开发者快速入门!以房价预测实战AI,手把手带你走完机器学习全流程,理解核心概念与工具应用。
原文标题:AI 基础知识从0.1到0.2——用“房价预测”入门机器学习全流程
原文作者:阿里云开发者
冷月清谈:
核心的特征工程是提升模型性能的关键,文章示范了如何处理缺失值、对类别变量进行One-Hot编码以及进行特征缩放。随后,在模型选择环节,作者深入浅出地讲解了拟合(欠拟合/过拟合)、泛化能力、模型复杂度以及正则化(L1/L2)等重要概念,并介绍了线性回归、岭回归和随机森林等常用模型。在训练与调优部分,文章指导读者如何训练基线模型、理解超参数和交叉验证的作用,并使用GridSearchCV进行超参数调优。模型评估环节则通过RMSE和图示分析预测误差与实际值的关系。
文章特别强调了模型优化与改进的重要性,提出可以从数据、特征和模型多个层面进行迭代。例如,通过生成新特征和特征选择来提升模型表现。最后,文章详细介绍了如何使用joblib将训练好的模型进行部署,并指出模型在实际应用中需要持续的监控、反馈与迭代优化。整个过程结合代码示例,力求让读者能够跟着步骤亲自动手实践,从而全面掌握机器学习的全链路开发。
怜星夜思:
2、文章以回归任务(房价预测)为例,讲解了模型开发流程。如果任务变成一个分类任务,比如预测某个房子在未来一年内会不会快速销售出去(是/否),那么这个机器学习流程从头到尾,有哪些关键步骤需要进行大的调整或补充,才能更好地适应分类问题?
3、文章最后提到了模型部署和监控,还举了个Flask的简单例子。但在实际的生产环境中,维护一个机器学习模型可不是保存一下再拿出来用这么简单。你们觉得,模型部署上线后,可能会遇到哪些意想不到的“坑”或者持续的大挑战?怎么才能让模型“永葆青春”呢?
原文内容

【系列文章】
沿着 AI 的发展脉络,本系列文章从Seq2Seq到RNN,再到Transformer,直至今日强大的GPT模型,我们将带你一步步深入了解这些关键技术背后的原理与实现细节。无论你是初学者还是有经验的开发者,相信读完这个系列文章后,不仅能掌握Transformer的核心概念,还能对其在整个NLP领域中的位置有一个全面而深刻的认识。那就让我们一起开始这段学习之旅吧!
作为一名开发工程师,可能对算法开发领域感到有些陌生,但其实它的核心是通过数据训练模型,并用这些模型解决实际问题。本文将以一个简单的“房价预测”问题为例,一步步了解算法工程师开发模型的完整过程。
零、使用模型解决业务问题流程
在上文《》中提到过:模型就是机器学习、深度学习中从数据中学习到的、用于做预测或决策的规则集合。当业务需求有清晰的规则执行,一般由工程同学编写 CRUD 进行实现。
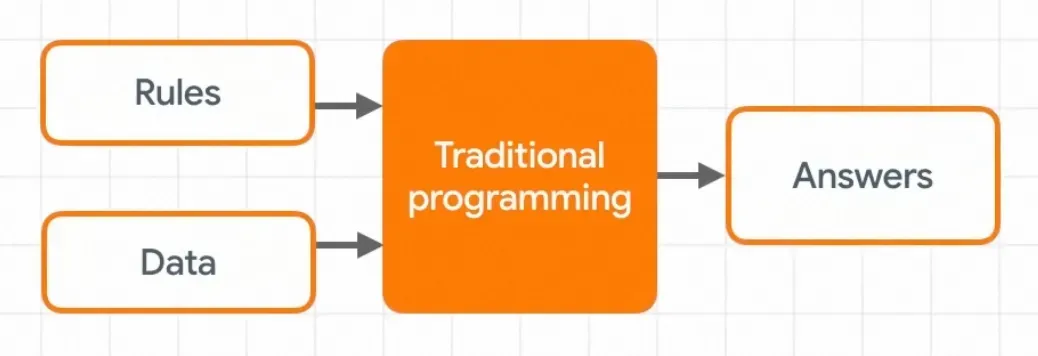
当业务只有一些数据、现象,没有这些数据的规则时候就需要算法同学训练、产出这个规则,也就是模型。
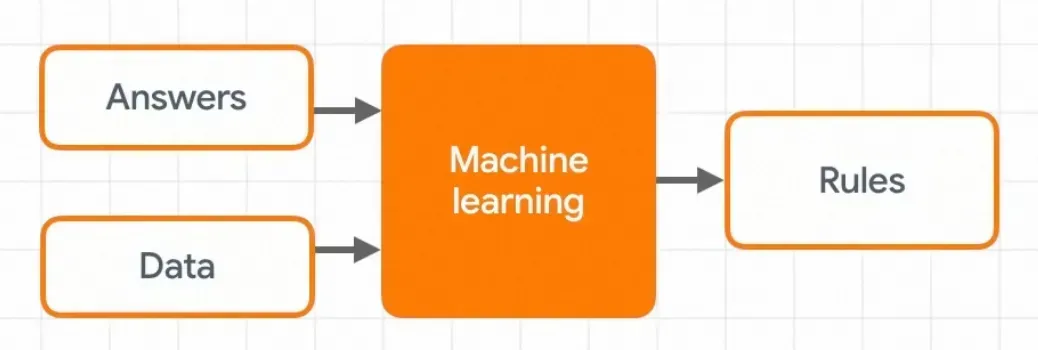
从这个角度想算法同学和工程同学的工作有点逆操作,但实际开发过程两者非常相似。
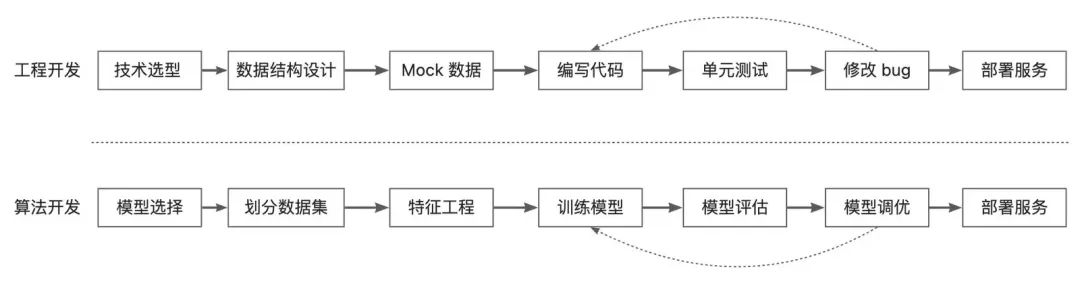
接下来按照以下流程来训练一个预测房价的回归任务:
1.需求分析 → 明确目标、指标、资源。
2.数据收集 → EDA、清洗、预处理。
3.划分数据集 → 训练集 / 验证集 / 测试集。
4.特征工程 → 特征选择、生成、转换。
5.模型选择 → 基于任务和数据选择候选模型。
6.训练与调优 → 基线训练、超参数调优。
7.模型评估 → 测试集评估、误差分析。
8.优化改进 → 数据、特征、模型层面的迭代。
9.部署与监控 → 服务化部署、性能监控、文档记录。
10.反馈与迭代 → 根据反馈持续改进。
一、需求分析
-
目标:房价预测需求的目标是根据房屋的一些特征(如面积、房间数量等),预测房屋的价格。
-
指标:这里我们采用均方误差(MSE)来衡量模型预测效果的标准,它是预测值与真实值差值平方的平均值,值越小说明模型预测越准确。
-
资源:包括使用的数据集、编程语言、库和框架等
-
数据集:kaggle 公开的房价数据集。
-
工具:Python 编程语言,使用 pandas、numpy、scikit-learn 等库。
-
计算资源:个人电脑即可完成,数据量不大。
衡量模型预测结果与真实结果之间差异的函数被称之为损失函数,使用 MSE 会带来两个好处:
1.消除正负号的影响,让误差 “绝对值化”,防止求和之后误差互相抵消;
2.放大误差便于模型优化,例如误差为 3 和 0.4,平方后变为 9 和 0.16,差异更明显。
二、数据收集
首先,我们需要获取数据并进行初步的探索性数据分析(EDA),了解数据的基本情况,并进行必要的清洗和预处理。
1.下载数据集:前往Kaggle竞赛页面下载train.csv和test.csv文件。
2.加载数据:使用 pandas 加载数据集。
3.探索数据:查看数据的基本信息、统计描述,以及缺失值情况。
4.可视化:了解目标变量(房价)及其与各特征的关系。
import pandas as pd import matplotlib.pyplot as plt import seaborn as sns加载数据
train = pd.read_csv(‘data/raw/train.csv’)
test = pd.read_csv(‘data/raw/test.csv’)查看数据集前几行
print(train.head())
基本统计信息
print(train.describe())
数据集信息
print(train.info())
缺失值统计
missing_values = train.isnull().sum()
print(missing_values[missing_values > 0])可视化目标变量分布
plt.rcParams[‘font.family’] = ‘SimSong’ # 设置中文字体
plt.figure(figsize=(10,6)) # 创建 10x6 的窗口
sns.histplot(train[‘SalePrice’], kde=True, color=‘blue’) # 自动统计数据在不同区间的频数,绘制直方图
plt.title(‘房价分布’)
plt.xlabel(‘价格’)
plt.ylabel(‘频数’)
plt.show()# 可视化房价与一些特征的关系
plt.figure(figsize=(10,6))
sns.scatterplot(x=train[‘GrLivArea’], y=train[‘SalePrice’], color=‘green’)
plt.title(‘房价与居住面积的关系’)
plt.xlabel(‘居住面积’)
plt.ylabel(‘价格’)
plt.show()
根据程序输出,数据质量还可以,暂时不用进一步的处理
pandas 是一个数据分析库,提供了大量的数据结构和函数,用于高效地处理和分析结构化数据。
Matplotlib 是 Python 广泛应用的绘图库,可以创建各式各样的静态、动态及交互式可视化图形。
Seaborn 是基于 Matplotlib 的数据可视化库,提供更高级的统计图形接口,能够创建统计图形。
三、划分数据集
Kaggle 给提供了训练数据和测试数据,但一般我们还会在训练数据中拆出一部分数据做模型的评估
1.训练集:训练集是用于训练模型的数据,一般占总数据集的 60%-80%。
2.验证集:验证集不参与模型的训练,而是用来评估模型在未见过的数据上的表现,一般占总数据集的 10%-20%。
3.测试集:模拟真实世界的未知数据,用于最终评估模型的泛化能力,一般占总数据集的 10%-20%。

我们从训练集中划分出验证集,以便在模型开发过程中评估模型性能。
from sklearn.model_selection import train_test_split分离特征和目标变量(标签)
X = train.drop([‘SalePrice’, ‘Id’], axis=1) # 特征矩阵
y = train[‘SalePrice’] # 目标变量划分训练集和验证集
X_train, X_val, y_train, y_val = train_test_split(
X, y, test_size=0.2, random_state=42
)
print(f’训练集大小: {X_train.shape}‘)
print(f’验证集大小: {X_val.shape}’)
程序执行后训练数据被分为两部分:
训练集大小: (1168, 79)
验证集大小: (292, 79)
sklearn 是一个数据分析库,提供了大量的数据结构和函数,用于高效地处理和分析结构化数据。
四、特征工程
特征工程是提升模型性能的重要步骤,涉及选择有用的特征、生成新特征以及对特征进行转换。Kaggle的 House Prices 数据集包含大量有用的特征,其中既有数值型特征,也有类别型特征。我们对数据做几个处理
-
处理缺失值:
-
对于类别型特征,使用众数(出现次数最多的值)进行填充。
-
对于数值型特征,使用中位数进行填充。
-
编码类别变量:
-
使用 One-Hot 编码将类别型特征转换为数值型。
-
使用
align确保训练集和验证集具有相同的特征,缺失的特征填充为 0。
-
特征缩放:
-
使用
StandardScaler对数值型特征进行标准化,使其具有均值为 0,标准差为 1 的分布,有助于模型更好地收敛。
# 复制训练集和验证集 X_train_fe = X_train.copy() X_val_fe = X_val.copy()处理缺失值
for dataset in [X_train_fe, X_val_fe]:
for column in dataset.columns:
if dataset[column].dtype == ‘object’:
# 对于类别型变量,使用众数填充缺失值
dataset[column].fillna(dataset[column].mode()[0], inplace=True)
else:
# 对于数值型变量,使用中位数填充缺失值
dataset[column].fillna(dataset[column].median(), inplace=True)验证缺失值是否处理完成
print(X_train_fe.isnull().sum().max()) # 输出 0
print(X_val_fe.isnull().sum().max()) # 输出 0使用 One-Hot 编码处理类别型变量
X_train_fe = pd.get_dummies(X_train_fe)
X_val_fe = pd.get_dummies(X_val_fe)对齐训练集和验证集的特征矩阵
X_train_fe, X_val_fe = X_train_fe.align(X_val_fe, join=‘left’, axis=1, fill_value=0)
特征缩放
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train_fe)
X_val_scaled = scaler.transform(X_val_fe)
print(f’特征缩放后,训练集大小: {X_train_scaled.shape}‘)
print(f’特征缩放后,验证集大小: {X_val_scaled.shape}’)
One-Hot 编码是将类别型变量转换为数值型变量的一种常用方法,它会为每个类别创建一个新的二进制列,该列的值为 1 表示该样本属于该类别,为 0 表示不属于该类别。
特征缩放是对数据集中的特征进行转换,使得不同特征的取值范围大致相同。例如一个特征的取值范围在 0~10 之间,而另一个特征的取值范围在 1000~10000 之间,通过特征缩放可以将这些特征的取值范围调整到相近的区间,从而使模型能够更加公平地对待每个特征。
五、模型选择
房价预测是一个典型的回归任务,常用的模型包括线性回归、岭回归、决策树、随机森林、梯度提升树(如XGBoost、LightGBM)等,为了更好的选择模型,首先来了解一些基础概念。
拟合
拟合(Fitting)是机器学习和统计学中的一个基本概念,指的是构建一个模型,使其能够准确地描述或预测给定数据集中的模式和关系:
-
欠拟合(Underfitting):模型在训练数据和测试数据上都表现不佳,通常是由于模型过于简单,无法捕捉数据中的潜在模式。
-
过拟合(Overfitting):模型在训练数据上表现良好,但在未见过的测试数据上表现较差,通常是由于模型过于复杂,捕捉到了数据中的噪声,只是记忆了训练数据本身,没有找到背后的模式规律。
泛化是与拟合相对的概念,模型的泛化能力是用来衡量模型在训练数据以外数据上表现的指标,一个具有良好泛化能力的模型不仅能准确拟合训练数据,还能有效地预测和处理新的、看不见的数据。
模型复杂度
模型复杂度是一个用来衡量机器学习模型在结构、参数等方面复杂程度的指标,用来反映模型对数据的拟合与泛化之间的平衡关系。通常来讲复杂度低的模型容易欠拟合,复杂度高的模型容易过度拟合训练数据中的噪声和细节,泛化能力差。
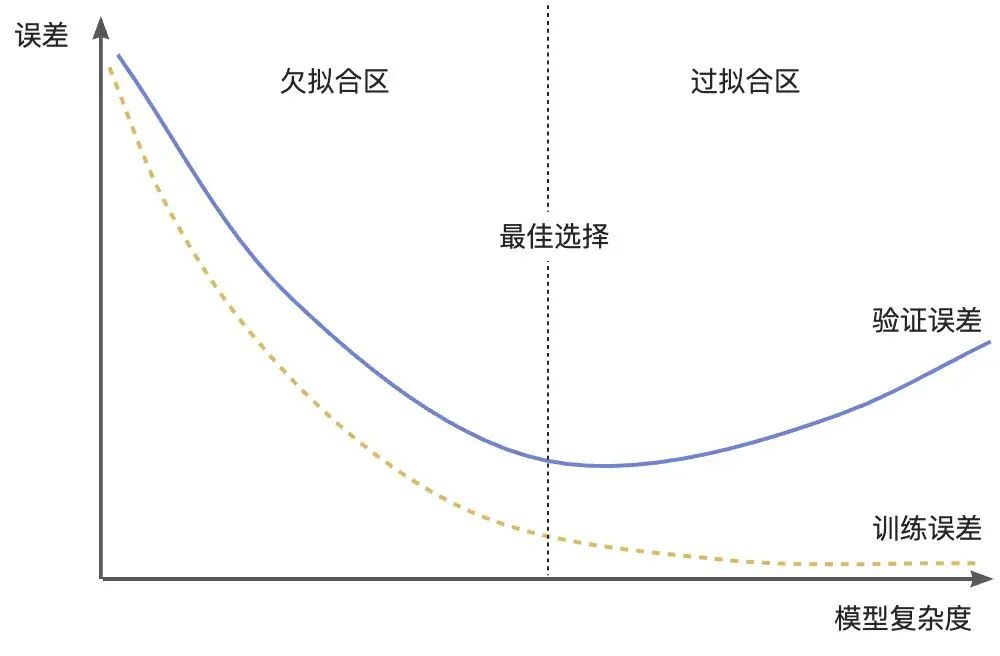
为了获得良好的泛化性能,需要在模型复杂度和过拟合、欠拟合之间找到一个平衡。从上图可以发现当模型复杂度太低时候,训练误差和验证误差都很大,模型欠拟合;当训练误差越来越小但验证误差越来越大时候意味着模型已经过拟合,而验证误差开始上升的点是我们想要的模型。
模型复杂度图有一个好处,无论数据集有多大,它看起来总是有两条曲线,训练误差总在下降,理想情况下验证误差先下降再上升。通常可以使用交叉验证、正则化等方法来调整模型复杂度,选择合适的模型结构和参数,使模型在训练数据上能够充分学习到数据的规律,同时在新数据上也具有较好的泛化能力。
正则化
正则化是用于防止模型过拟合、提高模型泛化能力的技术,通常过拟合是因为模型复杂,学习到了训练数据中的噪声和细节,而不是数据的真实规律。正则化的基本思想是在模型的损失函数(还记得开头提到过的 MSE 吗)中添加一个正则化项,对模型的复杂度进行惩罚,从而限制模型的参数取值范围,使得模型更加简单平滑,减少对训练数据的过拟合。有两种常见的正则化类型:
-
L1 正则化(Lasso 正则化):在损失函数中添加参数绝对值之和作为正则化项,具有特征选择的作用,它会使一些参数变为零,从而可以自动筛选出对模型重要的特征,减少模型的复杂度。
-
L2 正则化(岭回归):在损失函数中添加参数平方和作为正则化项,会使参数的值变小,但不会使参数变为零。它可以防止模型的参数过大,使得模型更加稳定,减少过拟合的风险。
使用正则化后,在训练过程中模型不仅要最小化原始的损失函数,还要考虑正则化项的影响,从而避免参数取值过大,使模型更加平滑。
决策树与随机森林
决策树是一种基于树形结构的模型。在模型中,每个内部节点表示一个特征的判断,每个分支代表判断结果,而每个叶子节点则给出最终的预测或决策。比如预测一张图片内的动物是否为 dog,每个叶子都包含一组可能的物种中的一种动物物种。
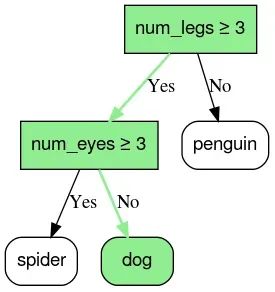
构建决策树主要是对每个候选特征,尝试找出一个分裂标准或阈值,使得数据依据这个特征被分成两个或多个子集后,子集内的样本更加同质,对于回归问题,通常使用 MSE 的降低量作为评价指标。
这一过程是递归的,从根节点开始,直到满足一定的停止条件。建成整棵树后,可以通过剪枝技术进一步简化模型,剪除对总模型预测贡献不大的分支,从而提高模型对新数据的泛化能力。
随机森林通过构建并结合多个决策树的预测结果,以获得更加稳定和准确的最终结果。主要构建过程是:
-
从原始训练集随机地抽取若干子样本,建立多个数据集。
-
在每个节点进行分裂时,不是考查所有特征,而是从随机选择的一部分特征中选择最佳分裂点。
-
训练完毕后,对于新的输入数据,每棵树给出一个预测,然后通过多数投票(或平均)的方式来决定最终结果。
这种随机性和多个模型的结合,使得随机森林在应对高维数据和具有噪声的数据时,通常比单一决策树有更好的泛化能力。
初次尝试可以从线性回归和随机森林开始
LinearRegression:是一种基本的线性回归模型,它通过 MSE 来拟合数据,从而找到最优的回归系数。
Ridge:是线性回归的一种扩展,也称为岭回归,它在普通线性回归的基础上增加了一个 L2 正则化,可以有效防止模型过拟合。
RandomForestRegressor:是一种基于决策树的集成学习模型,通过构建多个决策树并对它们的预测结果进行平均来进行回归预测。随机森林可以处理高维数据,具有较好的泛化能力和抗过拟合能力。
六、训练与调优
首先训练基线模型,然后通过调整超参数提升模型性能,使用交叉验证防止过拟合
-
训练基线模型:训练线性回归、岭回归和随机森林模型。
-
评估基线模型:使用验证集评估每个模型的均方误差(MSE)。
-
超参数调优:使用 GridSearchCV 对随机森林模型的超参数进行网格搜索,寻找最佳参数组合。
开始之前还是了解一些基础概念。
基础模型
基线模型是指在进行模型改进和优化之前,建立的一个简单、基础的模型。这个模型通常使用默认的参数设置和较为常规的方法构建,作为后续模型改进的参考标准。
超参数
超参数(Hyperparameter)是指在模型训练开始前,由用户预先设置的参数,用于控制整个训练过程和模型结构。模型参数(权重和偏置)是在训练过程中通过数据自动学习得到的,而超参数则是开发者根据经验、实验或者一些启发式方法在模型训练之前手动设置的。
超参数的选择可以显著影响模型的性能、有效性和效率,因此正确设置它们是机器学习模型优化过程中的重要步骤。常见的超参数包括:
1.学习率(Learning Rate):控制模型的权重更新幅度。学习率过大可能导致模型不稳定,过小则可能导致收敛速度过慢。
2.正则化参数:例如 L1 或 L2 正则化,用于控制模型复杂度和防止过拟合。
3.批次大小(Batch Size):每次训练模型时使用的数据样本数量。较大的批次可以提高训练效率,但可能需要更多的内存。
4.隐藏层数量和单元(Hidden Layers and Units):在神经网络中决定架构的复杂性。
5.决策树的最大深度(Max Depth of Decision Tree):限制树的最大层数,以防止过拟合。
交叉验证
交叉验证是一种评估和选择模型的技术,用于防止模型过拟合以及更准确地评估模型的性能。其基本思想:
-
当我们使用一个数据集来训练模型时,如果只在这个数据集上评估,很可能得到一个对训练数据很好的表现,但在面对新数据时可能效果不佳,这就是过拟合问题。
-
交叉验证通过把数据集划分成多个子集,让每个子集都轮流作为验证集,其余的数据作为训练集,从而可以对模型在不同数据划分下的表现进行充分的评估。
-
这种方法能够充分利用数据,每个样本既参与训练又参与验证,最终将多个验证结果汇总,给出更稳定、更可靠的模型性能估计。
开始训练
GridSearchCV 是 scikit-learn 库中用于超参数调优的工具,其主要作用是帮助你自动遍历预定义的超参数组合,通过交叉验证(Cross Validation)来寻找最佳的参数设置,从而优化模型性能。
-
根据提供的参数字典,生成所有可能的参数组合。如果有两个超参数,每个都有三个候选值,那么最终会有 3 × 3 = 9 种组合。
-
对于每一种超参数组合,GridSearchCV 都会使用交叉验证在训练数据上进行评估。
-
比较所有超参数组合对应的评估指标,根据指定的评分标准(如准确率、F1 分数、均方 MSE 等)选择出表现最好的超参数组合。
当然参数组合越多,交叉验证次数越多,总计算量成倍增加,对于计算开销较大的模型或大数据集,可考虑缩小参数范围或使用随机搜索(RandomizedSearchCV)。
from sklearn.metrics import mean_squared_error from sklearn.model_selection import GridSearchCV训练线性回归模型
lr.fit(X_train_scaled, y_train)
lr_preds = lr.predict(X_val_scaled)
lr_mse = mean_squared_error(y_val, lr_preds)
print(f’线性回归验证集MSE: {lr_mse}')训练岭回归模型
ridge.fit(X_train_scaled, y_train)
ridge_preds = ridge.predict(X_val_scaled)
ridge_mse = mean_squared_error(y_val, ridge_preds)
print(f’岭回归验证集MSE: {ridge_mse}')训练随机森林模型
rf.fit(X_train_fe, y_train)
rf_preds = rf.predict(X_val_fe)
rf_mse = mean_squared_error(y_val, rf_preds)
print(f’随机森林验证集MSE: {rf_mse}')超参数调优,使用网格搜索优化随机森林
param_grid = {
‘n_estimators’: [100, 200], # 随机森林中树的个数,尝试 100 和 200 两种设置
‘max_depth’: [None, 10, 20], # 每棵树的最大深度,尝试不限制、10 和 20 三种设置
‘min_samples_split’: [2, 5], # 继续分裂节点所需的最小样本数
}grid_search = GridSearchCV(
estimator=RandomForestRegressor(random_state=42), # 要优化的模型
param_grid=param_grid, # 参数网格
cv=5, # 将训练数据自动分为 5 个大致相等的子集,用于交叉验证
scoring=‘neg_mean_squared_error’, # 评估指标(负均方误差)
n_jobs=-1 # 并行计算,使用所有可用的CPU核来加速计算
)grid_search.fit(X_train_fe, y_train)
print(f’最佳参数: {grid_search.best_params_}‘)
print(f’最佳CV得分: {-grid_search.best_score_}’)使用最佳参数重新训练随机森林
best_rf = grid_search.best_estimator_
best_rf.fit(X_train_fe, y_train)
best_rf_preds = best_rf.predict(X_val_fe)
best_rf_mse = mean_squared_error(y_val, best_rf_preds)
print(f’优化后的随机森林验证集MSE: {best_rf_mse}')
执行后可以看到结果:
线性回归验证集MSE: 14189816400.231485
岭回归验证集MSE: 14289020855.107927
随机森林验证集MSE: 807947915.1960852
最佳参数: {'max_depth': 10, 'min_samples_split': 2, 'n_estimators': 100}
最佳CV得分: 957882699.9007219
优化后的随机森林验证集MSE: 834781203.5691917
优化后的随机森林验证集 MSE 竟然略大于随机森林验证集 MSE,略尴尬。。。可以使用不同的超参数组合“调参”或者使用贝叶斯优化等更高级的调优方法。
七、模型评估
在选择最优模型后,使用验证集进行最终评估,并进行误差分析以了解模型的不足。
RMSE 是“均方根误差”,也就是 MSE 的平方根,其单位与目标变量的原始单位一致,可以更直观地反映了预测误差的平均水平。
final_rmse = sqrt(best_rf_mse) print(f'最终随机森林验证集RMSE: {final_rmse}')误差分析
errors = y_val - best_rf_preds
plt.rcParams[‘font.family’] = ‘SimSong’ # 设置中文字体
plt.figure(figsize=(10,6))
sns.histplot(errors, bins=30, kde=True, color=‘red’)
plt.title(‘预测误差分布’)
plt.xlabel(‘误差 (实际 - 预测)’)
plt.ylabel(‘频数’)
plt.show()绘制实际值与预测值对比图
plt.figure(figsize=(10,6))
sns.scatterplot(x=y_val, y=best_rf_preds)
plt.plot([y_val.min(), y_val.max()], [y_val.min(), y_val.max()], color=‘black’, linestyle=‘–’)
plt.title(‘实际房价 vs 预测房价’)
plt.xlabel(‘实际房价 (美元)’)
plt.ylabel(‘预测房价 (美元)’)
plt.show()
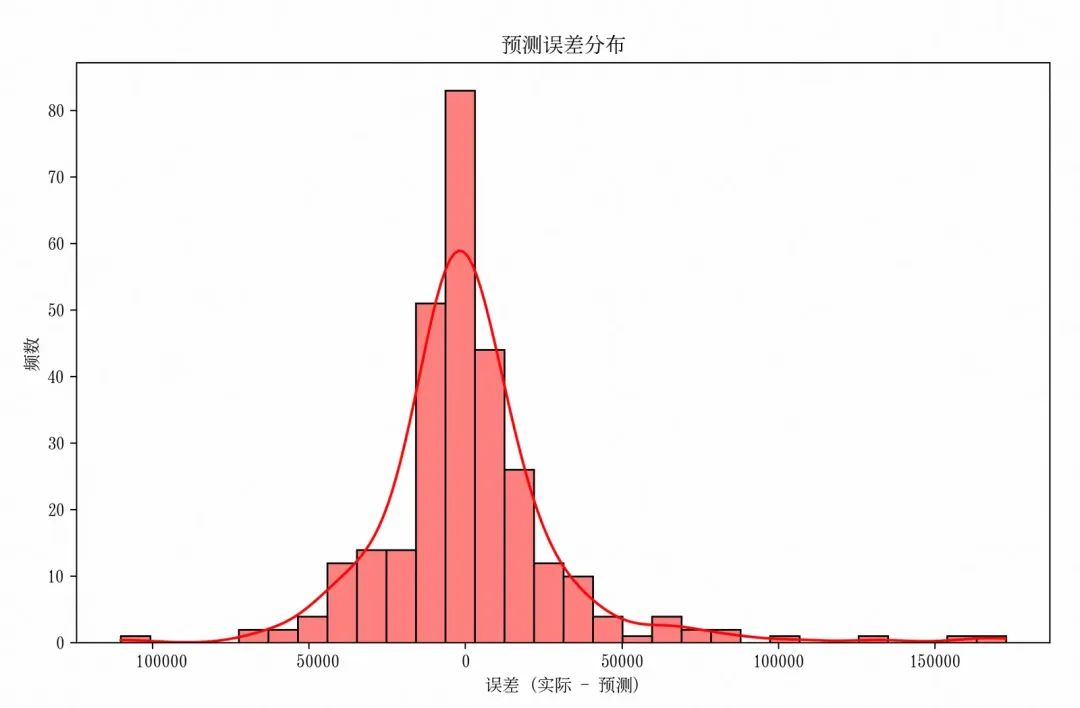
图中 RMSE 在 0 附近的频数最高,表明模型的大部分预测值与实际值较为接近,这是一个积极的信号,说明模型在多数情况下能够给出相对合理的预测。
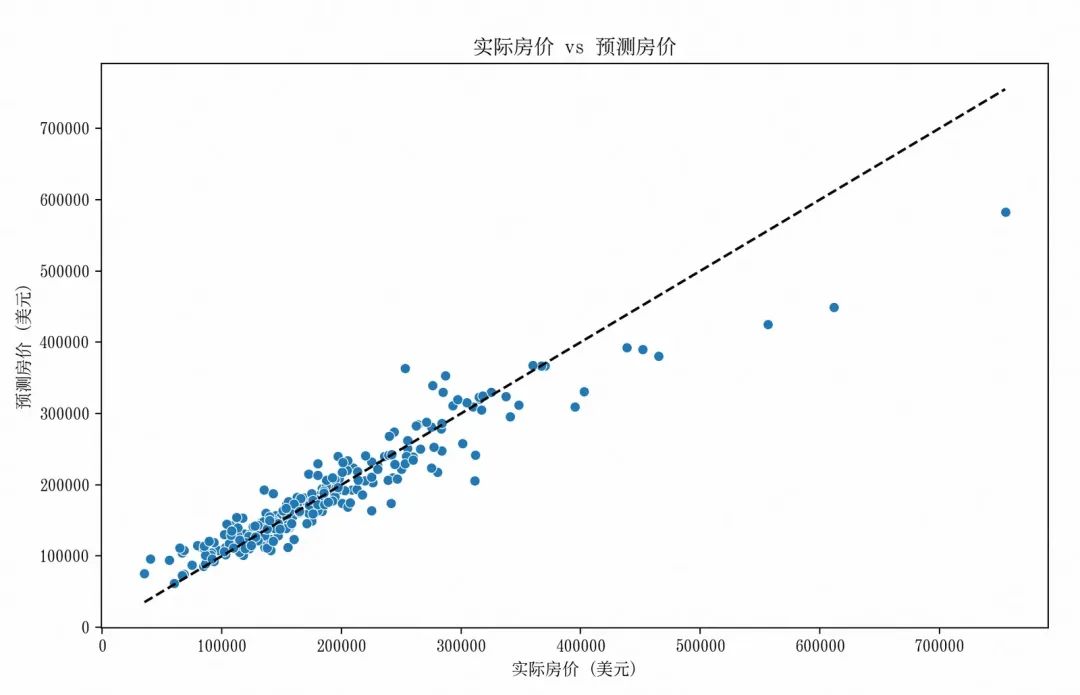
-
图中大部分点分布在对角线(理想预测线)附近,表明模型在一定程度上能够反映实际房价的趋势,对中低房价区域的预测有一定合理性。
-
然而在高房价区域(横轴和纵轴较大值处),点的分散程度明显增加,部分点偏离对角线较远,说明模型对高房价的预测准确性较差,可能在处理高价值样本或相关特征时存在不足。
八、优化改进
基于评估结果,可以从数据、特征和模型多个层面进行优化:
数据层面:
-
获取更多数据:采集更多相关数据,提升模型的泛化能力。
-
处理异常值:识别并处理数据中的异常值,以减少其对模型的负面影响。
特征层面:
-
生成新特征:如房屋总面积、房屋价值比率等。
-
特征选择:去除低相关性或冗余的特征,简化模型。
-
特征转换:对数变换、Box-Cox变换等,处理偏态分布的特征。
模型层面:
-
尝试其它模型:如梯度提升树(XGBoost、LightGBM)、支持向量机(SVM)等。
-
进一步超参数调优:扩展搜索范围或使用更高级的搜索方法(如随机搜索、贝叶斯优化)。
-
集成方法:结合多个模型的预测结果,提升整体性能。
我们通过三个手段优化模型:
-
生成新特征:通过组合现有特征生成新的特征,如总房间数,可能提升模型的表现。
-
特征选择:通过相关性分析选择与目标变量高度相关的特征,减少模型复杂度,提升性能。
-
重新训练模型:使用优化后的特征集重新训练随机森林模型,并评估其性能。
# 生成新特征:总房间数 X_train_fe['TotalRooms'] = X_train_fe['TotalBsmtSF'] + X_train_fe['1stFlrSF'] + X_train_fe['2ndFlrSF'] X_val_fe['TotalRooms'] = X_val_fe['TotalBsmtSF'] + X_val_fe['1stFlrSF'] + X_val_fe['2ndFlrSF']特征选择:选择与目标变量相关性较高的特征
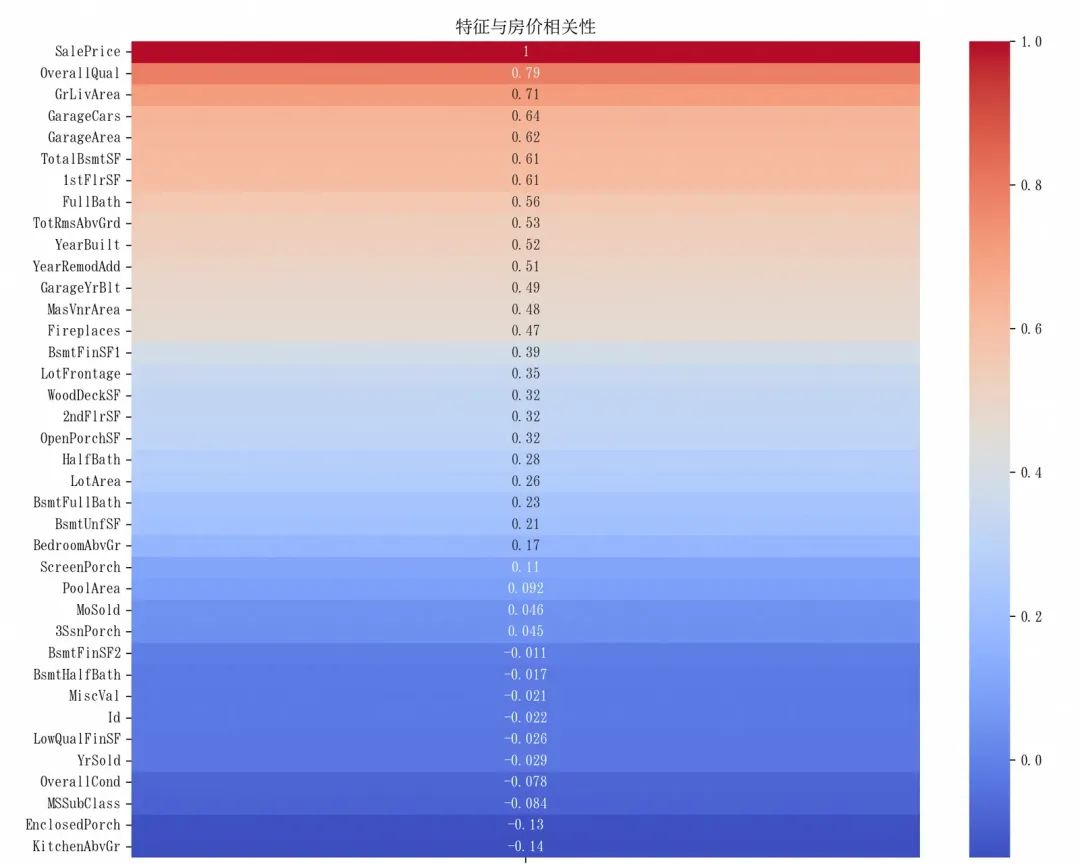
corr_matrix = train.corr(numeric_only=True)
假设选择相关性绝对值大于 0.12(反复试出来的)的特征
high_corr_features = corr_matrix[‘SalePrice’][corr_matrix[‘SalePrice’].abs() > 0.12].index
high_corr_features = high_corr_features.drop([‘SalePrice’]) # 去除目标变量本身重建特征集
X_train_selected = X_train_fe[high_corr_features]
X_val_selected = X_val_fe[high_corr_features]重新特征缩放
X_train_selected_scaled = scaler.fit_transform(X_train_selected)
X_val_selected_scaled = scaler.transform(X_val_selected)使用新的特征训练随机森林
best_rf.fit(X_train_selected, y_train)
new_rf_preds = best_rf.predict(X_val_selected)
new_rf_mse = mean_squared_error(y_val, new_rf_preds)
print(f’优化后随机森林验证集MSE: {new_rf_mse}')
线性回归验证集MSE: 12564956652.760109
岭回归验证集MSE: 12710807374.91197
随机森林验证集MSE: 760862367.6638939
最佳参数: {'max_depth': 20, 'min_samples_split': 2, 'n_estimators': 200}
最佳CV得分: 1096686290.3257225
优化后的随机森林验证集MSE: 756838039.5099173
最终随机森林验证集RMSE: 27510.68954988074
优化后随机森林验证集MSE: 755321480.0326563
九、部署与监控
一旦模型表现满意,就可以将其部署为服务,使其能够接受新数据并返回预测结果。同时,建立监控机制,确保模型在实际应用中的性能。
使用joblib将训练好的模型和Scaler持久化保存,以便在 API 中加载使用。
可以使用 Flask 写一个简单的测试:
from flask import Flask, request, jsonify import joblib import numpy as np import pandas as pdapp = Flask(name)
加载模型和Scaler
model = joblib.load(‘best_rf_model.joblib’)
scaler = joblib.load(‘scaler.joblib’)@app.route(‘/predict’, methods=[‘POST’])
def predict():
try:
data = request.get_json()
features = pd.DataFrame(data[‘features’])
# 预处理特征
# 需要与训练时的特征工程步骤一致
# 例如,生成新特征、编码类别变量、填充缺失值等
# 这里假设数据已经按模型要求处理完毕
prediction = model.predict(features)
return jsonify({‘prediction’: prediction.tolist()})
except Exception as e:
return jsonify({‘error’: str(e)})
if name == ‘main’:
app.run(debug=True)
十、反馈与迭代
部署后的模型需要持续监控其表现,并根据实际反馈进行改进。
1.监控模型性能:定期评估模型在新数据上的表现,确保其准确性。
2.数据更新:随着时间推移,数据分布发生变化,需要定期更新训练数据以保持模型的有效性。
3.迭代优化:基于监控和反馈结果,进行特征工程、模型调整或选择新模型。
假设我们发现模型在特定区域 LotArea 较小时预测误差较大,我们可以为这类房屋生成一个新的特征,例如是否小地块:
X_train_fe['Is_Small_Lot'] = X_train_fe['LotArea'] < 5000 X_val_fe['Is_Small_Lot'] = X_val_fe['LotArea'] < 5000重新特征选择和缩放
high_corr_features = corr_matrix[‘SalePrice’][corr_matrix[‘SalePrice’].abs() > 0.5].index
high_corr_features = high_corr_features.drop([‘SalePrice’]) # 去除目标变量本身X_train_selected = X_train_fe[high_corr_features]
X_val_selected = X_val_fe[high_corr_features]重新缩放
X_train_selected_scaled = scaler.fit_transform(X_train_selected)
X_val_selected_scaled = scaler.transform(X_val_selected)重新训练模型
best_rf.fit(X_train_selected, y_train)
new_rf_preds = best_rf.predict(X_val_selected)
new_rf_mse = mean_squared_error(y_val, new_rf_preds)
print(f’优化后随机森林验证集MSE: {new_rf_mse}')
最后
通过以上十个步骤,我们完成了从需求分析到模型部署开发房价预测模型的过程,作为开发工程师,借助 Python 强大的机器学习库,也可以轻松地构建、评估和部署模型。希望本文能帮助开发同学迈出机器学习的第一步。
参考链接:
Kaggle竞赛页面:https://www.kaggle.com/c/house-prices-advanced-regression-techniques
Quick BI 助力企业构建智能商业分析
针对企业在数据分析过程中面临的取数难、报表效率低和数据割裂等问题,Quick BI 支持通过自然语言完成看板搭建与数据获取,借助 AI 发现异常并归因,真正实现“对话即分析”,显著提升数据使用效率与用户体验,助力企业高效运营、科学决策。
点击阅读原文查看详情。