想深入理解大模型?《从零构建大模型》带你从零开始,揭秘GPT底层原理,成为AI时代的参与者和贡献者!
原文标题:我们需要一张能揭示大模型底层原理的地图
原文作者:图灵编辑部
冷月清谈:
怜星夜思:
2、这本书强调“从零开始”,那么对于已经有一定大模型使用经验的人来说,这本书的价值在哪里?
3、如果让你用一句话向别人推荐这本书,你会怎么说?
原文内容
缘起
从过年期间 DeepSeek 横空出世开始,几乎所有人都被卷到了大模型的浪潮当中,我也是那个时候开始开始重启公众号,开始了 AI 的学习与体验之路。
不得不说,大模型已经惊人的速度渗透到了我们工作的方方面面。无论是 Kimi、DeepSeek、豆包,还是 Cursor、Trae、Gemini,这些 AI 工具早已不只是“新奇玩具”。对于一线的开发者或 SRE 来说,它们是编码的得力助手;对于产品经理或团队负责人而言,它们是激发创意、优化产品路径的重要参考。我们每天都在使用各种 AI 产品,感受 AI 带来的效率提升。
但随之而来的,是一种更深层次的思考。我发现,仅仅停留在“使用”层面,可能逐渐陷入了一种新的被动:
-
• 作为技术人员,我们习惯了掌控工具,但面对大模型这个“黑箱”,我们感到能力仿佛有了一层天花板,无法深入优化,也难以判断其能力的真伪边界。
-
• 作为产品人,我们讨论着“AI-Native”,但如果不理解其技术基石,又如何能设计出真正有壁垒、有远见的产品?
-
• 而对于那些刚刚结束高考、准备拥抱大学生活的准大学生,或是希望投身 AI 浪潮的毕业生来说,面对这个日新月异的领域,最大的困惑莫过于:我的第一步应该迈向哪里?如何才能构建一个不被“版本迭代”轻易淘汰的坚实知识体系?
尽管我们的角色和视角各不相同,但似乎都指向了一个共同的诉求:我们需要一张能揭示大模型底层原理的地图。
“从调用 API 到复现 GPT”——这句话精准地描述了我们所有人都渴望完成的思维跨越:从一个“应用者”,转变为一个深刻的“理解者”,甚至未来的“构建者”。最近阅读的 Sebastian Raschka 这本新书《从零构建大模型》“Build a Large Language Model (from Scratch)”就可以很好的解决上面的问题。
在推荐这本书之前,我们必须先聊聊它的作者——塞巴斯蒂安 · 拉施卡(Sebastian Raschka)。
在机器学习和 Python 社区,这个名字本身就是一块金字招牌。如果你曾在学习 AI 的路上寻找过经典教材,那么你几乎不可能错过他的镇山之宝——被无数人奉为“红宝书”的《Python 机器学习》(Python Machine Learning)。这本书以其无与伦比的清晰度、理论与实践的完美结合,以及扎实的编码范例,成为了全球数百万学习者的入门和进阶圣经。无数人的机器学习知识体系,可以说就是由这本书构建起来的。这证明了他拥有将复杂理论转化为清晰、可实践的文字和代码的非凡能力。
因此,当这样一位以“讲得透彻、代码扎实”而闻名的作者,决定亲自撰写一本关于“从零开始构建大语言模型”的书时,你几乎可以无条件地相信:这,就是你一直在等待的那本硬核指南。
《从零构建大模型》

这本书最大的特点,就是为所有渴望“知其所以然”的人,提供了一条最扎实、最经典的路径:From Scratch,从零开始。它不要求你有深厚的算法背景,但它默认你对技术抱有最根本的好奇心。
这本书的整体逻辑都是按照下图展开的:
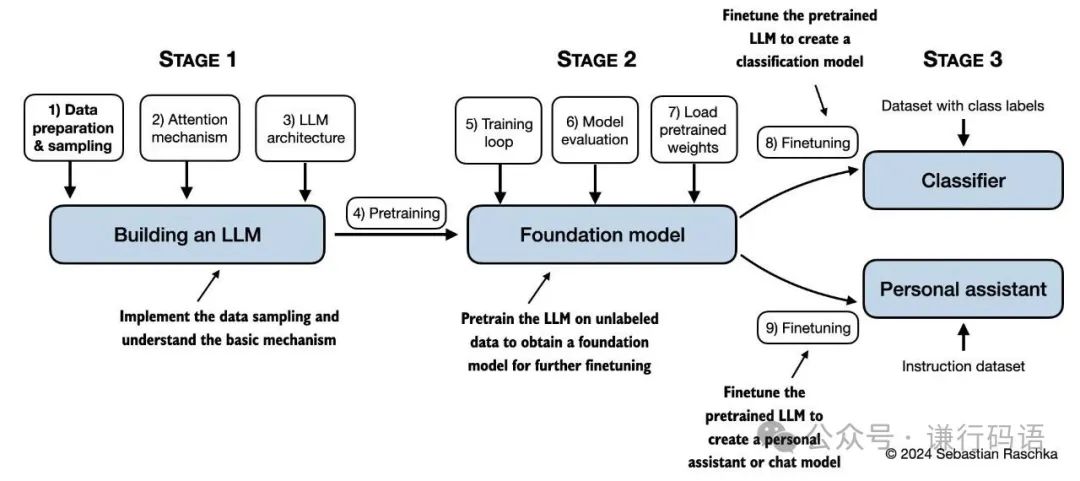
我用 processon 重新画了一版本:

-
• 从最基础的 文本分词(Tokenization) 开始,理解模型如何“阅读”人类的语言。
-
• 到亲手实现核心的自注意力机制(Self-Attention),真正看懂 Transformer 架构的心脏是如何跳动的。
-
• 再到最终将所有模块组装起来,完成一个虽然不大、但五脏俱全的 GPT 风格模型,并亲手训练它。

这本书可以不但可以带着你写出一个能跑的大模型程序,更重要的是,你将真正建立起对大模型技术的第一性原理认知,这个就非常重要了。
这套认知体系,对于开发者来说意味着更强的工程掌控力,对于产品经理来说意味着更敏锐的产品洞察力,而对于学生和新人来说,这无疑是进入 AI 领域最硬核、也最扎实的一张“入场券”。在你眼中,这些纷繁复杂玲琅满目的大模型都将不再是神秘的黑箱,而是一套你可以理解、分析、甚至有能力去改造的工程系统。
这本书有在 Github 有完整的代码项目:
-
官方项目:https://github.com/rasbt/LLMs-from-scratch
-
中文翻译项目:https://github.com/skindhu/Build-A-Large-Language-Model-CN
同时,这本书有很多的插图,能够图文并茂地进行原理教学:
-
介绍大语言模型在整体的 AI 框架位置:

-
介绍 transformer 架构:

-
介绍用 GPT 模型来处理垃圾信息分类任务:


写在最后
所以,回到我们最初的问题:从调用 API 到亲手复现 GPT,这中间的距离到底有多远?
读完这本书,我的答案是:它的距离,不在于你拥有多少高深的数学或算法知识,而在于你是否愿意迈出“从零开始”的第一步。
这本书最大的魅力,就是它将这个看似遥不可及的目标,分解成了你我都可以理解和执行的清晰步骤。它用一种近乎“开源”的精神,毫无保留地揭示了“黑箱”之中的秘密,将构建大模型的权利,真正交还到了每一个普通技术人的手中。
如果你不满足于仅仅做一个时代的见证者,而是渴望成为一名真正的参与者、乃至未来的贡献者,那么,翻开这本书,亲手构建你的第一个大语言模型,将是你迈向这个未来最坚实、也最精彩的一步。
加油,一起学习!
如果你觉得自己啃书太孤单,咱抱团学习,一起进步!快来扫码进群吧 ~👇
