华为CloudMatrix384超节点是新一代AI云基础设施,通过突破通信瓶颈,提升算力效率,为大模型应用提供强大支持。
原文标题:华为CloudMatrix384超节点很强,但它的「灵魂」在云上
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章提到 CloudMatrix-Infer 采用了一种对等式推理架构,将 LLM 推理分解为预填充、解码和缓存三个独立的子系统。这种分解方式相比传统架构有哪些优势?是否存在潜在的劣势?
3、华为云强调,企业应该选择云服务而非直接购买 CloudMatrix384 超节点。你认为除了文章中提到的几点原因外,还有哪些因素会影响企业的决策?
原文内容
编辑:Panda
AI 领域最近盛行一个观点:已经开始,评估将比训练重要。而在硬件层级上,我们也正在开始进入一个新世代。
过去几年,全球科技巨头的 AI 竞赛还聚焦于「芯片」本身 —— 比拼谁的计算核心更强大,就像 F1 赛场上对引擎马力的极致追求。而今天,战火已经蔓延到一个更宏大的新维度:系统架构。
当所有顶级玩家都拥有了性能强悍的「V12 引擎」后,人们痛苦地发现,真正的瓶颈已不再是单颗芯片的算力,而是如何将成百上千颗芯片连接起来,形成一个高效协同的整体。这就像将一千辆 F1 赛车同时塞进一条乡间小路,再强的引擎也只能在无尽的「堵车」中怠速轰鸣。
这个「交通堵塞」,就是今天 AI 数据中心面临的最致命瓶颈 —— 通信开销。在大模型分布式训练中,节点间的海量数据同步,常常导致算力利用率骤降。无数斥巨资采购的顶级芯片,大部分时间都在等待数据,而不是在计算。也就是说,AI 行业正面临一场深刻的效率危机。
因此,一个根本性的问题摆在了所有人的面前:如何才能彻底拆除芯片之间的「围墙」,构建一个真正没有堵车的「算力高速公路网」?
面对这个 AI 下半场的终极考题,华为云给出了自己的答案:CloudMatrix384 超节点。它不是对现有架构的修修补补,而是一次从底层发起的体系重构。其性能强大 —— 配备了 384 个昇腾 NPU 和 192 个鲲鹏 CPU,还配备了全面的 LLM serving 解决方案华为云 CloudMatrix-Infer,再搭配华为云专门为其开发的其它基础设施软件,就像是一套专为当今和未来的 AI 打造的「云上高速算力运输系统」,其中不仅有性能强大的计算引擎,也有高速传输数据的通信网络。
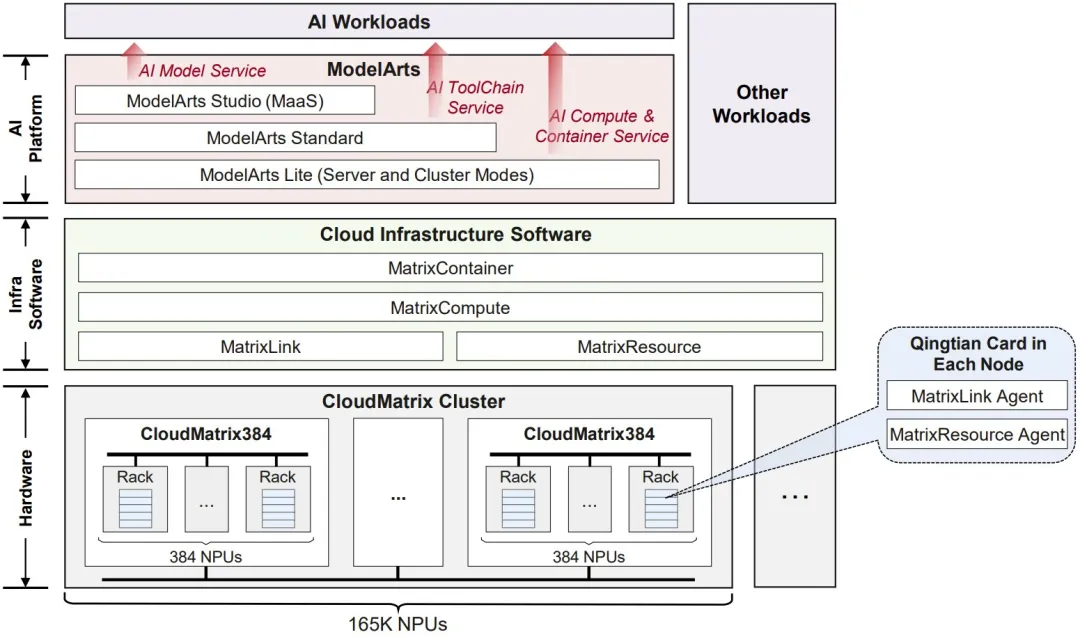
用于部署 CloudMatrix384 的云基础设施软件堆栈
CloudMatrix384 是什么?
从名称也能看出来,CloudMatrix384 超节点中,Cloud(云)是其重要内核,它是基于华为云「下一代 AI 数据中心架构」CloudMatrix 构建的。

CloudMatrix 采用了基于全对等高带宽互联(fully peer-to-peer high-bandwidth interconnectivity)和细粒度资源解耦(fine-grained resource disaggregation)的设计理念,实现「一切可池化、一切皆对等、一切可组合」的架构愿景。体现了华为云重塑 AI 基础设施基础架构的雄心。它的诞生是为了解决 AI 工作负载为数据中心基础设施所带来的一系列挑战,而 CloudMatrix384 则代表了这一愿景和理念的首个生产级实现。

在 2024 年 9 月的第九届华为全联接大会上,华为云 CEO 张平安宣布正式发布 AI 原生云基础设施架构 CloudMatrix
这些术语是什么意思?简单打个比方,我们可以把 CloudMatrix384 看作一个精心设计、高度协同的「超级大脑」。这个大脑拥有 384 个专为 AI 任务设计的昇腾 NPU 以及 192 个处理通用任务的鲲鹏 CPU。NPU 擅长处理复杂的 AI 运算,而 CPU 则负责常规的调度和管理,两者各司其职。
然而,拥有强大的核心只是第一步,另一大关键要让这些核心顺畅沟通。
为此,华为给 CloudMatrix384 引入了一套名为「统一总线(UB / Unified-Bus)」的革命性内部网络。我们可以将其理解为一张遍布整个计算大脑且没有红绿灯的「全对等高速公路」。
相较之下,许多传统架构的 AI 数据中心则更像是一个传统的层级森严的大公司。如果市场部要和技术部沟通一个紧急项目,信息需要先上报给市场总监,再由市场总监传递给技术总监,最后才下达到具体执行人。这个过程充满了延迟和瓶颈,就像是节点之间、芯片之间的通信带宽不均衡,效率也就可想而知了。
而在 CloudMatrix384 中,任何一个处理器(NPU/CPU)都能与其他任意处理器进行直接、高速的对话,实现了真正的「全对等」。
这就像一个极度扁平化的精英团队,所有专家围坐在一张圆桌旁,可以随时、无障碍地与任何人交流协作,信息传递几乎没有延迟。这种架构特性尤其适合需要大量「专家」紧密协作来完成一项任务的现代大模型(特别是混合专家 / MoE 模型),因为它从根本上解决了 AI 并行计算中最大的瓶颈——通信。
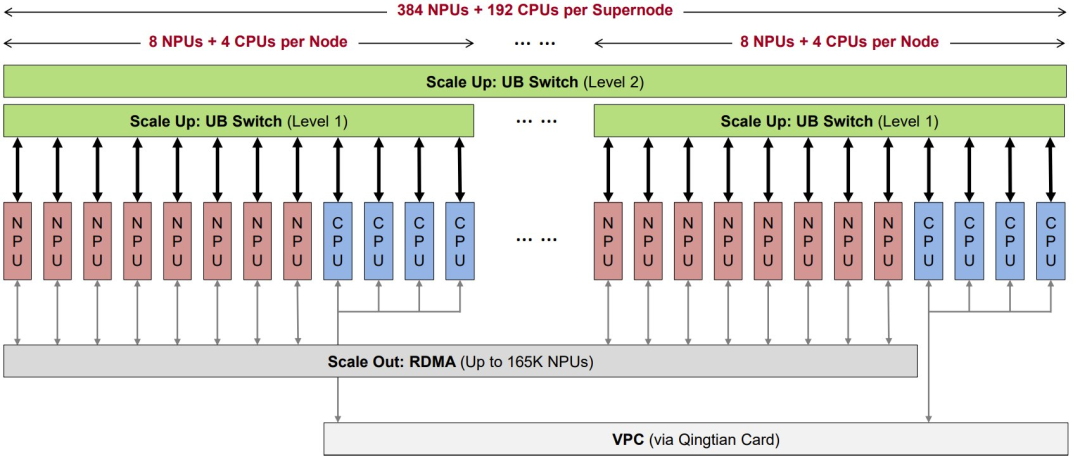
CloudMatrix384 超级节点的对等式硬件架构,具有一个超高带宽的统一总线(UB)平面(用于超级节点内部扩展)、一个 RDMA 平面(用于超级节点间通信)以及一个虚拟私有云(VPC)平面(用于与数据中心网络集成)。
当然,这些都还只是 CloudMatrix384 创新的一部分,其已经发布的技术报告中还有大量值得挖掘的技术细节。对此感兴趣的读者可千万不要错过:

-
论文标题:Serving Large Language Models on Huawei CloudMatrix384
-
论文地址:https://arxiv.org/pdf/2506.12708.pdf
在此技术报告中,与 CloudMatrix384 一道展示的还有 CloudMatrix-Infer。这是一个全面的 LLM 推理解决方案,代表了部署大规模 MoE 模型(例如 DeepSeek-R1)的一个最佳实践。
具体来说,CloudMatrix-Infer 引入了三大核心创新。
首先,他们设计了一种全新的对等式(peer-to-peer)推理架构,将 LLM 推断系统分解为三个独立的子系统:预填充(prefill)、解码(decode)和缓存(caching)。
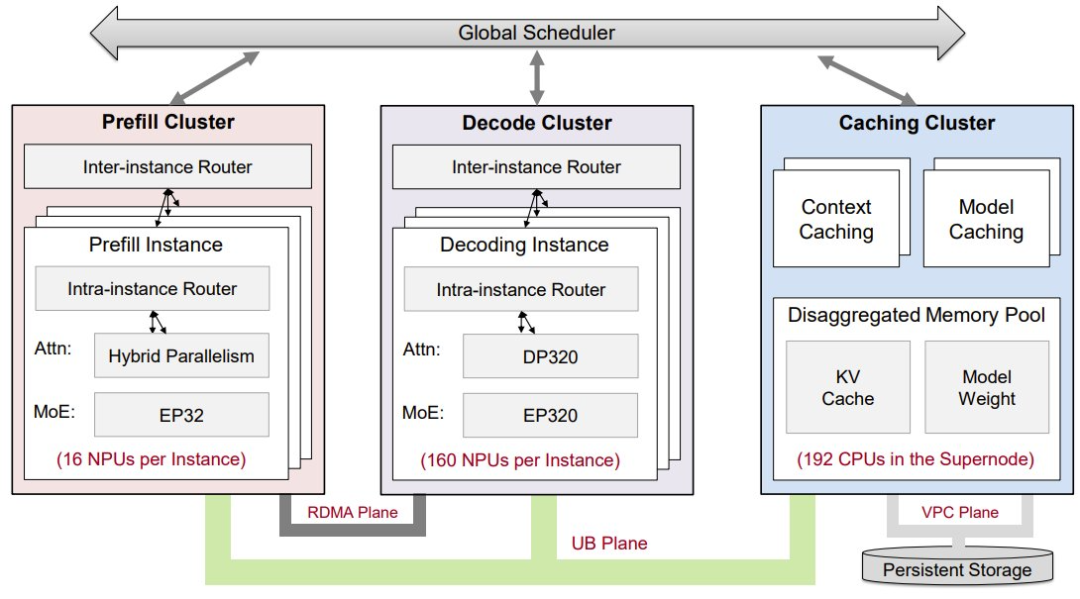
新提出的对等式 serving 架构可使所有 NPU 能够通过超高带宽 UB 网络统一访问由分解式内存池支持的共享缓存集群。
对等式意味着这三个子系统可作为平等且独立的资源池运行,而无需围绕一个中心化实体进行协调。这与传统的以 KV cache 为中心的架构大不一样,后者是将请求调度与缓存的 KV 块的物理位置紧密耦合,增加了调度复杂性并限制了资源分配的灵活性。
通过利用高带宽 UB 互连,华为构建了一个分离式内存池(disaggregated memory pool),可在整个系统中提供共享缓存服务。预填充和解码子系统中的所有 NPU 都可以对等方式直接从该池访问缓存的 KV 数据,并保持统一的带宽和延迟,无论数据最初的计算或存储位置如何。这种设计可将请求调度与数据本地性解耦,从而可以极大简化任务调度逻辑、提高缓存效率、提升整体系统资源利用率。
其次,他们开发了一种专门针对 MoE 模型优化的大规模专家并行 (LEP) 策略。
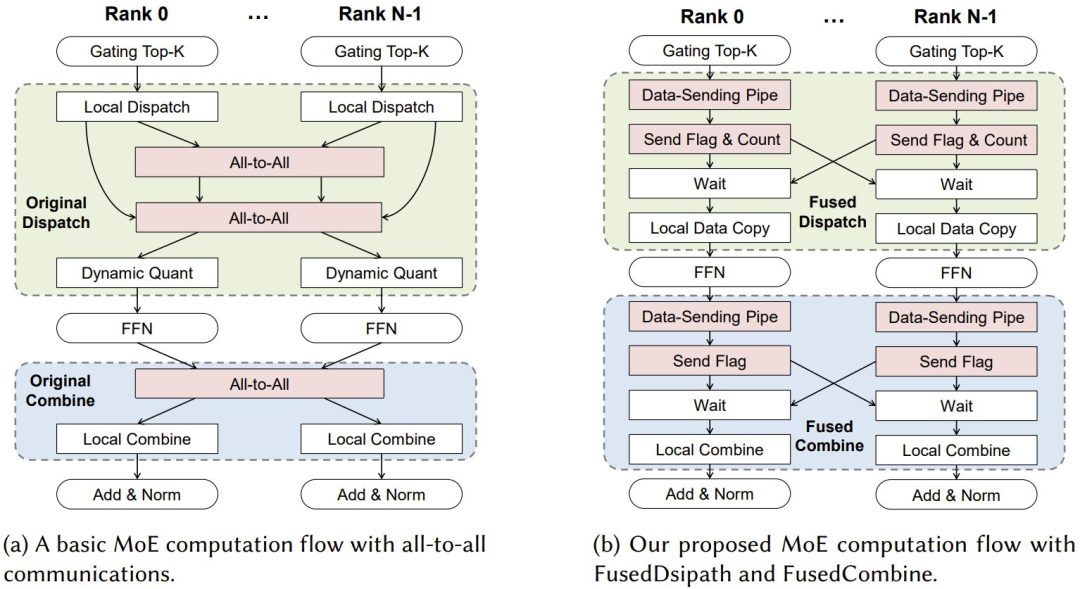
(a) 是基本的 MoE 计算流,(b) 是新提出的 MoE 计算流
LEP 的核心原理是聚合大量 NPU 的计算能力和内存带宽,以加速注意力和前馈网络的计算。这种加速的代价是 Token 调度和专家输出组合带来的通信开销增加。然而,CloudMatrix384 的超高带宽 UB 互连可确保这种通信延迟保持在可控范围内,不会成为主要的性能瓶颈。
此外,新提出的 LEP 策略支持极高的专家并行度,例如 EP320,这使得每个 NPU 芯片能够恰好承载 DeepSeek-R1 的一个专家。此配置可最大限度地减少同等级专家之间的串行执行,从而降低了整体 MoE 执行延迟。
这些设计选择共同实现了低解码延迟,并为基于 MoE 的推理带来了显著的端到端性能提升。
最后,他们提出了一套专为 CloudMatrix384 量身定制的硬件感知型优化方案,包括高度优化的 Ascend 算子、基于微批次的 pipelining 和 INT8 量化。
-
经过优化的算子可加速端到端执行,并为 LEP 提供高效的支持。
-
基于微批次的 pipelining 设计可通过重叠两个连续微批次的处理,提高资源利用率和系统吞吐量。
-
INT8 量化可提高计算效率,并显著降低内存带宽消耗。
这些优化与 CloudMatrix384 超节点独特的架构特性(包括 on-chip cube、向量和通信引擎以及高带宽 UB 互连)协同设计,从而最大限度地提高了整体执行效率。
说到这里,就不得不赞叹一番华为的前瞻性了。
其实早在 2022 年,当整个行业对大模型的未来还看法不一、ChatGPT 尚未问世时,华为就极富远见地坚持并主导了这个 384 卡超大集群的架构愿景。要知道,在当时,还很少人能想象算力需求会爆炸到今天的程度。
其技术报告中写到:「CloudMatrix384 的设计初衷是提升互连带宽和通信效率 —— 这些核心功能对于扩展大规模训练和推理工作负载至关重要。DeepSeek-R1 等大规模 MoE 模型的出现验证了这一架构远见,凸显了在现代 LLM 部署中,通信带宽与计算和内存带宽能力同等重要。」
正是这份对技术趋势的深刻洞察和坚持,才造就了华为云 CloudMatrix384 超节点这个超级计算引擎。它就像六百多年前从南京龙江港出发的郑和「宝船舰队」,正航向 AI 的浩瀚大洋。
CloudMatrix384 超节点虽好
但在云上用它更好
如此强大的 AI 算力超级服务器,是否意味着只要买到手,就能在 AI 军备竞赛中无往不胜?

华为云 CloudMatrix384 超节点,图源:华为开发者大会 2025
答案,可能恰恰相反。
对于绝大多数企业来说,直接购买并运营 CloudMatrix384,无异于一场充满巨大风险和挑战的豪赌。
资料显示,下一代云计算体系架构将是矩阵式的,其核心是「一切皆对等、一切可池化、一切可组合」。本质是让算力、内存、网络像水一样,可按需组成不同类型的资源池,并自由流动在集群内。而这种能力,只有在云上才能淋漓尽致地发挥。因为使用华为云,可以免除自己购买和部署的四大痛点:成本高、利用率不足、部署与调优困难、难以持续受益于新技术。
如何跨越门槛获取全球最强超节点?
诸多黑科技加身的华为云 CloudMatrix384 超节点价格相当高 —— 约 800 万美元,如此高的门槛,足以把绝大多数企业关在门外。而这还仅仅是初始成本,后续的机房、电力、散热等一系列运营成本,更是一笔持续的巨大开销。
而华为的昇腾 AI 云服务,巧妙打破了这个门槛。云上算力,可以让企业根据自己的需求租用华为云 CloudMatrix384 超节点的一部分,并且能做到随租随用和按需付费。这能极大地降低使用门槛,让任何规模的企业都有机会体验到顶级 AI 算力的威力。
利用率不足:买船不如买船票
很多企业斥巨资购买高端算力,却陷入了残酷的效率陷阱。在大模型分布式训练中,节点间的协作会产生通信瓶颈,导致算力利用率从 85% 骤降至 52 %。
更有甚者,受限于集群调度、网络拓扑等能力,很多企业最终只能获得 30% 的集群算力利用率。这意味着企业花重金买来的宝贵资源,在大部分时间里并没有创造价值,如同停在港口「晒太阳」—— 技术人员戏称其为「算力摸鱼」 ,造成了巨大的浪费。
选择云就不一样了。云的本质是共享经济,能实现资源利用率的最大化。华为云通过智能调度,创新地打造了基于训推共池(节点在训练和推理任务间切换 < 5 分钟)方案的「朝推夜训」模式:白天,算力可以服务于需要快速响应的在线推理业务;到了夜晚,闲置的算力则可以无缝切换,用于耗时较长的模型训练任务,让算力 24 小时连轴转,将每一分钱都用在刀刃上。
另外,通过 MatrixCompute 这项黑科技,华为云还实现了资源的「柔性计算」。它就像拆除了资源仓库间的围墙,能将零散的「独轮车」按需组装成「超级集装箱车」或「超跑」。系统会实时监测任务负载,动态调整资源配比,消除资源浪费或瓶颈,单任务资源利用率可提升 40% 至 100%。
华为云表示:「后续,我们还会提供更灵活的共享资源方案,持续帮助客户提升算力资源利用率。」
部署与调优也是绕不过去的槛儿
其实,就算企业真的选择了购买华为云 CloudMatrix384 超节点,要想真正将其用起来,也仍会面临很多部署与调优方面的困难,包括适配合适的算子和推理框架、配置故障监控与恢复流程等等。此外,超节点自身的运维极其复杂,它采用了大量的光模块,而这种部件故障率高,处理起来对客户来说是个沉重的负担。
为了开发和适配这套系统,华为内部顶级的技术团队花费了整整两年的时间。普通企业若要从零开始,其难度可想而知。
直接使用华为云,就可以直接享受其那套耗时两年打磨的成熟方案。
通过一系列技术优化,华为云确定性运维服务可以保障超节点运行长稳快恢,包括软硬件协同改进、程级重调度恢复和进程级在线恢复能力优化、训练任务线性度提升、推理故障快恢、超平面故障诊断能力等。比如 MatrixContainer 可实现「应用 - 基础设施」双向智能协同,能为应用实时分配最优路径,自动实现并行,并行效率业界领先 15% 以上。
这些技术累加下,华为云能做到光模块业务故障影响降低 96%、通用硬件故障万卡 10 分钟级快速恢复、千亿稀疏模型线性度优化达 95%+、千亿 MoE 分布式推理分钟级恢复、10 分钟内恢复网络故障。
此外,华为云还构建了昇腾云脑,其作用是扮演「AI 检修员」。它采用「三层容错」智能运维架构,能做到「1 分钟发现,10 分钟恢复」,将故障恢复时长缩短 50% ,为超节点运行提供长稳保障。
迭代速度那么快,买买买怎么才能跟得上这节奏?
答案就是:以租代买。
AI 领域的技术可谓日新月异,如果企业选择自己购买和部署华为云 CloudMatrix384 超节点,那么得到的是交付那一刻的硬件和技术能力。随着技术发展,硬件可能会慢慢落后于时代,无法享受到最新的技术红利。
云服务最迷人的地方也恰恰在此 —— 它能为你持续提供最新的科技加成。
例如,华为云通过分布式 QingTian 这一架构底座,实现了 CloudMatrix 中的「一切可池化」。它通过创新的 Memlink-direct 技术,将内存跨主机直接共享,彻底打破「单机内存墙」,构建统一的逻辑内存池。这正是「以存强算」EMS 服务的技术核心,能将首个 token 时延降低 80%。

EMS 弹性内存服务,图源:华为开发者大会 2025
再如,华为云通过 MatrixLink 实现了「一切皆对等」。它如同将只能行驶 1 辆车的乡间小路,扩建成 10 车道的高速公路,并配上智能导航系统。通过对组网、协议、通信语义和调度的四层重构,将 NPU 卡间通信带宽提升 32 倍,小包传输时延降低 100 倍,让万卡通信「0」冲突。
综上所述,无论是从成本和利用率,还是从部署调优和技术升级来看,通过华为的昇腾云来获取 CloudMatrix384 都无疑是企业奔赴 AI 新大陆的「最优解」。
效果如何?用数字说话
为了展示真正的实力,华为云使用 CloudMatrix-Infer 基于 CloudMatrix384 上部署了参数量高达 671B 的大规模 MoE 模型 DeepSeek-R1。
针对 DeepSeek-R1 等大规模 MoE 模型的特有架构,华为还进行了一些针对性的设计,包括基于昇腾 NPU 的多 token 预测(MTP)优化、使用混合并行化的 MLA 流、基于 CloudMatrix384 的预填充 pipeline 和解码 pipeline 以及 EMS(弹性内存服务)等。
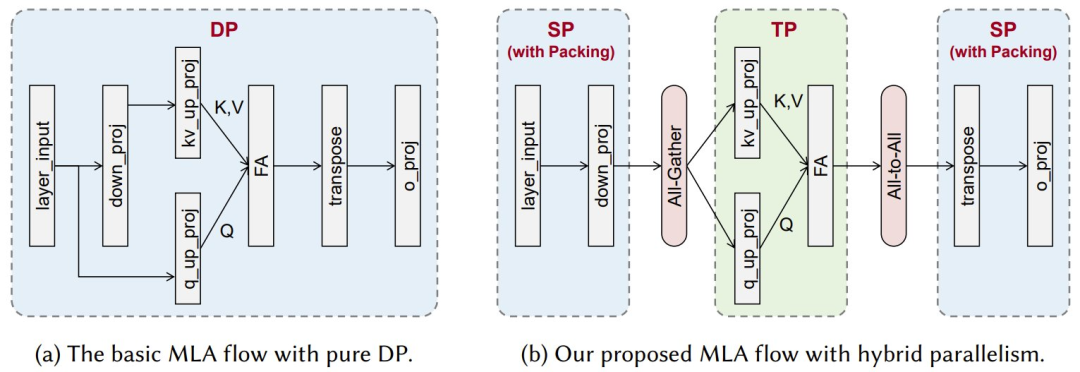
基础的 MLA(多头隐注意力)流 vs. 华为提出的支持混合并行的 MLA 流
这里我们就不再过多关注技术细节了,直接来看实验结果。可以说,实战表现十分亮眼!
首先,我们可以把大模型的一次问答,简单拆解为两个关键阶段来理解:
-
预填充: 好比是 AI 在阅读和理解你的问题。无论你的问题有多长,它都需要尽快读完并消化。
-
解码: 这是 AI 写出答案的过程,它会一个字一个字地生成回复内容。
在考验「阅读理解」能力的预填充阶段,CloudMatrix-Infer 在处理一个 4K 长度的问题时,可实现每 NPU 6,688 个 token / 秒的吞吐量,相当于每 TFLOPS 4.45 个 token / 秒的计算效率。
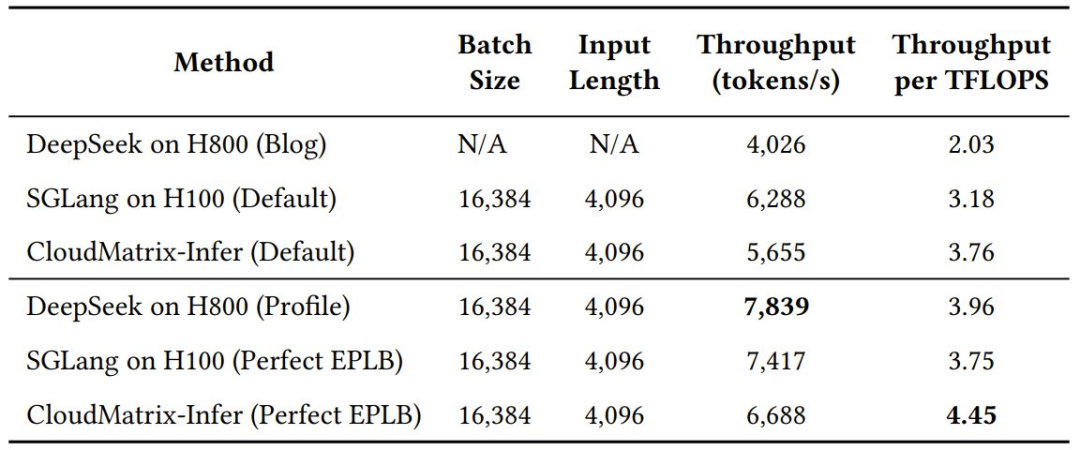
使用不同加速器时,DeepSeek-R1 的总体预填充吞吐量
而在更关键的解码阶段,该系统在 4K KV cache 长度下能维持每 NPU 1,943 个 token / 秒的吞吐量,同时可将输出每个 token 的时间(TPOT)始终保持在 50 毫秒以下,从而实现了每 TFLOPS 1.29 个 token / 秒的效率。
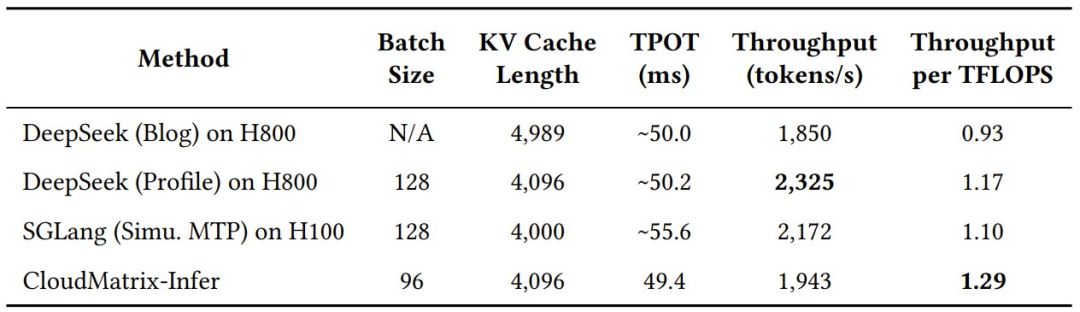
使用不同加速器时,DeepSeek-R1 的总体解码吞吐量
值得注意的是,这两个阶段的计算效率指标均超越了业界的领先框架,比如在 NVIDIA H100 上运行的 SGLang 以及 DeepSeek 官方在 NVIDIA H800 上运行的结果。
这说明,CloudMatrix384 不仅「跑得快」,而且「更省油」,它能更高效地将每一份宝贵的算力都压榨出来,用在刀刃上。
实验还表明,CloudMatrix-Infer 还可以有效管理吞吐量与延迟之间的权衡。
此外,AI 服务也像货运,有时追求「多拉快跑」(高吞吐),有时则需要「风驰电掣」(低延迟)。
实验表明,CloudMatrix-Infer 可以轻松地在这种需求间权衡。当客户需要极低的延迟,比如要求每个 token 的响应时间必须在 15 毫秒以内时,系统可以通过动态调整,实现每秒 538 个 token 的解码吞吐量,展现了其在不同服务场景下的高度适应性和性能可预测性。
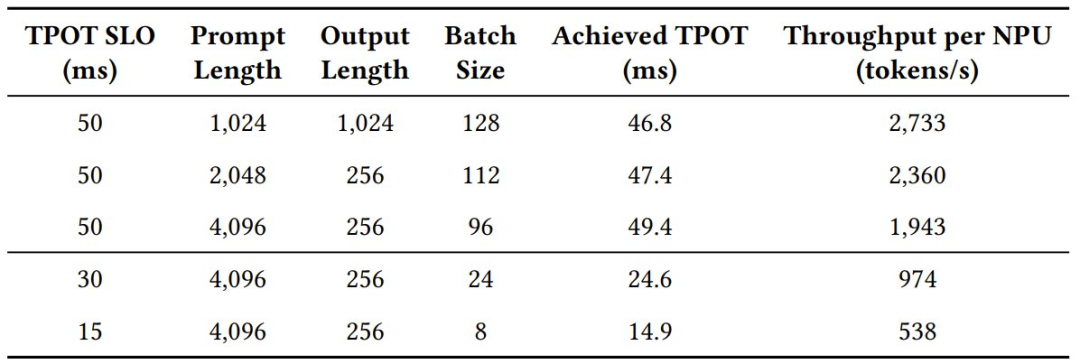
华为云 CloudMatrix384 超节点在不同 TPOT SLO 和提示词 / 输出长度下的解码吞吐量。
此外,为了让 DeepSeek-V3/R1 等大规模 MoE 模型实现高吞吐量、低延迟的推理,华为还设计并实现了一种用于模型权重和激活值的无训练分层式 INT8 量化方案。该方案可在最大化计算效率和减少内存占用的同时,精细地控制准确度损失。
该优化方案的实验表现也相当不错。在 16 个代表性基准测试中,INT8 量化保持了与官方 DeepSeek-R1 API 相当的准确度。这表明,在昇腾 NPU 上部署的 INT8 量化可有效地保留模型在各种任务中的性能。

采用 INT8 量化时,在昇腾 NPU 上的 DeepSeek-R1 与 DeepSeekR1 官方 API 的准确度比较
华为也进行了消融实验,验证了各组件的有效性。
总体而言,这些结果表明:CloudMatrix384 与对等 serving 解决方案 CloudMatrix-Infer 相结合,可以成为一个可扩展、高吞吐量、生产级的大规模 LLM 部署平台。
下一代 AI 算力
起锚扬帆
AI 时代的浪潮已至,其竞争的核心,早已超越了单纯的芯片比拼,进入了系统架构、软件生态和云服务协同的深水区。谁能率先实现计算、通信、存储三位一体的系统级融合,谁就能定义下一阶段 AI 基础设施的范式。华为云 CloudMatrix384 的出现,正是对这一趋势的最好回应,它所代表的或许正是下一代 AI 数据中心的形态。
在华为 CloudMatrix384 论文中,华为也透露了其更宏大的技术前瞻性,包括更近期的统一 VPC 和 RDMA 平面、扩展到更大的超节点、CPU 的资源分解和池化以及进一步改进 推理系统。这清晰地表明:今天的华为云 CloudMatrix384 超节点,才不过是个起点,前方还有广阔天地,而它也将把百模千态载向广阔天地。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com