Kimi K2万亿模型开源,性能与顶尖持平,三大创新技术重塑大模型训练。
原文标题:深夜开源首个万亿模型K2,压力给到OpenAI,Kimi时刻要来了?
原文作者:机器之心
冷月清谈:
Kimi K2的技术亮点主要体现在三个方面:
首先,它引入了全新的MuonClip优化器,解决了万亿参数模型训练中的稳定性问题。通过独特的qk-clip技术,该优化器能有效防止Attention logits爆炸,使得K2在15.5T tokens的预训练过程中未出现任何训练尖峰,大幅提升了token效率,为LLM训练开辟了新方法。
其次,为克服真实工具交互数据稀缺的难题,K2采用了大规模Agentic数据合成策略。通过模拟复杂的工具调用场景,生成多样化、高质量的数据,这不仅填补了特定领域的数据空白,还通过LLM评判员机制筛选出优质数据,为模型学习复杂工具使用能力奠定基础。
最后,Kimi K2引入了通用强化学习(General RL),结合自我评价机制,弥补了传统强化学习在非可验证任务中反馈信号不足的局限。模型能够充当自己的评判员,提供基于规则的反馈,并在可验证任务的策略回滚中持续更新评判员,实现了在各类复杂环境中持续优化的能力。
这些创新使得K2在不单纯依赖规模扩张的前提下,通过算法创新提升了模型效率和智能水平,预示着大模型技术竞争正从算力堆叠转向更高效、更智能的算法优化。
怜星夜思:
2、文章里提到Kimi K2在实际应用中能自动理解工具使用,不需要用户详细列出工作流程。你觉得这项“大模型智能体(Agentic)能力”在日常生活中最令人期待的应用场景有哪些?它会如何改变我们与AI的交互方式?
3、Kimi K2的开源,意味着顶级性能的大模型不再被少数公司垄断。对于个人开发者和中小型企业来说,开源大模型的普及是机遇还是挑战?他们该如何更好地利用开源模型来创新和发展?
原文内容
编辑:泽南、杜伟
没想到,Kimi 的首个基础大模型开源这么快就来了。
昨晚,月之暗面正式发布了 Kimi K2 大模型并开源,新模型同步上线并更新了 API,价格是 16 元人民币 / 百万 token 输出。


这次发布赶在了最近全球大模型集中发布的风口浪尖,前有 xAI 的 Grok 4,下周可能还有谷歌新 Gemini 和 OpenAI 开源模型,看起来大模型来到了一个新的技术节点。或许是感受到了 Kimi K2 的压力,就在刚刚,奥特曼发推预告了自家的开源模型。不过,网友似乎并不看好。
本次开源的共有两款模型,分别是基础模型 Kimi-K2-Base 与微调后模型 Kimi-K2-Instruct,均可商用。
-
博客链接:https://moonshotai.github.io/Kimi-K2/
-
GitHub 链接:https://github.com/MoonshotAI/Kimi-K2
根据 Hugging Face 页面数据显示,Kimi K2 的下载量在前 20 分钟便接近了 12K。
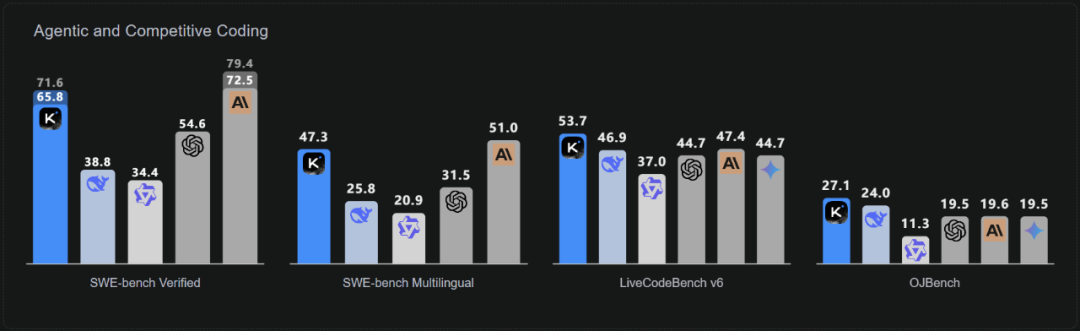
从 LiveCode Bench、AIME2025 和 GPQA-Diamond 等多个基准测试成绩来看,此次 Kimi K2 超过了 DeepSeek-V3-0324、Qwen3-235B-A22B 等开源模型,成为开源模型新 SOTA;同时在多项性能指标上也能赶超 GPT-4.1、Claude 4 Opus 等闭源模型,显示出其领先的知识、数学推理与代码能力。
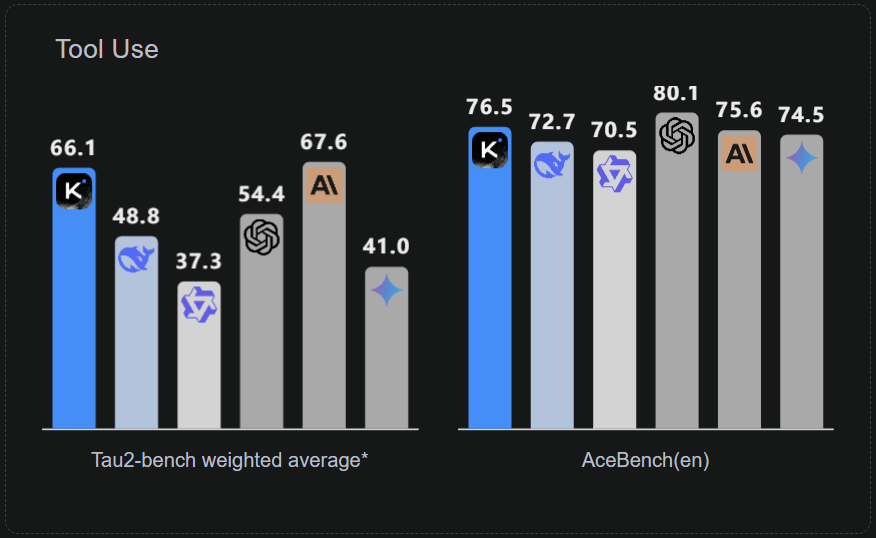
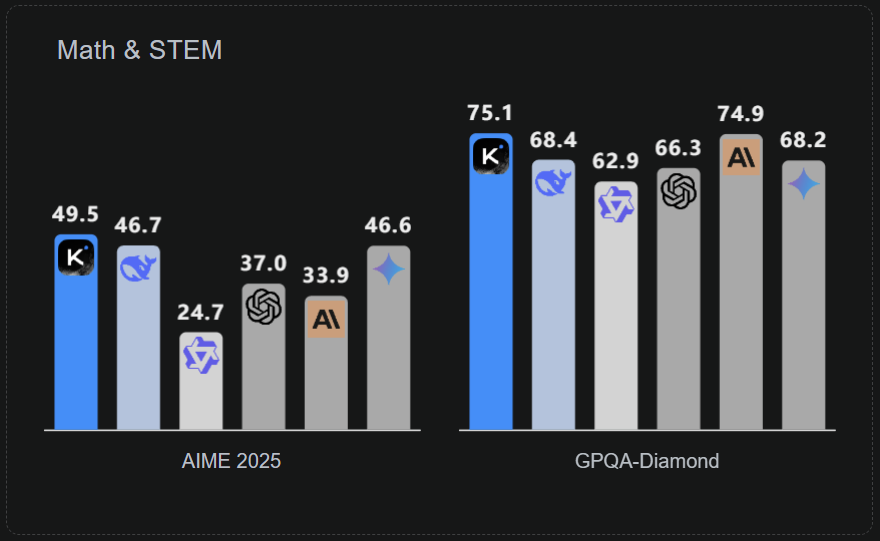
Kimi 展示了 K2 的一些实际应用案例,看起来它能自动理解如何使用工具来完成任务。它可以自动地理解所在的任务环境,决定如何行动,在下达任务指令时,你也不需要像以往那样为智能体列出详细的工作流程。
在完成复杂任务工作时,Kimi K2 会自动调用多种工具实现能力边界的扩展。昨天上线后,网友们第一时间尝试,发现可以实现不错的效果:


值得关注的是,就在昨天 Grok 4 发布后,人们第一时间测试发现其代码能力飘忽不定,但看起来 Kimi K2 的代码能力经住了初步检验。
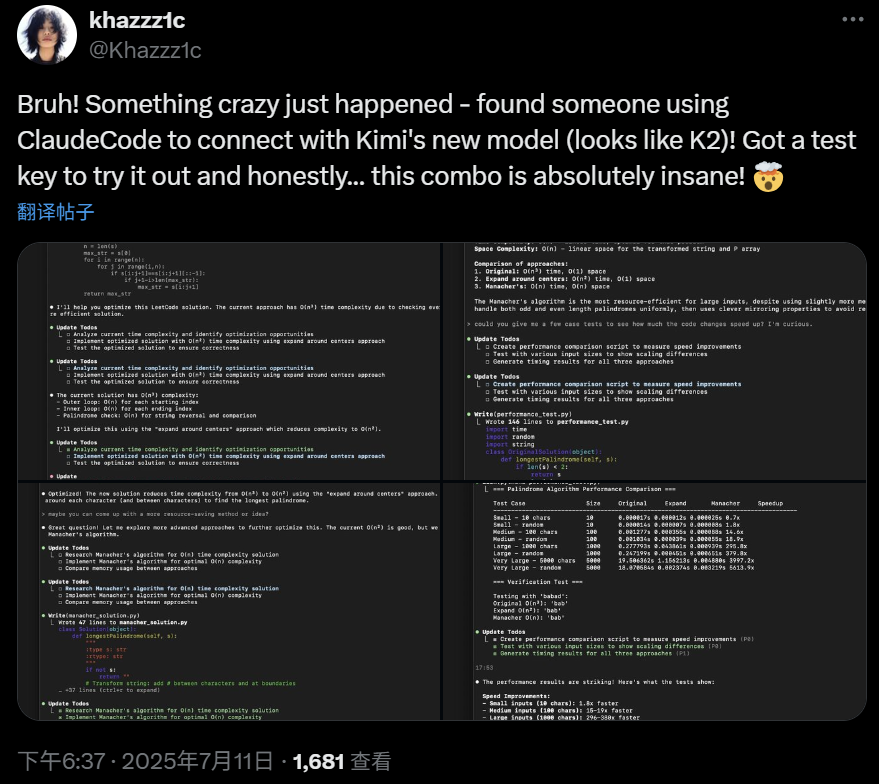
网友使用 Claude Code 链接 Kimi K2,发现效果不错。
从网友第一时间的测试来看,K2 代码能力是个亮点,因为价格很低,大家发现它可能是 Claude 4 Sonnet 的有力开源平替。有网友直接说 K2 是代码模型的 DeepSeek 时刻:

HuggingFace 联合创始人 Thomas Wolf 也表示,K2 令人难以置信,开源模型正在挑战最新的闭源权重模型。

在技术博客中,Kimi 也介绍了 K2 训练中的一些关键技术。
预训练数据 15.5T tokens
没用传统 Adam 优化器
首先,为了解决万亿参数模型训练中稳定性不足的问题,Kimi K2 引入了 MuonClip 优化器。
Muon 优化器作为一种优化算法,可以帮助神经网络在训练过程中更好地收敛,提升模型准确性和性能。今年 2 月,月之暗面推出了基于 Muon 优化器的高效大模型 Moonlight,证明这类优化器在 LLM 训练中显著优于当前广泛使用的 AdamW 优化器。
此次,Kimi K2 在开发过程中进一步扩展 Moonlight 架构。其中基于 Scaling Laws 分析,月之暗面通过减少 Attention Heads 数量来提升长上下文效率,同时增加 MoE 稀疏性来提高 token 利用效率。然而在扩展中遇到了一个持续存在的挑战:Attention logits 爆炸会导致训练不稳定,而 logit 软上限控制和 query-key 归一化等现有方案对此的效果有限。
针对这一挑战,月之暗面在全新的 MuonClip 中融入了自己提出的 qk-clip 技术,在 Muon 更新后直接重新缩放 query 和 key 投影组成的权重矩阵,从源头上控制 Attention logits 的规模,实现稳定的训练过程。
改进后的 MuonClip 优化器不仅可以扩展到 Kimi K2 这样万亿参数级别的 LLM 训练,还将大幅度提升 token 效率。一个更具 token 效率的优化器更能提升模型智能水平,这正是当前业界(如 Ilya Sutskever)看重的延续 Scaling Laws 的另一关键系数。
Kimi K2 的实验结果证实了这一点:MuonClip 能够有效防止 logit 爆炸,同时保持下游任务的性能。官方称,Kimi K2 顺利完成 15.5T tokens 的预训练,过程中没有出现任何训练尖峰,形成了 LLM 训练的一套新方法。
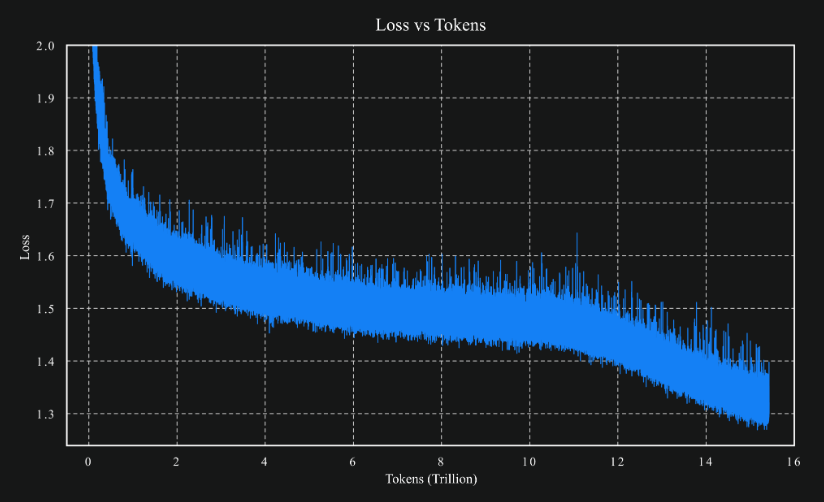
token 损失曲线
因此,相较于原始 Muon,MuonClip 取长补短,进一步放大其在预训练过程中的优势。自大模型技术爆发以来,优化器的探索方向不再是热门,人们习惯于使用 Adam,而如果想要进行替换,则需要大量的验证成本。Kimi 的全新探索,不知是否会成为新的潮流。
其次,为了解决真实工具交互数据稀缺的难题,Kimi K2 采用大规模 Agentic 数据合成策略,并让模型学习复杂工具调用(Tool Use)能力。
本周四,我们看到 xAI 的工程师们在发布 Grok 4 时也强调了新一代大模型的多智能体和工具调用能力,可见该方向正在成为各家公司探索的焦点。
Kimi 开发了一个受 ACEBench 启发的综合 pipeline,能够大规模模拟真实世界的工具使用场景。具体来讲,该流程系统性地演化出涵盖数百个领域的数千种工具,包括真实的 MCP 工具和合成工具,然后生成数百个具有多样化工具集的智能体。
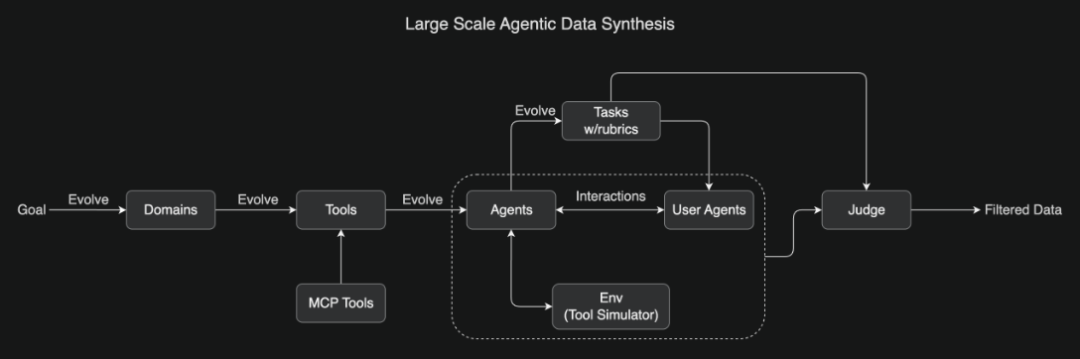
大规模 Agentic 数据合成概览
接下来,这些智能体与模拟环境、用户智能体进行交互,创造出逼真的多轮工具使用情景。最后,由一个大语言模型(LLM)充当评判员,根据任务评分标准(rubrics)评估模拟结果,筛选出高质量的训练数据。
一整套流程走下来,这种可扩展的 pipeline 生成了多样化、高质量的数据,有效填补特定领域或稀缺场景真实数据的空白。并且,LLM 对数据的评估与筛选有效减少低质量数据对训练结果的负面影响。这些数据层面的增强为大规模拒绝采样和强化学习铺平了道路。
最后,Kimi K2 引入了通用强化学习(General RL),通过结合 RL 与自我评价(self-judging)机制,在可验证任务与不可验证任务之间架起了一座桥梁。
在数学、编程等可验证任务上,我们可以根据正确答案、任务完成情况等可验证的奖励信号持续更新并改进对模型能力的评估。但是,传统强化学习由于依赖明确的反馈信号,因而在生成文本、撰写报告等不可验证任务中很难给出客观、即时的奖励。
针对这一局限,通用强化学习通过采用自我评价机制,让模型充当自己的评判员(critic),提供可扩展、基于 rubrics 的反馈。这种反馈替代了外部奖励,解决了不可验证任务中奖励稀缺的问题。 与此同时,基于可验证奖励的策略回滚(on-policy rollouts),持续对评判员进行更新,使其不断提升对最新策略的评估准确性。
这种利用可验证奖励来改进不可验证奖励估计的方式,使得 Kimi K2 既能高效地处理传统可验证任务,又能在主观的不可验证任务中自我评估,从而推动强化学习技术向更广泛的应用场景扩展。
从长远来看,Kimi K2 的这些新实践让大模型具备了在各种复杂环境中持续优化的能力,可能是未来模型智能水平继续进化的关键。
接下来,基模卷什么
Kimi 的发布,让我们想起前天 xAI 的 Grok-4 发布会,马斯克他们宣传自己大模型推理能力时,列出了基于通用 AI 难度最高的测试「人类最后的考试」Humanities Last Exam(HLE)上几个重要突破节点。
其中 OpenAI 的深度研究、Gemin 2.5 Pro 和 Kimi-Reseracher 都被列为了重要的突破:
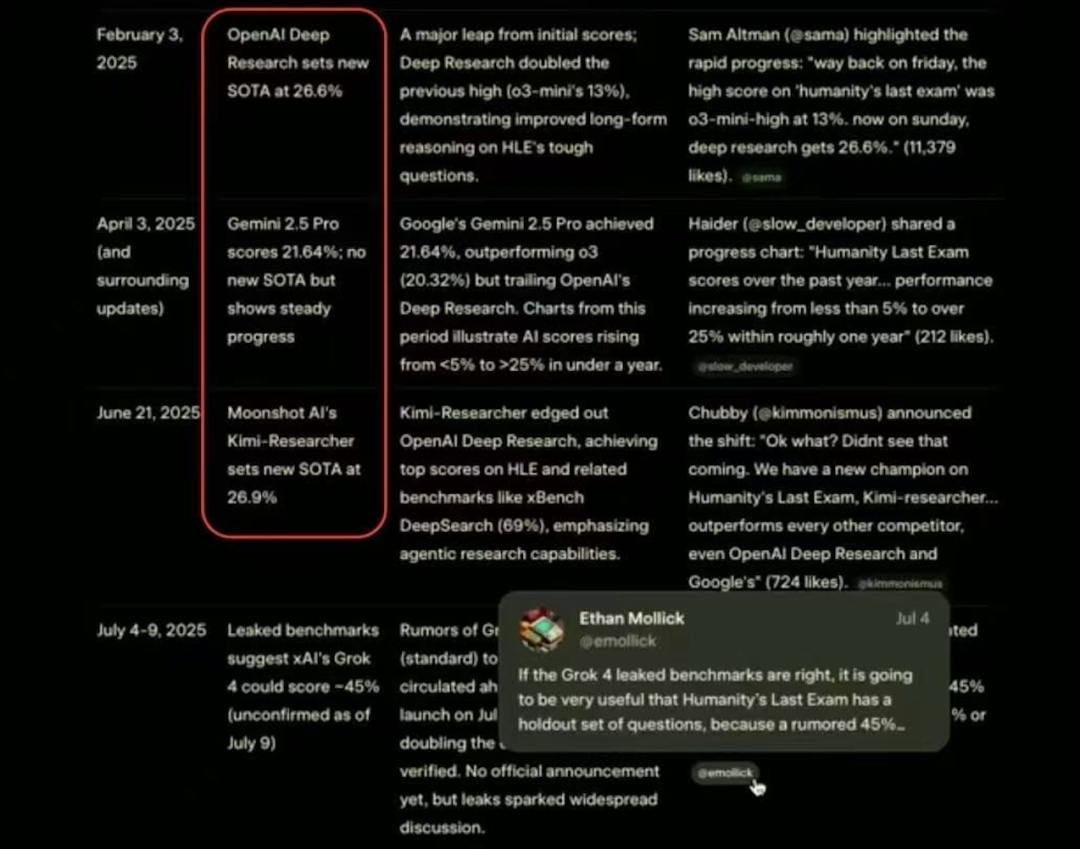
Kimi-Researcher 在上个月刚刚发布,其采用端到端自主强化学习,用结果驱动的算法进行训练,摆脱了传统的监督微调和基于规则制或工作流的方式。结果就是,探索规划的步骤越多,模型性能就越强。
而在 Kimi K2 上,月之暗面采用了与 Grok 4 类似的大规模工具调用方式。
另外,我们可以看到,由于国内算力资源的紧缺局面,新一波大模型技术竞争已经逐渐放弃单纯的堆参数、算力规模扩大的方式,在推动模型 SOTA 的过程中,通过算法上的创新来卷成本和效率成为趋势。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:[email protected]