上交大提出EEdit框架,通过减少扩散模型图像编辑中的时空冗余,实现免训练加速,多种引导方式,效果SOTA。
原文标题:ICCV 2025|降低扩散模型中的时空冗余,上交大EEdit实现免训练图像编辑加速
原文作者:机器之心
冷月清谈:
怜星夜思:
2、EEdit框架是如何做到“无需训练”就能实现加速的?这种免训练加速方法有什么优势和局限性?
3、EEdit框架中提到的“区域分数奖励”机制是如何工作的?它是如何平衡编辑区域的更新频率和非编辑区域的计算开销的?
原文内容

本论文共同第一作者闫泽轩和马跃分别是上海交通大学人工智能学院2025级研究生,以及香港科技大学2024级博士生。目前在上海交通大学EPIC Lab进行科研实习,接受张林峰助理教授指导,研究方向是高效模型和AIGC。
本文主要介绍张林峰教授的团队的最新论文:EEdit⚡: Rethinking the Spatial and Temporal Redundancy for Efficient Image Editing。
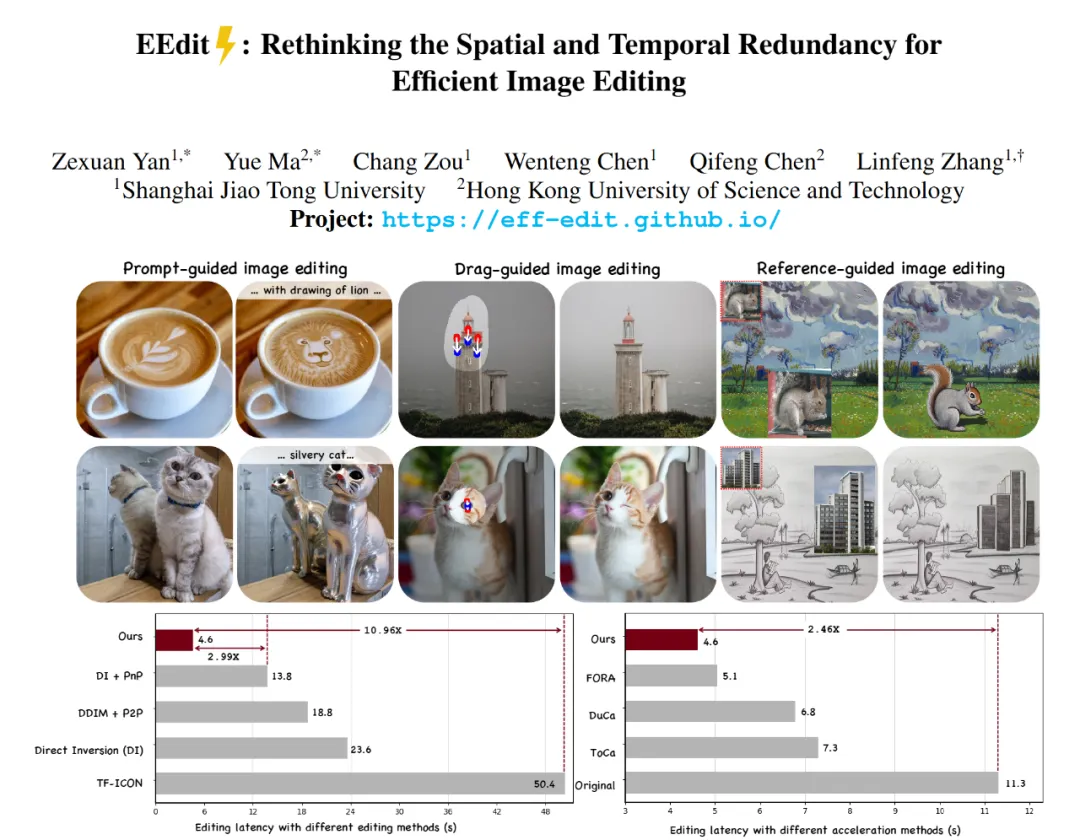
这是首个用于加速匹配流模型上兼容多种引导方案的图像编辑框架。该框架速度提升显著,较原始工作流可加速2.4倍;并且输入引导条件灵活,支持包括参考图像引导,拖拽区域引导,提示词引导的多种编辑任务;该框架采用免训练的加速算法,无需微调和蒸馏。
该论文已经入选ICCV 2025。
-
论文链接:
https://arxiv.org/pdf/2503.10270
-
论文已开源:
https://github.com/yuriYanZeXuan/EEdit
最近,基于流匹配(Flow Matching)的扩散模型训练方式逐渐成为扩散模型的热点,以其优雅简洁的数学形式和较短时间步的生成能力吸引了许多研究者的关注。其中以Black Forest Lab开发的FLUX系列模型为主要代表,它在性能和生成质量上超过了以往的SD系列模型水平,从而达到了扩散模型领域的SOTA水平。
然而,扩散模型在图像编辑上的表现还存在诸多痛点,包括所需时间步数量较多,反演过程开销大但是对最终编辑结果质量影响有限,更重要的是,非编辑区域的计算带来的不必要的开销,造成了计算资源的巨大浪费。此外,在各种类型的编辑引导方法上,流匹配模型当前还没有一个统一的方案进行应用和加速。对于图像编辑任务中由于时空冗余性所带来的计算开销问题,当前学界的研究还处于初级阶段,相关研究内容还是一片蓝海。
面对当前研究现状,上海交通大学EPIC Lab团队提出了一种无需训练的高效缓存加速编辑框架EEdit。
其核心思想在于,在一个基于扩散模型的反演-去噪的图像编辑过程中,使用输出特征复用的方式在时间冗余性上压缩反演过程时间步;使用区域分数奖励对区域标记更新进行频率控制,非编辑区域复用缓存特征,同时又尽量多地更新编辑区域对应的标记从而达到高效计算的目标。
EEdit具有几个重要的亮点:
1. 无需训练,高效加速。EEdit基于开源的FLUX-dev模型进行推理,无需任何训练或蒸馏,相较于未加速版本达超2.4X推理速度,而相比于其他类型的图像编辑方法最快可达超10X加速。
2. 在图像编辑领域中,首次发掘并尝试解决了由于时空冗余性带来的计算开销浪费的问题。通过反演过程特征复用和区域分数奖励控制区域标记计算频率从而降低编辑任务中模型计算额时空冗余性。
3. 适配多种输入类型引导。该编辑框架适配多种引导类型的编辑任务,包括参考图像引导的图像合成,提示词引导的图像编辑,拖拽区域引导的图像编辑任务。
接下来,我们一起来看看该研究的细节。
研究动机
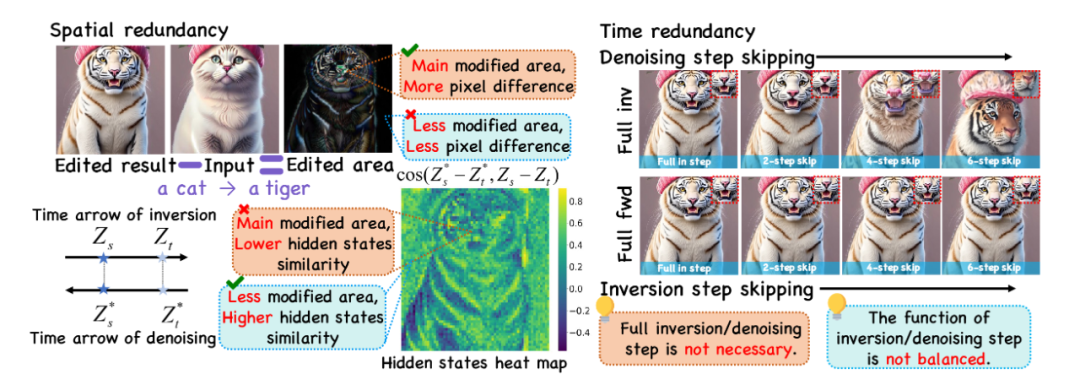
图表1在将猫->虎的编辑案例中发现的模型计算开销的空间和时间冗余
本文作者在一个图像编辑的实际案例中发现了存在于基于扩散模型的图像编辑任务中的时空冗余性。
非编辑区域相对于编辑区域存在更高的空间冗余 ,在像素级别的差分可视化图像中,编辑区域(动物脸部,毛发纹理部分)存在高亮区域表明这里存在较大的变化幅度,其余黑色区域代表了非编辑区域基本无变化幅度。本文作者将隐藏层按照空间上的对应关系进行重排并使用热力图进行可视化。在隐藏层状态的差分余弦相似度热力图中,也可以发现一致的空间冗余性:编辑区域在反演-去噪过程的前后阶段有较低的相似度,而非编辑区域有更高的相似度。
反演过程相对于去噪过程存在更高的时间冗余,本文作者在一个完整时间步中的反演-扩散过程中分别通过复用来控制跳过一定比例的时间步带来的模型计算。完整反演过程下,缩减去噪时间步编辑结果呈现迅速崩坏的现象;相反,完整去噪过程下,缩减反演时间步编辑结果仍然与完整计算基本保持一致。鉴于扩散模型在每一个时间步的完整计算都需要数据通过整个模型,减少冗余的时间步对于加速编辑延迟有着立竿见影的效果。
方法简介
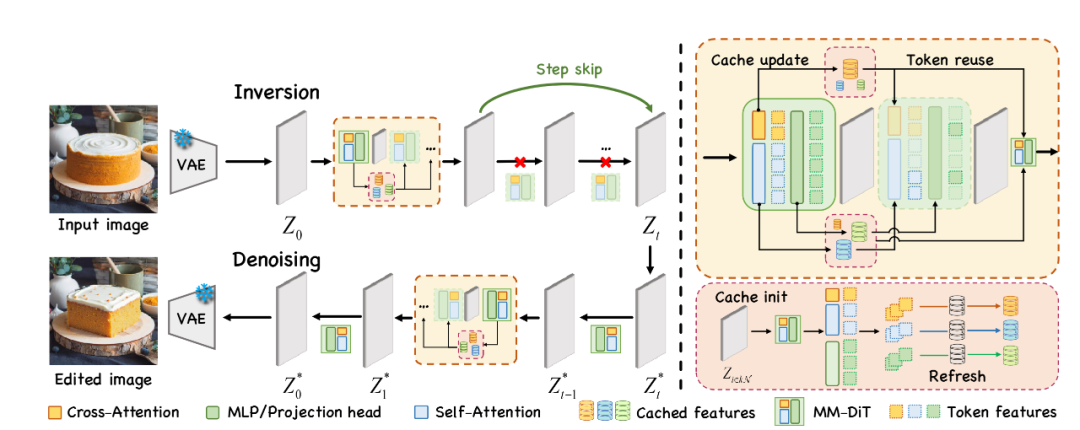
图表2基于扩散模型反演-去噪范式编辑框架的缓存加速方案
基于MM-DIT扩散模型的图像编辑的框架采用了一种有效免训练方法。编辑框架采用原始图像和编辑提示为输入。具体而言,在反演和去噪的两个过程中,固定的时间步周期进行刷新,而对于周期内时间步,则采用用于更新缓存的部分计算。反演过程中本文作者还额外采用了直接复用模型输出特征来跳过计算的反演过程跳步(Inversion Step Skipping, ISS)技巧。
而对于缓存更新的部分,作者精心设计了空间局域缓存算法,具体设计如下:
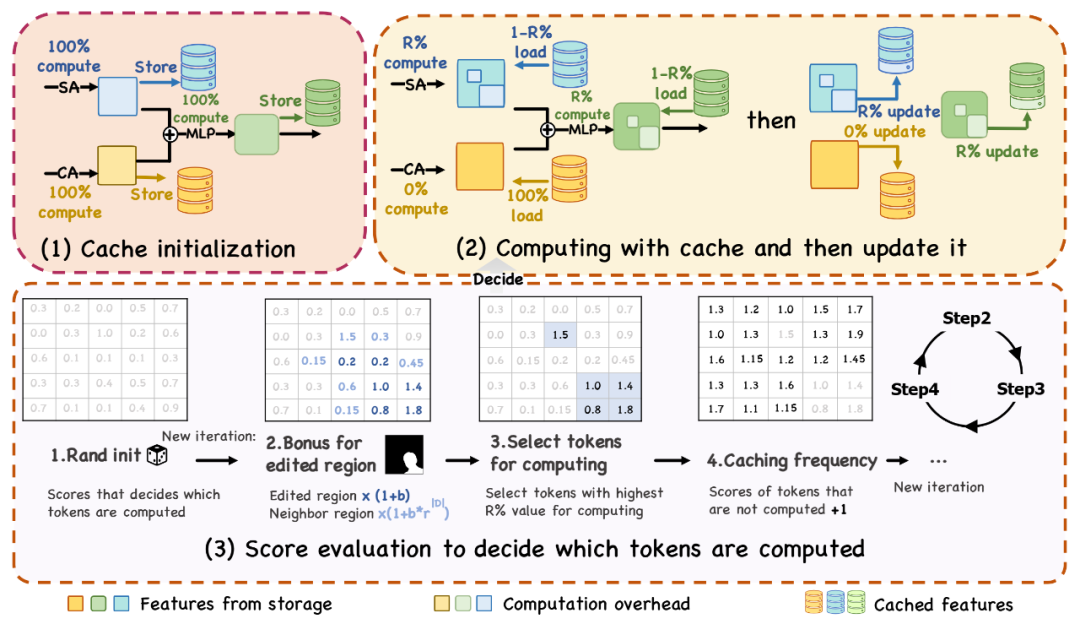
图表3用于缩减空间冗余性的空间缓存算法设计
对于图像编辑过程中存在的空间冗余,本文作者巧妙地设计了一种利用图像输入的编辑区域掩码作为空间知识先验来针对性地更新feature tokens的缓存算法。空间局域缓存算法(Spatial Locality Caching, SLoC)是一种即插即用的针对MM-DiT的缓存算法。该算法针对MLP,Cross-Attention, Self-Attention的不同组件都可以进行缓存加速。SLoC会在初始化阶段和固定周期时间步上进行完全计算以减少漂移误差,在周期内会部分计算自注意力和多层前馈神经网络部分的feature tokens并及时更新到缓存中。
SLoC的核心在于对于分数图(Score Map)的细粒度控制来改变不同空间区域所对应的feature tokens经过计算的频率,具体而言:
1. 初始化时会使用随机种子将整个分数图随机初始化,此时所有feature tokens的评分都是服从于高斯分布的随机均匀分布。
2. 对于被编辑区域的feature tokens乘以一个系数作为区域分数奖励,对于相邻区域则乘以一个随L1距离衰减的系数,从而按照编辑区域分布来改变分数图的数值分布。
3. 按照分数图数值排序后的前R%数值对应的索引下标来选取feature tokens,送入模型层进行计算并更新缓存。
4. 对于未被选中的feature tokens,会给予分数图的递增补偿,从而平衡不同区域间的计算频次。对于被选中的feature tokens,该递增补偿会重新累计。
作者还采用了缓存索引预处理(Token Index Preprocessing, TIP)的技巧,具体来说,作者还利用了缓存更新算法中下标索引与具体向量内容的无关性,将缓存更新索引的更新逻辑可以从在线计算方式等价地转变成离线的预处理算法,从而使用集中计算来加速这一缓存的更新过程。
总而言之,通过空间可感的缓存更新和重用算法,SLoC作为EEdit的核心组件发挥了在保证图像编辑质量无损的前提下,加以TIP的技巧使得EEdit达到了相对于未加速的原始方案超过2.4X的加速比。
实验结果
本文在FLUX-dev的开源权重上进行实验,在包括PIE-bench,Drag-DR,Drag-SR,以及TF-ICON benchmark四个数据集上进行了详细的定性和定量实验,对EEdit的性能和生成质量进行检验。
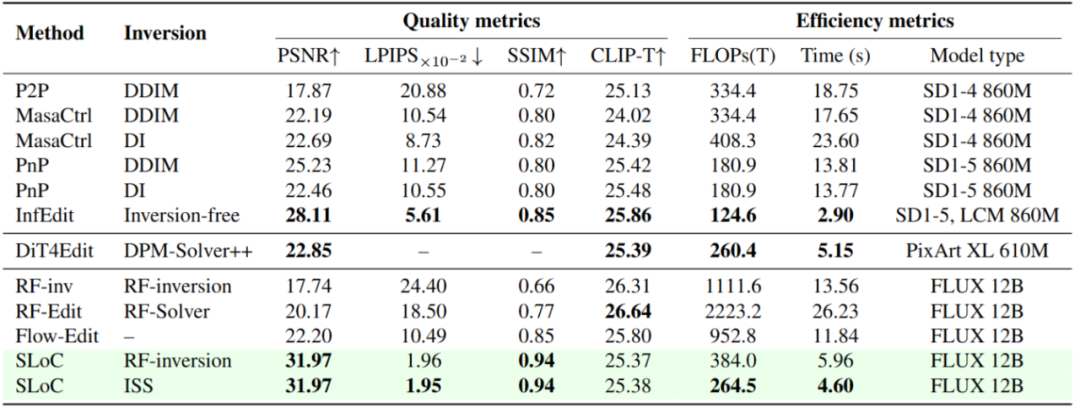
图表4 SLoC在各种指标上与已有的SD系列模型,FLUX系列工作的对比
定量评估维度包括生成领域常用的PSNR,LPIPS,SSIM,CLIP,也包括定量衡量模型效率的FLOPs和推理时间指标。如下图所示,相比于其它类型的编辑方法,EEdit采用的SLoC+ISS的方案,在相同扩散模型权重(FLUX 12B)下的指标的普遍最优,且计算开销和推理时间也有显著提高。有趣的是,相比于权重小一个数量级的的SD系列,本文的方法也具有推理效率上的竞争力。

图表5 EEdit在各种类型的引导条件中的编辑能力与其它方法的对比
不仅如此,定性实验也表明,在多种引导模式下,本文方法具有更强编辑区域精确度,和更强的背景区域一致性。在提示词引导的几个案例中,别的方法存在大幅修改整体布局,或者背景不一致,画风不一致的问题存在;在拖拽引导的案例中,对于用户输入的拖拽意图,本文的方法体现了更好的遵循程度;在参考图像引导的图像合成任务中,本文的方法在画风一致,以及与原物品身份一致性的保持程度上都呈现了显著的优越性。
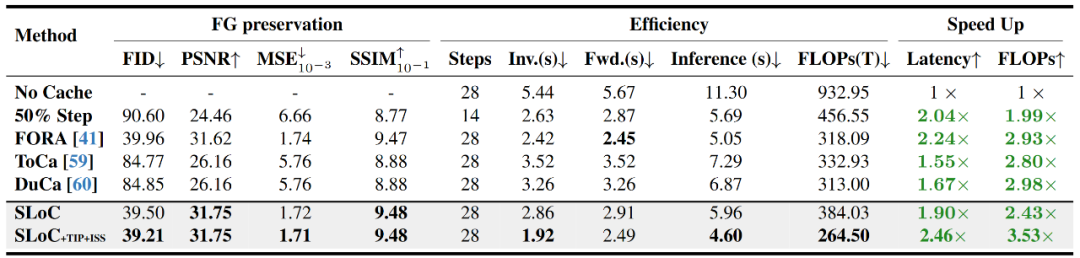
图表 6 空间局域缓存相比于其它加速方法的性能对比
空间局域缓存是否是应用于编辑任务的优越缓存算法?本文作者通过与其它的缓存加速算法的比较,得出的结论是肯定的。与同样可应用于MM-DiT的缓存算法,FORA,ToCa和DuCa相比,本文提出的SLoC算法不仅在加速比和推理延迟上取得优势,而且在前景保持度(FG preservation)中取得了最优的结果。甚至在某些指标上相比于其它缓存加速算法,效果提高50%以上。
如需引用本文,欢迎按照以下格式:
@misc{yan2025eeditrethinkingspatial,
title={EEdit : Rethinking the Spatial and Temporal Redundancy for Efficient Image Editing},
author={Zexuan Yan and Yue Ma and Chang Zou and Wenteng Chen and Qifeng Chen and Linfeng Zhang},
year={2025},
eprint={2503.10270},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2503.10270},
}
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com