上海AI Lab等机构推出VideoRoPE++,一种新颖的视频位置编码方法,有效提升长视频理解能力,并在多个任务中超越现有技术。
原文标题:ICML 2025 Oral工作再升级!上海AI Lab联合复旦、港中文推出支持更长视频理解的最佳工具VideoRoPE++
原文作者:机器之心
冷月清谈:
怜星夜思:
2、YaRN-V外推方案只在时间维度进行频率插值,而保持空间维度不变,这是出于什么考虑?这种不对称的处理方式在其他多模态任务中是否适用?
3、VideoRoPE++在长视频理解任务中表现出色,那么它在计算资源上的开销如何?与传统的RoPE相比,训练和推理的成本会增加多少?
原文内容

本文第一作者魏熙林,复旦大学计算机科学技术学院人工智能方向博士生,研究方向是多模态大模型、高效长上下文;目前在上海人工智能实验室实习,指导 mentor 是臧宇航、王佳琦。
一、背景介绍
虽然旋转位置编码(RoPE)及其变体因其长上下文处理能力而被广泛采用,但将一维 RoPE 扩展到具有复杂时空结构的视频领域仍然是一个悬而未决的挑战。
VideoRoPE++ 这项工作首先进行了全面分析,确定了将 RoPE 有效应用于视频所需的五个关键特性,而先前的工作并未充分考虑这些特性。
作为分析的一部分,这项工作构建了一个全新的评测基准 ——V-RULER,其中的子任务 “带干扰项的大海捞针(Needle Retrieval under Distractor, NRD)” 表明:当前 RoPE 变体在缺乏合理时间维度建模策略时,容易被周期性干扰项误导,表现不稳定。
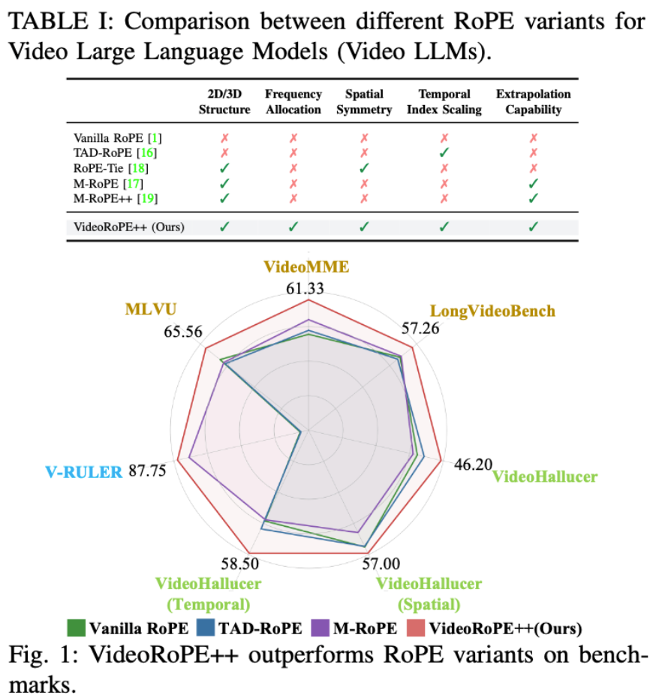
基于分析,作者提出了 VideoRoPE++,它具有三维结构,旨在保留时空关系。VideoRoPE 的特点包括低频时间分配以减轻周期性碰撞、对角布局以保持空间对称性,以及可调整的时间间隔以解耦时间和空间索引。
此外,为提升模型在训练范围之外的外推能力,作者团推还提出了外推方案 ——YaRN-V。该方法仅在低频时间轴上进行插值,同时保持空间维度的稳定性与周期性,从而实现在长视频场景下的结构一致性与外推鲁棒性。在长视频检索、视频理解和视频幻觉等各种下游任务中,VideoRoPE++ 始终优于先前的 RoPE 变体。

-
Paper: https://github.com/Wiselnn570/VideoRoPE/blob/main/VideoRoPE_plus.pdf
-
Project Page:
https://wiselnn570.github.io/VideoRoPE/
-
Code:
https://github.com/Wiselnn570/VideoRoPE/
二、分析
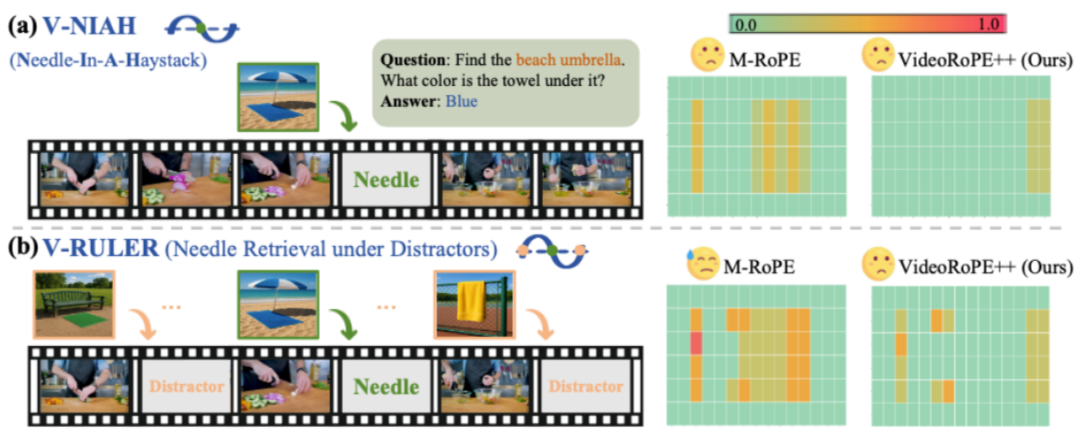
左图:为了展示频率分配的重要性,基于 VIAH(a),作者提出了一个更具挑战性的 benchmark: V-RULER,子任务 Needle Retrieval under Distractors 如(b)所示,其中插入了相似图像作为干扰项。右图:与 M-RoPE 相比,VideoRoPE++ 在检索中更具鲁棒性,并且不容易受到干扰项的影响。
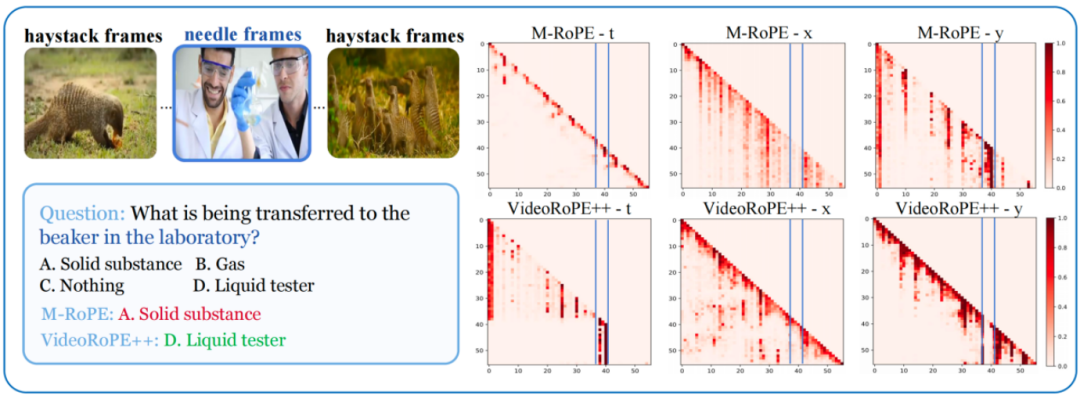
上图:M-RoPE 的时间维度局限于局部信息,导致对角线布局。下图:VideoRoPE++ 有效利用时间维度进行检索。M-RoPE 在定位目标图像上有效,但在多选问题中表现不佳,因为它主要通过垂直位置编码来定位图像,而非时间特征,导致时间维度未能捕捉长距离依赖关系,关注局部信息。相比之下,空间维度则捕捉长距离语义信息,导致 M-RoPE 在频率分配设计上表现较差。
三、VideoRoPE ++ 设计
作者团队提出了 VideoRoPE++,一种视频位置嵌入策略,优先考虑时间建模,通过低频时间分配(LTA)减少振荡并确保鲁棒性。它采用对角线布局(DL)以保持空间对称性,并引入可调时间间隔(ATS)来控制时间间隔,以及提出 YaRN-V 对训练范围以外的位置信息进行外推。VideoRoPE++ 有效地建模了时空信息,从而实现了鲁棒的视频位置表示。
1. 低频时间分配 (LTA):
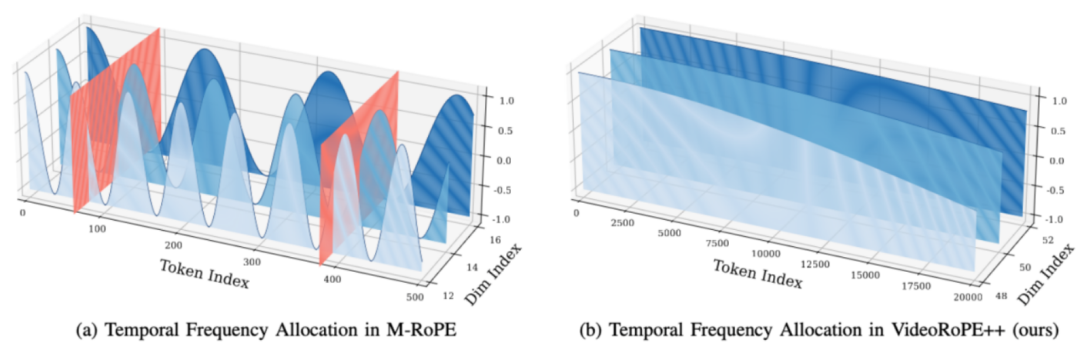
考虑一个基于 RoPE 的 LLM,头部维度为 128,对应 64 个旋转角度 θn,分布在不同维度上。每个图示中,用平行的蓝色平面表示 cos (θnt) 在 3 维上的表现。
(a)对于 M-RoPE,时间依赖性由前 16 个高频旋转角度建模,导致振荡和位置信息失真。低维度间隔较短,振荡周期性使得远距离位置可能具有相似信息,类似哈希碰撞(如红色平面所示),容易引发干扰,误导模型。
(b)相比之下,VideoRoPE++ 通过最后 16 个旋转角度建模时间依赖性,具有更宽的单调间隔。时间建模不再受振荡影响,显著抑制了干扰项的误导效应。
2. 对角线布局 (DL) :
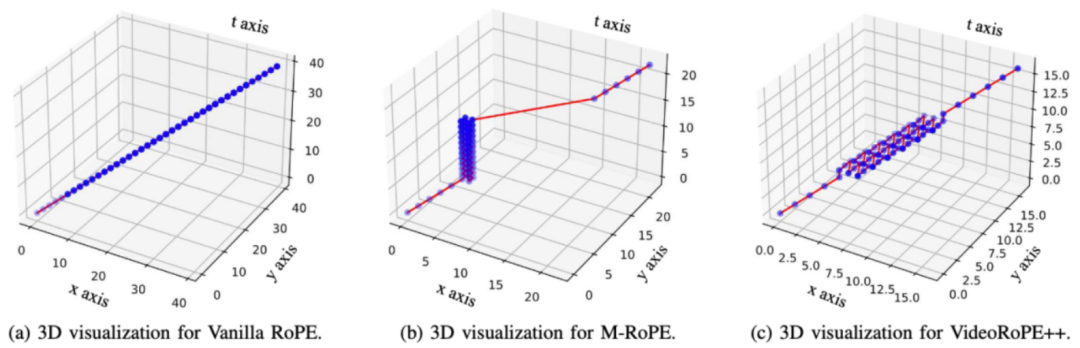
原始 1D RoPE(Su et al., 2024)未包含空间建模。M-RoPE(Wang et al., 2024b)虽然采用 3D 结构,但引入了不同帧间视觉标记索引的差异。相比之下,VideoRoPE++ 实现了平衡,保留了原始 RoPE 一致的索引增长模式,并引入了空间建模。优点包括:1)保留视觉标记的相对位置,避免文本标记过于接近角落;2)保持原始 RoPE 编码形式,相邻帧的空间位置信息增量与文本标记增量一致。
3. 可调时间间隔 (ATS) :
为了缩放时间索引,作者团队引入缩放因子 δ 来对齐视觉和文本标记之间的时间信息。假设 τ 为标记索引,起始文本(0 ≤ τ < Ts)的时间、水平和垂直索引为原始标记索引 τ。对于视频输入(Ts ≤ τ < Ts + Tv),τ − Ts 表示当前帧相对于视频开始的索引,通过 δ 缩放控制时间间距。对于结束文本(Ts + Tv ≤ τ < Ts + Tv + Te),时间、水平和垂直索引保持不变,形成线性进展。根据可调节的时间间距设计,视频位置编码(VideoRoPE++)中 τ-th 文本标记或(τ, w, h)-th 视觉标记的位置信息(t, x, y)如式(7)所示。
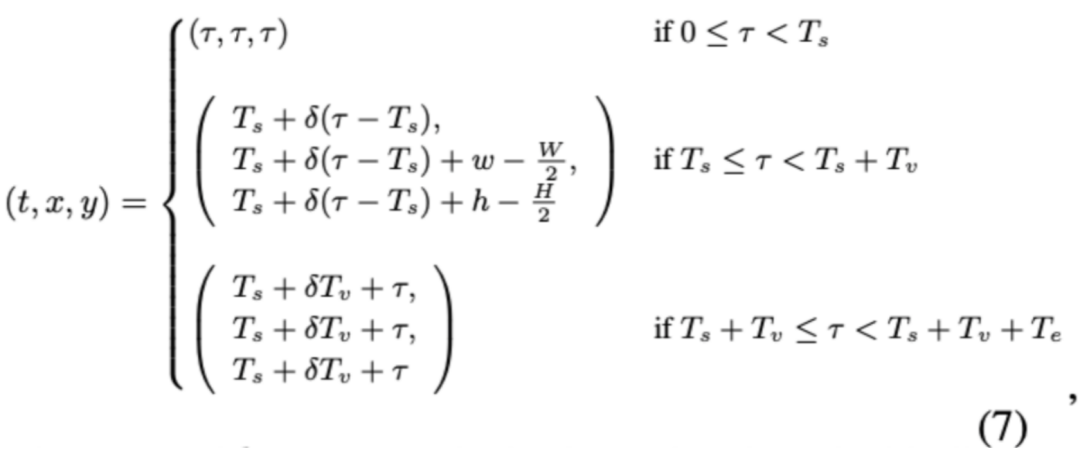
其中,w 和 h 分别表示视觉块在帧中的水平和垂直索引。
4. 基于 YaRN-V 的外推能力
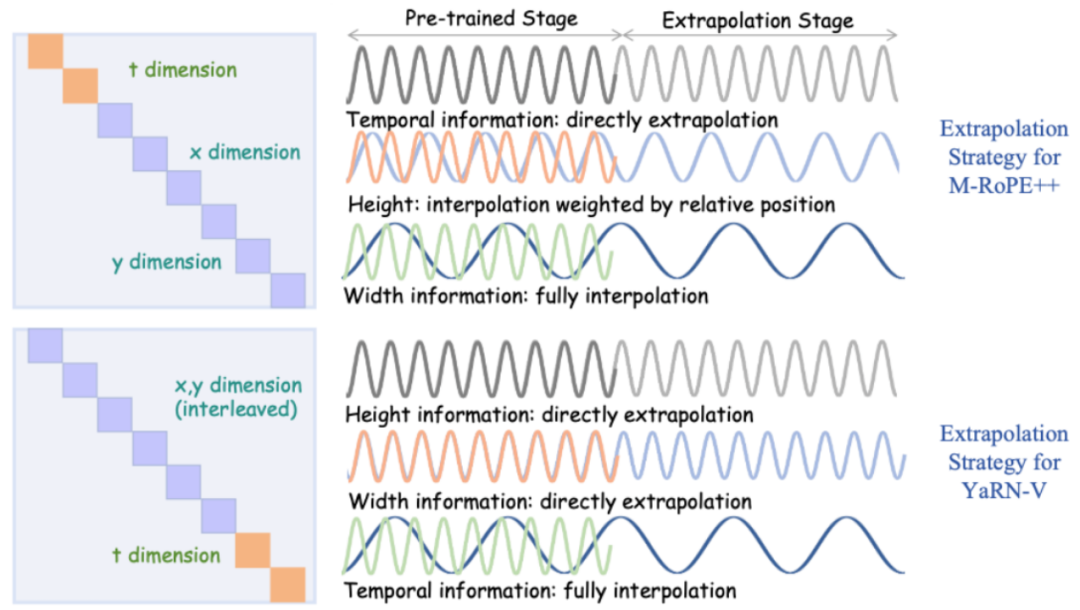
在视频理解任务中,时空维度的差异性对位置编码提出了特殊挑战:空间信息(如纹理与边缘)通常具有局部性和周期性,而时间信息则跨越更长且不确定的范围,依赖更广的上下文建模。为解决这一不对称性,作者提出了 YaRN-V,一种仅沿时间维度进行频率插值的外推方法,同时保持空间维度不变。该选择性设计在保留空间结构的同时,有效提升了长视频建模中的时间泛化能力。YaRN-V 的设计依据于空间与时间维度在频域特性上的本质差异:空间维度处于高频段,训练中已完成一个完整周期,因此模型能自然泛化至未见过的空间位置;而时间维度处于低频段,训练范围内无法覆盖完整周期,因此仅对时间轴插值便可实现有效的长时外推。
四、实验结果
长视频检索任务:
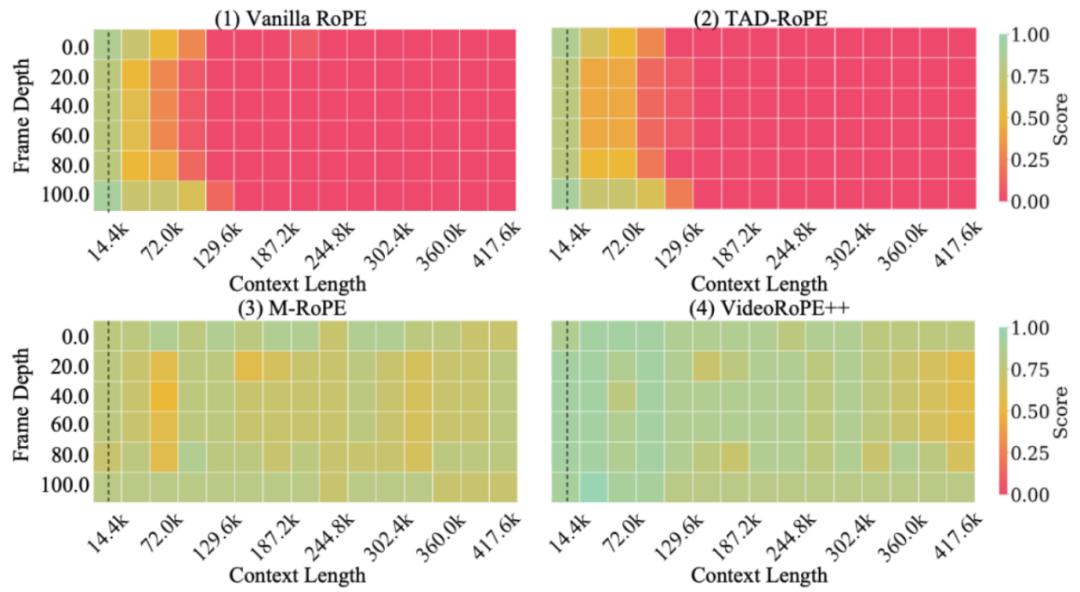
作者团队展示了 VideoRoPE++ 与其他 RoPE 变体在 V-RULER 上的性能。Vanilla RoPE 和 TAD-RoPE 在视觉训练上下文外具备一定外推能力,但超出极限后失效。相比之下,VideoRoPE 和 M-RoPE 在测试上下文内表现优越,且 VideoRoPE 始终优于 M-RoPE,展现出更强鲁棒性。
长视频理解任务:
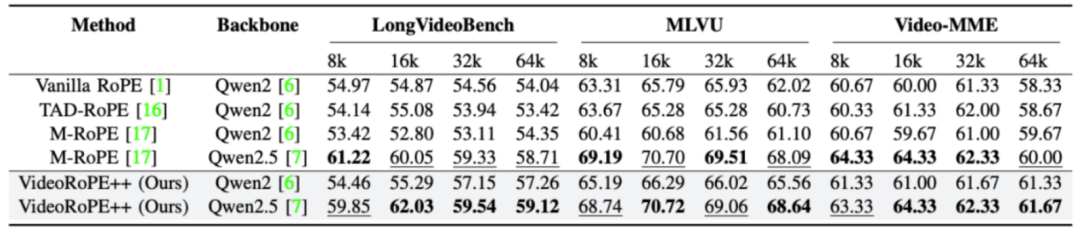
如表所示,作者团队在三个长视频理解基准上比较了 VideoRoPE++ 与现有 RoPE 变体(Vanilla RoPE、TAD-RoPE 和 M-RoPE)。VideoRoPE++ 在这些基准上优于所有基线方法,展示了其鲁棒性和适应性。在 LongVideoBench、MLVU 和 Video-MME 上,VideoRoPE++ (Qwen2 基座) 在 64k 上下文长度下分别比 M-RoPE 提高了 2.91、4.46 和 1.66 分,突显了其在捕捉长距离依赖关系和处理具有挑战性的视频任务中的卓越能力。
外推任务:
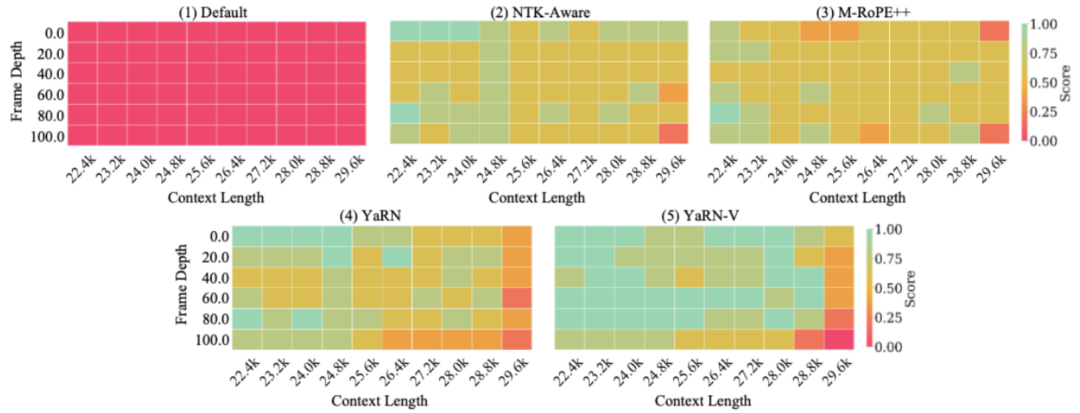
在本次实验中,作者针对超出训练范围的长序列输入,系统评测了多种位置外推方案。在 V-RULER 基准中的 Lengthy Multimodal Stack 任务上,作者提出的方法 YaRN-V 以 81.33 的得分显著领先,较最强基线 YaRN 提升 13.0 分,稳健应对混合模态干扰下的超长位置索引。相比之下,传统位置编码方案已完全失效,而 NTK-Aware(67.66)和 MRoPE++(62.30)等方法虽有一定泛化能力,但整体表现仍有限。
实验结果表明,YaRN-V 能更好支撑视频大模型在长输入场景下的时间对齐,避免位置溢出带来的性能衰退,是多模态长序列理解的理想方案。
五、总结
本文确定了有效位置编码的四个关键标准:2D/3D 结构、频率分配、空间对称性和时间索引缩放。通过 V-NIAH-D 任务,作者展示了先前 RoPE 变体因缺乏适当的时间分配而易受干扰。因此,提出了 VideoRoPE++,采用 3D 结构保持时空一致性,低频时间分配减少振荡,对角布局实现空间对称性,并引入可调节时间间距和外推方案 YaRN-V。VideoRoPE++ 在长视频检索、视频理解和视频幻觉任务中优于其他 RoPE 变体。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com