本文从源码层面解析 Cline AI 如何将自然语言指令转化为实际代码变更,核心在于 Prompt 组装和 Tools 调用,是 Agent 开发的经典实践。
原文标题:从输入指令到代码落地:Cline AI 源码浅析
原文作者:阿里云开发者
冷月清谈:
怜星夜思:
2、文章提到 Cline 针对 Claude4 定制了 System Prompt,这意味着针对不同的大语言模型需要采用不同的优化策略。你在使用其他 AI 编程工具时,有没有类似经验?你是如何针对不同模型进行优化的?
3、Cline 使用 replace_in_file 工具来修改文件,这种方式有哪些优缺点?有没有更安全或者更高效的代码修改方案?
原文内容

阿里妹导读
文章揭示了Cline如何将简单的自然语言指令转化为具体的编程任务,并执行相应的代码修改或生成操作。
本篇文章从源码角度来看一下从我们输入指令到 Cline 输出的过程到底是怎样的,这样对我们后续使用 Cline 会有更好的帮助。
Cline 是一个非常好用的 AI 开发助手。关于 Cline 可以戳官方文档了解。
https://cline.bot/
启动 Cline
访问 Cline 的 Github 仓库 README:
https://github.com/cline/cline?tab=readme-ov-file
# Local Development Instructions
git clone https://github.com/cline/cline.git
code cline
npm run install:all
在 VSCode 里 F5 或者 Run->Start Debugging 开始调试 Cline VSCode 插件。此时会新开一个 VSCode 窗口,这个窗口里加载就是我们调试版本的 Cline 插件。
这里可能遇到一些问题,一个是仓库里提到的,如果构建有问题,需要安装 esbuild Problem Matchers插件:https://marketplace.visualstudio.com/items
另外项目的 Webview 里需要安装 electron 这个巨无霸,可能会很慢,可以设置为国内源:
electron_mirror=https://npmmirror.com/mirrors/electron/
electron_builder_binaries_mirror=https://npmmirror.com/mirrors/electron-builder-binaries/
shamefully-hoist=true
Step by Step Debug
VSCode 对自家插件的调试做的非常好,不管是 VSCode 主进程还是 Webview 容器,下面就一步一步的开始调试。
前端输入
我们准备一段简单的输入:创建一个新任务,实现快速排序算法,并插入到 utils 文件内。
/newtask 实现快速排序算法,写入 @/src/utils/index.ts 文件
这里使用了 Cline 的内置的两个功能:内置命令 Command /newtask 以及 mention @ 功能指定了写入的文件。Command 可以理解为指定特定任务的 prompts,方便执行一些高频操作的任务,Cline 内置了诸如新建任务、创建 Rule、创建 Github Issue 等 Command。@ 功能可以指定模型特别关注的上下文,比如指定的文件内容,指定的目录内容。
输入框内输入上述内容,点击发送,代码文件:
webview-ui/src/components/chat/ChatView.tsx,发送消息的方法为handleSendMessage,Webview 内只负责收集输入信息,实际任务处理的逻辑都会发送至 VSCode 的主进程内,VSCode 主进程处理过程中,会实时的发送消息回 Webview。
// 文件位置 webview-ui/src/services/grpc-client-base.ts window.addEventListener("message", handleResponse)// Send the request
const encodedRequest = encodeRequest(request)
vscode.postMessage({
type: “grpc_request”,
grpc_request: {
service: service.fullName,
method: method.name, // method 为 newTask
message: encodedRequest, // message 为输入的文本、图片、文件消息等
request_id: requestId,
is_streaming: false,
},
})
message 的格式:
我们这里没有添加图片和文件,files 和 images 为空。
files =(0) [ ]
images =(0) [ ]
text ='/newtask 创建一个快速排序算法,写入 @/src/utils/index.ts 文件'
VSCode 主进程接收 grpc_request 消息进行处理。
VSCode 主进程接收消息
主进程处理的内容位于:src/core/controller/grpc-handler.ts:
/**
* Handle a gRPC request from the webview
* @param service The service name
* @param method The method name
* @param message The request message
* @param requestId The request ID for response correlation
* @param isStreaming Whether this is a streaming request
* @returns The response message or error for unary requests, void for streaming requests
*/
async handleRequest(
service: string,
method: string,
message: any,
requestId: string,
isStreaming: boolean = false,
): Promise<{
message?: any
error?: string
request_id: string
} | void> {}
可以看到,参数和 Webview 传过来的一致。
任务初始化
经过各种封装,最终处理的任务落到了src/core/controller/index.ts 的 initTask 方法内一个超级大的 Task 类的初始化:
this.task = new Task(
this.context,
this.mcpHub,
this.workspaceTracker,
(historyItem) => this.updateTaskHistory(historyItem),
() => this.postStateToWebview(),
(message) => this.postMessageToWebview(message),
(taskId) => this.reinitExistingTaskFromId(taskId),
() => this.cancelTask(),
apiConfiguration,
autoApprovalSettings,
browserSettings,
chatSettings,
shellIntegrationTimeout,
terminalReuseEnabled ?? true,
enableCheckpointsSetting ?? true,
customInstructions,
task,
images,
files,
historyItem,
)
Task 类位于src/core/task/index.ts,在一系列的初始化后:
初始化的代码没有过度深究,从类名来看,包括了后续任务执行中可能使用到的工具:浏览器、命令行、Url、DiffView 等;mcp 的配置;autoApprove 的配置等等。
终于进入到实际的逻辑处理:
首先,根据用户配置的模型提供商信息创建 AI 的 api handler:
// Now that taskId is initialized, we can build the API handler
this.api = buildApiHandler(effectiveApiConfiguration)
然后,进入到 startTask 方法:
say 方法会在聊天面板新增一条消息,比如下面的代码,将用户的输入信息显示在聊天面板:
await this.say("text", task, images, files)
构建 User Prompt
接下来,构建 userContent:
// 为用户输入的消息添加一个 task 标签。
let userContent: UserContent = [
{
type: "text",
text: `<task>\n${task}\n</task>`,
},
...imageBlocks,
]
/**
text =
‘<task>\n/newtask 创建一个快速排序算法,写入 @/src/utils/index.ts 文件\n</task>’
type =
‘text’
/
如果用户提供了文件(Cline 支持用户上传文本文件),背后其实是访问文本文本,也用来构造 userContent。if (files && files.length > 0) {
const fileContentString = await processFilesIntoText(files)
if (fileContentString) {
userContent.push({
type: "text",
text: fileContentString,
})
}
}
继续构造 Prompts
用过 Cline 的话,我们会知道 Cline 会循环处理任务,所以 User Prompts 构造完成后,进入到 initiateTaskLoop 方法,真正执行任务的方法为 recursivelyMakeClineRequests:
进一步处理用户的输入信息:
const [parsedUserContent, environmentDetails, clinerulesError] = await this.loadContext(userContent, includeFileDetails)
这样处理之后,用户输入重新组装为 parsedUserContent,内容比较长,这里不贴了,大致格式为:
<explicit_instructions type="new_task"></explicit_instructions>
<task>用户输入</task>
<fileContent>src/utils/index.ts内的文件</fileContent>
再次看一下我们的输入:/newtask 实现快速排序算法,写入 @/src/utils/index.ts 文件,上面三段一一对应:<explicit_instructions type="new_task"> 对应 /newtask 命令,这是 Cline 的内置 prompt,@/src/utils/index.ts 添加了该文件内容作为上下文。
同时将 environmentDetails 也添加到 userContent,environmentDetails 有工作目录、当前时间、当前打开的 Tab 等。
userContent = parsedUserContent
// add environment details as its own text block, separate from tool results
userContent.push({ type: "text", text: environmentDetails })
怪不得 Cline 这么耗 Token!
模型请求
继续进入 attemptApiRequest 方法,首先构造 System prompt:
const isClaude4ModelFamily = await this.isClaude4ModelFamily()
let systemPrompt = await SYSTEM_PROMPT(cwd, supportsBrowserUse, this.mcpHub, this.browserSettings, isClaude4ModelFamily)
比较有意思的是,Cline 针对 Claude4 定制了不同的 System Prompt。
System Prompt 里会告诉模型我们当前已经提供了哪些工具以及这些工具该如何调用(参数和规则),比如本次任务要将模型生成的代码写入已有文件,那么就需要使用到
replace_in_file这个工具,这里贴一下 System Prompt 里关于replace_in_file的内容。
## replace_in_file
Description: Request to replace sections of content in an existing file using SEARCH/REPLACE blocks that define exact changes to specific parts of the file. This tool should be used when you need to make targeted changes to specific parts of a file.
Parameters:
- path: (required) The path of the file to modify(relative to the current working directory ${cwd.toPosix()})
- diff: (required) One or more SEARCH/REPLACE blocks following this exact format:
\`\`\`
------- SEARCH
[exact content to find]
=======
[new content to replace with]
+++++++ REPLACE
\`\`\`
Critical rules:
1. SEARCH content must match the associated file section to find EXACTLY:
* Match character-for-character including whitespace, indentation, line endings
* Include all comments, docstrings, etc.
2. SEARCH/REPLACE blocks will ONLY replace the first match occurrence.
* Including multiple unique SEARCH/REPLACE blocks if you need to make multiple changes.
* Include *just* enough lines in each SEARCH section to uniquely match each set of lines that need to change.
* When using multiple SEARCH/REPLACE blocks, list them in the order they appear in the file.
3. Keep SEARCH/REPLACE blocks concise:
* Break large SEARCH/REPLACE blocks into a series of smaller blocks that each change a small portion of the file.
* Include just the changing lines, and a few surrounding lines if needed for uniqueness.
* Do not include long runs of unchanging lines in SEARCH/REPLACE blocks.
* Each line must be complete. Never truncate lines mid-way through as this can cause matching failures.
4. Special operations:
* To move code: Use two SEARCH/REPLACE blocks (one to delete from original + one to insert at new location)
* To delete code: Use empty REPLACE section
Usage:
<replace_in_file>
<path>File path here</path>
<diff>
Search and replace blocks here
</diff>
</replace_in_file>
同时,System Prompt 也继续追加了用户的偏好语言,方便按照用户偏好的语言进行输出。
接下来发送请求:
let stream = this.api.createMessage(systemPrompt, contextManagementMetadata.truncatedConversationHistory)
针对模型的输出,需要进一步处理,是直接展示在聊天面板,还是需要调用工具处理,这部分逻辑在src/core/assistant-message/parse-assistant-message.ts 的 parseAssistantMessageV2 方法内。
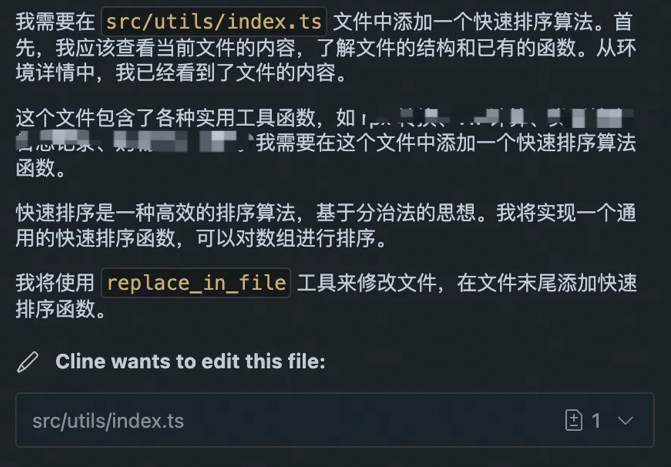
针对我们本次创建排序算法的任务,下面是一个模型输出样例:
<thinking>\n我需要在`src/utils/index.ts`文件中添加一个快速排序算法。首先,我已经看到了文件的内容,这是一个工具函数集合文件,包含了各种实用函数,如rpx转换、vw计算、类型检查、日志记录等。\n\n我需要在这个文件中添加一个快速排序算法实现。快速排序是一种高效的排序算法,基于分治法的思想。我将实现一个通用的快速排序函数,可以对数组进行排序。\n\n我将使用`replace_in_file`工具来修改文件,在文件末尾添加快速排序算法的实现。我需要确保添加的代码与现有代码风格保持一致,并提供适当的类型注解和注释。\n\n我将在文件末尾添加快速排序算法的实现,包括:\n1. 一个主快速排序函数,接受一个数组和可选的比较函数\n2. 一个辅助函数用于分区操作\n\n让我使用`replace_in_file`工具来修改文件。\n</thinking>\n\n<replace_in_file>\n<path>src/utils/index.ts</path>\n<diff>\n------- SEARCH\nexport const jump2UpdateApp = () => {\n if (is… (a, b) => {\n if (a < b) return-1;\n if (a > b) return1;\n return0;\n}): T[ ] => {\n // 创建数组副本,不修改原数组\n const result = [...arr];\n \n // 内部快速排序实现\n const _quickSort = (arr: T[ ], left: number, right: number) => {\n if (left < right) {\n const pivotIndex = partition(arr, left, right);\n _quickSort(arr, left, pivotIndex - 1);\n _quickSort(arr, pivotIndex + 1, right);\n }\n };\n \n // 分区操作\n const partition = (arr: T[ ], left: number, right: number): number => {\n // 选择最右边的元素作为基
parseAssistantMessageV2 方法会解析上述输出内容,主要是从模型输出中解析出使用哪些工具以及工具的参数,比如这里我们发现模型输出中有 <replace_in_file>,那就说明这次需要使用 replace_in_file 工具。
接下来调用 presentAssistantMessage 方法真正将模型消息展示给用户,一方面展示文本消息,类似下图:
一方面执行上一步解析出的 tool,将模型生成代码以 diff 的方式写入文件,这里借助 VSCode 的能力创建 diffView。自此这个任务算是完成了。
总结
抛开 Cline 中用户交互和工程处理的部分,我们发现最核心的其实只有两件事情:
1、prompt 组装。这其中包括了 System Prompt、VSCode 和系统的环境信息、内置 Command、内置的 @ 引用(文件、目录信息)、用户的输入(文本、图片、文本文件),当然还有我们之前介绍的 Rules 以及我们提到过的 Workflow(本质是用户自定义的 Command)。这些内容共同组装称为 Prompt 发送给模型,力求给模型足够多的上下文信息,获得更加准确的结果。
2、tools 调用。首先在 System Prompt 定义了模型可以调用的 Tool(包括内置的和本文未涉及的 MCP Server ),在模型输出时指定调用的 Tool 和需要的参数,以此进一步增强模型的能力。
两者共同合作完成用户的编码的任务。
由此我们可以看到 Agent 开发中最重要的三点:
2. 丰富的创意和合适的落地场景;
3. 丝滑的体验。
部署SSL证书,实现Web服务加密访问
用户使用 HTTP 请求访问网站域名,通常会存在安全风险。使用 HTTPS 协议可以有效规避安全风险,保证请求全链路的数据访问安全。本方案介绍如何将 SSL 证书部署到 Web 应用服务器,帮助您的 Web 服务器和网站间建立可信的 HTTPS 协议加密连接,为您的网站安全加锁,保证数据安全传输。
点击阅读原文查看详情。