Grok 4 跑分泄露,HLE 成绩亮眼引争议,或推动AI大模型发展,一切有待官方发布。
原文标题:刚刚,Grok4跑分曝光:「人类最后考试」拿下45%,是Gemini 2.5两倍,但网友不信
原文作者:机器之心
冷月清谈:
怜星夜思:
2、Grok 4 Code 在 SWEBench 上的得分与 Claude Opus 4 持平,你认为这对于程序员来说意味着什么?未来 AI 编程助手会如何改变程序员的工作方式?
3、马斯克亲自熬夜开发 Grok 4,这种All in 的工作方式是否值得提倡?在AI 模型开发过程中,除了技术之外,还有哪些因素会影响最终的成果?
原文内容
编辑:杨文、泽南
马斯克搭帐篷熬夜开发有效果了?这么高跑分,还不发布。
刚刚,Grok 4 和 Grok 4 Code 的基准测试结果疑似泄露。
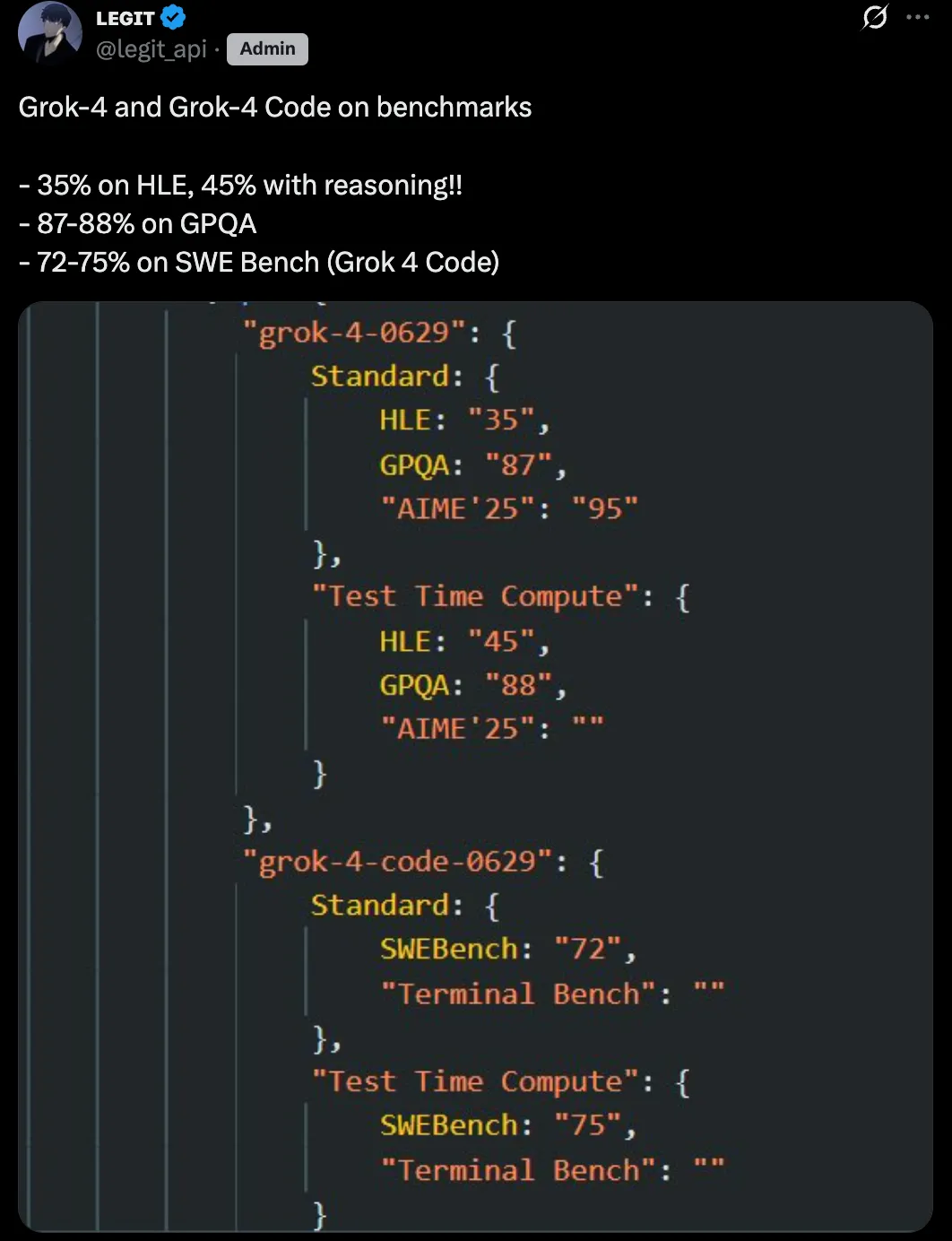
X 博主 @legit_api 发帖称,Grok 4 在 HLE(Humanities Last Exam,人类最后考试)上的标准得分是 35%,使用推理技术后提高到 45%;在 GPQA 上的得分是 87-88%;而Grok 4 Code 在 SWE Bench 上的得分则达到 72-75%。
这个跑分结果意味着什么?有网友将其与 OpenAI o3 和 Claude Opus 4 等竞争模型进行了对比。
Grok 4 在 HLE 上的标准得分约为 35%,使用推理技术后提升至 45%,这比 OpenAI o3 的最佳公开得分(约 20%)高出两倍,比 GPT-4o 高出四到五倍。要知道 HLE 是一个自由回答测试,随机猜测准确率仅约 5%,因此每个百分点的提升都非常困难。
在 GPQA(研究生级物理和天文学问题)上,Grok 4 得分 87-88%,与 OpenAI o3 的顶级表现相当,并明显超过 Claude 4 Opus 的约 75%。
Grok 4 在 AIME '25(2025 年美国数学奥赛)上得分 95%,远超 Claude 4 Opus 的 34%,并略优于 OpenAI o3 的 80-90%(取决于思维模式)。
此外,Grok 4 Code 在 SWEBench 的得分与 Claude Opus 4 的 72.5% 持平,略高于 OpenAI o3 的 71.7%。而在 Terminal-Bench 上,Claude 4 Opus 领先,得分 43%,xAI 尚未发布 Grok-4 的相关数据。
其中,网友讨论最多的就是 Grok 4 在 HLE 上达到了惊人的 45%,几乎是 Gemini 2.5 Pro 成绩的两倍。如果泄露的测试结果属实,那么意味着 Grok 4 通过了 AI 基准测试中最艰难的一关。

还有网友建议关注「标准」得分,认为这是公开模型的基准,推理得分可能涉及实验性配置。
不过,也有网友表示质疑,认为 Grok 4 的 HLE 分数不太可能这么高,这里面肯定有问题。

该网友给出的理由是,上次 xAI 报告了其他模型使用单次尝试的结果,但对自己的模型却使用了不同的报告方法。
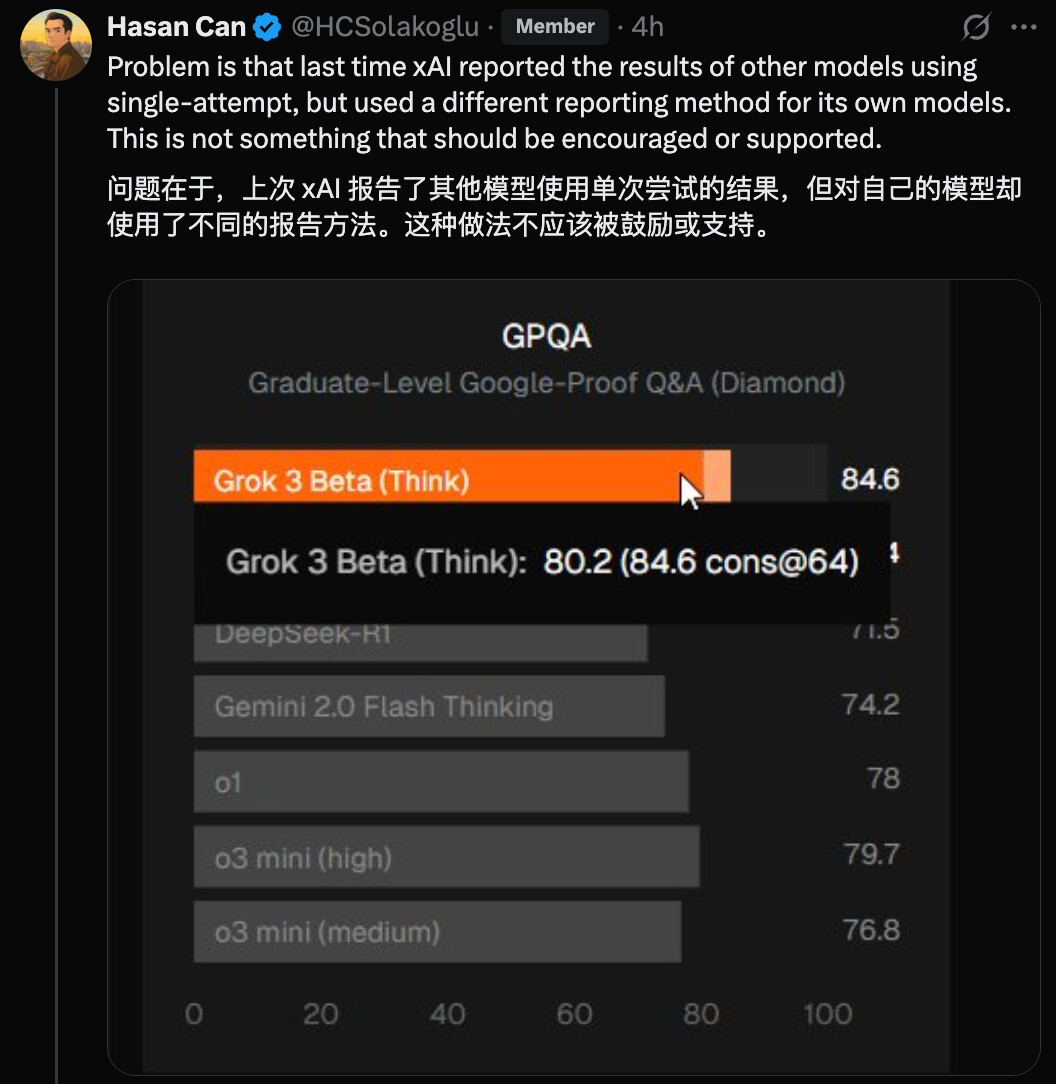
@legit_api 回复称,这些数字是真实的,但我们不知道配置。

有网友总结道,目前 Grok 4 泄露出来的所有基准成绩,除了 HLE 以外,其他的看起来似乎还算「合理」。不过 HLE 能跑到这么高分又应该如何解释呢?毕竟这个基准中包含很多晦涩难懂的信息检索。
或许一切都要等待模型正式发布才能有答案了。
其实早在 7 月 1 日,外媒 TestingCatalog 就发文爆料,Grok 4 系列模型的相关信息在 xAI 开发者中控台网站上泄露,包括旗舰模型 Grok 4 和编程模型 Grok 4 Code。
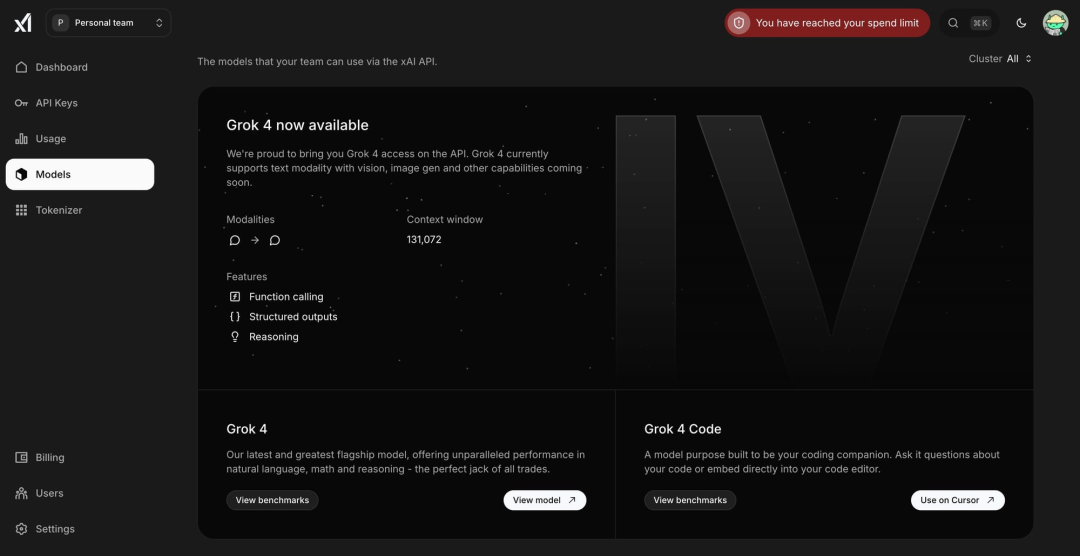
截图显示,Grok 4 仅支持文本模式,视觉、图像生成及其他功能即将推出。Grok4 支持约 13 万 tokens 上下文窗口,较许多竞争对手的前沿模型要小,这可能表明 xAI 在优化推理速度和实时可用性,而非追求最大化的长上下文性能。从功能上来看,Grok 4 将包括函数调用、结构化输出和推理能力。
还有网友扒出了 xAI 开发者中控台的源代码,这些代码显示,Grok 4 是一个在自然语言、数学和推理方面「拥有无可匹敌的能力」的通才模型,并在当地时间 6 月 29 日完成了训练,其标语为「Think Bigger and Smarter」。
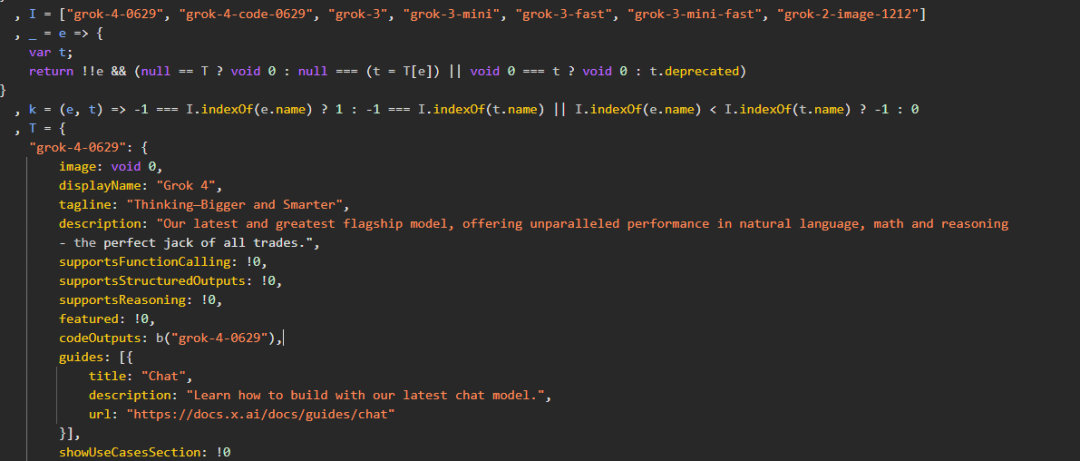
截图还显示,Grok 4 Code 则是一款专为编程设计的模型,用户可以直接向它提问代码问题,也可以直接嵌入代码编辑器中。
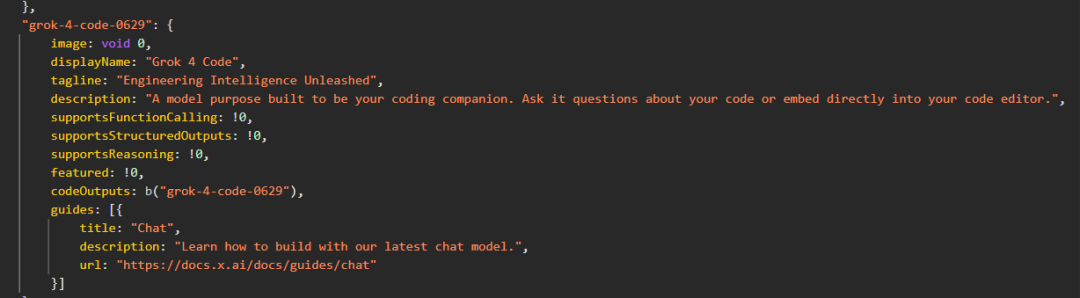
上个星期,马斯克在推文中表示,他正「通宵达旦地开发 Grok 4」,模型开发「进展良好」但仍需进行「最后一次大规模训练」,特别是在专门代码模型方面。为了这一目标,从上月底开始,马斯克带头在办公室内支起帐篷睡觉,以全身心投入工作。
X 的工程师还出面回应了一下帐篷的问题。
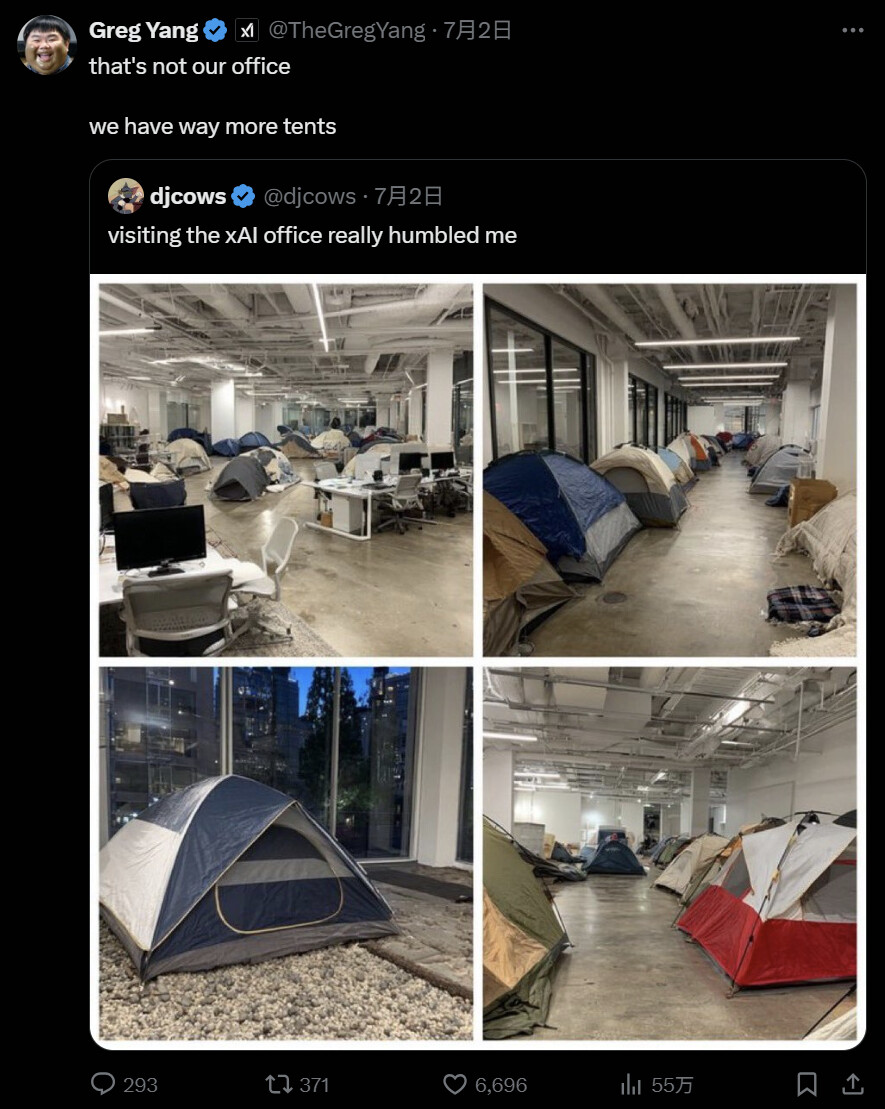
生成式 AI,都卷到这种地步了?
泄露的分数不仅刺激了广大网友的小心脏,也在刺激着众多 AI 科技公司。马斯克今天虽然没有如之前预测的那样「官宣」Grok 4 开源,但表示推特上的 Grok 功能有了明显的提升。

有网友为此专门去问了 Grok,它认为 7 月更新是 Grok 4,但不完整。

再加上 Benchmark 成绩已经曝光,或许 Grok 4 过几天就要正式发布了。
如果成绩属实,不管是架构的创新还是规模的扩展,Grok 都将推动一波 AI 大模型的发展,让我们拭目以待。
参考链接:
https://www.reddit.com/r/singularity/comments/1lrmn42/grok_4_and_grok_4_code_benchmark_results_leaked/
https://www.testingcatalog.com/xai-prepares-grok-4-and-grok-4-code-for-upcoming-launch/
https://x.com/AiBattle_/status/1940139539525419512

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com