华为开源盘古大模型,包含70亿和720亿参数版本,并分享昇腾推理技术。直播将深入解析模型训练与推理优化,展现应用效果,不容错过。
原文标题:直播预告:「开箱」华为盘古首个开源大模型
原文作者:机器之心
冷月清谈:
怜星夜思:
2、盘古 Pro MoE 模型中提到的 MoGE 创新架构,通过混合专家分组的路由策略来解决传统 MoE 模型的负载不均衡问题。那么,这个分组的依据是什么?是如何保证不同设备间专家数量均衡的?在实际训练过程中,这种策略会带来哪些额外的挑战?
3、昇腾平台 Pangu Pro MoE 全链路高性能推理系统优化实践中,提到的 H2Parallel 分层混合并行优化、TopoComm 拓扑亲和通信优化、DuoStream 多流融合通算掩盖等技术,分别解决了哪些具体的问题?这些技术在其他AI芯片或者平台上是否具有普适性?
原文内容

这周一,开源阵营又迎来一个重磅玩家 —— 华为盘古。
这次,这个新玩家一口气宣布了两个大模型的开源 ——70 亿参数的稠密模型「盘古 Embedded」和 720 亿参数的混合专家模型「盘古 Pro MoE」,甚至连基于昇腾的模型推理技术也一并开源了。
综合来看,这两个大模型都不是「等闲之辈」:在 SuperCLUE 5 月榜单上,盘古 Pro MoE 在千亿参数量以内的模型中,排行并列国内第一。在智能体任务上,它的打榜成绩甚至比肩 6710 亿参数的 DeepSeek-R1,在文本理解和创作领域也达到开源模型的第一名。盘古 Embedded 也是相当能打,在学科知识、编码、数学和对话能力方面均优于同期同规模模型。
更重要的是,这些模型采用了一些领先的技术来实现高效的训练和推理,比如分组混合专家 MoGE 算法、自适应快慢思考合一以及全链路的高性能推理系统优化。在极度注重效率的行业应用中,这些技术至关重要,也是当前大模型赛道除了性能之外的竞争重点。
在之前的文章中,机器之心已经对这些技术做了一些介绍(见文末扩展阅读)。在阅读过程中,大家可能有一些疑问。不过,没关系,7月4日,我们请来了华为盘古幕后的多位研究人员进行技术分享和交流,一次性帮大家解答疑惑。
这些研究人员将深入解析两个模型在训练和推理优化方面的核心技术,并通过盘古 Pro MoE 的实际演示展现其应用效果。无论你是学术研究者还是行业从业者,都将从这场技术分享中获得宝贵的洞察和启发。
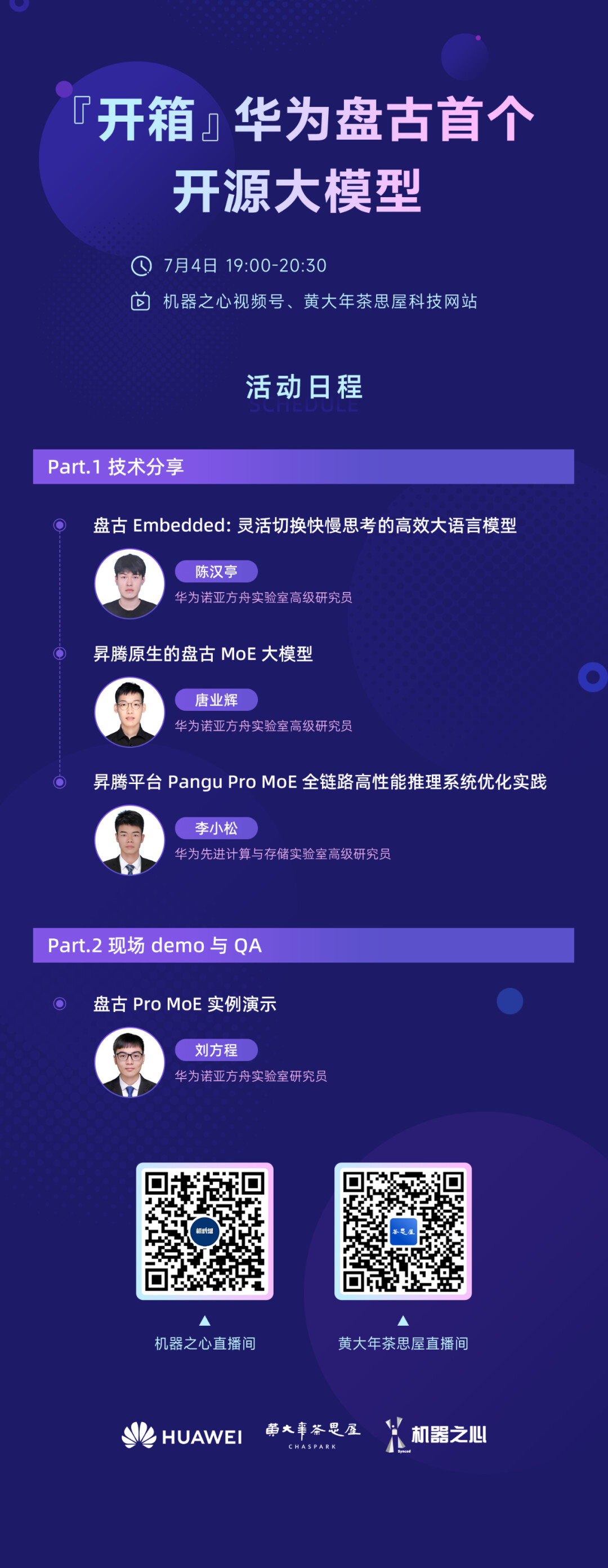
主题一:盘古 Embeded: 灵活切换快慢思考的高效大语言模型
内容概览
本研究提出了盘古 Embeded(一款兼具高效性与推理能力的灵活思维语言模型),该模型基于昇腾神经网络处理器(NPUs)训练,具备快速与深度交替的思维能力。
针对现有推理大语言模型存在的计算成本过高(参数量大)和延迟问题(由冗长的思维链冗长),我们构建了多维优化框架,整合三大核心技术:(1)迭代式蒸馏微调策略平衡基础推理能力提升与任务特定适配;(2)通过延迟容忍调度框架实现昇腾平台上的可扩展强化学习,该框架创新性地结合延时同步并行(SSP)与分布式优先数据队列;(3)双系统快慢思维框架实现效率与深度的自适应协调,提供手动 / 自动模式切换功能以灵活应对不同任务需求。
实验表明,盘古 Embeded 在显著降低推理延迟的同时保持卓越推理精度,特别适用于移动设备等资源受限场景。本研究开创了在保持实际部署能力前提下,通过统一方法提升端侧大语言模型推理能力的路径。
分享嘉宾
陈汉亭,北京大学智能科学专业博士,现任华为诺亚方舟实验室高级研究员,主要研究方向为大语言模型架构、压缩加速、reasoning 等,在国际顶级会议、期刊发表论文 50+篇,论文被引用 8000+次,担任 NeurIPS 等国际顶级学术会议领域主席,曾获 CVPR24 最佳学生论文 runner up,曾入选斯坦福全球 Top2% 学者榜单。

主题二:昇腾原生的盘古 MOE 大模型
内容概览
MOE 模型可以兼容模型效果和推理效率,已经逐渐成为业界模型的主流。本研究提出 Pangu Pro MoE,一款昇腾原生的 MOE 大模型(总参数 72B,激活参数 16B),兼顾精度和效率,在权威榜单 SuperCLUE 千亿内模型档位上并列国内第一。
为解决传统 MoE 模型的负载不均衡问题,本研究提出 MoGE 创新架构,通过混合专家分组的路由策略,最大程度保证了不同设备间专家数的均衡,并在昇腾平台上建模仿真,选取昇腾亲和的最优规格。此外,通过混合并行优化、通算融合、量化压缩、算子优化等系统方法,软硬协同优化,大幅提升了模型在昇腾 910、昇腾 310 等硬件平台的推理效率。
基于大量高质量数据,模型在 4000 + 昇腾 NPU 集群长稳训练,拥有强大的慢思考能力,在通用知识、数学推理等多个方面均取得了优于现有同规模模型的效果,详细技术报告可见:https://arxiv.org/pdf/2505.21411.
分享嘉宾
唐业辉,华为诺亚方舟实验室高级研究员,主要研究方向是深度学习和 AI 大模型,特别是大语言模型的架构、训练和高效部署。他负责训练了多个盘古基础大模型,其中盘古 Pro MoE(72B)大模型、盘古 Ultra MoE(718B)大模型综合能力同量级业界领先,1.5B、3B 等端侧大模型在多款终端产品商用。他博士毕业于北京大学,在 NeurIPS、ICML 等顶会发表论文 50 余篇,谷歌学术被引 8000 余次,并担任 NeurIPS 等国际顶级会议领域主席(Area Chair)。

主题三:昇腾平台 Pangu Pro MoE 全链路高性能推理系统优化实践
内容概览
Scaling Law 持续演进的趋势下,混合专家(MoE)架构凭借其动态稀疏计算特性而备受青睐,其能够在同等算力规模下训练出参数更大且效果更优的模型,已成为通往通用人工智能(AGI)的关键路径。然而,MoE 模型在推理部署时存在内存占用高、访存效率低、路由不均衡等问题,直接部署的推理性能低下。
针对这些难题,本研究围绕盘古 Pro MoE 模型和昇腾平台开展软硬协同系统优化,在系统侧构建 H2Parallel 分层混合并行优化、TopoComm 拓扑亲和通信优化、DuoStream 多流融合通算掩盖等技术,实现最优分布式并行推理提高计算效率;在算子侧设计开发 MulAttention 融合计算、SwiftGMM 融合计算、MerRouter 融合计算等算子融合技术,充分释放昇腾的澎湃算力。
通过模型架构与昇腾平台亲和的系统优化,能够大幅提升盘古 Pro MoE 模型在昇腾平台的推理效率,实现极致推理性能。
分享嘉宾
李小松,华为先进计算与存储实验室高级研究员,博士毕业于清华大学,主要研究方向为推理系统性能优化和 AI 计算系统架构,在国际顶级会议和期刊发表论文 10 余篇。

主题四:盘古 Pro MoE 实例演示
内容概览
围绕通用问答、复杂推理、金融场景等任务,我们将直播演示盘古模型的特性并做深度解析。
分享嘉宾
刘方程,华为诺亚方舟实验室研究员,硕士研究生毕业于北京大学。近期的主要研究方向包括语言模型的预训练和推理加速。多项研究成果发表于 ICML、NeurIPS 等顶级学术会议,曾获得 ImageNet 无限制对抗攻击 @CVPR2021 赛道冠军。

扩展阅读:
-
《》
-
《?》
-
《》
-
《》
-
《》
-
《》
直播间
本次分享将在机器之心视频号与黄大年茶思屋科技网站直播,欢迎大家关注预约。
