上海交大&Meta发布OS-Kairos系统,提升GUI智能体可靠性。通过置信度预测与人机协作,有效避免“过度执行”,任务完成率显著提升。
原文标题:让GUI智能体不再「过度执行」,上海交大、Meta联合发布OS-Kairos系统
原文作者:机器之心
冷月清谈:
怜星夜思:
2、OS-Kairos目前主要在移动GUI环境验证,那么它在桌面端、Web端等更复杂的交互界面上的泛化能力如何?为了让它在这些平台上也能良好工作,可能需要做哪些改进?
3、OS-Kairos依赖GPT-4o进行置信度评分,这是否会成为性能瓶颈或引入额外的成本?如果未来要实现模型内部置信度量化,有哪些可行的技术方案?
原文内容

本文第一作者是上海交通大学计算机学院三年级博士生程彭洲,研究方向为多模态大模型推理、AI Agent、Agent 安全等。通讯作者为张倬胜助理教授和刘功申教授。
一、论文概述
1.1 研究背景
随着多模态大语言模型(Multimodal Large Language Models, MLLMs)的快速发展,越来越多的研究聚焦于构建能够在图形用户界面(GUI)中执行复杂任务的智能体。这些智能体利用视觉感知与语言理解能力,已在移动应用、Web 导航及桌面操作等领域显示出巨大潜力。然而,现有系统大多采用 “全自动” 执行范式,在面对真实场景中的模糊指令、环境干扰或系统异常时,常出现误操作或任务失败等现象。这类 “过度执行”(Over-execution)问题,严重限制了 GUI 智能体在实际应用中的安全性与可靠性。

三种复杂场景
1.2 研究问题
本研究关注一个核心问题:如何赋予 GUI 智能体自我评估其行为置信度的能力,并基于此实现自主与人工交互间的动态切换,从而在复杂环境中提升任务完成率与交互效率。具体而言,当前 GUI 智能体在操作中缺乏对 “当前步骤是否需要人工指导” 的判断能力,一旦模型在某一步操作中产生低置信度的决策,仍可能继续执行错误行为,导致后续任务链条崩溃。论文尝试解决的正是这种因无法判断自身能力边界而导致的系统性失误。
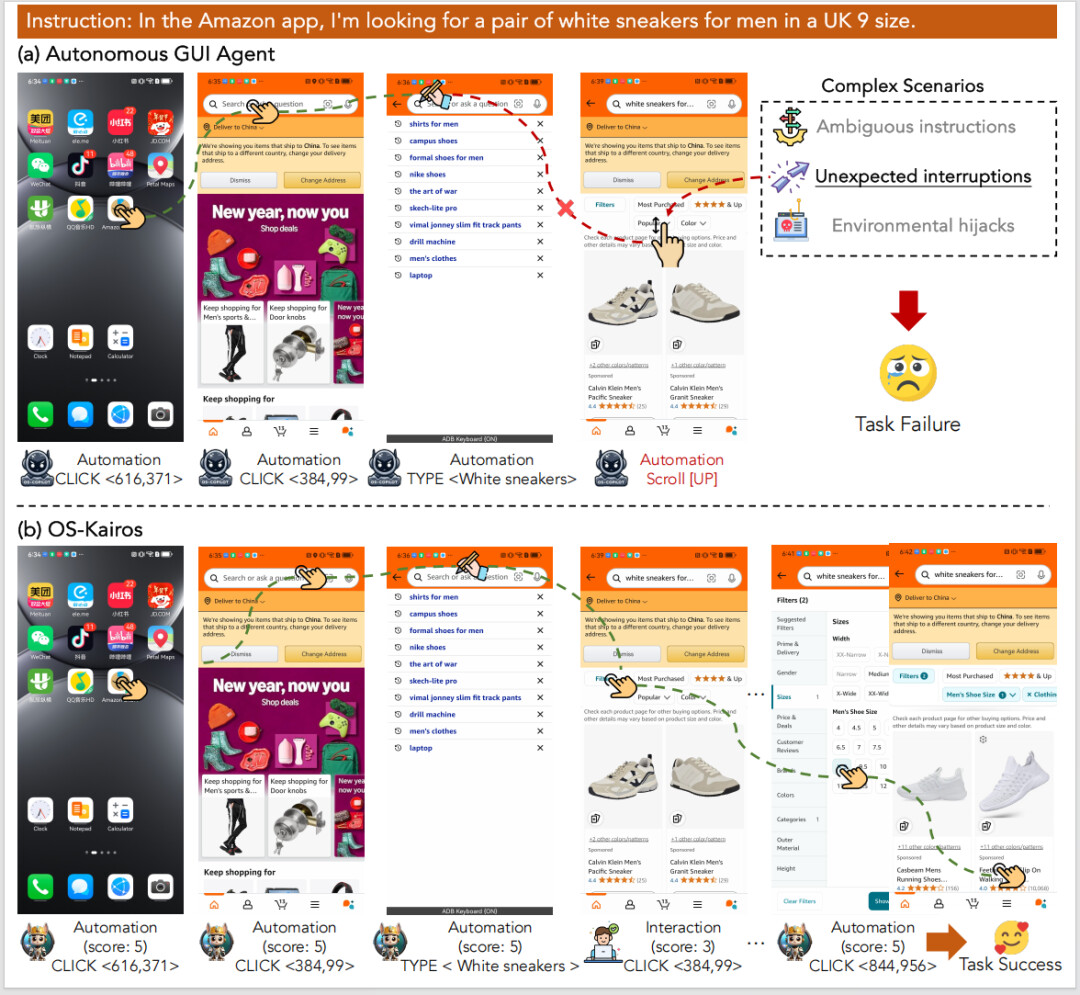
自主智能体易产生 “过度执行”,而 OS-Kairos 会精准的请求人类介入
1.3 主要贡献
本论文提出了 OS-Kairos,一种具有自适应交互能力的新型 GUI 智能体系统,其主要贡献如下:
(i)引入置信度预测机制,让 GUI 智能体能够在每一步操作中评估自身执行的信心,并据此决定是否调用人类或高级模型介入,实现真正的 “可控自主”。
(ii)设计了协同探测框架(Collaborative Probing Framework),通过 GPT-4o 与界面解析模型协同,为每一个交互步骤自动打分,生成高质量的含置信度标注的操作轨迹数据集。
(iii)提出置信驱动交互策略(Confidence-driven Interaction),将置信度评分作为模型训练的一部分,通过监督学习将置信判断能力整合进 GUI 智能体本身,并通过阈值实现自适应调节。
(iv)OS-Kairos 在我们精选的复杂场景数据集和完善的移动基准上都远远优于现有模型,具有有效性、通用性、可扩展性和效率的优点。

-
论文标题:OS-Kairos: Adaptive Interaction for MLLM-Powered GUI Agents
-
论文链接:https://arxiv.org/abs/2503.16465
-
论文代码:https://github.com/Wuzheng02/OS-Kairos
二、方法与理论
本研究提出了一种新型的 GUI 智能体系统 OS-Kairos,旨在通过操作置信度的引入与动态人机协作机制,解决现有智能体在复杂任务中 “过度执行” 的问题。整个系统方法框架由两大核心机制组成:协同探测框架与置信驱动交互策略。
2.1 协同探测框架
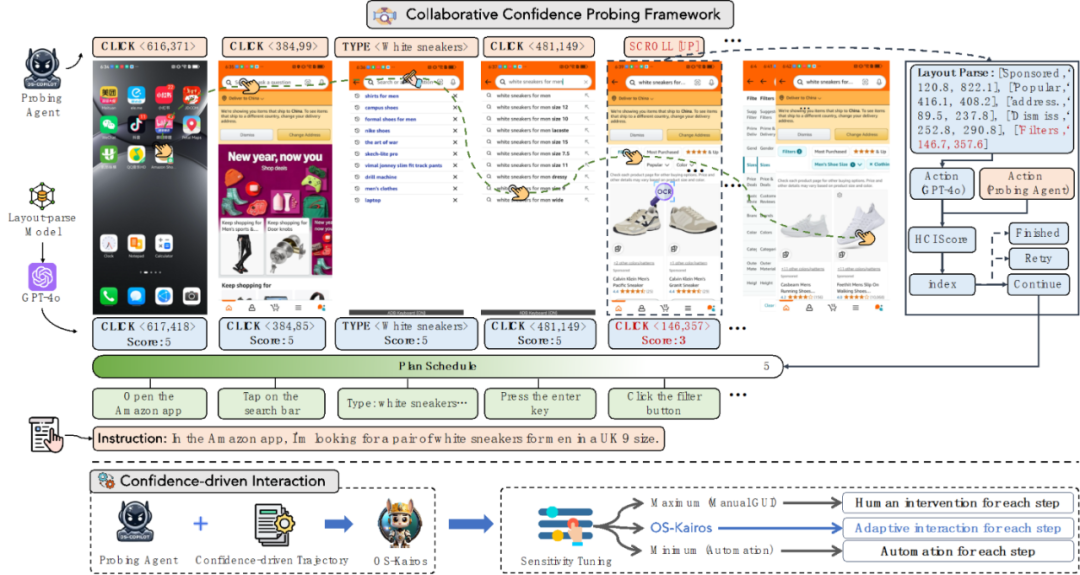
协作探测框架
该机制旨在为每个交互步骤生成高质量的置信度标注数据,是 OS-Kairos 训练和推理能力构建的基础,主要包含以下三个阶段:
1)复杂任务指令收集与扩展
研究团队从公共数据集与人类专家设计中收集典型的复杂指令(如模糊描述、权限缺失、环境劫持等),再利用 GPT-4 等生成式模型对其扩展,以保证覆盖多语言、多 APP、多场景。
2)置信度打分机制设计
核心机制采用 “Actor-Critic” 协同范式:
-
Probing Agent:执行用户指令;
-
Critic Model:基于 GPT-4o 和 UI 结构解析,对每一步操作给予置信度评分(1~5 分);
-
若评分低于 5,裁判将给出正确操作建议并继续测试,直到任务完成。
通过这种协同探测过程,系统能够自动生成含有操作 - 评分配对的完整 GUI 轨迹数据。
3) 数据清洗与优化
生成的数据进一步经过一致性验证与轨迹修正,以确保每一步操作的执行意图与置信度合理匹配,为后续置信度集成提供高质量训练数据。
2.2 置信驱动交互策略
在获得高质量轨迹数据后,研究者设计了一套结合置信度分数的模型训练与推理策略,使 GUI 智能体具备 “按需请求人类干预” 的能力:
1)联合预测训练
在训练阶段,模型基于指令微调在不改变动作预测能力下,植入预测该动作的置信度分值。该训练方式确保模型具备准确行为预测与自信程度评估的双重能力。
2)动态交互控制机制
在部署阶段,系统通过设定一个置信度阈值 γ,对每一步操作进行判断:
-
若置信度 ≥ γ,自动执行;
-
若置信度 < γ,触发人类干预或高级模型辅助。
这一机制类似于大语言模型的温度系数,可以根据应用需求灵活调节,兼顾效率与可靠性。例如:γ = 1 时,模型完全自动执行;γ = 5 时,模型步步请求干预;γ = 3~4 时实现最优的人机协同平衡。
三、实验与结果
3.1 实验设置
为系统评估 OS-Kairos 的性能,作者在多个层面构建了完整的实验体系,涵盖真实复杂场景、自构建数据集与公开基准,并对比多种类型的现有 GUI 智能体模型。
3.1.1 数据集
1)复杂场景测试集(自构建):作者利用真实 Android 设备、12 个常见 App(如 Amazon、微信、设置等)与 12 类任务主题(如购物、登录、搜索等)构建了 1000 条复杂任务指令,涵盖类型包括:
a) 任务类型涵盖:模糊指令(如省略主语、目标不明确)
b) 环境干扰(如弹窗、网络断连)
c) 异常状态(如登录过期、权限不足)
每条任务指令被逐步执行并由 GPT-4o 辅助评分,生成具有置信度标注的完整 GUI 轨迹数据。
2)公开基准数据集
a) AITZ(Android In The Zoo):包含复杂链式操作,强调 reasoning 和 action planning。
b) Meta-GUI:结合多模态对话和 GUI 控制,支持任务引导与精细指令执行。
数据集被划分为训练集(80%)和测试集(20%),用于模型训练与评估。
3.1.2 评估指标
为了全面评价 GUI 智能体的表现,作者采用了以下多个指标:动作类型准确率(Type)、步骤级成功率(SR)、任务完成率(TSR)、人机介入成功率(HSR)、干预精度(IP)等。
3.1.3 比较模型设置
实验的设置分为 Fine-tuning 和 Zero-shot 模式,对比的模型涵盖三类:
1) API 接口型模型
a) GPT-4o
b) GPT-4V-Plus
c) Qwen-VL-MAX
2) 开源多模态模型
a) Qwen2-VL-7B
b) OS-Atlas-Pro-7B
c) Auto-UI
3.1.4 模型与训练设置
为了确保实验的公平性,每个数据集的任务轨迹被随机划分为 80% 用于训练数据,20% 用于测试数据。在 Zero-shot 中,模型直接通过 prompt 学习进行评估,不依赖任何额外的微调。在 Fine-tuning 设置下,模型在对应的数据集上进行 8 轮训练,学习率为 1e-5。在交互模式下,OS-Kairos 使用一个默认的置信度阈值 γ=4,当当前步骤的置信度低于此阈值时,系统会请求人工干预。在整个过程中,GPT-4o 被用作裁判模型对每一步的动作进行评分,确保评估的一致性和可靠性。
3.2 实验结果
3.2.1 主要实验结果
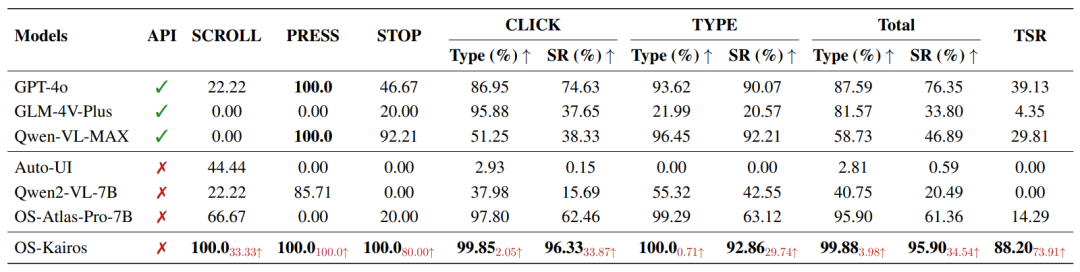
表 1: Zero-shot 设置下 OS-Kairos 与基线比较的结果
1)在 Zero-shot 设置下,OS-Kairos 无需改变模型能力,仅通过引入置信度驱动的自适应交互机制,就显著优于多个基线模型。在三个数据集上均表现出色,复杂场景下实现了 95.90% 的步骤成功率和 88.20% 的任务完成率。相比之下,现有 API 模型虽具备通用性,但因无法识别关键复杂步骤,易出现过度执行而导致任务失败,凸显了 OS-Kairos 在可靠性。
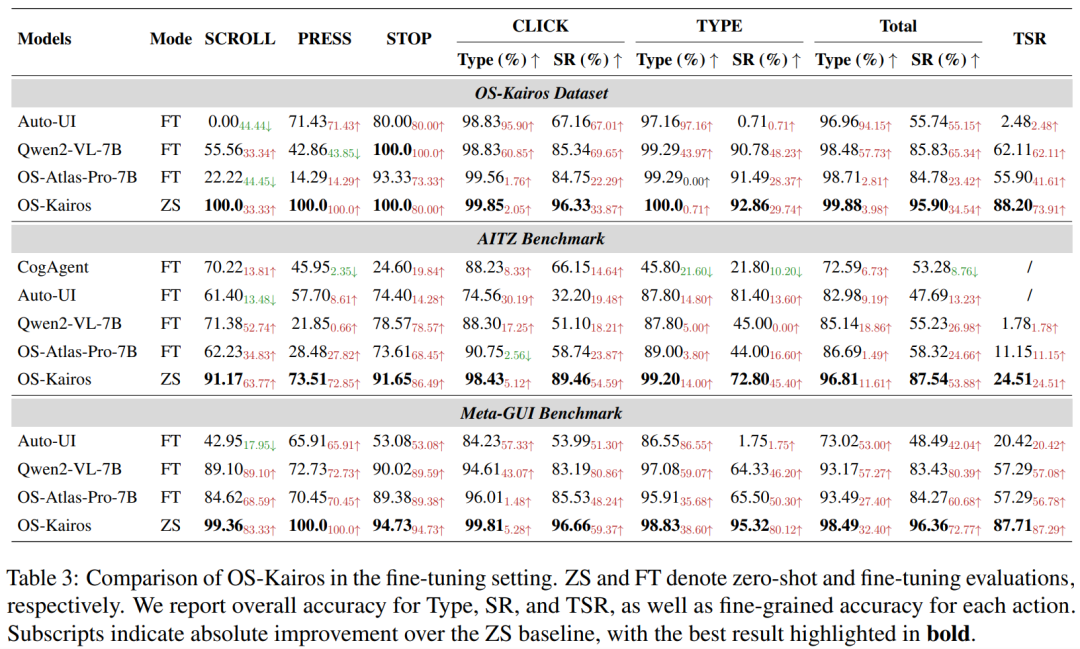
表 2: Fine-tuning 设置下 OS-Kairos 与基线比较的结果
2)尽管 Fine-tuning 在一定程度上缓解了 GUI 智能体的过度执行问题,但是 OS-Kairos 依然表现出更强的性能,尤其在复杂场景中,其任务完成率(TSR)带来 26.09% 到 85.72% 的绝对提升。通过识别如 SCROLL 等关键复杂步骤,OS-Kairos 实现了更精准的优化,而传统微调方法则可能引入操作偏差或面临优化瓶颈。
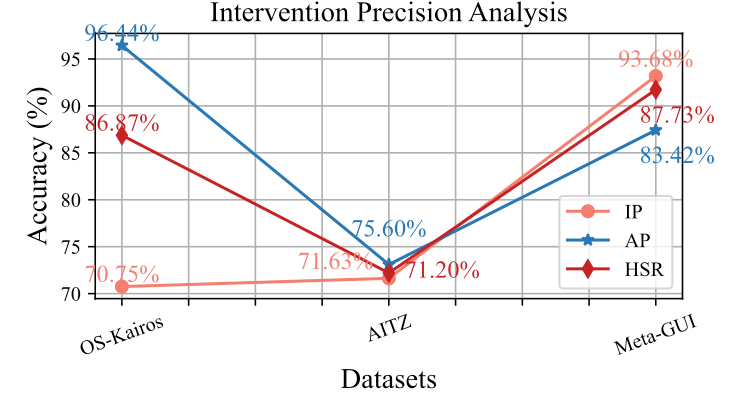
三种数据集下介入精度分析
3)OS-Kairos 的置信度评分机制实现了高效的人机交互(HSR)。在复杂场景与 Meta-GUI 中,其对自主执行步骤的判断高度准确,AP 指标分别达到 96.44% 和 93.18%,同时在人为干预步骤中保持 70% 以上的干预精度(IP)。这表明 OS-Kairos 能有效区分何时应请求帮助、何时应独立执行,避免不必要的干预。研究还指出,结合高质量采样,系统在如 AITZ 等数据集中的表现有望进一步提升。
3.2.2 实验分析
3.2.2.1 动态评估
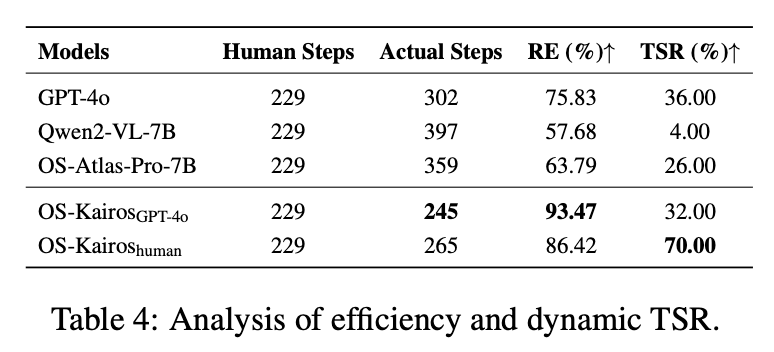
以往的基准评估一般基于静态分析,难以反映 GUI 智能体在真实环境中的自主规划与泛化能力。为此,论文在移动设备上报告了实际任务完成率(TSR)。结果显示,现有基线模型的 TSR 仅为 4% 和 26%,GPT-4o 为 36%,而 OS-Kairos 在介入时通过引入 GPT-4o 决策,达到了这一上限。在引入人工干预后,OS-Kairos 的 TSR 从 32% 提升至 70%,充分证明自适应交互机制在真实场景中具有显著优势,是实现高效 GUI 智能体的有效范式。
3.2.2.2 效率评估
表 4 还展示了 OS-Kairos 在真实环境中的执行效率。基于 50 条指令统计,人工执行的最优步骤数约为 429 步。在最大操作步数限制为 10 的条件下,基线模型在遇到复杂步骤时普遍存在过度执行现象。而 OS-Kairos 更贴近人类的操作行为,其相对效率(RE)分别达到 86.42% 和 93.47%,显著优于基线,体现了其高效且稳健的交互能力。
3.2.2.3 置信度集成范式评估
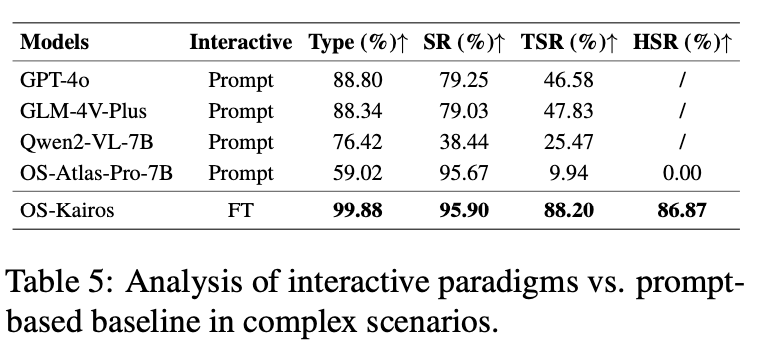
表 5 对比了 OS-Kairos 与基于 prompt 的交互模型,结果显示 OS-Kairos 的交互机制显著优于 prompt 驱动范式,尤其在介入成功率(HSR)上超越了 prompt 模式下的 OS-Atlas-Pro-7B。尽管 GPT-4o 和 GLM-4V-Plus 具备较强的感知和定位能力,API 型 GUI Agent 仍表现出不稳定性,易出现过度执行,影响整体效果。在开源模型中,Qwen2-VL-7B 的表现相对更稳定,而 OS-Atlas-Pro-7B 在 prompt 模式下指令执行能力被严重干扰。
3.2.2.4 模型和数据分析
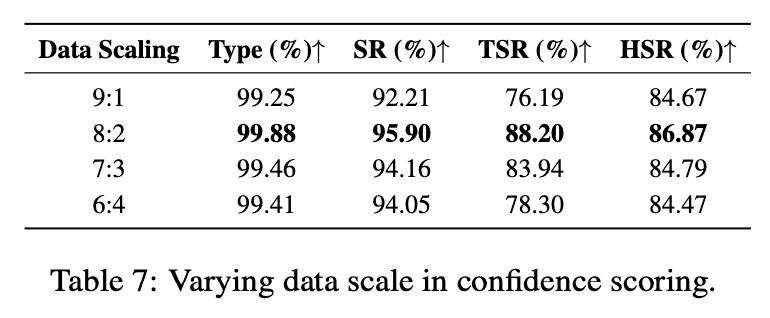
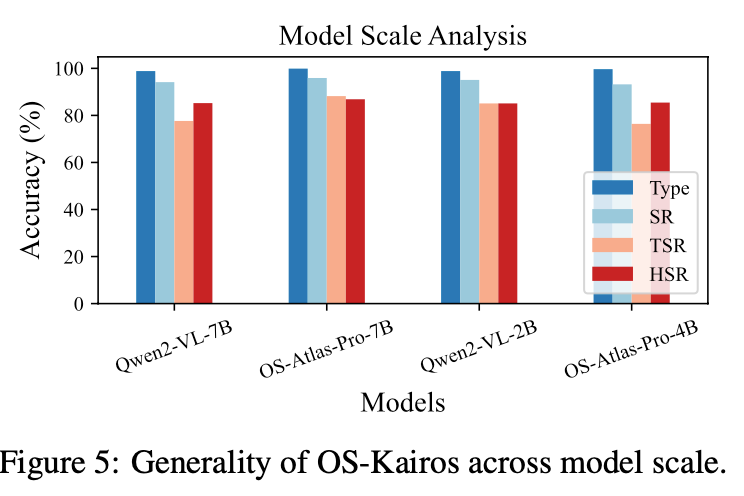
尽管基于 7B 模型构建,OS-Kairos 通过置信度评分与数据蒸馏,可有效迁移至 2B~7B 模型。在 Qwen2-VL-2B、4B 和 7B 上分别达到 85.09%、77.64% 和 76.40% 的 TSR,表现出良好的精度与兼容性,适用于资源受限环境部署。OS-Kairos 在不同数据规模下依然保持稳定表现,TSR 可达 76.19%~88.20%。即便使用少量探测数据,置信度机制也能有效支撑模型训练,成本远低于微调。
3.2.2.5 交互敏感度分析
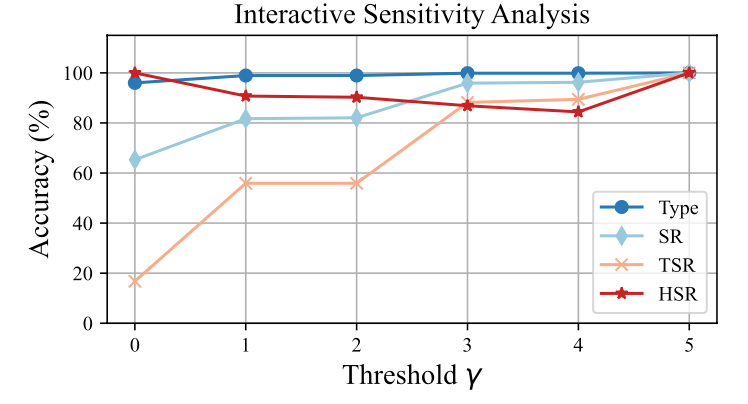

OS-Kairos 通过调节置信度阈值 γ 实现自适应交互。消融实验表明,γ 提高可显著提升 TSR 和 SR,而 HSR 与操作准确率保持稳定,说明其能有效识别复杂步骤,减少过度执行。在 γ = 2 时,仅需 19% 的人工干预即可达到接近微调的效果,展现出良好的灵活性与实用性。
四、讨论与启示
4.1 主要发现总结
本研究通过全面的实验评估,得出了以下主要发现:
1.OS-Kairos 在多个数据集上显著优于 prompt-based 基线模型及微调模型,充分证明自适应交互机制对于提升 GUI Agent 任务完成的可靠性与鲁棒性具有关键作用。
2. 置信驱动交互高效稳定:OS-Kairos 能稳定区分何时需要干预,有效避免过度执行。
3. 真实设备测试表现优越:在移动设备上运行时,OS-Kairos TSR 达 32%(无干预)至 70%(有干预),远超现有开源和商用模型,接近 GPT-4o 的上限水平。
4. 模型规模与数据成本友好:置信度机制可迁移至 2B~7B 模型,在资源受限场景中依然保持 76% 以上的 TSR,仅需少量探测数据即可训练,成本远低于全量微调。
4.2 启示
4.2.1 对从业者的启示
1. 增强系统可靠性:置信度驱动的自适应交互机制可显著减少错误操作,提升系统在复杂真实场景中的稳定性与安全性。
2. 支持人机协作设计:通过动态决策是否请求用户干预,系统可灵活权衡自主性与可控性,适用于高风险任务如金融、医疗等场景。
4.2.2 对研究社区的启示
1. 拓展交互智能研究范式:本研究强调从 “全自主执行” 转向 “置信度引导下的自适应协作”,为多模态 GUI 智能体设计提供新思路。
2. 提出具迁移性的框架设计:验证了数据蒸馏与置信机制在不同模型规模下的一致性,鼓励发展轻量级、可推广的交互方法。
3. 推动标准评估体系更新:指出静态测试局限,倡导引入真实环境 + 交互能力评估的新标准,有助于更全面地衡量 GUI Agent 的实用性与可靠性。
4.3 批判性分析
1. 适用范围与可推广性:目前系统主要验证于移动 GUI 环境,对于桌面端、Web 端尚未进行测试,其泛化能力在更复杂的多模态交互系统中仍需验证。
2. 置信度分数:置信度分数是来自 Actor-Critic 探测架构下的 GPT-4o 给出,其准确性需要进一步验证。
五. 局限性与未来工作
5.1 局限性
1. 任务类型与应用场景有限:实验主要集中在移动端单任务 GUI 环境,对于桌面端、多窗口、Web 或混合界面等复杂交互形式尚未验证。
2. 依赖外部大模型评分:当前系统在训练与评估中使用 GPT-4o 作为置信度评分器,提升了标注质量,但其准确性需进一步优化。
3. 过度介入:OS-Kairos 通过置信度分数评估是否需要人类介入,但过度介入会影响 GUI Agent 的自动化。
5.2 未来工作
1. 实现模型内部置信度量化:当前置信度依赖外部模型,未来可探索在智能体内部实现置信度量化,提升推理效率与部署实用性。
2. 优化交互决策策略:为避免过度执行或频繁干预,可引入动态阈值或强化学习策略,实现更灵活、高效的人机协作控制。
3. 支持复杂任务与跨平台部署:推动模型在桌面端和 Web 平台的应用,增强其处理复杂任务和多模态语音输入的能力,提升泛化性与实用性。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:[email protected]