致!
原文作者:图灵编辑部
冷月清谈:
怜星夜思:
2、文章里提到检索增强生成(RAG)技术可以“让大模型看懂你的知识库”,这在构建企业内部的私有ChatGPT时非常有用。但是,除了技术实现本身,大家觉得在把RAG系统真正整合进一个大型企业的现有工作流程中时,最大的挑战或潜在的坑会是什么?
3、文章提到在数据有限的情况下,可以用增强版SBERT等方法对模型进行微调。对于我们这些没有大型GPU集群的个人学习者或开发者来说,有没有什么比较经济实惠甚至免费的途径,可以实际操作这些微调技术,感受一下效果呢?还是说,这依然是个“烧钱”的领域,普通人很难涉足?
原文内容
通过让机器更好地理解并生成类人语言,大模型为人工智能领域打开了全新的可能性,并深刻影响了整个行业。
这是《图解大模型》一书中由作者 Jay Alammar 和 Maarten Grootendorst 撰写的开篇语。随着人工智能的不断演进,大模型正站在最前沿,彻底改变我们与机器的互动方式、信息处理流程,甚至语言本身的理解方式。
当今这个由 AI 驱动的时代,我们早已不再惊讶于 ChatGPT 编写诗歌、Copilot 生成代码,甚至 Midjourney 一键出图。大模型(LLM)正悄然渗透进各行各业,深刻改变着我们与机器的互动方式。而如果你想真正理解这些改变背后的技术逻辑,亲手构建属于自己的 LLM 应用,那么这本《图解大模型》将是一本不可错过的实战之书。
作者 Jay Alammar 和 Maarten Grootendorst,一个是以图解 Transformer 闻名的可视化大牛,另一个是 BERTopic 作者、embedding 实战派。这对组合联手打造的这本书,既有清晰的技术讲解,也有动手实操的示例代码,堪称想看懂又能上手的理想教程。
为什么这本书值得读?
不再被 Transformer 吓退
第 1 章提供了语言模型内部工作机制的高级概述,第 2 和第 3 章则对这些概念进行了更深入的拆解。
作者巧妙地使用图示、插图和代码示例来解释复杂主题,如分词、嵌入、Transformer 模型以及注意力机制。
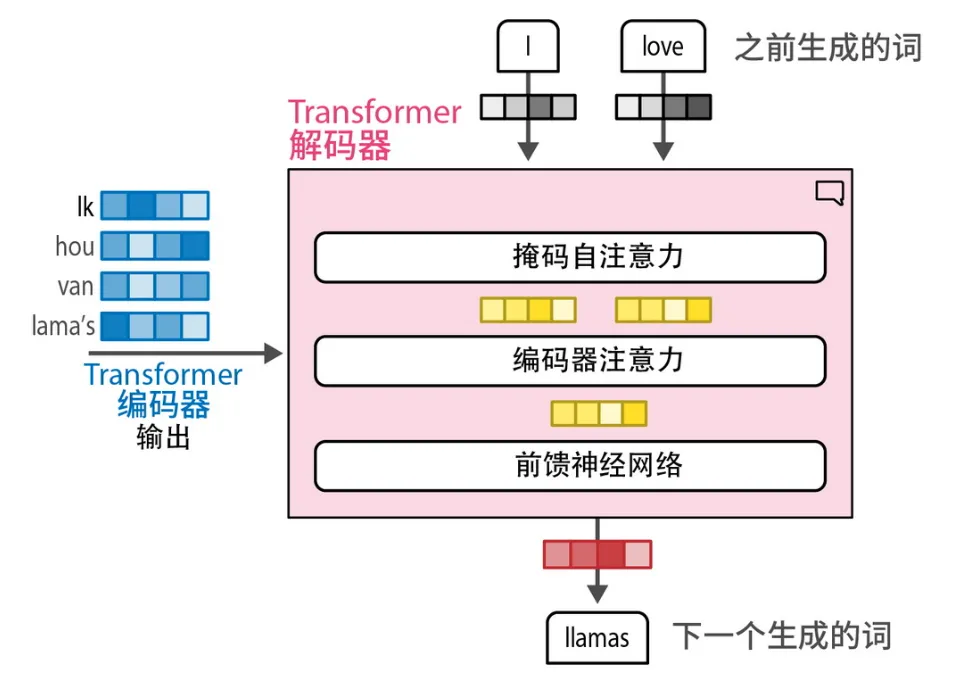
阅读建议:第 1 章内容可能更适合具备机器学习背景的读者,对其他人而言可能略显艰涩。如果你觉得吃力,可以先快速浏览;后面的第 2、3 章会对这些内容进行更细致的讲解。
重新认识 embedding 的价值
嵌入模型在该领域的重要性不言而喻,因为它们是众多应用背后的核心驱动力。
第 4 章讲解了如何利用开源嵌入模型完成分类任务,无需高成本的微调,也不需要 GPU 训练,甚至可以处理无标签数据。
第 5 章讲解了如何用嵌入模型进行文本聚类,识别异常点、加速标注流程,或是在大量文本中抽取主题信息。
提示工程
第 6 章对提示工程的讲解非常实用,哪怕你只是日常使用 ChatGPT,也能从中学到设计 prompt 的思路。
其中“Tree of Thought”的方法更是让我印象深刻,一个简单的模板就能引导模型展开多条思路,非常适合任务拆解。

利用树状结构,生成模型可以生成待评分的中间思考过程。最有希望的思考过程会被保留,而较差的会被剪枝
检索增强生成(RAG)
第 8 章专门介绍了热门的 RAG 技术 —— “让大模型看懂你的知识库”。不仅讲解了基础架构,还涵盖了高级技巧与评估方法,是构建私有 ChatGPT 的核心章节。
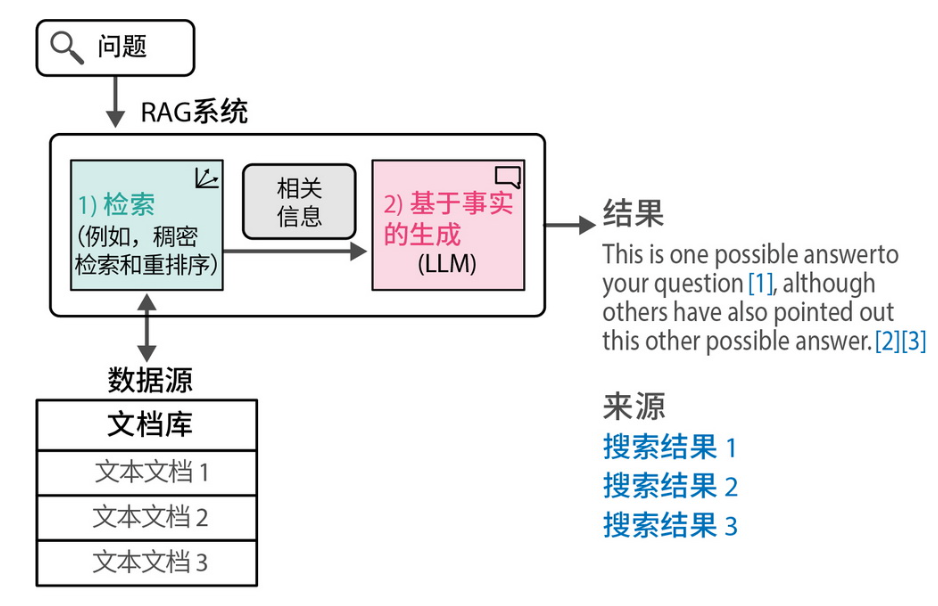
生成式搜索在搜索流程的末端生成答案和摘要,同时引用其来源(由搜索系统的前序步骤返回)
LangChain 框架实战
第 7 章系统介绍了 LangChain,这个目前很受欢迎的 LLM 应用开发框架。对于开发者来说,这一章可以大大缩短上手时间,尤其是 Agent 部分的讲解更是非常具有启发性。
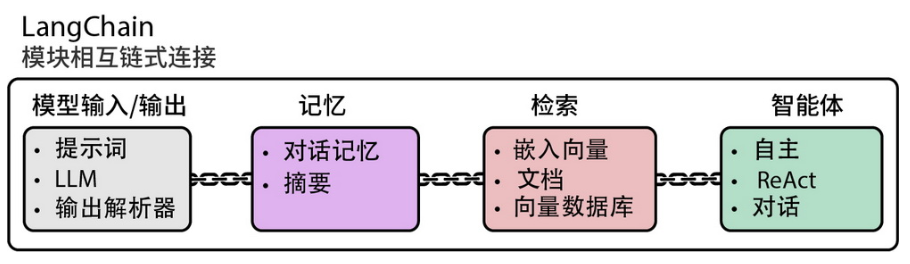
LangChain 作为全功能 LLM 应用框架,其模块化组件可通过链式架构构建复杂的 LLM 系统
大模型在搜索引擎中的应用
第 8 章还探讨了语义搜索在 Google、Bing 等搜索引擎中的应用,讲解了 reranking(重排序)优化搜索结果的工程机制,内容很硬核。

多模态
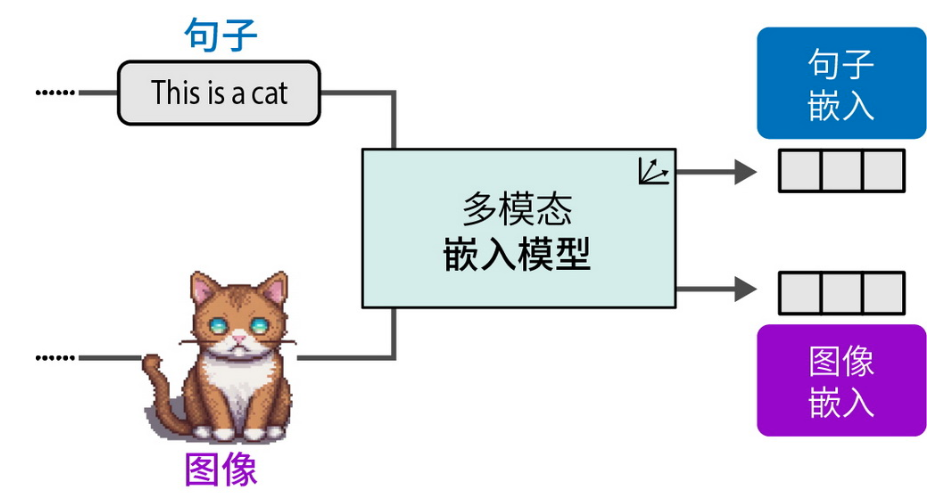
多模态嵌入模型可在同一向量空间中为不同模态生成嵌入向量
命名实体识别(NER)
作者还在书中介绍了如何通过 NER 精准地识别文本中的人名、地名等实体,特别适用于涉及敏感信息的脱敏处理。
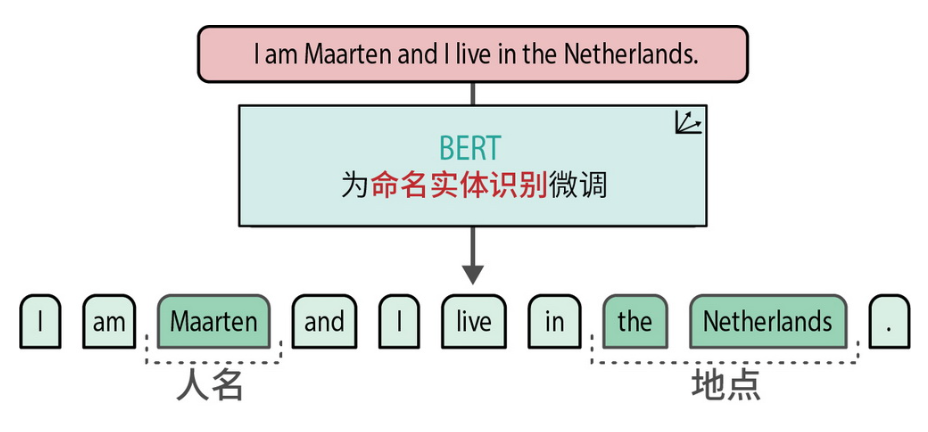
微调后的 BERT 模型能够识别人名和地点等命名实体
模型训练与微调
这一部分是我最期待的内容之一——将大模型(LLM)适配到特定的应用场景,展现了它们的灵活性和广泛的适用性。第 10 到第 12 章就专门聚焦于这个主题,涵盖了嵌入式模型和生成式模型的应用。
我特别喜欢第 10 章,它讲解了如何在数据有限的情况下使用增强版 SBERT(Augmented SBERT)对模型进行微调,并介绍了用于无监督训练的 TSDAE 方法。这些技术在缺乏大规模标注数据时非常有价值。
第 11 章则超越了传统的分类任务微调范畴,深入探讨了如何根据算力资源有选择性地微调模型的部分层级。作者对“微调部分层”和“微调全部层”的对比分析,也提供了在资源有限或训练时间受限的情况下,做出合理取舍的实用指南。
第 10 至 12 章聚焦 LLM 的定制化使用,包括少量数据下的微调方法(如 Augmented SBERT、TSDAE)、选择性微调策略,以及 Adapter 模型和量化技术。对于有意将 LLM 应用到具体场景的开发者来说,这几章干货满满。
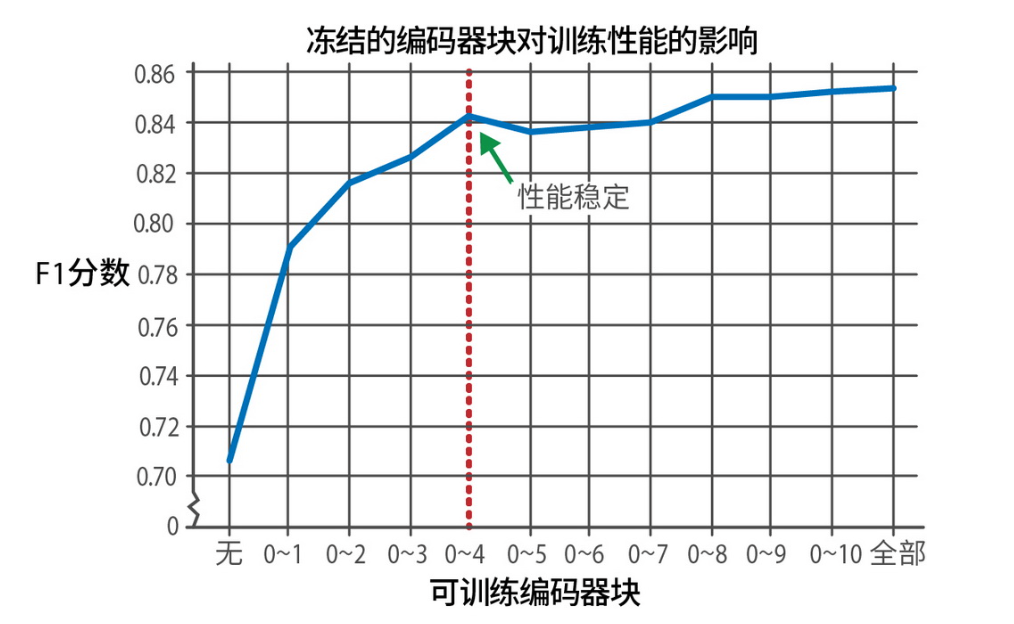
冻结特定编码器块对模型性能的影响。训练更多模块带来的性能提升会快速趋于平缓
第 12 章介绍了“适配器(Adapters)”的概念,它为每个下游任务都进行完整微调提供了一种替代方案。这种方法与构建可组合的软件的理念高度契合,而这正是工程师们始终追求的目标。此外,本章还探讨了量化(Quantization)技术如何提升训练效率,将数学原理与计算机科学方法相结合,展现了模型优化中的一系列创新策略。
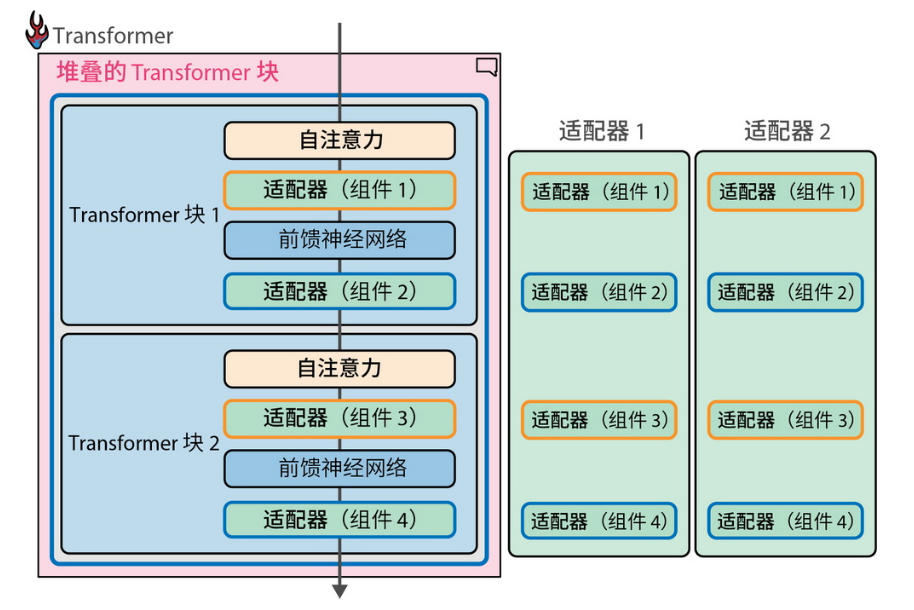
专门用于特定任务的适配器可以被替换到相同的架构中,前提是它们共享原始模型架构和权重
无论你是初入大模型世界的新手,还是希望进一步掌握其应用的开发者,《图解大模型》这本书可以说都是一本不可错过的实用指南。
作者不仅用清晰的语言和丰富的图示解析复杂概念,还提供了大量可运行的代码示例,真正做到了手把手教学。
更难得的是,作者还附上了大量公开论文作为延伸阅读,帮助读者进一步深入探索。
随着 AI 技术的不断演进,理解并掌握大语言模型,已经成为越来越多技术岗位的核心能力。
如果你想往前更进一步,这本书不仅给你基础,还带你走向实际落地的第一步。读完之后,你不会只停留在知道,而是真正地开始去用。
推荐每一位想要理解并拥抱大模型时代的读者阅读。
推荐指数:⭐⭐⭐⭐⭐

《图解大模型:生成式AI原理与实战》
[沙特] 杰伊·阿拉马尔,[荷] 马尔滕·格鲁滕多斯特 | 著

《图解DeepSeek技术》
[沙特] 杰伊·阿拉马尔, [荷] 马尔滕·格鲁滕多斯特 | 著
李博杰 孟佳颖 | 译
2 小时搞懂 DeepSeek 底层技术。近 120 幅全彩插图通俗解读,内容不枯燥。从推理模型原理到 DeepSeek-R1 训练,作者是大模型领域知名专家 Jay & Maarten, 袋鼠书《图解大模型》同系列,广受欢迎。

入营流程:
-
扫码付款后扫码添加小助手
-
发送手机号 / 订单截图验证入群
-
入群后查看公告,开启共学之旅
常见问题:
-
没有 AI 背景可以学吗?可以,只需基础 Python 知识
-
直播错过怎么办?有回放,节奏自由,随看随学
-
图书是电子版吗?全部都是实体书,并且全国包邮
-
读过部分图书了还适合加入吗?当然适合,核心是社群、项目和系统性