OPPO研究院开源TaskCraft框架及包含41,000条智能体任务的数据集,自动化生成复杂Agent任务,解决Agent RL高质量数据稀缺难题,显著提升模型推理能力。
原文标题:Agent RL和智能体自我进化的关键一步: TaskCraft实现复杂智能体任务的自动生成
原文作者:机器之心
冷月清谈:
怜星夜思:
2、TaskCraft在生成任务时,如何保证生成的任务对于智能体来说既有挑战性,又不会过于困难导致无法完成?难度控制的关键是什么?
3、TaskCraft生成的任务都附带了真实的执行轨迹,这个执行轨迹对于智能体的训练有什么价值?除了监督式微调和强化学习,还有没有其他的利用方式?
原文内容

近年来,基于智能体的强化学习(Agent + RL)与智能体优化(Agent Optimization)在学术界引发了广泛关注。然而,实现具备工具调用能力的端到端智能体训练,首要瓶颈在于高质量任务数据的极度稀缺。当前如 GAIA 与 BrowserComp 等主流数据集在构建过程中高度依赖人工标注,因而在规模与任务复杂性方面均存在明显限制——BrowserComp 仅涵盖约 1300 个搜索任务,GAIA 则仅提供约 500 条多工具协同任务样本。与基础大模型训练中动辄万级以上的指令数据相比,差距十分显著。
尽管在基础模型阶段,像 self-instruct 这样的自监督方法已经借助大语言模型(LLM)成功构建了大规模的指令型数据,有效提升了模型的通用性和泛化能力,但在智能体(Agent)场景下,这类静态指令数据却难以满足实际需求。原因在于,复杂的智能体任务通常需要模型与环境进行持续的动态交互,同时涉及多工具的协同操作和多步骤推理。而传统的指令数据缺乏这种交互性和操作性,导致其在智能体训练中迁移性差、适用性有限。
为应对上述挑战,OPPO 研究院的研究者提出了 TaskCraft,一个面向智能体任务的自动化生成框架,旨在高效构建具备可扩展难度、多工具协同与可验证执行路径的智能体任务实例。TaskCraft 通过统一的流程化建构机制,摆脱了对人工标注的依赖,能够系统性地产生覆盖多种工具(如 URL、PDF、HTML、Image 等)的复杂任务场景,并支持任务目标的自动验证,确保数据质量与执行闭环。 基于该框架,研究团队构建并开源了一个包含约 41,000 条智能体任务的合成数据集,显著扩展了现有 Agent 数据资源的规模与多样性,为后续通用智能体的训练与评估提供了有力支撑。

-
论文标题:
TaskCraft: Automated Generation of Agentic Tasks
-
论文地址:
https://arxiv.org/abs/2506.10055
-
Github:
https://github.com/OPPO-PersonalAI/TaskCraft
-
数据集:
https://huggingface.co/datasets/PersonalAILab/TaskCraft
数据生成
生成过程主要分为两大部分:第一部分 生成简单且可验证的原子任务;第二部分 通过深度拓展和宽度拓展,不断构建新的原子任务,使复杂性逐步提升。
原子任务的生成
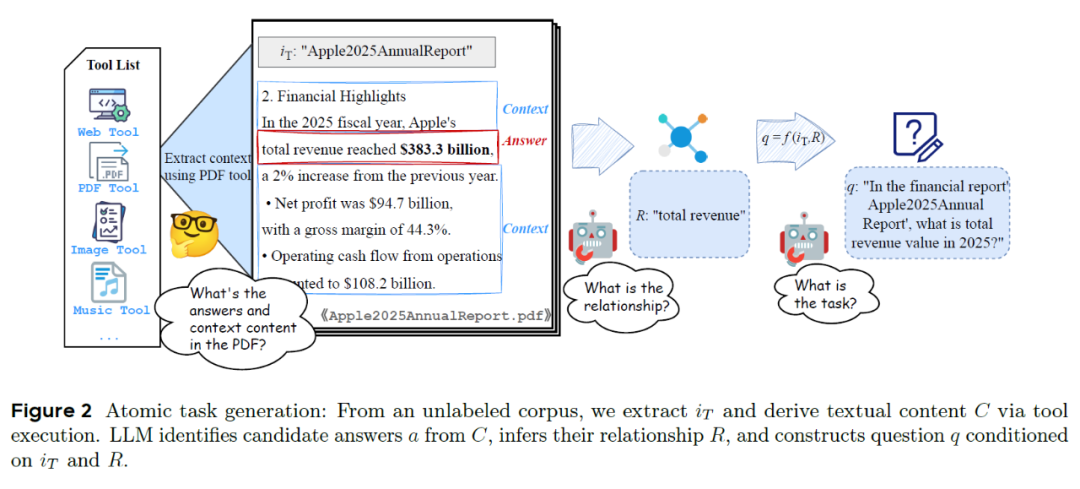
原子结构生成示意图
可以简单理解为,从原始数据中提取核心问题,然后确保问题必须通过特定工具来解决。整个流程包含以下四个关键步骤:
1.收集信息:系统从多种来源(网页、PDF、图片等)提取信息。例如,企业财报、一张统计图或一篇新闻文章。
2.识别关键内容: 利用LLM从这些文档中提取候选结论,比如:2025 年苹果公司总收入为 383.3 亿美元
3.生成问题:LLM需要将这些候选结论转换为工具回答的问题。例如:“在财务报告《Apple 2025 年度报告》中,2025 年的总收入是多少?”(答案:383.3 亿美元)
4.验证任务:每个原子任务被保留必须满足以下两个条件:
-
必须依赖工具才能解答( LLM 无法直接推导答案)。
-
必须经过 Agent 验证,确保能够顺利执行任务。
任务拓展
任务拓展旨在将一个简单任务逐步演化为更具层次和挑战性的复杂任务,使 Agent 必须通过多个步骤才能完成任务。拓展方式主要包括深度拓展与宽度拓展。
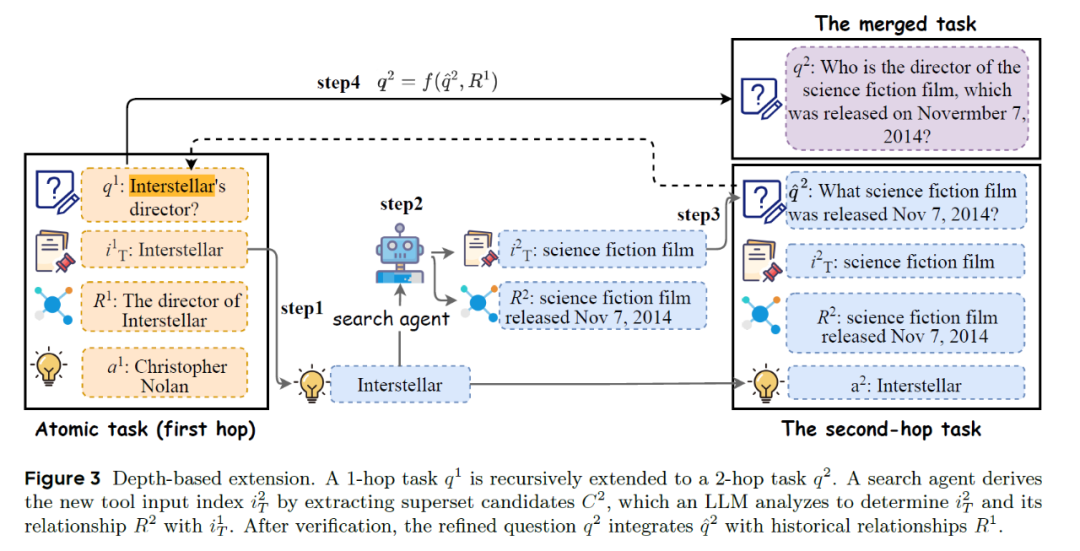
深度拓展示意图
其中,深度拓展的目标是为了构建可被拆解为一系列相互依赖的任务。每一步都依赖前一步的结果,从而构建出一条多步推理链。其主要包括以下四步:
1.确认主任务与拓展标识符:拓展标识符一般是具有强特殊性的文本,往往作为获取工具上下文的输入关键字。例如对于任务:“电影《星际穿越》的导演是谁?”(答案:克里斯托弗·诺兰),其中的拓展标识符是:《星际穿越》。
2.执行Agent搜索,构造新的辅助原子任务:Search Agent以拓展标识符为线索执行搜索,并从搜索结果中构造一个新的原子任务,其答案即为该拓展标识符。例如:“哪部美国著名科幻电影是在 2014 年 11 月 7 日上映的?”(答案:《星际穿越》)
3.合并辅助原子任务,更新主任务:将辅助原子任务与原主任务进行融合,构建一个逻辑连贯的复合任务。例如:“2014 年 11 月 7 日上映的美国著名科幻电影,它的导演是谁?“(答案:克里斯托弗·诺兰)
4.验证任务合理性:为了规避对合并问题的整体验证,研究者采用了多种规则对合并后的主任务进行语义验证,包括:超集验证、关系验证、信息泄露验证、替换合理性验证等。
而宽度拓展则是通过选择两个(或多个)结构兼容的原子任务, 这些任务应来自同一信息源(如同一篇网页或 PDF),且答案之间不存在因果依赖。使用 LLM 将多个任务的语义合并成一个自然、流畅且具备完整性的新任务。
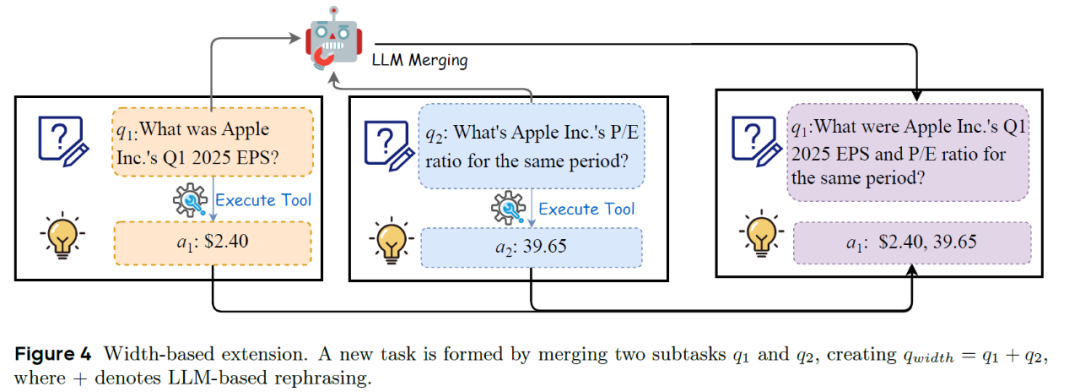
宽度拓展示意图
通过 Prompt Learning 提升任务生成效率
在 TaskCraft 的任务构建流程中,Prompt 的设计起到了至关重要的作用。研究团队采用了自举式 few-shot 提示优化机制,基于生成的任务数据对提示进行了迭代优化,从而实现了提示模板的自我进化。如表1,实验结果显示,原子任务的生成通过率从初始的 54.9% 提高至 68.1%,同时平均生成时间减少了近 20%。在深度拓展任务中,6 轮任务扩展的成功率由 41% 提升至 51.2%,进一步验证了生成数据在提升任务构建质量与效率方面的显著效果。

表1 Prompt Learning实验结果
对智能体基础模型进行SFT训练
其次,研究团队进一步评估了 TaskCraft 所生成任务数据在提升大模型能力方面的实际效果。以 Qwen2.5-3B 系列为基础,研究者基于三个典型的多跳问答数据集(HotpotQA、Musique 和 Bamboogle)的训练集,生成了约32k条多跳任务以及轨迹,并利用这些生成数据对模型进行监督微调(SFT)。如表2,实验结果表明,经过微调后,Base 模型的平均性能提升了 14%,Instruct 模型提升了 6%,说明 TaskCraft 生成的数据在增强大模型的推理能力与工具调用表现方面具有显著成效。此外,当这些微调模型与强化学习方法 Search-R1 相结合时,模型性能进一步提升,进一步证明 TaskCraft 所生成的任务数据不仅能用于监督学习,也可作为强化学习的优质训练起点。
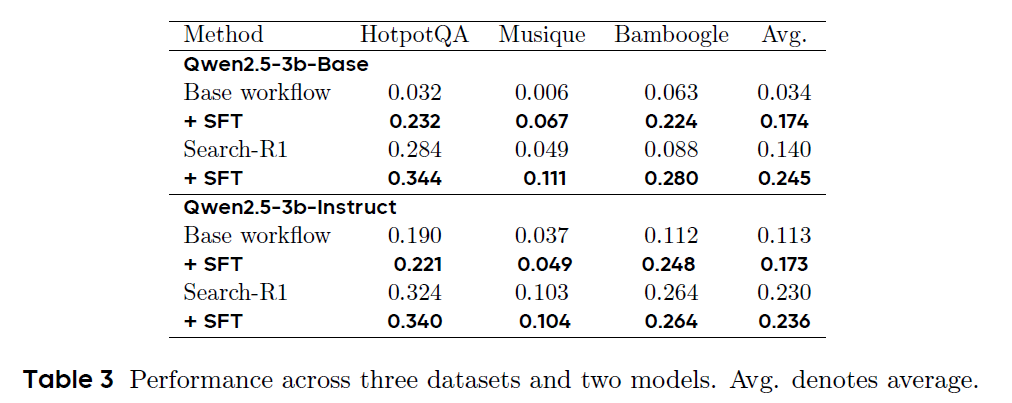
表2 监督微调效果
此外,你可能会好奇:引入搜索 Agent 是否真的有必要?为此,研究团队设计了一项对比实验,比较了两种任务构建方式的效果:一是直接使用 GPT-4.1 基于某个结论生成任务,另一种则是借助基于 GPT-4.1 的 Search Agent 自动生成任务。结果如表 3 所示,TaskCraft 构建范式在多项指标上表现更优。

表3任务构建范式的有效性分析
相比之下,TaskCraft 生成的任务具有显著更高的通过率,验证时间更短,且工具使用次数更符合“原子任务”的定义(理论最优为:一次输入索引 + 一次目标工具调用)。此外,任务的工具调用次数也更稳定,方差更小,反映出 TaskCraft 在保持原子任务难度的一致性方面具备更强的优势。
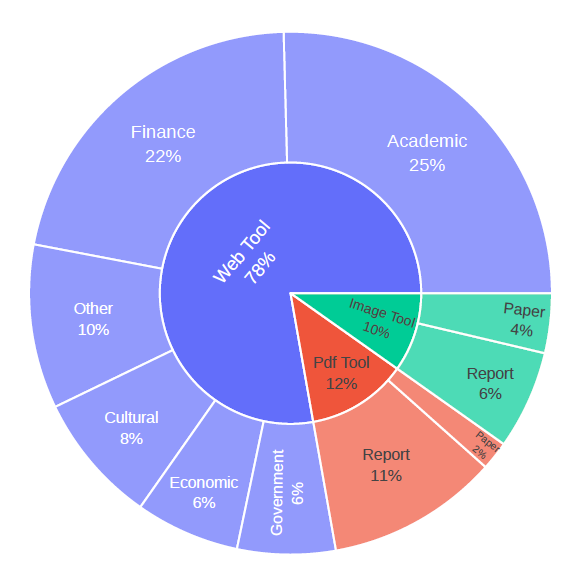
原子数据域分布
基于 TaskCraft,研究者构建了一个包含约 41,000 个 agentic 任务的大规模数据集,为 AI 智能体的系统化调优与评估提供了坚实的基础。该数据集覆盖多个工具使用场景,包括网页搜索、PDF 阅读、图像理解等,任务结构层次丰富,难度可控,支持原子级任务和多跳复杂任务。由于所有任务都附带了真实的执行轨迹,不仅可以进行监督式微调(SFT),还能为强化学习(RL)提供高质量的训练数据起点。这使得该数据集可广泛应用于智能体基础模型的能力增强、Agent 推理策略的评估,以及多工具调用环境下的泛化能力测试。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:[email protected]