Meta AI或放弃“开源之光”身份,内部正讨论其最强模型Behemoth转向闭源,对依赖开源的开发者和学术界影响深远。
原文标题:内部爆料:Alexandr Wang上任第一把火,Meta大模型闭源
原文作者:机器之心
冷月清谈:
“Behemoth”模型已完成数据训练,但因内部性能表现不佳而延迟发布,目前高层团队正考虑放弃此模型,转而开发闭源版本。历史上,Meta的开源策略为其赢得了开发者广泛赞誉,首席AI科学家Yann LeCun也曾是开源的坚定支持者。Meta此举的背景是其通过投资Scale AI并聘请Alexandr Wang重组AI部门,旨在追赶谷歌、OpenAI等竞争对手,并掌握更多算力。
面对外界关注,Meta发言人表示,公司在开源AI方面的立场没有改变,计划继续发布领先的开源模型,但也会训练开源和闭源模型的组合。尽管讨论仍处于初步阶段,尚未做出最终决定,任何重大变化都需要CEO扎克伯格的批准。Alexandr Wang在内部会议中并未明确表态模型将采用开源还是闭源模式,为行业发展带来不确定性。与此同时,OpenAI也宣布无限期推迟开源模型,这引发了业内人士的担忧:如果顶级AI公司不再开源,依赖开源模型构建产品的创业公司和学术界将面临巨大挑战。
怜星夜思:
2、Meta和OpenAI都可能闭源,这让咱们这些靠开源吃饭的开发者和研究者咋办?难道以后只能用性能差一点的模型,或者得投入更多自己搞研发吗?
3、AI圈子里的“开源”和“闭源”之争,是不是会一直持续下去?大家觉得未来是会两边共存呢,还是说某个模式最终会独领风骚?
原文内容
编辑:张倩
曾经被称为「开源之光」的 Meta,之后可能也要走闭源路线了。

在 Meta 内部,关于 AI 发展路径出现了不同声音。包括新任首席 AI 官 Alexandr Wang 在内的一些高层领导建议,公司不应该将其最优秀的 AI 模型开源。然而,另一些高管则认为,在 Meta 努力追赶竞争对手的当下,开源策略仍然具有优势。
这一讨论的焦点集中在 Meta 最强大的开源 AI 模型「Behemoth」(Llama 4 最大版本)上。据 The Information 报道,Meta 最近几周暂停了 Behemoth 的部分工作。此前,Meta 已因性能问题延迟了 Llama 4 的两个版本,随后还延迟了推理版本和最大版本(即Behemoth)。
据知情人士透露,Meta 已完成对 Behemoth 模型的数据训练,但由于内部性能表现不佳而延迟发布。同时,内部人士称,超级智能实验室的高层团队上周讨论了放弃这一模型,转而开发闭源模型的可能性。
多年来,Meta 一直选择开源其 AI 模型。这一策略为 Meta 赢得了开发者的广泛赞誉。该公司首席 AI 科学家 Yann LeCun 曾表示「获胜的平台将是开放的平台」。
然而,任何转向闭源 AI 模型的举措都将是 Meta 在哲学层面和技术层面的重大转变。
Meta 的 AI 战略调整伴随着组织架构的重大变化。上个月,该公司完成了对 Scale AI 的 143 亿美元投资,获得 49% 的股份,并聘请 Scale AI 的 CEO Alexandr Wang 担任 Meta 首席 AI 官。
Meta 随后将整个 AI 部门重新命名为「Meta 超级智能实验室」,由 Alexandr Wang 领导。在更大的 AI 部门内,Alexandr Wang 领导着一个由十几名新聘研究员、Scale AI 的几名副手以及前 GitHub CEO Nat Friedman 组成的核心团队。
该团队在一个与公司其他部分隔离的办公空间工作,并且紧邻扎克伯格。最近,扎克伯格在采访中公开表示,在关于超级智能实验室成功招揽人才的种种报道中,有一个重要因素被忽视了,即对于更多算力的掌控。加入Meta超级智能实验室的人才都有很高的算力调度权。扎克伯格还指出,Meta 计划在 2026 年启用一个名为「普罗米修斯」(Prometheus)的 1GW 超级集群,这使其成为首批拥有如此规模人工智能数据中心的科技公司之一。

面对外界对后续路线的关注,Meta 发言人在声明中表示:「我们在开源 AI 方面的立场没有改变。我们计划继续发布领先的开源模型。我们历史上并没有发布所有开发的内容,预计未来将继续训练开源和闭源模型的组合。」
目前,超级智能实验室的讨论仍处于初步阶段,尚未做出最终决定,任何重大变化都需要 CEO 扎克伯格的批准。随着谷歌、OpenAI 和 Anthropic 等竞争对手在 AI 领域的激烈竞争,Meta 如何平衡开源理念与商业竞争需要,将成为业界关注的焦点。
在周二举行的问答会议上,Alexandr Wang 告诉约 2000 名 Meta AI 员工,虽然他的小团队工作将保持私密性,但 Meta 整个 AI 部门现在都将致力于创造超级智能。不过,他并未明确表态 AI 模型将采用开源还是闭源模式。这给整个 AI 行业的发展带来了不确定性。
与此同时,OpenAI 最近也宣布,开源模型将无限期推迟。
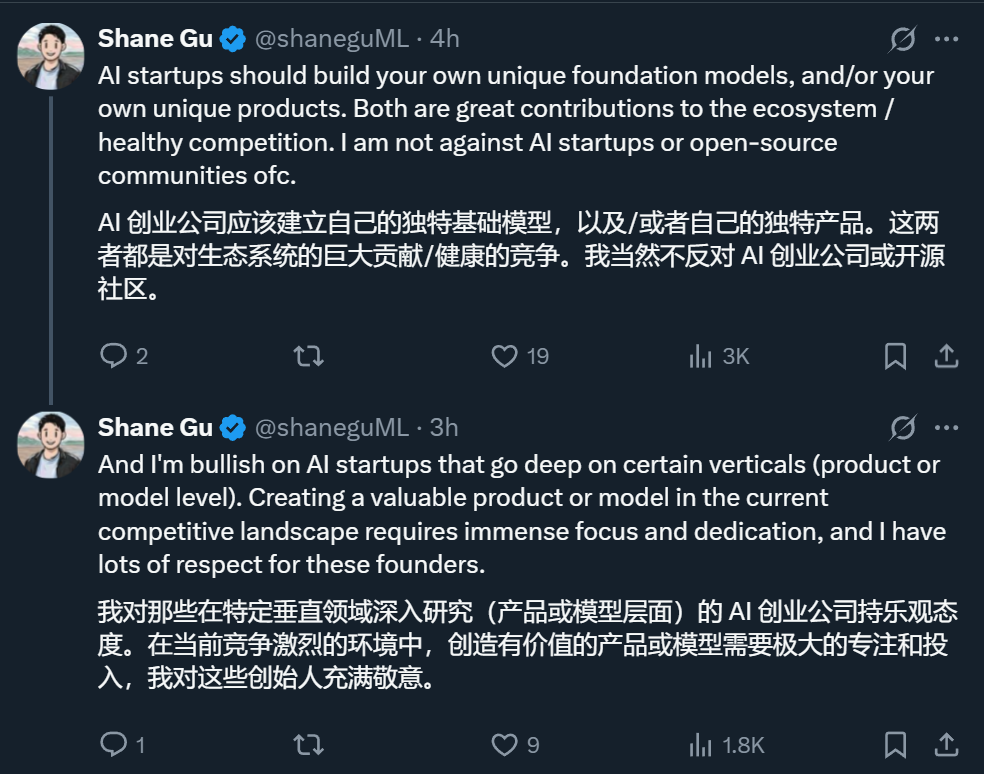
这一消息让不少人担心:如果 Meta 等顶级 AI 公司以后都不开源了,那些依赖开源模型打造产品的创业公司该怎么办?
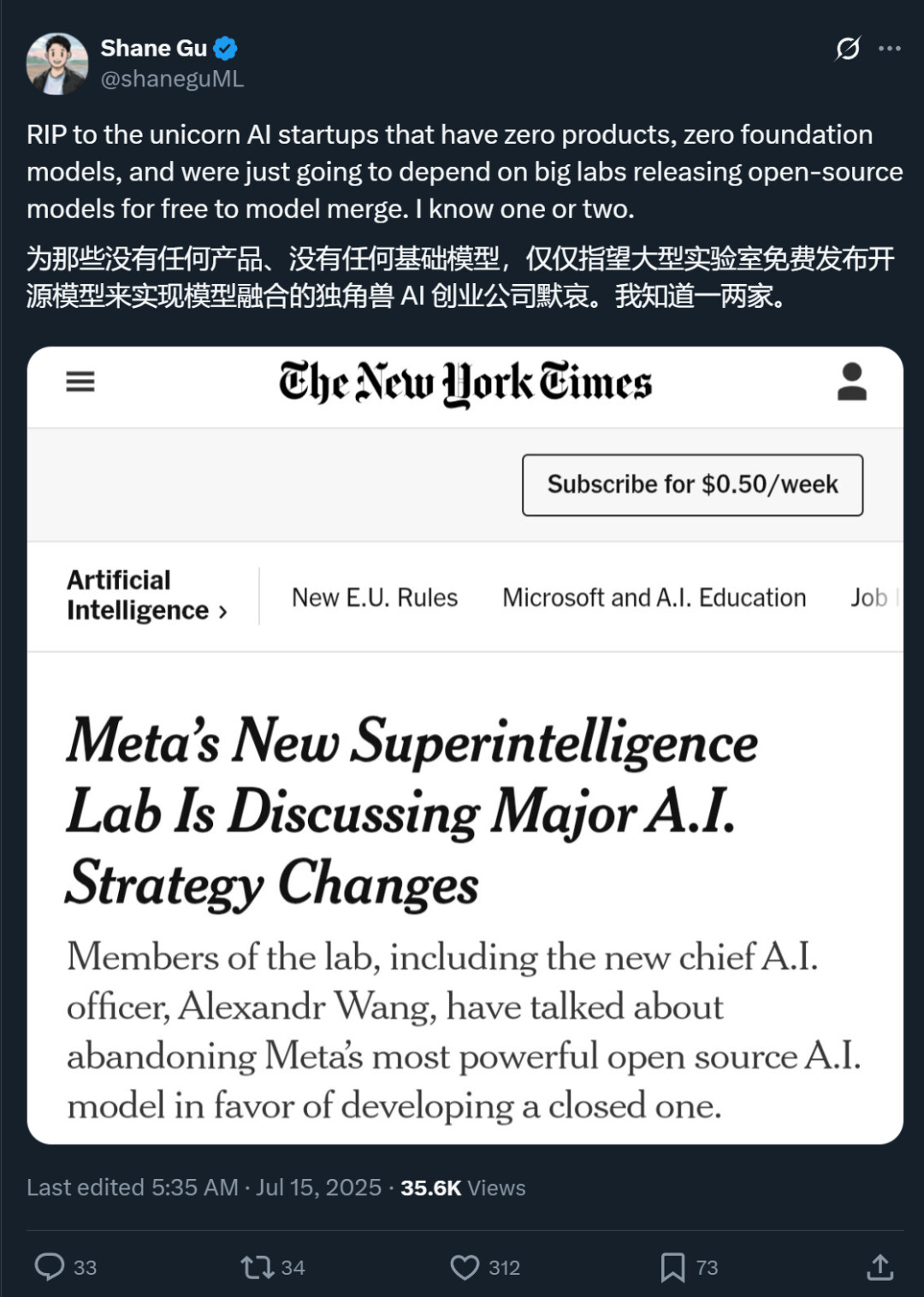
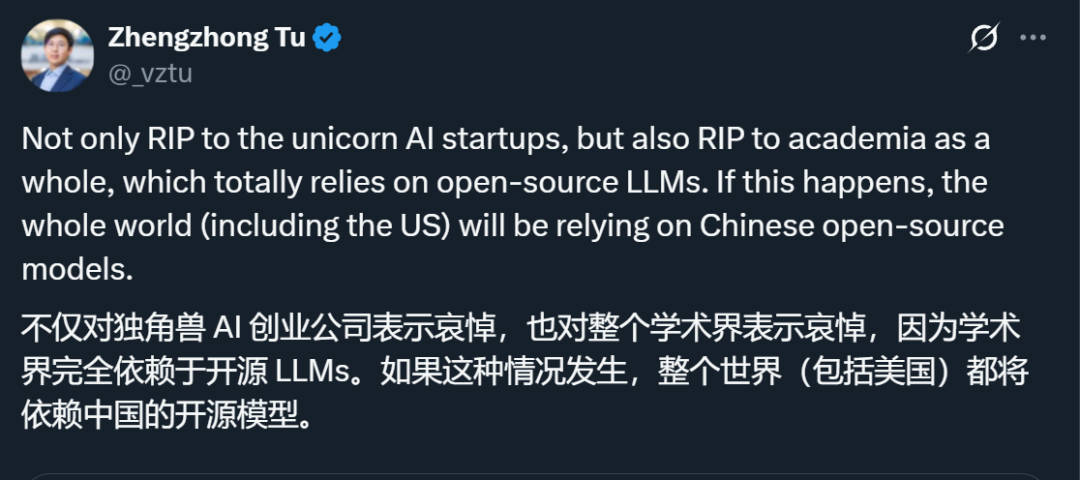
还有人指出,其实更应该担心的是学术界,因为学术界现在几乎完全依赖于开源模型。如果 Meta 不开源,美国学术界可能就要依赖中国的开源模型了。

不过,也有些人是有心理准备的,比如早早提出并实践「分布式训练」的从业者们。

开源和闭源,你觉得 Meta 会选哪条路?
参考链接:
https://www.theinformation.com/briefings/meta-discusses-developing-closed-ai-models?rc=vm2xxv
https://www.nytimes.com/2025/07/14/technology/meta-superintelligence-lab-ai.html

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com