Reefknot是一个评估多模态大模型关系幻觉的基准,揭示了当前模型在关系理解方面的不足,并提出一种有效的缓解策略,助力构建更可靠的AI系统。
原文标题:ACL 2025 | 深入浅出看关系:探索多模态大模型关系“幻觉”问题
原文作者:数据派THU
冷月清谈:
怜星夜思:
2、文章中提出的Detect-then-Calibrate方法很有意思,通过熵值来判断模型是否可能产生幻觉。大家觉得这个方法在实际应用中会有哪些限制?比如,熵值的阈值应该如何选择?
3、Reefknot数据集的构建过程中,研究者们花费了大量精力进行数据筛选和人工审核,确保数据集的质量。大家认为在构建类似的大规模数据集时,为了保证数据质量,除了人工审核外,还可以采取哪些更有效的方法?
原文内容

1、什么是“关系幻觉”?
如今,多模态大语言模型(MLLMs)已经在我们生活中随处可见,无论是聊天机器人还是自动驾驶,甚至是医疗诊断,都有它们的身影。然而,这些模型有时却会“编故事”,做出与现实不符的错误回答,我们称之为“幻觉”现象。
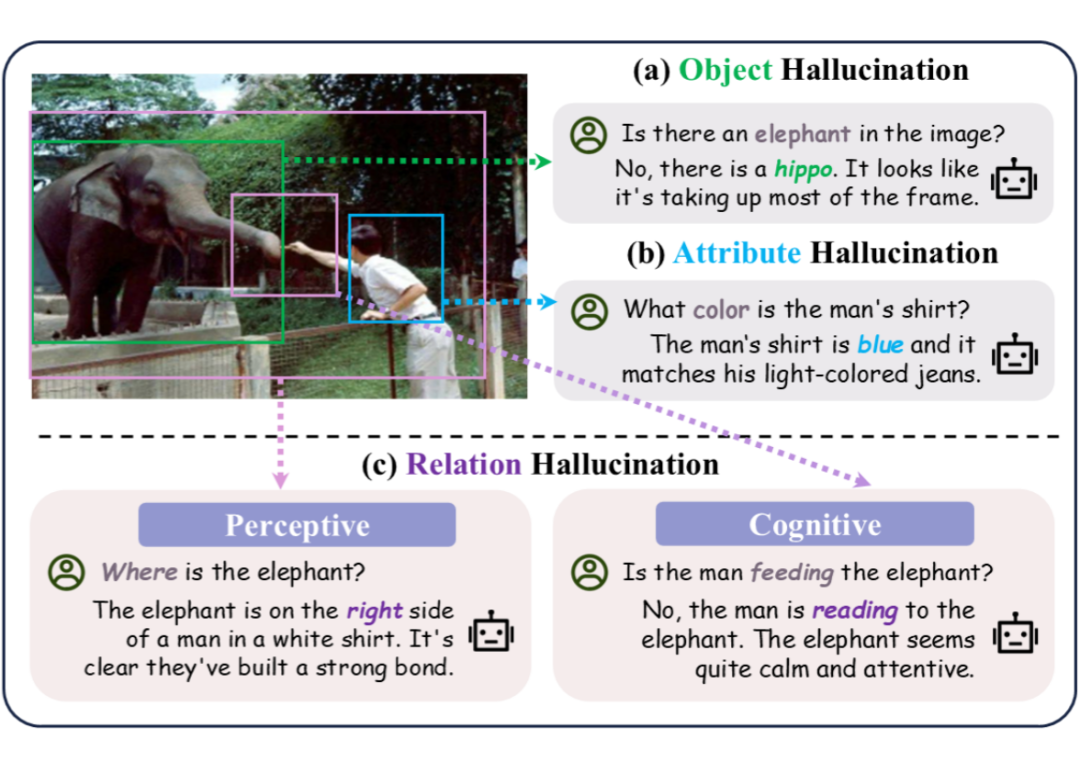
在过去的研究中,幻觉往往被简单地分为对象级(判断是否存在某个物体)和属性级(判断物体的颜色、形状等特性)。但现实世界中,还有更复杂的幻觉类型——关系幻觉。这种幻觉涉及到两个及以上物体之间的逻辑关系,比如“桌子上的杯子”或“男孩在吃披萨”,模型可能错误地描述这些关系,造成严重后果。
2、大模型的“小毛病”:关系幻觉究竟是什么?
随着多模态大语言模型(MLLMs)的兴起,这些模型在文本与图片等多种模态之间表现出了强大的能力。然而,它们也有自己的“软肋”:会产生错误甚至虚假的描述,尤其是描述图片中物体之间关系时的错误。
这种错误不仅仅是误判物体(object hallucination)或属性(attribute hallucination),而且还可能涉及复杂的关系推理。
关系幻觉的危害显而易见,比如在医疗诊断、自动驾驶等领域,这种错误可能会带来严重后果。因此,我们迫切需要一个高质量的数据集来系统地分析、评估并改善大模型的关系幻觉问题。
3、Reefknot横空出世:关系幻觉领域的里程碑式贡献

论文标题:
Reefknot: A Comprehensive Benchmark for Relation Hallucination Evaluation, Analysis and Mitigation in Multimodal Large Language Models (2025 ACL, Findings)
论文链接:
https://arxiv.org/abs/2408.09429
代码链接:
https://github.com/JackChen-seu/Reefknot
研究团队:
香港科技大学(广州)、香港科技大学
3.1 Reefknot不止于评测,更关乎“真知灼见”
Reefknot 不是一个简单的测试集,它是一个包含超过 20000 个真实世界样本的综合性基准,致力于对关系幻觉进行全面评测、深入分析和有效缓解。
1. 精心构建的“考题”:源于真实,拒绝臆造
研究者们首先对“关系幻觉”给出了系统性的定义,从感知(Perceptive)和认知(Cognitive)两个维度进行剖析。
-
感知关系:指的是那些具体的空间方位关系,比如“在…上(on)”、“在…后面(behind)”、“在…里面(in)”等。
-
认知关系:则包含更抽象的动作或状态,比如“吹(blowing)”、“看(watching)”、“读(reading)”等。
为了保证“考题”的真实性和高质量,Reefknot 的构建过程可谓煞费苦心:
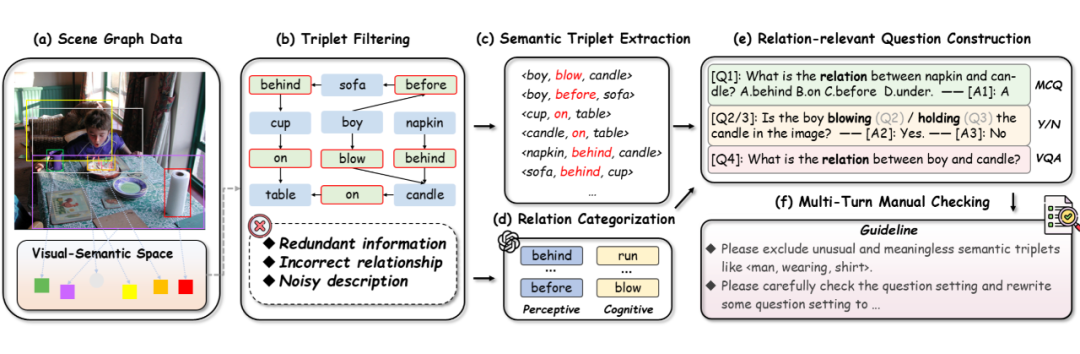
▲ Reefknot 数据集构建流程
-
数据来源:核心数据来源于广泛使用的 Visual Genome 场景图数据集,确保了场景的真实性和多样性。
-
拒绝“二手”信息:Reefknot 中的关系三元组(例如:<Boy , behind, sofa>)直接从原始数据中提取,更符合关系词在日常生活中的分布,力求原汁原味。
-
严格筛选与分类:
-
首先研究团队对从 VG 数据中构建场景图并识别出的关系三元组进行过滤,去除冗余、错误或描述不清的信息。
-
随后利用 GPT 辅助,将筛选后的关系精心划分为“感知”和“认知”两大类。
-
多样化的“考查方式”:Reefknot 设计了三种不同的提问方式,全方位考察模型对关系的理解和推理能力:
-
“是不是”题(Yes / No):
通过正负样本对比(比如同时问 “A 是不是在 B 的上面”和 “A 是不是在 B 的下面”),考察模型能否准确判断。
-
“选哪个”题(Multiple Choice Questions, MCQ):
设置一个正确答案和三个干扰选项,在有限词汇内评估模型抵抗关系幻觉的能力。
-
“问与答”题(Visual Question Answering, VQA):
开放式提问,全面评估模型的指令遵循能力和在开放环境下的关系感知能力。
-
专家“三堂会审”:
构建好的问题集还要经过至少三轮、四位领域专家的严格“人工审核”,剔除那些没有信息量(比如“窗户是不是在墙上?”这类无需看图就能回答的问题)或表述不当的问题,确保每一道“考题”都具有含金量。

▲ Reefknot 中的真实数据
经过这一系列复杂精密的流程,最终形成了包含 11084 张图片、总计 21880 个问题的 Reefknot 基准数据集。
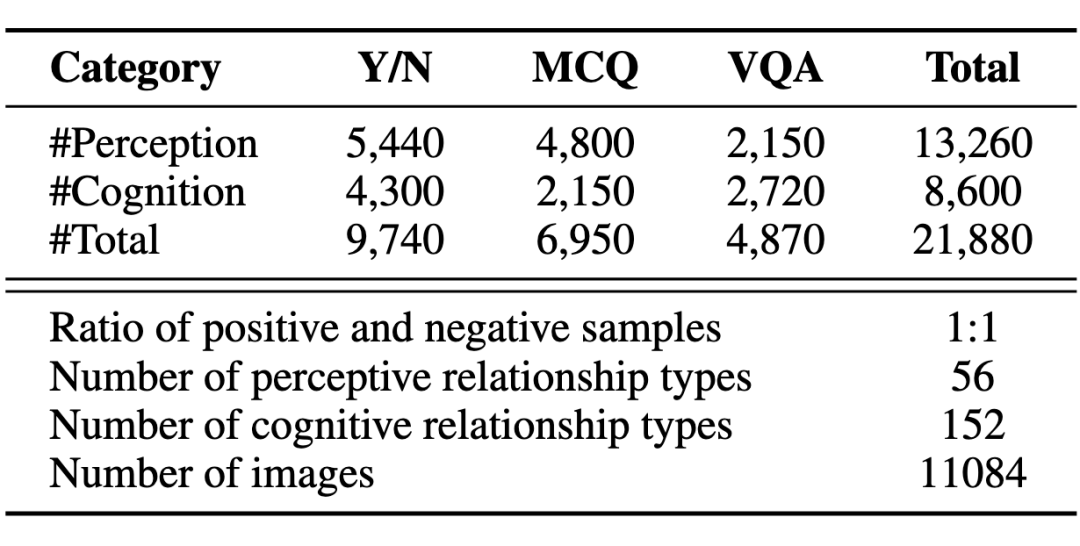
▲ 数据集统计信息
2. “大摸底”揭示真相:现有模型“偏科”严重
用 Reefknot 对主流的多模态大模型进行一番“大摸底”后,研究者们发现了一些值得深思的现象:
-
关系幻觉普遍存在且更严重:
结果显示,当前大部分 MLLMs 在处理关系幻觉方面表现不佳,甚至比处理物体幻觉还要吃力。
这说明,让模型“看懂关系”确实是个大挑战。
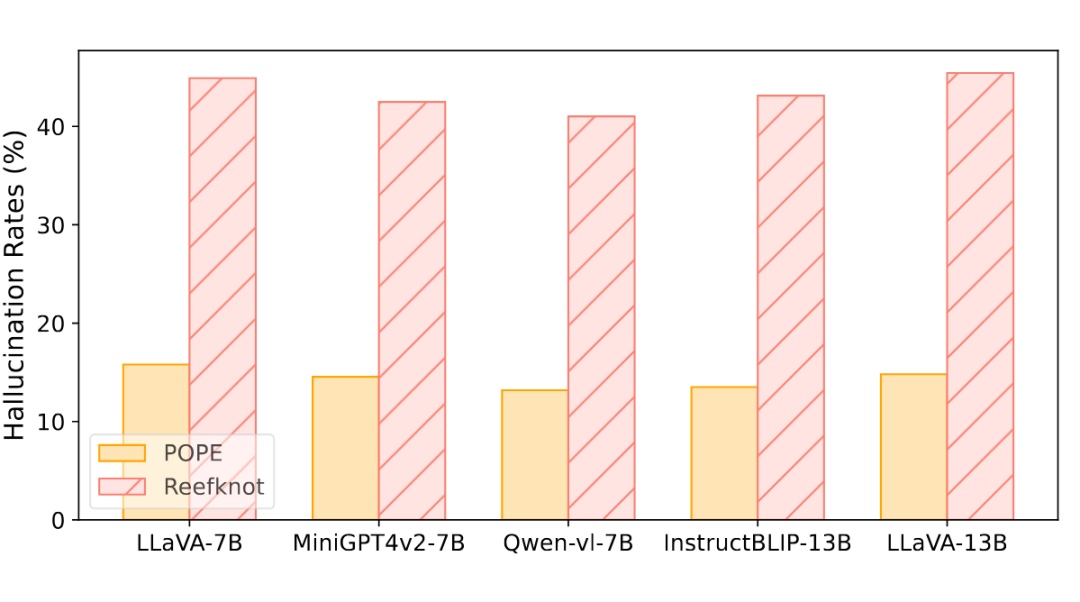
▲ 测评基座模型上物体幻觉和关系幻觉的幻觉率
-
“感知”比“认知”更易出错:
有一个与直觉可能相悖的发现是,模型在判断具体的“感知关系”(如方位)时,比判断抽象的“认知关系”(如动作)更容易产生幻觉,错误率平均高出 10% 左右,在某些模型和设置下甚至超过 30%。
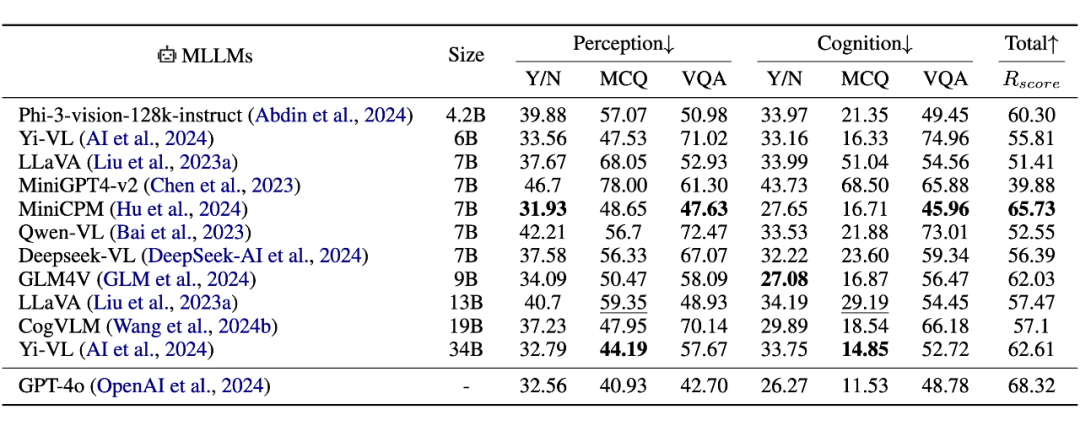
▲ 测评主流模型在 Reefknot 上的表现
研究者推测,这可能是因为模型在预训练和微调阶段接触了大量图文描述数据,这些数据通常更侧重于描述抽象动作行为(认知关系),而相对忽略了对常识性空间位置(感知关系)的标注。
3.2 Reefknot的“独门秘籍”:侦测并校准关系幻觉
Reefknot 不仅是一个优秀的“考官”,还是一位出色的“诊断师”和“治疗师”。研究团队基于对幻觉产生机制的深入分析,提出了一种名为 Detect-then-Calibrate(先侦测后校准)的创新缓解策略。
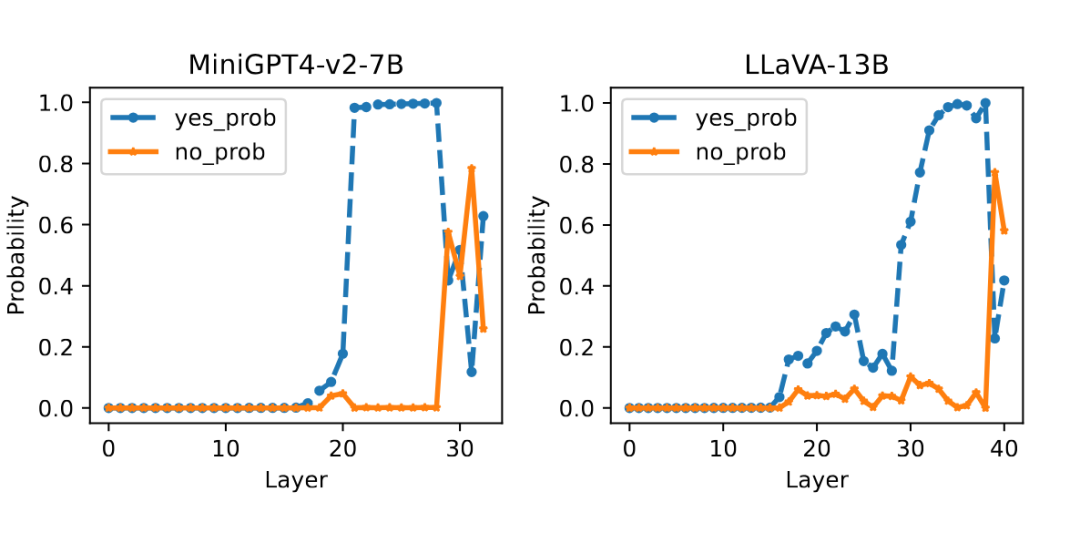
▲ MiniGPT4-v2-7B 和 LLaVA-13B 的发生幻觉时的层级变化规律
研究团队通过剖析不同尺寸的模型在不同层间对答案的信心变化,并观测到往往在发生幻觉时,在深层会伴随着概率的突变交错。同时剧烈的概率变化也是导致熵值的急速上升的原因。
核心洞察:研究发现,当模型产生关系幻觉时,它对答案的“自信心”会显著下降。正常情况下,模型给出正确答案的概率可能高达 90% 以上,但产生幻觉时,这个概率可能骤降到 50% 多一点。这种不确定性可以用“熵值(Entropy)”来衡量,熵值越高,不确定性越大,产生幻觉的可能性也越高。

▲ Detect-then-Calibrate 算法流程
“侦测-校准”两步走:
1. 侦测(Detect):设置一个熵值阈值。如果模型输出答案的熵值超过了这个阈值,就认为模型可能正在“胡说八道”。
2. 校准(Calibrate):一旦侦测到潜在的幻觉,就利用模型中间层(这些层通常包含更原始、更少被“带偏”的信息)的隐藏状态来“校准”最终的输出。
这种方法并非对所有情况都进行干预,而是精准打击那些可能产生幻觉的“高危病例”,避免“误伤”正常的回答。
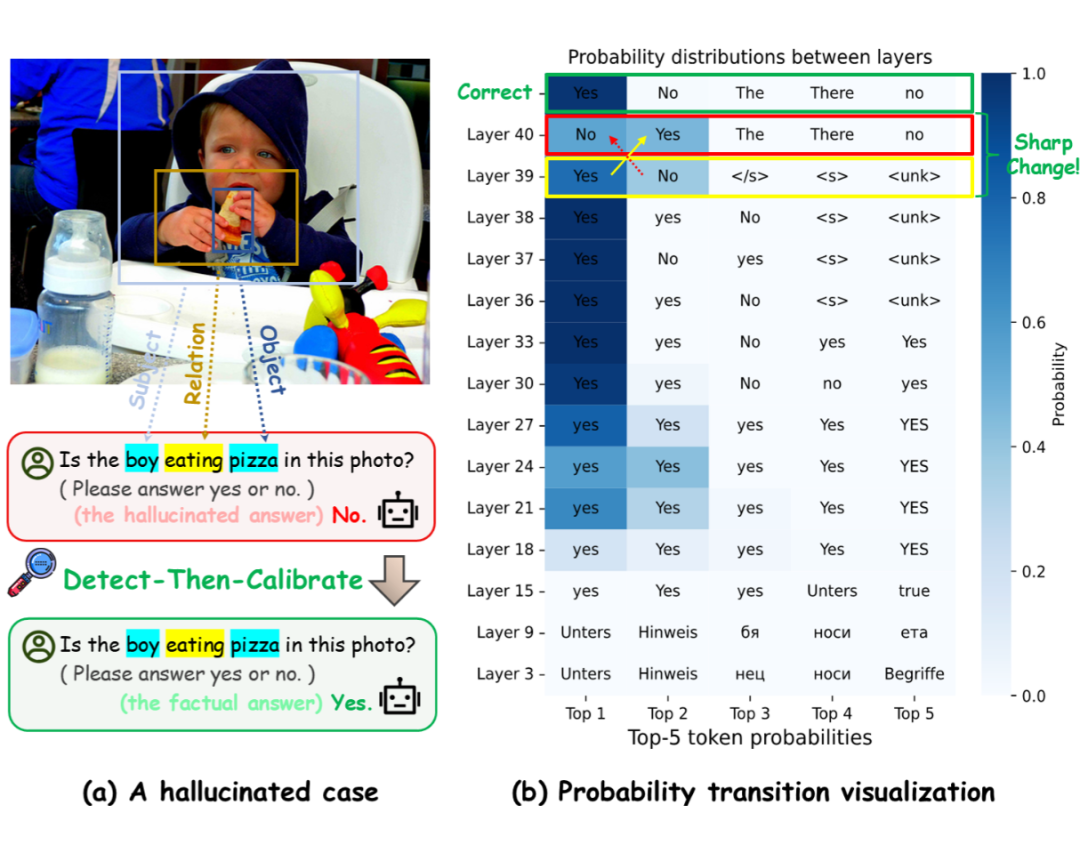
▲ 一个真实的幻觉案例及校准过程
实验结果表明,这套“组合拳”效果显著,在 Reefknot 以及另外两个关系幻觉数据集上,平均能将幻觉率降低 9.75%!
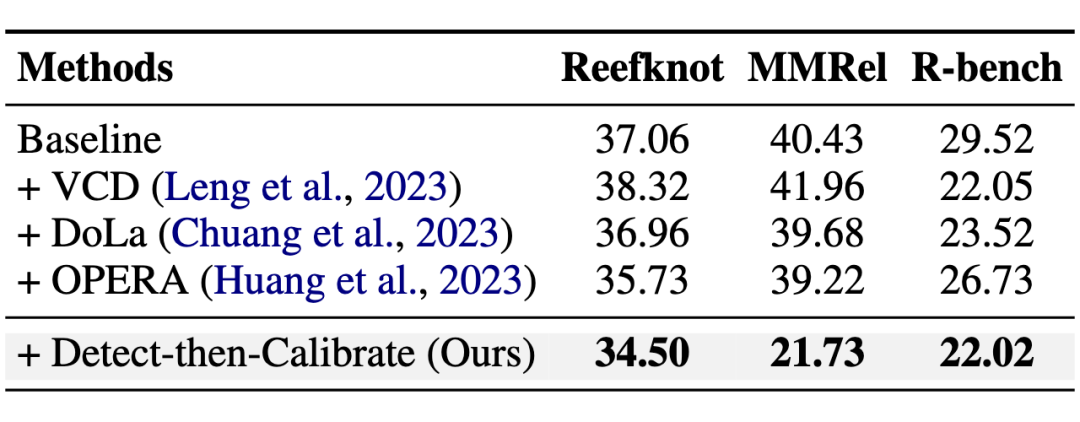
▲ Detect-then-Calibrate 方法与其他缓解方法的性能对比
4、总结与展望
Reefknot 的提出,为多模态大模型关系幻觉的研究提供了一个全面、真实、可靠的基准。它不仅揭示了当前模型在关系理解方面的短板,还提供了一套行之有效的缓解策略。
研究者们期待,Reefknot 能够像一块坚实的“礁石”一样,为构建更值得信赖、更智能的多模态 AI 系统奠定重要基础,让 AI 真正做到“眼明心亮”,更好地服务于人类社会。

