ESA:图学习突破!基于边集合和端到端注意力机制,超越GNN与图Transformer,性能卓越!
原文标题:NC 2025 | 一种基于端到端注意力机制的图学习方法
原文作者:数据派THU
冷月清谈:
怜星夜思:
2、文章说ESA完全不依赖“消息传递”,这会不会意味着GNN的时代要终结了?未来的图学习是不是会彻底转向这种纯注意力模式,还是说消息传递和注意力机制会有某种结合,发挥各自优势?
3、ESA模型通过边集合建模,并且强调对错误连接的鲁棒性。在现实世界中,图数据往往会存在噪声或不完整。这种鲁棒性在处理‘不干净’的数据时,具体能带来哪些显著优势?比如,处理社交网络中的虚假关系或者生物分子结构中的实验误差?
原文内容


今天介绍一篇发表在 Nature Communications 的图学习论文《An end-to-end attention-based approach for learning on graphs》。该工作提出了一种全新范式的图学习方法 ESA(Edge-Set Attention),不再依赖传统的节点消息传递机制,而是将图建模为边集合,并通过纯注意力机制进行信息交互。该方法无需结构先验和位置编码,模型结构简洁却具备强表达力,在70项图与节点任务中大幅超越GNN与图Transformer,展现出优异的性能、鲁棒性与迁移能力,是一项值得关注的图学习基础模型探索工作。
1. 摘要
近期,基于 Transformer 的图学习架构蓬勃发展,主要原因是注意力机制作为一种有效的学习机制,以及其取代消息传递方案中手工编写算子的愿望。然而,人们对其经验有效性、可扩展性和预处理步骤的复杂性提出了担忧,尤其是在与那些通常在各种基准测试中表现相当的简单图神经网络相比时。为了解决这些缺陷,作者将图视为边的集合,并提出了一种纯粹基于注意力机制的方法,该方法由一个编码器和一个注意力池机制组成。编码器垂直交织掩蔽自注意力模块和原始自注意力模块,以学习边的有效表示,同时允许处理输入图中可能出现的错误指定。尽管该方法简单易懂,但在 70 多个节点级和图级任务(包括具有挑战性的长距离基准测试)上,该方法的表现优于经过微调的消息传递基线和最近提出的基于 Transformer 的方法。此外,作者在从分子图到视觉图以及异质节点分类等不同任务上展示了最先进的性能。该方法在迁移学习环境中也优于图神经网络和Transformer,并且比具有相似性能水平或表达能力的替代方案具有更好的扩展性。
2. 引言
图神经网络(Graph Neural Networks, GNNs)近年来已成为图结构数据建模的主流方法,凭借消息传递机制(Message Passing)在分子建模、社交网络分析、推荐系统等领域大放异彩。然而,随着研究的深入,其一系列局限性也逐渐显现:
-
设计繁复:GNN层通常依赖手工设计的邻居聚合函数,难以统一泛化,不同任务需专门调试。
-
过平滑问题:节点表示在多层传播中趋于一致,导致辨识度下降,尤其在异质图中表现不佳。
-
过压缩问题:长距离依赖信息容易在传播过程中被“挤压”丢失,影响预测性能。
-
迁移性差:与自然语言处理中的预训练-微调模式不同,GNN在跨任务迁移中效果有限。
为此,Transformer结构因其强大的表达能力和注意力机制被引入图学习领域,试图提供更灵活的建模方式。然而,图Transformer方法也面临一系列挑战:如需要复杂的结构/位置编码、大量预处理步骤,计算代价高昂,实际效果甚至不如调参良好的传统GNN。
在这一背景下,作者提出了一种完全基于注意力机制的图学习新范式——Edge-Set Attention (ESA),不再依赖“邻居聚合”这一传统思想,而是将图建模为边的集合,通过交替的 Masked Attention 与 Self-Attention 直接学习边表示,并通过注意力池化生成图级表征。模型不仅结构简洁,且摆脱了位置编码、结构预处理等繁琐步骤,在各类任务中展现出强大的性能和迁移能力,开启了图学习“后消息传递时代”的探索。
3. 方法
在传统图学习中,图被建模为“节点+邻居”的结构,而ESA(Edge-Set Attention)模型则彻底打破这一思维框架,提出一种更直接的视角:图 = 边集合(Edge Set)。
这意味着,ESA关注的不再是“节点怎么聚合邻居信息”,而是“边之间是如何相互关联”。换句话说,它从“边”的角度重塑了图神经网络的核心计算方式。
3.1 ESA 模型结构总览
ESA 主要由两个部分组成:
1.编码器(Encoder):
-
由多层 交替堆叠的 Masked Self-Attention 和 Vanilla Self-Attention 组成;
-
Masked Attention 只允许连接的边之间进行注意力交互;
-
Vanilla Attention 则允许任意边之间的信息传递,从而提升对输入图错误连接的鲁棒性。
2.注意力池化模块(Attention Pooling):
-
将所有边的表示聚合为图级表示,替代传统 GNN 中固定的sum/mean/max 池化。
3.2 ESA 模型结构图
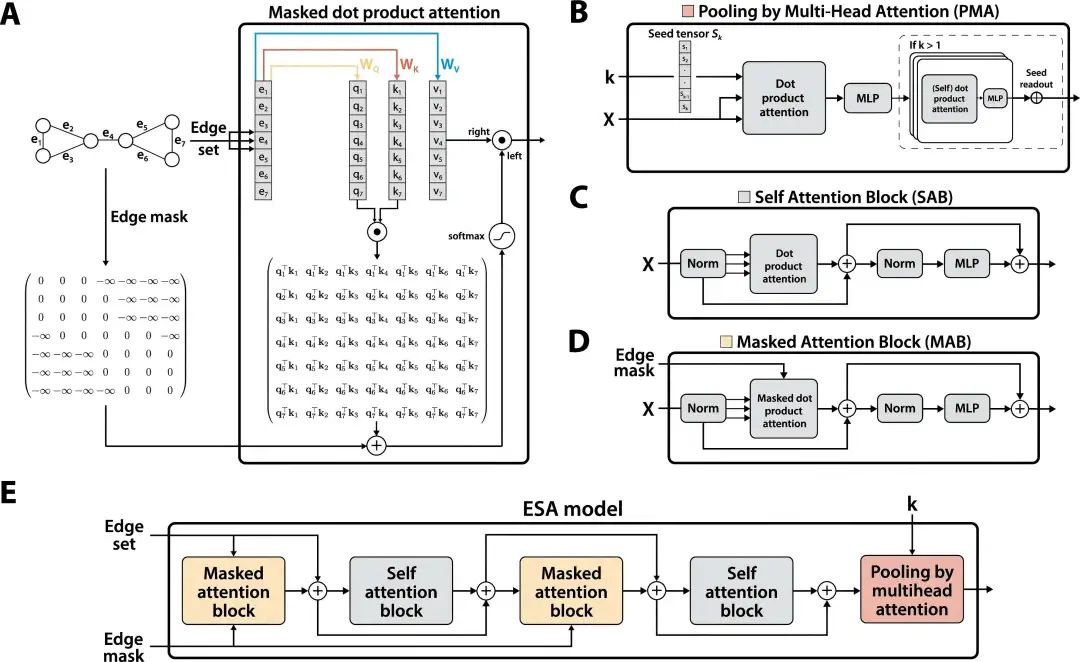
-
A. Masked Attention(左上): 对边之间进行注意力计算,仅允许存在共享节点的边对参与(即图结构中的真实连接)。边之间的连通关系通过一个Edge Mask 矩阵进行控制。
-
B–D. 模块组件:
-
B:PMA(Pooling by Multihead Attention):聚合边特征生成图表示;
-
C:SAB(Self Attention Block):边与边之间的全局自注意力交互;
-
D:MAB(Masked Attention Block):基于结构遮蔽的边注意力,强调图结构约束。
-
E. ESA整体架构(底部流程图):MAB 与 SAB交替堆叠,最后通过PMA模块进行图级聚合表示。整个流程不依赖位置编码和图结构预处理,简洁高效、易于迁移。
3.3 Masked Attention 工作机制
Masked Attention 的核心操作是:只在有连接的边之间计算注意力权重。
数学表达如下:
设 为边集合, 为两条边,若它们共享节点,则构成注意力连接:
其中:
-
是可学习的线性变换矩阵;
-
是从边 到 的注意力权重;
-
表示与 有共同节点的边集合。
论文中将这种机制称为 “边对之间的遮蔽注意力(Masked Attention)”,它对图结构中的“真实连接关系”具有结构感知能力。
4. 实验
ESA 模型在多达 70 个图学习任务上进行了全面评估,涵盖分子建模、图像图、社交网络图、节点分类等多个领域,展示出稳定领先的 SOTA 性能。
4.1 分子属性预测
-
代表性数据集:QM9、DOCKSTRING、PCQM4MV2、ZINC、MoleculeNet
-
ESA 在 QM9 数据集中 19 个目标属性中,有 15 个表现为最佳;
-
在药物筛选数据集 DOCKSTRING 上,ESA 在 5 个靶点中 4 个取得最优;
4.2 长距离图任务
-
任务来源:LRGB(Long Range Graph Benchmark)中的 PEPTIDES-STRUCT 和 PEPTIDES-FUNC
-
这类任务路径长、直径大,对模型建模能力要求极高。
-
ESA 在仅使用一半层数的情况下,超过 GraphGPS、TokenGT 和强GNN模型,展示出出色的全局建模能力。
4.3 图级分类任务
-
任务涵盖:
-
图像图(如 CIFAR-10、MNIST)
-
社交图(如 IMDB-B、IMDB-M、Reddit)
-
生物图与合成图(如 ENZYMES、PROTEINS、MalNet)
-
ESA 多次获得最佳 MCC(Matthews Correlation Coefficient),在任务小样本、结构复杂情况下仍保持鲁棒性。
4.4 节点级任务
-
节点分类任务包括同质图(如 Cora、PubMed)与异质图(如 Twitch、Reddit-Threads);
-
ESA 派生出 NSA(Node-Set Attention)模块,即不做图池化、直接输出节点嵌入,表现仍优于多个 GNN 和 Transformer 变体;
-
特别是在异质图上,表现明显优于 GAT、GCN 等经典方法,解决 GNN 过平滑问题。
4.5 模型效率表现
在 下图 中,ESA 在多个维度上展示出卓越的效率表现:
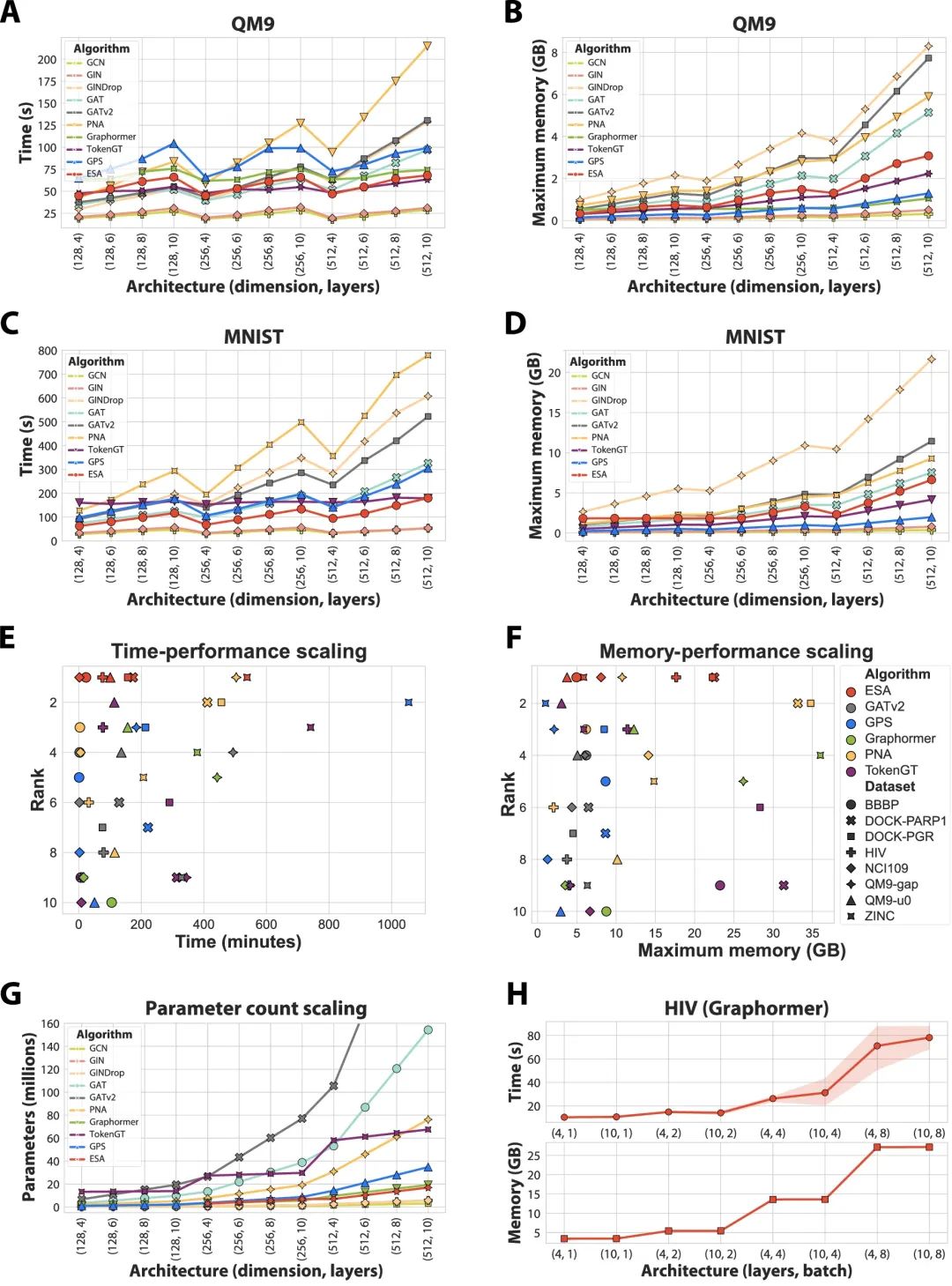
-
图 A & C:ESA 在 QM9 与 MNIST 数据集上训练耗时显著低于 TokenGT 和 Graphormer,即使模型层数和维度增加,增长速率也更缓和;
-
图 B & D:内存占用方面,ESA 同样比其他 Transformer 类模型更节省资源;
-
图 E & F:综合训练耗时与性能排名、内存与性能排名,ESA 处于右上角(性能高、资源低);
-
图 G:参数数量增长更为平稳,适合扩展;
-
图 H:在 HIV 数据集上,与 Graphormer 对比显示 ESA 在不同批量和层数设置下,始终保持较低的计算和显存开销。
4.6 模型可解释性分析
ESA 并非一个“黑箱”模型。在 Figure 3 中,作者进一步展示了 ESA 每一层注意力分数的基尼系数分布,以量化注意力的集中程度:
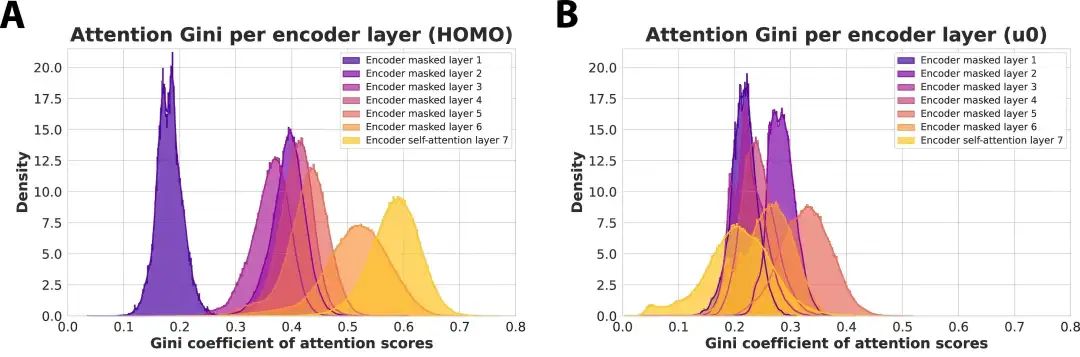
-
图 A(HOMO) 与 图 B(u0):展示在 QM9 数据集中预测量子属性时,不同编码器层的注意力稀疏性分布。
-
可以看出,越深的层,其注意力权重越集中,表明 ESA 能逐层聚焦关键边,具备结构上的可解释性和分层语义建模能力。
5. 结论与未来展望
本文提出的 ESA 模型以全新的边集合视角重构了图学习的方式,完全基于注意力机制,不依赖传统的消息传递框架、位置编码或结构先验。通过交替使用遮蔽注意力和自注意力,ESA 能够在保持图结构感知能力的同时,有效捕捉全局关系,具备更强的表达力与鲁棒性。尽管结构上极为简洁,但 ESA 在分子预测、图像图分类、社交网络分析等多个任务上均取得了显著优于现有 GNN 和图 Transformer 模型的性能,展示出其强大的通用性和实际应用潜力。ESA 的成功说明:图学习不必拘泥于节点聚合与邻居消息传递,全注意力机制也可以成为构建强大图表示模型的核心基础。这一工作为图学习方法的进一步发展提供了新的思路与方向。
6. 原文:
论文链接:
https://www.nature.com/articles/s41467-025-60252-z#Sec20
代码地址:
https://github.com/davidbuterez/edge-set-attention
编辑:于腾凯
校对:林亦霖

