MLLMs 长推理链反增幻觉,因视觉注意力减弱与语言主导。
原文标题:更长的推理链反而导致更多幻觉,MLLMs 幻觉解法仅「抄作业」还不够?摘要
原文作者:机器之心
冷月清谈:
分析认为,这主要源于现有 MLLMs 的架构和训练机制问题。结构上,模型采用“视觉编码器 + 接口模块 + 语言模型”组合,视觉特征被压缩,易导致“注意力漂移”,使模型更关注语言而非图像。加之语言模型规模远超视觉编码器,加剧了语言模态的主导地位。训练机制沿用“下一个 token 预测”,难以捕捉视觉空间结构与跨模态一致性,缺乏对整句语义合理性的约束。
怜星夜思:
2、长推理链反而更“幻”?MLLM 复杂任务路在何方?
3、MLLM 的幻觉,对“多模态智能”评估有啥新挑战?
原文内容
机器之心PRO · 会员通讯 Week 27
--- 本周为您解读 ② 个值得细品的 AI & Robotics 业内要事 ---
1. 更长的推理链反而导致更多幻觉,MLLMs 幻觉解法仅「抄作业」还不够?
更长的推理链为何反而使 MLLMs 产生更加严重的幻觉问题?相比于大语言模型的事实性错误和常识违背,MLLMs 在视觉任务上 「多」出了哪些幻觉?以往针对 LLMs 幻觉的方法,MLLMs 能否直接"抄作业"?为何视觉编码器的 「进化」 对解决 MLLMs 幻觉问题极为重要?RAG 方法对提升多模态生成的可信度是否依然奏效?

要事解读① 更长的推理链反而导致更多幻觉,MLLMs 幻觉解法仅「抄作业」还不够?
引言:近日,斯坦福大学、UCSB 及 USSC 的学者通过注意力分析发现,与 LLMs 不同的是,随着思维链(CoT)生成内容的变长,更长的推理链反而使多模态大模型(MLLMs)产生更强的幻觉。
更长的推理链为何反而使 MLLMs 产生更加严重的幻觉问题?MLLMs 的幻觉来源与 LLMs 有何不同?
1、测试时计算使得多模态大型语言模型能够生成扩展的推理链,然而斯坦福大学、UCSB 及 USSC 的学者观察到这种改进的推理能力常常伴随着幻觉的增加。[1-1]
① 随着生成内容的变长,模型倾向于偏离图像内容,更多地依赖语言先验。
② 通过注意力分析,研究团队发现更长的推理链会减少对视觉输入的关注,从而导致幻觉。
2、相较于传统大语言模型(LLMs)中对事实性错误的讨论,多模态模型(MLLMs)幻觉不仅涉及语言生成的偏差,更体现为跨模态的语义失配,即模型「看图说话」时对图像理解出现偏差,生成内容偏离甚至虚构了视觉细节。
① 在大语言模型中,幻觉主要被定义为输出内容与现实事实不符,例如虚构人物、伪造引用、逻辑冲突等。其根源多来自语言建模的泛化机制和训练语料中的偏误。
表:LLMs 和 MLLMs 幻觉对照表[1-1]-[1-18]
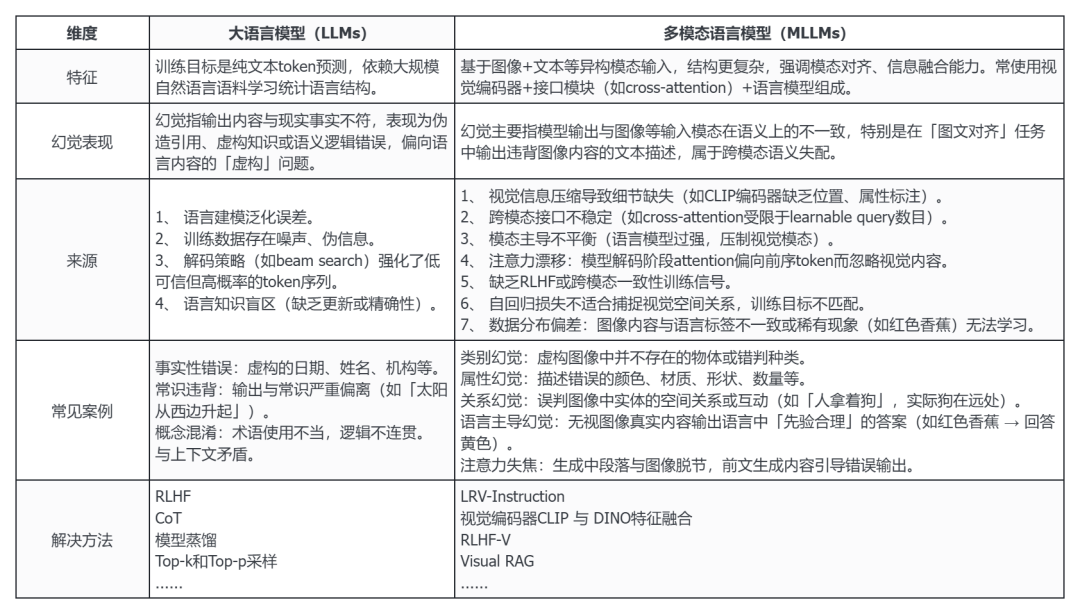
3、为何这些幻觉在多模态大模型中频发?其主要原因在于当前主流的多模态架构在结构设计和训练机制上均存在潜在失衡。
4、一方面,多模态大模型通常采用「视觉编码器 + 接口模块 + 语言模型」的模块化结构,主流接口包括 Cross-Attention(交叉注意力)机制和视觉投影(Projection Layer)机制。[1-2]
① Cross-Attention(交叉注意力)机制如 MiniGPT-4 中的 Q-Former,使用可学习的查询向量来捕捉图像特征。
② 视觉投影(Projection Layer)机制,如 LLaVA 中通过线性映射或 MLP 将视觉特征压缩映射至语言空间。
5、尽管这些接口在一定程度上实现了模态间的信息传递,但由于视觉特征被压缩为有限的 token,模型极易发生「注意力漂移」(Attention Drift)现象。
① 即在生成过程中,模型的自注意力机制更倾向于关注已有的语言 token,而非图像输入。
② 这种「语言主导」现象,在视觉挑战性较高(遮挡、模糊、罕见物体)或语言先验极强的场景中较为普遍。
6、另一方面,语言模型规模远大于视觉编码器(通常为 CLIP),加剧了语言模态对最终输出的支配倾向。
① 模型在「香蕉是什么颜色」这类问题上,可能更依赖其内部知识(即黄色)而非图像中的实际颜色(红色),造成输出事实与图像直接冲突。
7、在训练机制上,目前多模态仍沿用大语言模型中的「下一个 token 预测」作为核心训练损失(Autoregressive Loss),这种 token 级别监督方式难以捕捉视觉内容的空间结构与跨模态一致性,尤其缺乏对整句语义合理性或跨模态对齐的约束。