探索LLM推理缓存优化技术,包括PagedAttention、RadixAttention和LMCache,降低TTFT、TPOT,提升吞吐。
原文标题:性能最高提升7倍?探究大语言模型推理之缓存优化
原文作者:阿里云开发者
冷月清谈:
怜星夜思:
2、LMCache 提到可以将 KV Cache 存储在不同的位置(GPU, CPU DRAM,本地磁盘),这种分层存储的策略是如何决定的?在什么情况下应该将哪些 KV Cache 移动到 CPU 或磁盘上?
3、文章中提到 DeepSeek 的 Context Caching 使用了硬盘缓存技术,虽然成本降低了,但速度也变慢了。这种方案在哪些场景下会更适用?是否存在一些优化手段,可以在使用硬盘缓存的同时,尽量减少性能损失?
原文内容
前言
AI技术一路发展至今,推理优化是一个永存的话题,尤其是面临算力有限的情况下,如何将有限的计算资源利用最大化,是需要持续努力去实现的。今天我们来探讨一下大语言模型(LLM)推理缓存优化技术的演进和未来展望。本文主要进行原理性的探究,下一期会有相关的落地实践方案。
缩略词解释
LLM:大语言模型, Large Language Model
TTFT:首Token延迟, Time to First Token
TPOT:平均Token,Time Per Output Token
APC:自动前缀缓存, Automatic Prefix Cache
先说总结
-
KV Cache
-
目前主流推理框架vLLM, SGLang都已经支持,而且都是默认开启的
-
优化点
-
降低TTFT
-
降低TPOT
-
提升吞吐
-
Paged Attention
-
主要针对KV Cache在内存管理上的优化,提升资源利用率
-
优化点
-
提升吞吐
-
Prefix Caching
-
vLLM, SGLang默认开启,但是两者实现原理上略有不同
-
优化点
-
降低TTFT
-
提升吞吐
-
LMCache
-
还在快速成长阶段
-
目前只支持集成在vLLM,需要主动安装配置和开启
-
优化点
-
降低TTFT,TPOT
-
提升吞吐
LLM一些背景知识回顾
目前主流的推理框架是vLLM和SGLang。
LLM推理过程可以划分为下面两个阶段:
-
Prefill阶段
-
模型接受用户的提示词(Prompt),并且并行计算所有Token的Query、Key和Value向量。
-
这一阶段需要通过并行计算充分利用GPU算力资源,所以属于计算密集型场景,瓶颈在于算力而非内存。
-
Decode阶段
-
模型逐个推理生成Token,每次只生成一个Token。模型首先计算其对应的Query、Key和Value,当前Token的Query会与现在以及历史上所有的Key进行点积计算,最终获得此Token的Attention。
-
这一阶段是串行的无法并行加速,而且需要频繁读写缓存数据,属于IO密集型场景,对缓存存储的空间和读写效率要求比较高。
LLM缓存技术
KV Cache
在LLM中,回归生成(auto regressive generation)是很关键的一个机制,这意味着模型会基于用户提供的提示词(prompt),逐步推理生成下一个token。此过程是串行的,而且极大地依赖于Transformer架构中的自注意力机制(self-attention)。
在self-attention中,模型会为每个token计算三个向量:Query(Q), Key(K), Value(V)。每次生成一个新的Token,都需要当前的Query向量和之前Token的key向量进行进行点积计算注意力分数,再据此对Value向量做加权求和。这就需要频繁访问此前的Token计算的结果。为了避免重复计算这些历史的Key和Value向量,所以就将他们缓存下来,成为KV Cache。
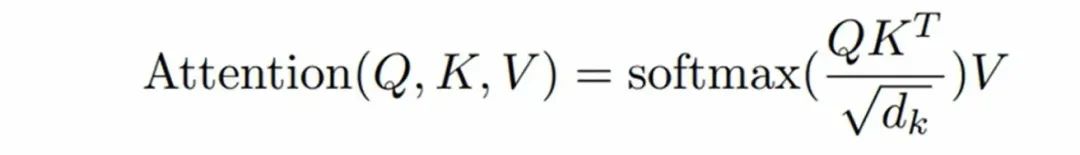
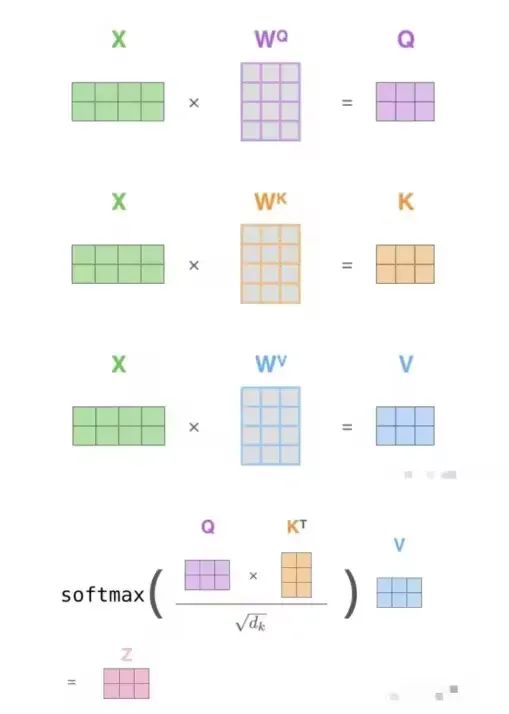
KV Cache如今已经是主流大语言模型的通用技术,通过缓存每一步生成过程中的Key和Value向量(即KV Cache),避免重复计算,节省算力。这部分缓存不会一直常驻GPU显存,而是会随着请求的增长,动态的增长和释放。所以KV Cache的管理至关重要,不合理的KV Cache管理会出现大量的内存碎片,导致内存等资源浪费,进而限制并发、拉低整体吞吐。下面将对各主流推理框架在KV Cache方面的实现原理和优化进行介绍。
下图是LLAMA-8B模型在NVIDIA A100 40GB GPU上推理的显存占用分布:
-
Parameters(26GB, 65%):模型权重参数,启动后常驻GPU显存中;
-
KV Cache(>30%);
-
Others;

传统KV Cache面临问题
-
显存增长快
-
内存碎片化
-
缓存难以复用
为了解决上述问题接下来我们看看各个主流LLM推理框架是如何优化的。
vLLM
PagedAttention
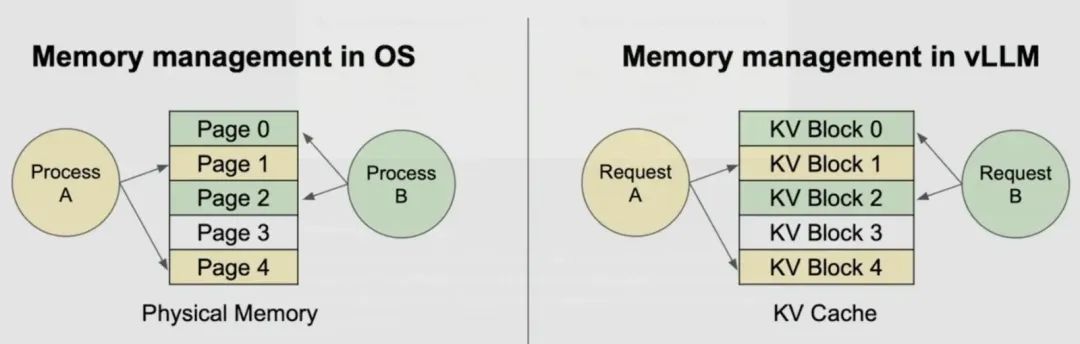
vLLM引入了一个全新的注意力机制PagedAttention,它借鉴的是操作系统中的虚拟内存分页技术,将每次请求的KV Cache按块存储在非连续的内存地址中。通过Block粒度的内存管理,实现了高效、动态的KV Cache管理。
关键改进有如下:
-
灵活的内存管理,提升内存复用率,减少内存碎片;
-
KV Cache被切分为固定大小的Block;
-
默认每个Block存储16个Token;
-
Block可以存放在非连续的物理内存中;
-
多样化的共享策略
-
使用Copy-on-Write(CoW)机制,允许并行采样(Parallel Sampling)的场景下,共享生成的KV Cache,CoW机制的意思是只有新的生成序列生成并写入新的Token的时候,才会复制当前的Block,否则和之前的序列共享KV Cache Block。
-
相同prompt开头的token可以被共享。
内存管理
以vLLM官方文档中的例子,说明PagedAttention过程,用户Prompt为“Alan Turing is a computer scientist”
1. prefill阶段
a.prompt中的所有token会被计算KV Cache并缓存在Block 0和Block 1中,其中Block 1只占用了两个token位置未被占满。
b.Block 0和1分别映射到物理Block 7和1。
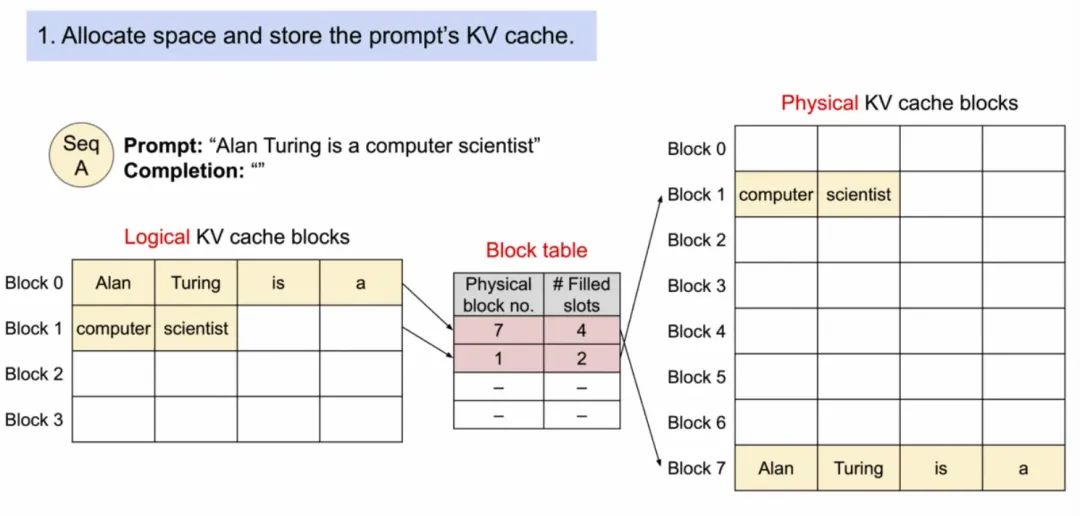
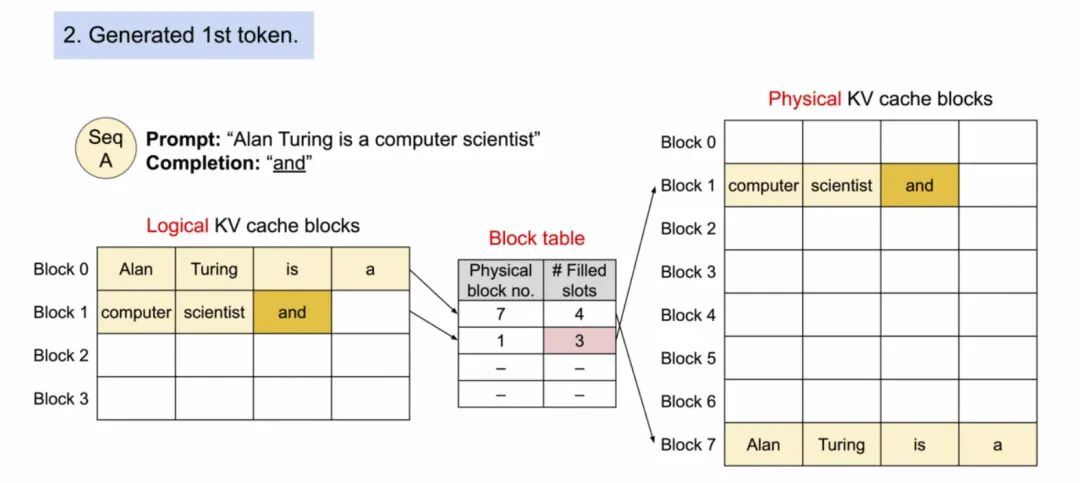
2. decode阶段-生成第一个token。因为Block 1还未满,所以继续在Block 1填充,然后Block Table的Filled slots + 1。
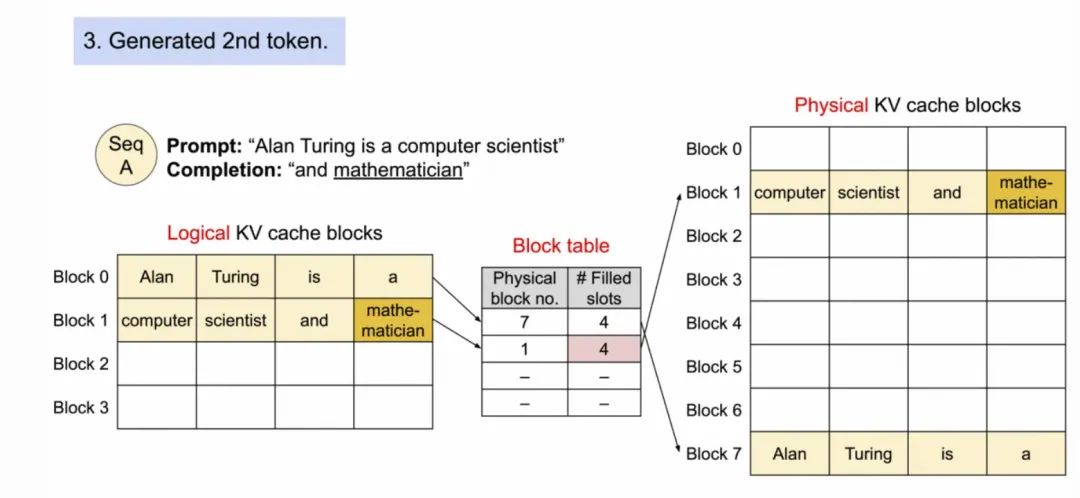
3. decode阶段-生成第二个token。Block 1扔未满,继续在Block 1填充,然后Block Table的Filled slots + 1。
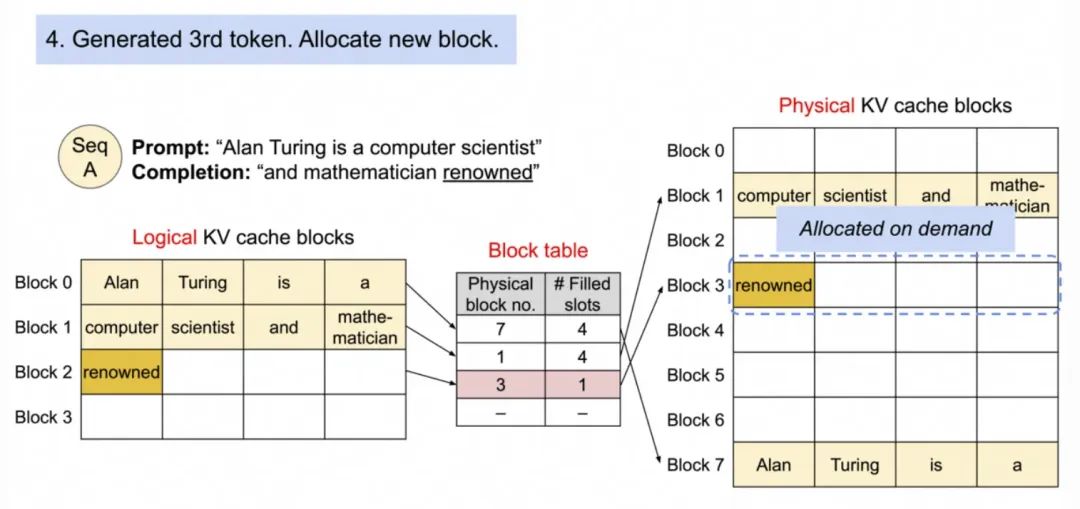
4. decode阶段-生成第三个token。Block 1慢了,分配新的Block。
在 Parallel Sampling 中,同一个 prompt 会生成多个候选输出,便于用户从多个备选中选择最佳响应,常用于内容生成或模型对比测试。
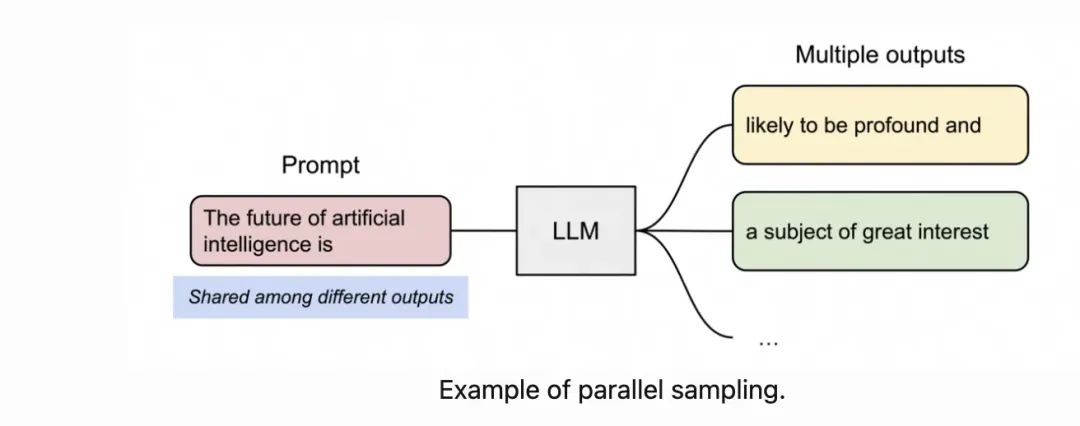
在 vLLM 中,这些采样序列共享相同的 prompt,其对应的 KV Cache 也可以共用同一组物理块。PagedAttention 通过引用计数和 block-level 的 copy-on-write 机制实现共享与隔离的平衡:只有当序列出现不同分支时,才会触发复制操作。
下面是Parallel Sampling通过CoW机制管理内存的官方演示实例:
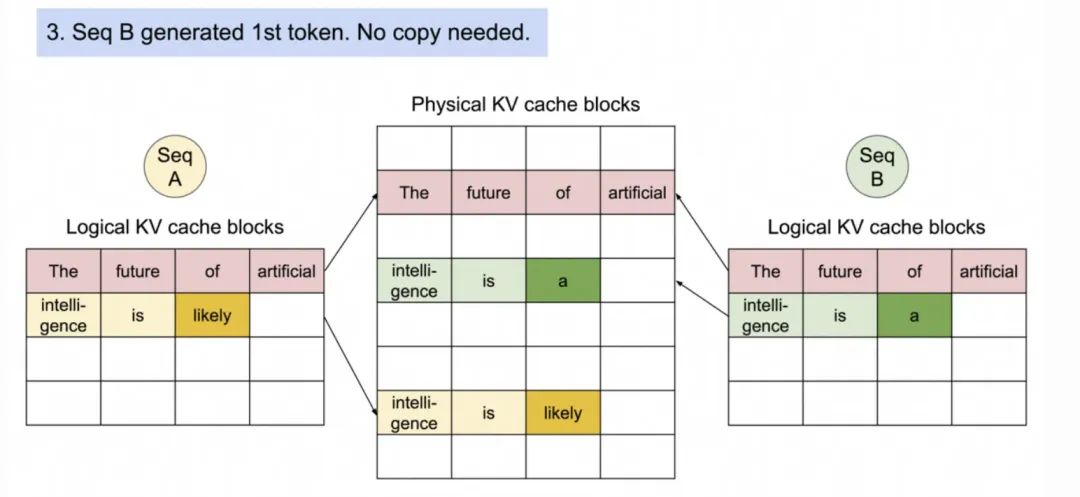
1. 两个序列A和B从共享Prompt("The future of artificial intelligence is")开始。
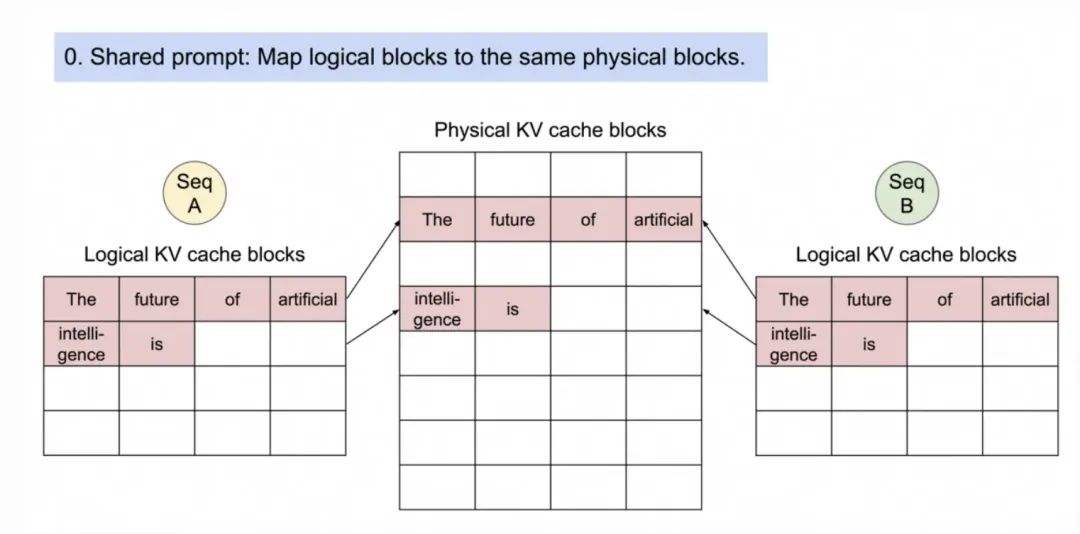
2. 序列A生成第一个Token“likely”。
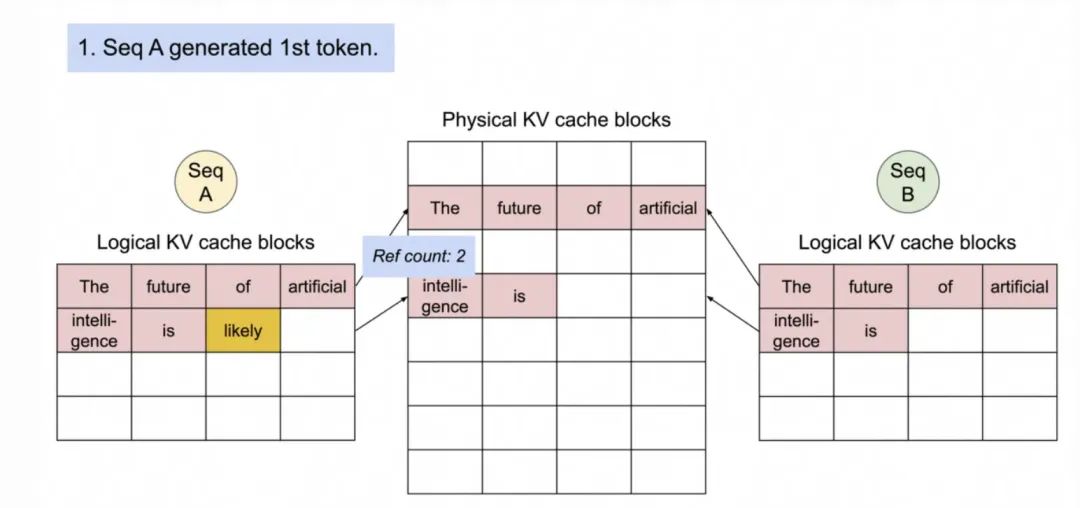
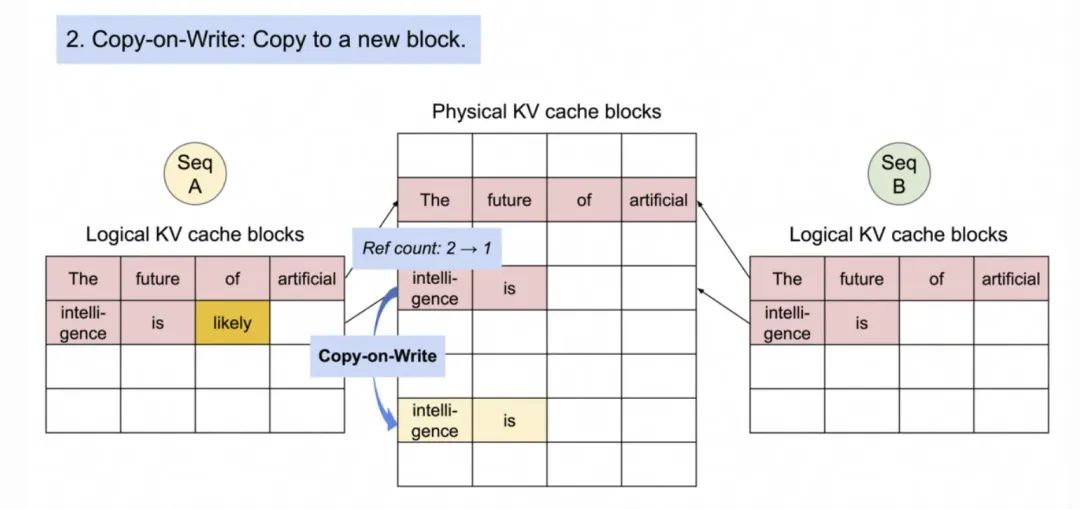
3.序列2准备生成序列,会先复制“intelligence is”这个Block,然后写入新生成的token “likely”。原来的序列A继续生成新的Token“a”。
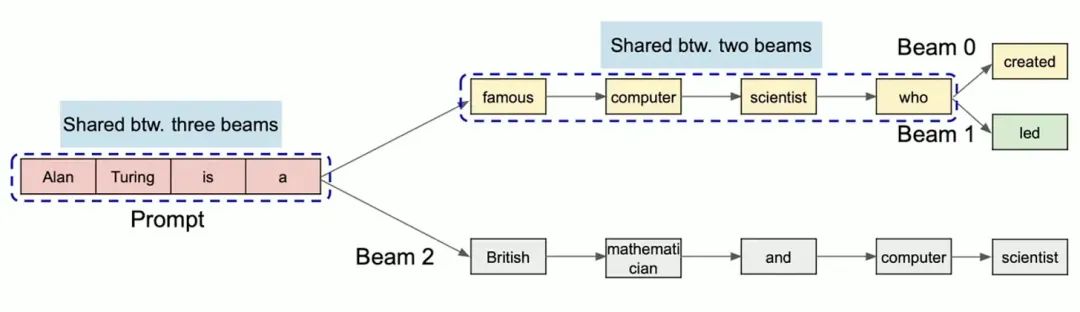
Beam Search是机器翻译常见的解码策略,他会通过维护多个Beam路径,每轮扩展最有候选并保留Top-K序列。
共享前缀(Shared Prefix)
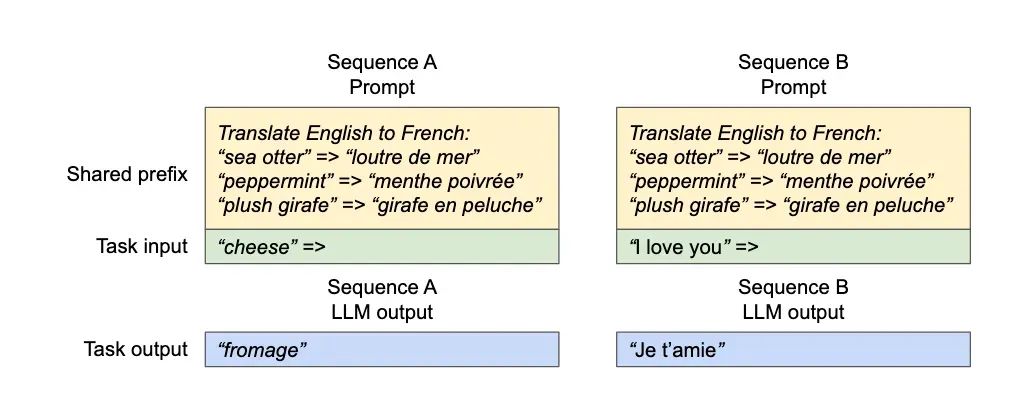
Shared Prefix允许多个用户用相同的Prompt来发送请求,节省prefill阶段的计算时间,提升后续任务的准确性和效率。
通过优化内存管理,能够并行处理多种解码策略,比如greedy decoding, beam search, and top-k sampling等。
自动前缀缓存(Automatic Prefix Caching)
Automatic Prefix Caching 会对已有的Query的KV Cache 进行缓存,如果新的Query和已有的Query拥有相同的前缀Prefix,那么这个新的Query可以复用之前的KV Cache。特别适用于多轮对话或具有长系统提示的场景,因为这些场景中往往存在大量可以共享的前缀信息。
vLLM的Prefix Caching实现和SGLang最大的不同是采用一种称为Hash RadixAttention的方法,它使用哈希码作为物理KV Block的唯一标识,这种方法在工程上更为简单:
hash(prefix tokens + block tokens) <--> Logical KV blocks -> Physical KV blocks
要启用vLLM中的Prefix Caching,可以在vLLM引擎中设置enable_prefix_caching=True。例如,在代码中可以这样设置:
llm = LLM(
model='lmsys/longchat-13b-16k',
enable_prefix_caching=True
)
限制
-
Automatic Prefix Caching 减少了Prefix阶段的计算,也就是降低了TTFT,对于生成新的Token也就是Decoding阶段(TPOT)没有任何加速作用。
-
在vLLM离线推理场景下,prefix cache是默认关闭的,需要
enable_prefix_caching=True开启。 -
vLLM实时场景下是默认开启的,可以添加
--no-enable-prefix-caching关闭。
SGLang
RadixAttention
SGLang提出的RadixAttention技术通过基数树(Radix Tree)数据结构管理KV缓存,实现了跨多个生成调用的自动复用 。其技术原理对标vLLM的PagedAttention和Automatic Prefix Caching 。
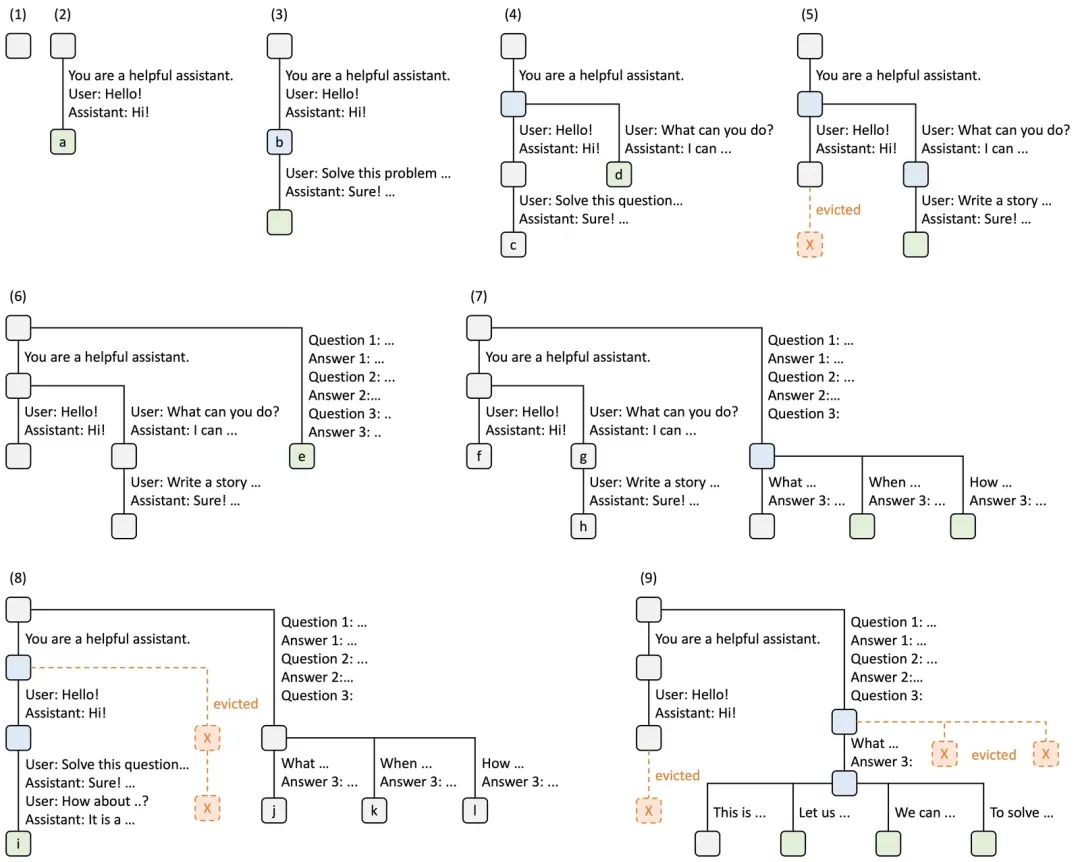
基数树的每个节点代表一个token序列,边代表token。当新请求到来时,RadixAttention会在树中进行前缀匹配,找到最长共享前缀节点并复用其KV缓存 。特别是在多轮对话这种场景下,缓存命中率能提高3到5倍,延迟自然就降下来了。
下图是SGLang官方论文《Fast and Expressive LLM Inference with RadixAttention and SGLang》插图,介绍了多个请求的时候,Radix Tree的维护方式。前端总是向框架发送完成的Prompts,然后框架会自动完成前缀匹配,复用和缓存。树结构存储在CPU中,而且维护成本很低。
LMCache(Redis for LLM)
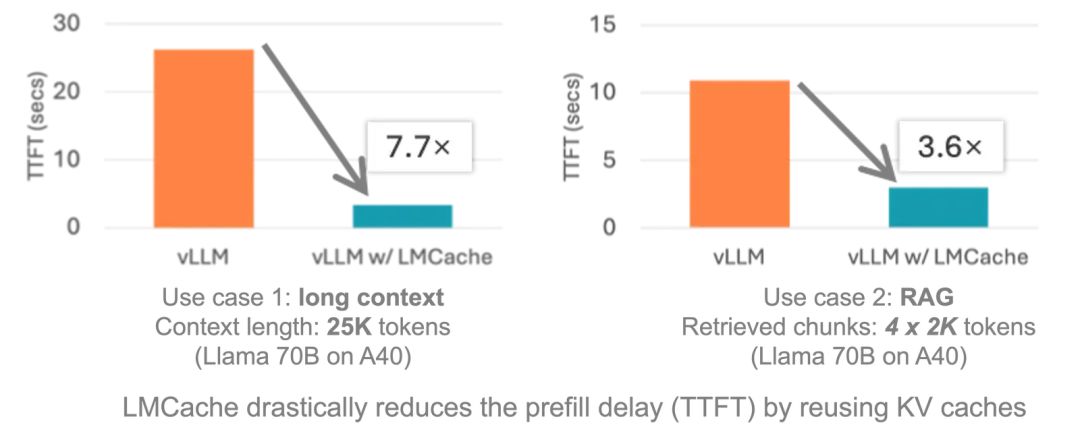
LMCache的核心目标是降低首Token产出时间(TTFT)和提升吞吐,尤其是长对话场景。
下面是和vLLM对比的结果,TTFT最高降低7.7倍。
实现原理
通过在不同位置存储可重用文本的KV缓存,包括(GPU, CPU DRAM,本地磁盘),LMCache在任何服务引擎实例中重用任何可重用文本的KV缓存(不一定是前缀)。因此,LMCache节省了宝贵的GPU周期,减少了用户的响应延迟。
核心特性如下:
-
High performance CPU KVCache offloading
-
Disaggregated prefill
-
P2P KVCache sharing
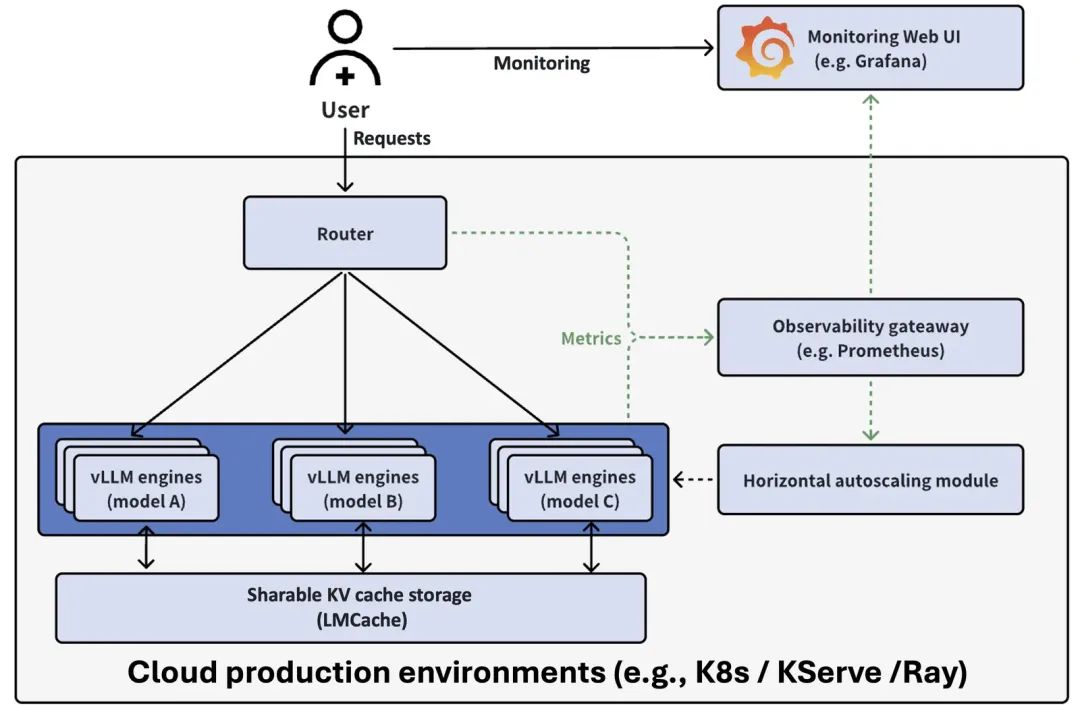
Context Caching of DeepSeek
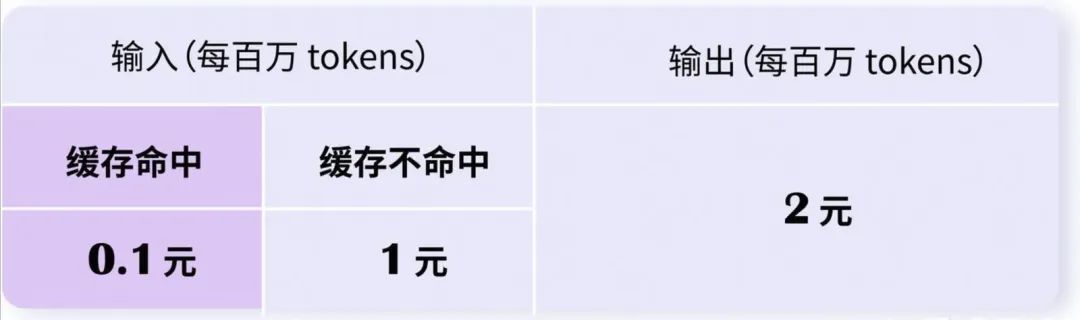
deepseek API提供的Prefix Caching产品名叫做Context Caching,和SGLang/vllm不同的是,DeepSeek采用的是上下文硬盘缓存技术,把预计未来会重复使用的内容,缓存在分布式的硬盘阵列中,而不是缓存在gpu显存中,这块设计思路和上面的LMCache有异曲同工之妙。缓存命中的部分,DeepSeek 收费 0.1元 每百万 tokens;没命中的部分收费1元 每百万 tokens:
此外,从公开的deepseek官网公开的信息中可以看到:
-
DeepSeek V2 提出的 MLA 结构,在提高模型效果的同时,大大压缩了上下文 KV Cache 的大小,使得存储所需要的传输带宽和存储容量均大幅减少,因此可以缓存到低成本的硬盘上。
-
缓存系统以 64 tokens 为一个存储单元,不足 64 tokens 的内容不会被缓存。
-
缓存系统是“尽力而为”,不保证 100% 缓存命中。
-
缓存不再使用后会自动被清空,时间一般为几个小时到几天。
参考:
-
Efficient Memory Management for Large Language Model Serving with :https://arxiv.org/abs/2309.06180PagedAttention
-
https://blog.runpod.io/introduction-to-vllm-and-how-to-run-vllm-on-runpod-serverless/
-
https://github.com/cr7258/ai-infra-learning/tree/main/lesson/02-pagedattention-%E6%A0%B8%E5%BF%83%E6%8A%80%E6%9C%AF-pagedattention-%E5%8E%9F%E7%90%86%E8%AF%A6%E8%A7%A3
-
https://blog.vllm.ai/2023/06/20/vllm.html?ref=blog.runpod.io
-
https://github.com/LMCache/LMCache
-
https://github.com/vllm-project/production-stack/tree/main
MCP 赋能可视化 OLAP 智能体应用
针对传统数据分析中存在的 SQL 使用门槛高、分析可视化流程复杂,本方案基于云数据库 PolarDB MySQL 版与阿里云百炼,结合 MCP 工具的 SQL 执行与绘图能力,利用模型智能解析与高效推理,实现从数据接入到分析可视化的全流程一站式部署。
点击阅读原文查看详情。